Selenium+PhantomJS
Selenium
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,类型像我们玩游戏用的按键精灵,可以按指定的命令自动操作,不同是Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)。
Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。但是我们有时候需要让它内嵌在代码中运行,所以我们可以用一个叫 PhantomJS 的工具代替真实的浏览器。
可以从 PyPI 网站下载 Selenium库,也可以用 第三方管理器
pip用命令安装:
pip install selenium==2.48.0
PhantomJS
PhantomJS 是一个基于Webkit的“无界面”(headless)浏览器,它会把网站加载到内存并执行页面上的
JavaScript,因为不会展示图形界面,所以运行起来比完整的浏览器要高效。
如果我们把 Selenium 和 PhantomJS 结合在一起,就可以运行一个非常强大的网络爬虫了,这个爬虫可以处理 JavaScrip、Cookie、headers,以及任何我们真实用户需要做的事情。
注意:PhantomJS 只能从它的官方网站下载。 因为 PhantomJS 是一个功能完善(虽然无界面)的浏览器而非一个 Python 库,所以它不需要像 Python 的其他库一样安装,但我们可以通过Selenium调用PhantomJS来直接使用。
PhantomJS 官方参考文档
快速入门
Selenium 库里有个叫 WebDriver 的 API。WebDriver 有点儿像可以加载网站的浏览器,但是它也可以像BeautifulSoup 或者其他 Selector 对象一样用来查找页面元素,与页面上的元素进行交互 (发送文本、点击等),以及执行其他动作来运行网络爬虫。
简单案例:
# 导入 webdriver
from selenium import webdriver
import time # 要想调用键盘按键操作需要引入keys包
from selenium.webdriver.common.keys import Keys # 调用环境变量指定的PhantomJS浏览器创建浏览器对象
driver = webdriver.PhantomJS() # 如果没有在环境变量指定PhantomJS位置
# driver = webdriver.PhantomJS(executable_path="./phantomjs")) # get方法会一直等到页面被完全加载,然后才会继续程序,
# 通常测试会在这里选择 time.sleep(2)
driver.get("http://www.baidu.com") # # 获取页面名为 wrapper的id标签的文本内容
data = driver.find_element_by_id("wrapper").text # 打印数据内容
print(data) # 打印页面标题 "百度一下,你就知道"
print(driver.title) # 生成当前页面快照并保存
driver.save_screenshot("index.png") # id="kw"是百度搜索输入框,输入字符串"长城"
driver.find_element_by_id("kw").send_keys(u"长城") # id="su"是百度搜索按钮,click() 是模拟点击
driver.find_element_by_id("su").click() #time.sleep(2)这个时间表示服务器响应时间
# 获取新的页面快照
driver.save_screenshot("长城.png") # 打印网页渲染后的源代码
# print(driver.page_source) # 获取当前页面Cookie
print(driver.get_cookies()) # # ctrl+a 全选输入框内容driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'a') # driver.save_screenshot("长城a.png") # # ctrl+x 剪切输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'x') # 输入框重新输入内容
driver.find_element_by_id("kw").send_keys(u"python") driver.save_screenshot("a1.png") # 模拟Enter回车键
