Python数据分析--Pandas知识点(一)
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘
1. 重复值的处理
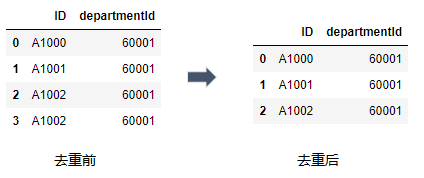
利用drop_duplicates()函数删除数据表中重复多余的记录, 比如删除重复多余的ID.
import pandas as pd
df = pd.DataFrame({"ID": ["A1000","A1001","A1002", "A1002"],
"departmentId": [60001,60001, 60001, 60001]})
df.drop_duplicates()
2. 缺失值的处理
缺失值是数据中因缺少信息而造成的数据聚类, 分组, 截断等
2.1 缺失值产生的原因
主要原因可以分为两种: 人为原因和机械原因.
1) 人为原因: 由于人的主观失误造成数据的缺失, 比如数据录入人员的疏漏;
2) 机械原因: 由于机械故障导致的数据收集或者数据保存失败从而造成数据的缺失.
2.2 缺失值的处理方式
缺失值的处理方式通常有三种: 补齐缺失值, 删除缺失值, 删除缺失值, 保留缺失值.
1) 补齐缺失值: 使用计算出来的值去填充缺失值, 例如样本平均值.
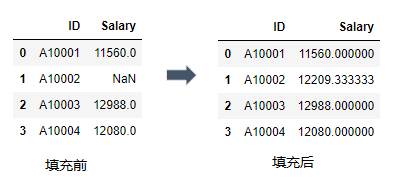
使用fillna()函数对缺失值进行填充, 使用mean()函数计算样本平均值.
import pandas as pd
import numpy as np
df = pd.DataFrame({'ID':['A10001', 'A10002', 'A10003', 'A10004'],
"Salary":[11560, np.NaN, 12988,12080]})
#用Salary字段的样本均值填充缺失值
df["Salary"] = df["Salary"].fillna(df["Salary"].mean())
df
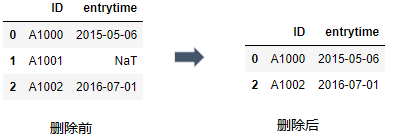
2) 删除缺失值: 当数据量大时且缺失值占比较小可选用删除缺失值的记录.
示例: 删除entrytime中缺失的值, 采用dropna函数对缺失值进行删除:
import pandas as pd
df = pd.DataFrame({"ID": ["A1000","A1001","A1002"],
"entrytime": ["2015-05-06",pd.NaT,"2016-07-01" ]})
df.dropna()
3) 保留缺失值.
3. 删除前后空格
使用strip()函数删除前后空格.
import pandas as pd
df = pd.DataFrame({"ID": ["A1000","A1001","A1002"],
"Surname": [" Zhao ","Qian"," Sun " ]})
df["Surname"] = df["Surname"].str.strip()
df

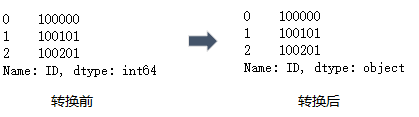
4. 查看数据类型
查看所有列的数据类型使用dtypes, 查看单列使用dtype, 具体用法如下:
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname": [" Zhao ","Qian"," Sun " ]})
#查看所有列的数据类型
df.dtypes
#查看单列的数据类型
df["ID"].dtype

5. 修改数据类型
使用astype()函数对数据类型进行修改, 用法如下
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname": [" Zhao ","Qian"," Sun " ]})
#将ID列的类型转化为字符串的格式
df["ID"].astype(str)
6. 字段的抽取
使用slice(start, end)函数可完成字段的抽取, 注意start是从0开始且不包含end. 比如抽取前两位slice(0, 2).
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname": [" Zhao ","Qian"," Sun " ]})
#需要将ID列的类型转换为字符串, 否则无法使用slice()函数
df["ID"]= df["ID"].astype(str)
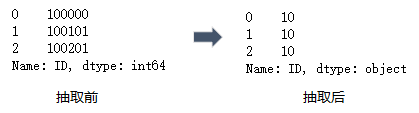
#抽取ID前两位
df["ID"].str.slice(0,2)
7. 字段的拆分
使用split()函数进行字段的拆分, split(pat=None, n = -1, expand=True)函数包含三个参数:
第一个参数则是分隔的字符串, 默认是以空格分隔
第二个参数则是分隔符使用的次数, 默认分隔所有
第三个参数若是True, 则在不同的列展开, 否则以序列的形式显示.
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
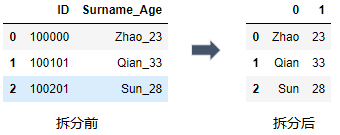
#对Surname_Age字段进行拆分
df_new = df["Surname_Age"].str.split("_", expand =True)
df_new
8. 字段的命名
有两种方式一种是使用rename()函数, 另一种是直接设置columns参数
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
#第一种方法使用rename()函数
# df_new = df["Surname_Age"].str.split("_", expand =True).rename(columns={0: "Surname", 1: "Age"})
# df_new
#第二种方法直接设置columns参数
df_new = df["Surname_Age"].str.split("_", expand =True)
df_new.columns = ["Surname","Age"]
df_new
两种方式同样的结果:

9. 字段的合并
使用merge()函数对字段进行合并操作.
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
df_new = df["Surname_Age"].str.split("_", expand =True)
df_new.columns = ["Surname","Age"]
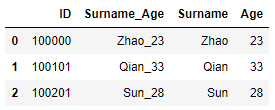
#使用merge函数对两表的字段进行合并操作.
pd.merge(df, df_new, left_index =True, right_index=True)
10. 字段的删除
利用drop()函数对字段进行删除.
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
df_new = df["Surname_Age"].str.split("_", expand =True)
df_new.columns = ["Surname","Age"]
df_mer= pd.merge(df, df_new, left_index =True, right_index=True)
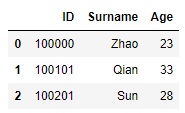
#drop()删除字段,第一个参数指要删除的字段,axis=1表示字段所在列,inplace为True表示在当前表执行删除.
df_mer.drop("Surname_Age", axis = 1, inplace =True)
df_mer
删除Surname_Age字段成功:
11. 记录的抽取
1) 关系运算: df[df.字段名 关系运算符 数值], 比如抽取年龄大于30岁的记录.
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
df_new = df["Surname_Age"].str.split("_", expand =True)
df_new.columns = ["Surname","Age"]
df_mer= pd.merge(df, df_new, left_index =True, right_index=True)
df_mer.drop("Surname_Age", axis = 1, inplace =True)
#将Age字段数据类型转化为整型
df_mer["Age"] = df_mer["Age"].astype(int)
#抽取Age中大于30的记录
df_mer[df_mer.Age > 30]
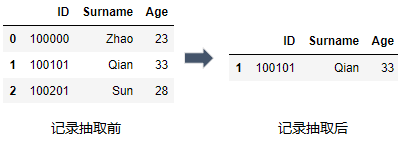
2) 范围运算: df[df.字段名.between(s1, s2)], 注意既包含s1又包含s2, 比如抽取年龄大于等于23小于等于28的记录.
df_mer[df_mer.Age.between(23,28)]
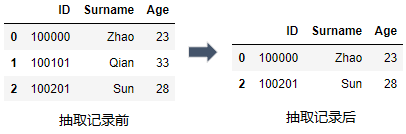
3) 逻辑运算: 与(&) 或(|) 非(not)
比如上面的范围运算df_mer[df_mer.Age.between(23,28)]就等同于df_mer[(df_mer.Age >= 23) & (df_mer.Age <= 28)]
df_mer[(df_mer.Age >= 23 ) & (df_mer.Age <= 28)]

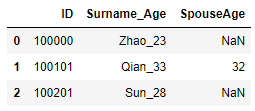
4) 字符匹配: df[df.字段名.str.contains("字符", case = True, na =False)] contains()函数中case=True表示区分大小写, 默认为True; na = False表示不匹配缺失值.
import pandas as pd
import numpy as np
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28"],"SpouseAge":[np.NaN,"",np.NaN]})
#匹配SpouseAge中包含2的记录
df[df.SpouseAge.str.contains("",na = False)]

当na改为True时, 结果为:
5) 缺失值匹配: df[pd.isnull(df.字段名)]表示匹配该字段中有缺失值的记录.
import pandas as pd
import numpy as np
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28"],"SpouseAge":[np.NaN,"",np.NaN]})
#匹配SpouseAge中有缺失值的记录
df[pd.isnull(df.SpouseAge)]

