redis 持久化的两种方式
一:快照模式
或许在用Redis之初的时候,就听说过redis有两种持久化模式,第一种是SNAPSHOTTING模式,还是一种是AOF模式,而且在实战场景下用的最多的
莫过于SNAPSHOTTING模式,这个不需要反驳吧,而且你可能还知道,使用SNAPSHOTTING模式,需要在redis.conf中设置配置参数,比如下面这样:

# Save the DB on disk:
#
# save <seconds> <changes>
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
#
# Note: you can disable saving completely by commenting out all "save" lines.
#
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
#
# save "" save 900 1
save 300 10
save 60 10000
上面三组命令也是非常好理解的,就是说900指的是“秒数”,1指的是“change次数”,接下来如果在“900s“内有1次更改,那么就执行save保存,同样
的道理,如果300s内有10次change,60s内有1w次change,那么也会执行save操作,就这么简单,看了我刚才说了这么几句话,是不是有种直觉在
告诉你,有两个问题是不是要澄清一下:
1. 上面这个操作应该是redis自身进行的同步操作,请问是否可以手工执行save呢?
当然可以进行手工操作,redis提供了两个操作命令:save,bgsave,这两个命令都会强制将数据刷新到硬盘中,如下图:
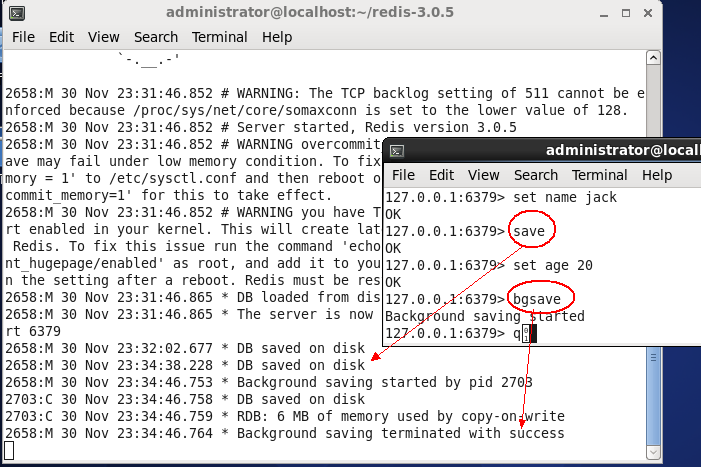
————————————————————————————————————————————————————————
Redis 持久化:
提供了多种不同级别的持久化方式:一种是RDB,另一种是AOF.
RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)。
AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。 AOF 文件中的命令全部以 Redis 协议的格式来保存,新命令会被追加到文件的末尾。 Redis 还可以在后台对 AOF 文件进行重写(rewrite),使得 AOF 文件的体积不会超出保存数据集状态所需的实际大小。Redis 还可以同时使用 AOF 持久化和 RDB 持久化。 在这种情况下, 当 Redis 重启时, 它会优先使用 AOF 文件来还原数据集, 因为 AOF 文件保存的数据集通常比 RDB 文件所保存的数据集更完整。你甚至可以关闭持久化功能,让数据只在服务器运行时存在。
了解 RDB 持久化和 AOF 持久化之间的异同是非常重要的, 以下几个小节将详细地介绍这这两种持久化功能, 并对它们的相同和不同之处进行说明。
RDB 的优点:
RDB 是一个非常紧凑(compact)的文件,它保存了 Redis 在某个时间点上的数据集。 这种文件非常适合用于进行备份: 比如说,你可以在最近的 24 小时内,每小时备份一次 RDB 文件,并且在每个月的每一天,也备份一个 RDB 文件。 这样的话,即使遇上问题,也可以随时将数据集还原到不同的版本。RDB 非常适用于灾难恢复(disaster recovery):它只有一个文件,并且内容都非常紧凑,可以(在加密后)将它传送到别的数据中心,或者亚马逊 S3 中。RDB 可以最大化 Redis 的性能:父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
RDB 的缺点:
如果你需要尽量避免在服务器故障时丢失数据,那么 RDB 不适合你。 虽然 Redis 允许你设置不同的保存点(save point)来控制保存 RDB 文件的频率, 但是, 因为RDB 文件需要保存整个数据集的状态, 所以它并不是一个轻松的操作。 因此你可能会至少 5 分钟才保存一次 RDB 文件。 在这种情况下, 一旦发生故障停机, 你就可能会丢失好几分钟的数据。每次保存 RDB 的时候,Redis 都要 fork() 出一个子进程,并由子进程来进行实际的持久化工作。 在数据集比较庞大时, fork() 可能会非常耗时,造成服务器在某某毫秒内停止处理客户端; 如果数据集非常巨大,并且 CPU 时间非常紧张的话,那么这种停止时间甚至可能会长达整整一秒。 虽然 AOF 重写也需要进行 fork() ,但无论 AOF 重写的执行间隔有多长,数据的耐久性都不会有任何损失。
AOF 的优点:
使用 AOF 持久化会让 Redis 变得非常耐久(much more durable):你可以设置不同的 fsync 策略,比如无 fsync ,每秒钟一次 fsync ,或者每次执行写入命令时 fsync 。 AOF 的默认策略为每秒钟 fsync 一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync 会在后台线程执行,所以主线程可以继续努力地处理命令请求)。AOF 文件是一个只进行追加操作的日志文件(append only log), 因此对 AOF 文件的写入不需要进行 seek , 即使日志因为某些原因而包含了未写入完整的命令(比如写入时磁盘已满,写入中途停机,等等), redis-check-aof 工具也可以轻易地修复这种问题。
Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
AOF 的缺点:
对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。AOF 在过去曾经发生过这样的 bug : 因为个别命令的原因,导致 AOF 文件在重新载入时,无法将数据集恢复成保存时的原样。 (举个例子,阻塞命令 BRPOPLPUSH 就曾经引起过这样的 bug 。) 测试套件里为这种情况添加了测试: 它们会自动生成随机的、复杂的数据集, 并通过重新载入这些数据来确保一切正常。 虽然这种 bug 在 AOF 文件中并不常见, 但是对比来说, RDB 几乎是不可能出现这种 bug 的。
RDB 和 AOF ,我应该用哪一个?
一般来说,如果想达到足以媲美 PostgreSQL 的数据安全性, 你应该同时使用两种持久化功能。如果你非常关心你的数据,但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久化。有很多用户都只使用 AOF 持久化, 但我们并不推荐这种方式: 因为定时生成 RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快, 除此之外, 使用 RDB 还可以避免之前提到的 AOF 程序的 bug 。因为以上提到的种种原因, 未来我们可能会将 AOF 和 RDB 整合成单个持久化模型。 (这是一个长期计划。)
RDB 快照:
在默认情况下, Redis 将数据库快照保存在名字为 dump.rdb 的二进制文件中。你可以对 Redis 进行设置, 让它在“ N 秒内数据集至少有 M 个改动”这一条件被满足时, 自动保存一次数据集。你也可以通过调用 SAVE 或者 BGSAVE , 手动让 Redis 进行数据集保存操作。比如说, 以下设置会让 Redis 在满足“ 60 秒内有至少有 1000 个键被改动”这一条件时, 自动保存一次数据集:
save 60 1000
这种持久化方式被称为快照(snapshot)。
快照的运作方式:
当 Redis 需要保存 dump.rdb 文件时, 服务器执行以下操作:
Redis 调用 fork() ,同时拥有父进程和子进程。
子进程将数据集写入到一个临时 RDB 文件中。
当子进程完成对新 RDB 文件的写入时,Redis 用新 RDB 文件替换原来的 RDB 文件,并删除旧的 RDB 文件。
这种工作方式使得 Redis 可以从写时复制(copy-on-write)机制中获益。
只进行追加操作的文件(append-only file,AOF)
快照功能并不是非常耐久(durable): 如果 Redis 因为某些原因而造成故障停机, 那么服务器将丢失最近写入、且仍未保存到快照中的那些数据。尽管对于某些程序来说, 数据的耐久性并不是最重要的考虑因素, 但是对于那些追求完全耐久能力(full durability)的程序来说, 快照功能就不太适用了。
从 1.1 版本开始, Redis 增加了一种完全耐久的持久化方式: AOF 持久化。
你可以通过修改配置文件来打开 AOF 功能:
appendonly yes
从现在开始, 每当 Redis 执行一个改变数据集的命令时(比如 SET), 这个命令就会被追加到 AOF 文件的末尾。
这样的话, 当 Redis 重新启时, 程序就可以通过重新执行 AOF 文件中的命令来达到重建数据集的目的。
AOF 重写:
因为 AOF 的运作方式是不断地将命令追加到文件的末尾, 所以随着写入命令的不断增加, AOF 文件的体积也会变得越来越大。举个例子, 如果你对一个计数器调用了 100 次 INCR , 那么仅仅是为了保存这个计数器的当前值, AOF 文件就需要使用 100 条记录(entry)。然而在实际上, 只使用一条 SET 命令已经足以保存计数器的当前值了, 其余 99 条记录实际上都是多余的。为了处理这种情况, Redis 支持一种有趣的特性: 可以在不打断服务客户端的情况下, 对 AOF 文件进行重建(rebuild)。执行 BGREWRITEAOF 命令, Redis 将生成一个新的 AOF 文件, 这个文件包含重建当前数据集所需的最少命令。
AOF 有多耐久?