# time.sleep(10) #加个延时,不然可能会报错:
# Element is not currently interactable and may not be manipulated # driver.find_element_by_id("su").send_keys(Keys.RETURN)
#注意:这个地方用回车是没有效果的,因为输入框在表单当中,
# 可以使用表单提交完成请求driver.find_element_by_id("su").submit() time.sleep(2)
driver.save_screenshot("a3.png")
执行效果如下图所示 # # 清除输入框内容driver.find_element_by_id("kw").clear() # #
# # 生成新的页面快照
driver.save_screenshot("ziyi.png") # 获取当前url
print(driver.current_url) # 关闭当前页面,如果只有一个页面,会关闭浏览器
# driver.close() # 关闭浏览器
driver.quit()
结果如下:

页面操作
Selenium 的 WebDriver提供了各种方法来寻找元素,在百度首页有一个表单输入框:
#百度输入框架页面源码
#<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off"> # 1.根据id获取标签# time.sleep(2)
element = driver.find_element_by_id("kw")
#获取标签的属性 # 格式:标签.get_attribute("属性名") print(element.get_attribute("type"))#text print(element.get_attribute("class"))#s_ipt # 2.根据name获取标签标
element = driver.find_element_by_name("wd") # 3.根据标签名获取标签名
element = driver.find_elements_by_tag_name("input") #返回列表 # 4.通过XPath来匹配
element = driver.find_element_by_xpath("//input[@id='kw']")#返回元素
定位UI元素 (WebElements)
在一个页面中有很多不同的策略可以定位一个元素。在你的项目中, 你可以选择最合适的方法去查找元素。Selenium提供了下列的方法给你:
一次查找单个元素:
# 通过ID查找元素
find_element_by_id
# 通过Name查找元素
find_element_by_name
# 通过XPath查找元素
find_element_by_xpath
# 通过链接文本获取超链接
find_element_by_link_text
find_element_by_partial_link_text
# 通过标签名查找元素
find_element_by_tag_name
# 通过Class name 定位元素
find_element_by_class_name
# 通过CSS选择器查找元素
find_element_by_css_selector
一次查找多个元素 (这些方法会返回一个list列表):
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
可能出现的报错
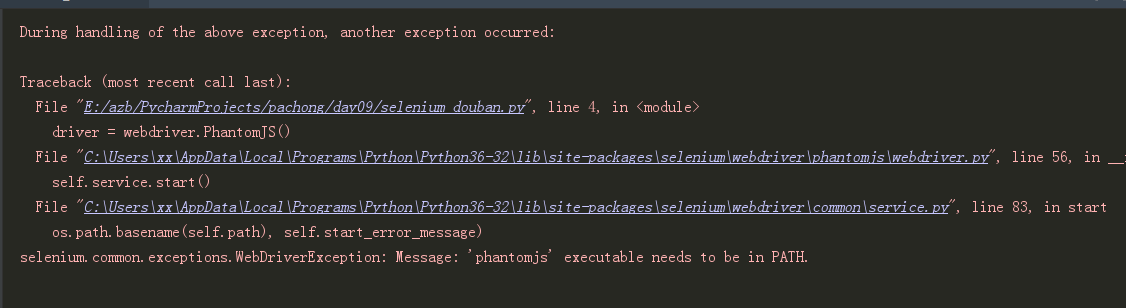
解决:
将PhantomJS路径添加到环境变量中 或者在创建浏览器对象是指定Phantomjs路径
Selenium+PhantomJS的更多相关文章
- selenium + phantomjs 爬取落网音乐
题记: 作为一个业余程序猿,最大的爱好就是电影和音乐了,听音乐当然要来点有档次的.落网的音乐的逼格有点高,一听听了10年.学习python一久了,于是想用python技术把落网的音乐爬下来随便听. 目 ...
- 使用selenium+phantomJS实现网页爬取
有些网站反爬虫技术设计的非常好,很难采用WebClient等技术进行网页信息爬取,这时可以考虑采用selenium+phantomJS模拟浏览器(其实是真实的浏览器)的方式进行信息爬取.之前一直使用的 ...
- Selenium + PhantomJS + python 简单实现爬虫的功能
Selenium 一.简介 selenium是一个用于Web应用自动化程序测试的工具,测试直接运行在浏览器中,就像真正的用户在操作一样 selenium2支持通过驱动真实浏览器(FirfoxDrive ...
- 数据抓取的艺术(一):Selenium+Phantomjs数据抓取环境配置
数据抓取的艺术(一):Selenium+Phantomjs数据抓取环境配置 2013-05-15 15:08:14 分类: Python/Ruby 数据抓取是一门艺术,和其他软件不同,世界上 ...