12.记录的合并
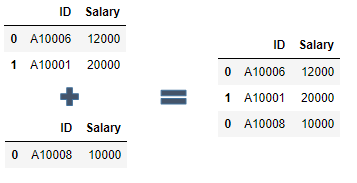
使用concat()函数可以将两个或者多个数据表的记录合并一起, 用法: pandas.concat([df1, df2, df3.....])
import pandas as pd
df1 = pd.DataFrame({"ID": ["A10006","A10001"],"Salary": [12000, 20000]})
df2 = pd.DataFrame({"ID": ["A10008"], "Salary": [10000]})
#使用concat()函数将df1与df2的记录进行合并
pd.concat([df1, df2])
以上是部分内容, 还会持续总结更新....
Python数据分析--Pandas知识点(一)的更多相关文章
- Python数据分析--Pandas知识点(三)
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘. Python数据分析--Pandas知识点(一) Python数据分析--Pandas知识点(二) 下面将是在知识点一, ...
- Python数据分析--Pandas知识点(二)
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘. Python数据分析--Pandas知识点(一) 下面将是在知识点一的基础上继续总结. 13. 简单计算 新建一个数据表 ...
- Python数据分析-Pandas(Series与DataFrame)
Pandas介绍: pandas是一个强大的Python数据分析的工具包,是基于NumPy构建的. Pandas的主要功能: 1)具备对其功能的数据结构DataFrame.Series 2)集成时间序 ...
- python 数据分析--pandas
接下来pandas介绍中将学习到如下8块内容:1.数据结构简介:DataFrame和Series2.数据索引index3.利用pandas查询数据4.利用pandas的DataFrames进行统计分析 ...
- Python数据分析Pandas库方法简介
Pandas 入门 Pandas简介 背景:pandas是一个Python包,提供快速,灵活和富有表现力的数据结构,旨在使“关系”或“标记”数据的使用既简单又直观.它旨在成为在Python中进行实际, ...
- Python之Pandas知识点
很多人都分不清Numpy,Scipy,pandas三个库的区别. 在这里简单分别一下: NumPy:数学计算库,以矩阵为基础的数学计算模块,包括基本的四则运行,方程式以及其他方面的计算什么的,纯数学: ...
- Python数据分析 Pandas模块 基础数据结构与简介(一)
pandas 入门 简介 pandas 组成 = 数据面板 + 数据分析工具 poandas 把数组分为3类 一维矩阵:Series 把ndarray强大在可以存储任意数据类型可以专门处理时间数据 二 ...
- Python数据分析Pandas库之熊猫(10分钟二)
pandas 10分钟教程(二) 重点发法 分组 groupby('列名') groupby(['列名1','列名2',.........]) 分组的步骤 (Splitting) 按照一些规则将数据分 ...
- Python数据分析Pandas库之熊猫(10分钟一)
pandas熊猫10分钟教程 排序 df.sort_index(axis=0/1,ascending=False/True) df.sort_values(by='列名') import numpy ...
随机推荐
- 尚硅谷redis学习10-复制
是什么? 能干嘛? 怎么玩? 1) 初始情况 设置slave 日志查看 主机查看 备机日志 复制状态 觉见问题 1 切入点问题?slave1.slave2是从头开始复制还是从切入点开始复制?比如从k4 ...
- 八皇后问题C语言解法
偶遇八皇后问题,随即自己写了一个仅供参考 #include<stdio.h> #include<math.h> #define SIZE 8 void Circumsribe( ...
- 使用git pull与本地文件冲突
出错信息如下: error: Your local changes to 'c/environ.c' would be overwritten by merge. Aborting. Please, ...
- Java API下载和查阅方法
使用来自API的类是简单的.只要把它当做自己写的就可以,采用import来引用,可以节省自己编程的气力~ 1.API文档下载地址 https://www.oracle.com/technetwork/ ...
- Haskell语言学习笔记(80)req
req req 是一个好用,类型安全,可扩展,上层的HTTP客户端的库. $ cabal install req Installed req-1.1.0 Prelude> :m +Network ...
- C++ CBitmap,HBitmap,Bitmap区别及联系
加载一位图,可以使用LoadImage: HANDLE LoadImage(HINSTANCE hinst,LPCTSTR lpszName,UINT uType,int cxDesired,int ...
- fengsuo
IP地址特定端口封锁 原理: 配合上文中特定IP地址封锁里路由扩散技术封锁的方法进一步精确到端口,从而使发往特定IP地址上特定端口的数据包全部被丢弃而达到封锁目的,使该IP地址上服务器的部分功能无法在 ...
- http://www.cnblogs.com/wuyunfei/p/4277226.html
http://www.cnblogs.com/wuyunfei/p/4277226.html
- 吴裕雄 python 机器学习-DMT(1)
import numpy as np import operator as op from math import log def createDataSet(): dataSet = [[1, 1, ...
- 消息中间件MQ详解及四大MQ比较
一.消息中间件相关知识 1.概述 消息队列已经逐渐成为企业IT系统内部通信的核心手段.它具有低耦合.可靠投递.广播.流量控制.最终一致性等一系列功能,成为异步RPC的主要手段之一.当今市面上有很多主流 ...