你可以配置 Redis 多久才将数据 fsync 到磁盘一次。
有三个选项:
每次有新命令追加到 AOF 文件时就执行一次 fsync :非常慢,也非常安全。
每秒 fsync 一次:足够快(和使用 RDB 持久化差不多),并且在故障时只会丢失 1 秒钟的数据。
从不 fsync :将数据交给操作系统来处理。更快,也更不安全的选择。
推荐(并且也是默认)的措施为每秒 fsync 一次, 这种 fsync 策略可以兼顾速度和安全性。
总是 fsync 的策略在实际使用中非常慢, 即使在 Redis 2.0 对相关的程序进行了改进之后仍是如此 —— 频繁调用 fsync 注定了这种策略不可能快得起来。
如果 AOF 文件出错了,怎么办?
服务器可能在程序正在对 AOF 文件进行写入时停机, 如果停机造成了 AOF 文件出错(corrupt), 那么 Redis 在重启时会拒绝载入这个 AOF 文件, 从而确保数据的一致性不会被破坏。
当发生这种情况时, 可以用以下方法来修复出错的 AOF 文件:
为现有的 AOF 文件创建一个备份。
使用 Redis 附带的 redis-check-aof 程序,对原来的 AOF 文件进行修复。
$ redis-check-aof --fix
(可选)使用 diff -u 对比修复后的 AOF 文件和原始 AOF 文件的备份,查看两个文件之间的不同之处。
重启 Redis 服务器,等待服务器载入修复后的 AOF 文件,并进行数据恢复。
AOF 的运作方式
AOF 重写和 RDB 创建快照一样,都巧妙地利用了写时复制机制。
以下是 AOF 重写的执行步骤:
Redis 执行 fork() ,现在同时拥有父进程和子进程。
子进程开始将新 AOF 文件的内容写入到临时文件。对于所有新执行的写入命令,父进程一边将它们累积到一个内存缓存中,一边将这些改动追加到现有 AOF 文件的末尾: 这样即使在重写的中途发生停机,现有的 AOF 文件也还是安全的。当子进程完成重写工作时,它给父进程发送一个信号,父进程在接收到信号之后,将内存缓存中的所有数据追加到新 AOF 文件的末尾。现在 Redis 原子地用新文件替换旧文件,之后所有命令都会直接追加到新 AOF 文件的末尾。
为最新的 dump.rdb 文件创建一个备份。
将备份放到一个安全的地方。
执行以下两条命令:
redis-cli> CONFIG SET appendonly yes
redis-cli> CONFIG SET save ""
确保命令执行之后,数据库的键的数量没有改变。
确保写命令会被正确地追加到 AOF 文件的末尾。
步骤 3 执行的第一条命令开启了 AOF 功能: Redis 会阻塞直到初始 AOF 文件创建完成为止, 之后 Redis 会继续处理命令请求, 并开始将写入命令追加到 AOF 文件末尾。
步骤 3 执行的第二条命令用于关闭 RDB 功能。 这一步是可选的, 如果你愿意的话, 也可以同时使用 RDB 和 AOF 这两种持久化功能。
别忘了在 redis.conf 中打开 AOF 功能! 否则的话, 服务器重启之后, 之前通过 CONFIG SET 设置的配置就会被遗忘, 程序会按原来的配置来启动服务器。
RDB 和 AOF 之间的相互作用:
在版本号大于等于 2.4 的 Redis 中, BGSAVE 执行的过程中, 不可以执行 BGREWRITEAOF 。 反过来说, 在 BGREWRITEAOF 执行的过程中, 也不可以执行 BGSAVE 。
这可以防止两个 Redis 后台进程同时对磁盘进行大量的 I/O 操作。
如果 BGSAVE 正在执行, 并且用户显示地调用 BGREWRITEAOF 命令, 那么服务器将向用户回复一个 OK 状态, 并告知用户, BGREWRITEAOF 已经被预定执行: 一旦 BGSAVE 执行完毕, BGREWRITEAOF 就会正式开始。当 Redis 启动时, 如果 RDB 持久化和 AOF 持久化都被打开了, 那么程序会优先使用 AOF 文件来恢复数据集, 因为 AOF 文件所保存的数据通常是最完整的。
备份 Redis 数据:
Redis 对于数据备份是非常友好的, 因为你可以在服务器运行的时候对 RDB 文件进行复制: RDB 文件一旦被创建, 就不会进行任何修改。 当服务器要创建一个新的 RDB 文件时, 它先将文件的内容保存在一个临时文件里面, 当临时文件写入完毕时, 程序才使用 原子地用临时文件替换原来的 RDB 文件。这也就是说, 无论何时, 复制 RDB 文件都是绝对安全的。
redis 持久化的两种方式的更多相关文章
- Redis持久化的两种方式和区别
该文转载自:http://www.cnblogs.com/swyi/p/6093763.html Redis持久化的两种方式和区别 Redis是一种高级key-value数据库.它跟memcached ...