- 动态网页爬取例子(WebCollector+selenium+phantomjs)
目标:动态网页爬取 说明:这里的动态网页指几种可能:1)需要用户交互,如常见的登录操作:2)网页通过JS / AJAX动态生成,如一个html里有<div id="test" ...
- python+selenium自动化软件测试(第6章):selenium phantomjs页面解析使用
我们都知道Selenium是一个Web的自动化测试工具,可以在多平台下操作多种浏览器进行各种动作,比如运行浏览器,访问页面,点击按钮,提交表单,浏览器窗口调整,鼠标右键和拖放动作,下拉框和对话框处理等 ...
- 学习用java基于webMagic+selenium+phantomjs实现爬虫Demo爬取淘宝搜索页面
由于业务需要,老大要我研究一下爬虫. 团队的技术栈以java为主,并且我的主语言是Java,研究时间不到一周.基于以上原因固放弃python,选择java为语言来进行开发.等之后有时间再尝试pytho ...
- 利用Selenium+PhantomJS 实现截图
using OpenQA.Selenium; using OpenQA.Selenium.PhantomJS; using System; using System.Drawing; using Sy ...
- python selenium+phantomjs alert()弹窗报错
问题:用selenium+phantomjs 模拟登陆,网页用JavaScript的alert("登陆成功")弹出框,但是用switch_to_alert().accept()报错 ...
- C#使用Selenium+PhantomJS抓取数据
本文主要介绍了C#使用Selenium+PhantomJS抓取数据的方法步骤,具有很好的参考价值,下面跟着小编一起来看下吧 手头项目需要抓取一个用js渲染出来的网站中的数据.使用常用的httpclie ...
随机推荐
- 我的第一篇博客之js的XXXX年XX月XX日 星期[日一-六] [上下]午 XX时:XX分
<!DOCTYPE html> <html> <head> <title>test</title> ...
- rem是如何实现自适应布局的
原文链接:http://caibaojian.com/web-app-rem.html 摘要:rem是相对于根元素<html>,这样就意味着,我们只需要在根元素确定一个px字号,则可以来算 ...
- SO减单后MO分配给其他SO的问题修复
逻辑:MO取进FP系统之前,首先判断是否带有SO号+SO行号,如果带有SO号+SO行号,则判断此SO号和SO行号是否存在订单表中,如果不存在则表示此MO对应的订单已减单,此MO需要做过滤,并展现在报表 ...
- PropertyGrid控件动态生成属性及下拉菜单 (转)
http://blog.sina.com.cn/s/blog_6f14b7010101b91b.html https://msdn.microsoft.com/zh-cn/library/ms1718 ...
- 五:python 对象类型详解二:字符串(上)
一:常量字符串 常量字符串用起来相对简单,也许最复杂的事情就是在代码中有如此多的方法来编写它们. eg:单引号:'spam"m' , 双引号: “spa'm” , 三引号:‘’‘... ...
- 侯捷STL课程及源码剖析学习3: 深度探索容器list
一.容器概览 上图为 GI STL 2.9的各种容器.图中以内缩方式来表达基层与衍生层的关系.所谓的衍生,并非继承(inheritance)关系,而是内含(containment)关系.例如 heap ...
- hdu 5023 线段树+位运算
主要考线段树的区间修改和区间查询,这里有一个问题就是这么把一个区间的多种颜色上传给父亲甚至祖先节点,在这里题目告诉我们最多30颜色,那么我们可以把这30中颜色用二进制储存和传给祖先节点,二进制的每一位 ...
- leecode 937 Reorder Log Files (模拟)
传送门:点我 You have an array of logs. Each log is a space delimited string of words. For each log, the ...
- TOJ3448: 小学生的作业
Python字符串的插入操作 传送门:http://acm.tzc.edu.cn/acmhome/problemdetail.do?&method=showdetail&id=3448 ...
- httpclient和httpUrlConnect区别
HttpURLConnection的用法 一.创建HttpURLConnection对象 URL url = new URL("http://localhost:8080/TestHttpU ...