- redis持久化的两种方式
redis是一个内存型数据库.当redis服务器重启时,数据会丢失.我们可以将redis内存中的数据持久化保存到硬盘的文件中. redis持久化有两种机制.RDB与AOF.默认方式是RDB. 1.RD ...
- Redis持久化的两种方式(RDB和AOF)
redis提供了两种持久化的方式,分别是RDB(Redis DataBase)和AOF(Append Only File). RDB,简而言之,就是在不同的时间点,将redis存储的数据生成快照并存储 ...
- redis持久化的两种方式RDB和AOF
原文链接:http://www.cnblogs.com/tdws/p/5754706.html Redis的持久化过程中并不需要我们开发人员过多的参与,我们要做的是什么呢?除了深入了解RDB和AOF的 ...
- redis 持久化有几种方式?
面试题 redis 的持久化有哪几种方式?不同的持久化机制都有什么优缺点?持久化机制具体底层是如何实现的? 面试官心理分析 redis 如果仅仅只是将数据缓存在内存里面,如果 redis 宕机了再重启 ...
- 转载redis持久化的几种方式
redis持久化的几种方式 1.前言 Redis是一种高级key-value数据库.它跟memcached类似,不过数据可以持久化,而且支持的数据类型很丰富.有字符串,链表,集 合和有序集合.支持在服 ...
- Redis的持久化的两种方式drbd以及aof日志方式
redis的持久化配置: 主要包括两种方式:1.快照 2 日志 来看一下redis的rdb的配置选项和它的工作原理: save 900 1 // 表示的是900s内,有1条写入,则产生快照 save ...
- Redis数据持久化的两种方式RDB和AOF
由于Redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了,于是需要开启redis的持久化功能,将数据保存到磁 盘上,当redis重启后,可以从磁盘中恢复数据.redis提 ...
- redis做持久化的两种方式,RDB、AOF讲解
redis的两种持久化方式: 1.RDB方式 概念:在指定的时间间隔内保存数据快照 实现方式: 找到redis的安装目录,修改redis的配置文件(redis.conf):① 修改备份的时间间隔:sa ...
随机推荐
- 解题:CF1118F2 Tree Cutting (Hard Version)
题面 好题不问Div(这是Div3最后一题,不得不说Mike真是强=.=) 首先同一个颜色的点的LCA要和它们在一个划分出的块里,那么我们先按颜色把所有点到它们的LCA的路径涂色,如果这个过程中出现了 ...
- Django通过中间件实现登录验证demo
前提:中间件版的登录验证需要依靠session,所以数据库中要有django_session表. from django.conf.urls import url from django.contri ...
- C/C++ 类成员函数指针 类成员数据指针
普通函数指针: "return_type (*ptr_name)(para_types) " 类成员函数指针: "return_type (class_name::*p ...
- eos节点启动源码分析
在eos源码目录中programs/nodeos/main.cpp文件里,为节点启动的主函数main函数内部做了两件事1 初始化 application if(!app().initialize< ...
- python的内置模块random随机模块方法详解以及使用案例(五位数随机验证码的实现)
1.random(self): Get the next random number in the range [0.0, 1.0) 取0到1直接的随机浮点数 import random print( ...
- HDU 5299 圆扫描线 + 树上删边
几何+博弈的简单组合技 给出n个圆,有包含关系,以这个关系做游戏,每次操作可以选择把一个圆及它内部的圆全部删除,不能操作者输. 圆的包含关系显然可以看做是树型结构,所以也就是树上删边的游戏. 而找圆的 ...
- 英文写作指南——《“compare to”等同“compare with”吗?》
- dedecms织梦让channelartlist标签支持currentstyle属性
打开include\taglib\channelartlist.lib.php 大约93行 找到: $pv->Fields['typeurl'] = GetOneTypeUrlA($typei ...
- linq.js - LINQ for JavaScript
var jsonArray = [ { "user": { "id": 100, "screen_name": "d_linq&q ...
- [转载]Understanding the Bootstrap 3 Grid System
https://scotch.io/tutorials/understanding-the-bootstrap-3-grid-system With the 3rd version of the gr ...