大数据学习——flume日志分类采集汇总
1. 案例场景
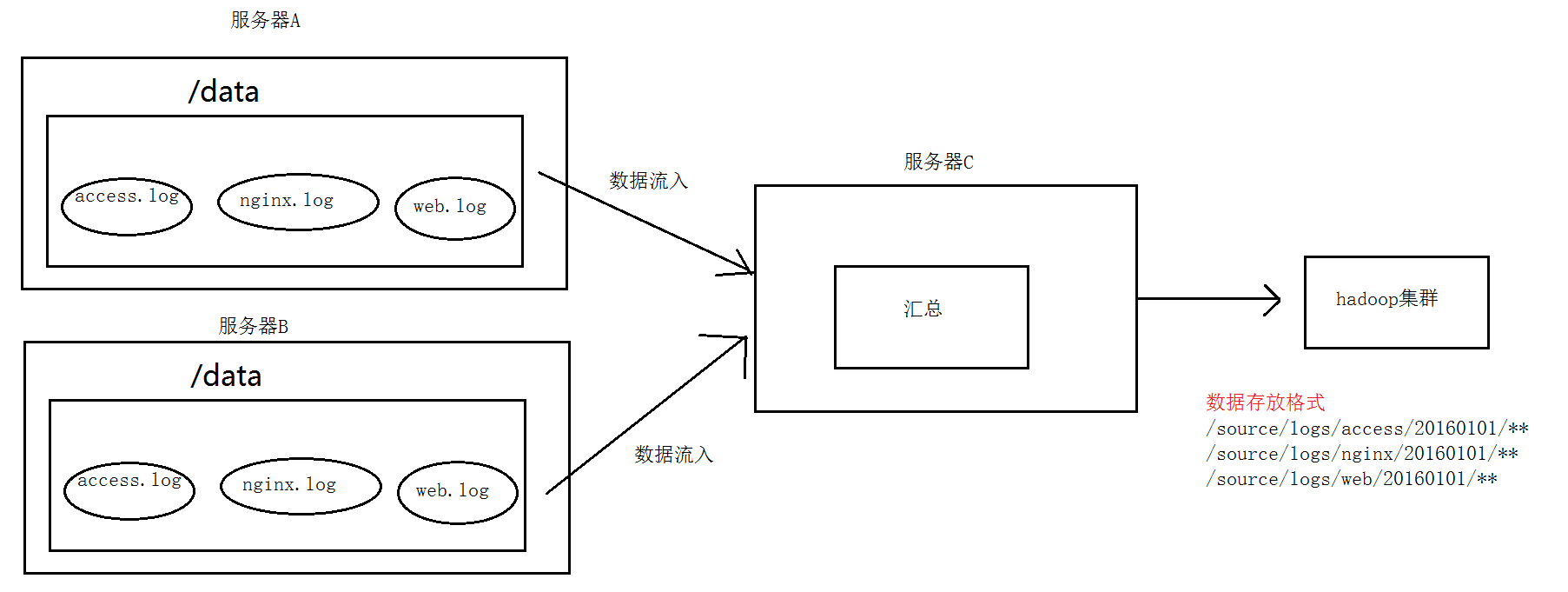
A、B两台日志服务机器实时生产日志主要类型为access.log、nginx.log、web.log
现在要求:
把A、B 机器中的access.log、nginx.log、web.log 采集汇总到C机器上然后统一收集到hdfs中。
但是在hdfs中要求的目录为:
/source/logs/access/20160101/**
/source/logs/nginx/20160101/**
/source/logs/web/20160101/**
2. 场景分析
3. 数据流程处理分析
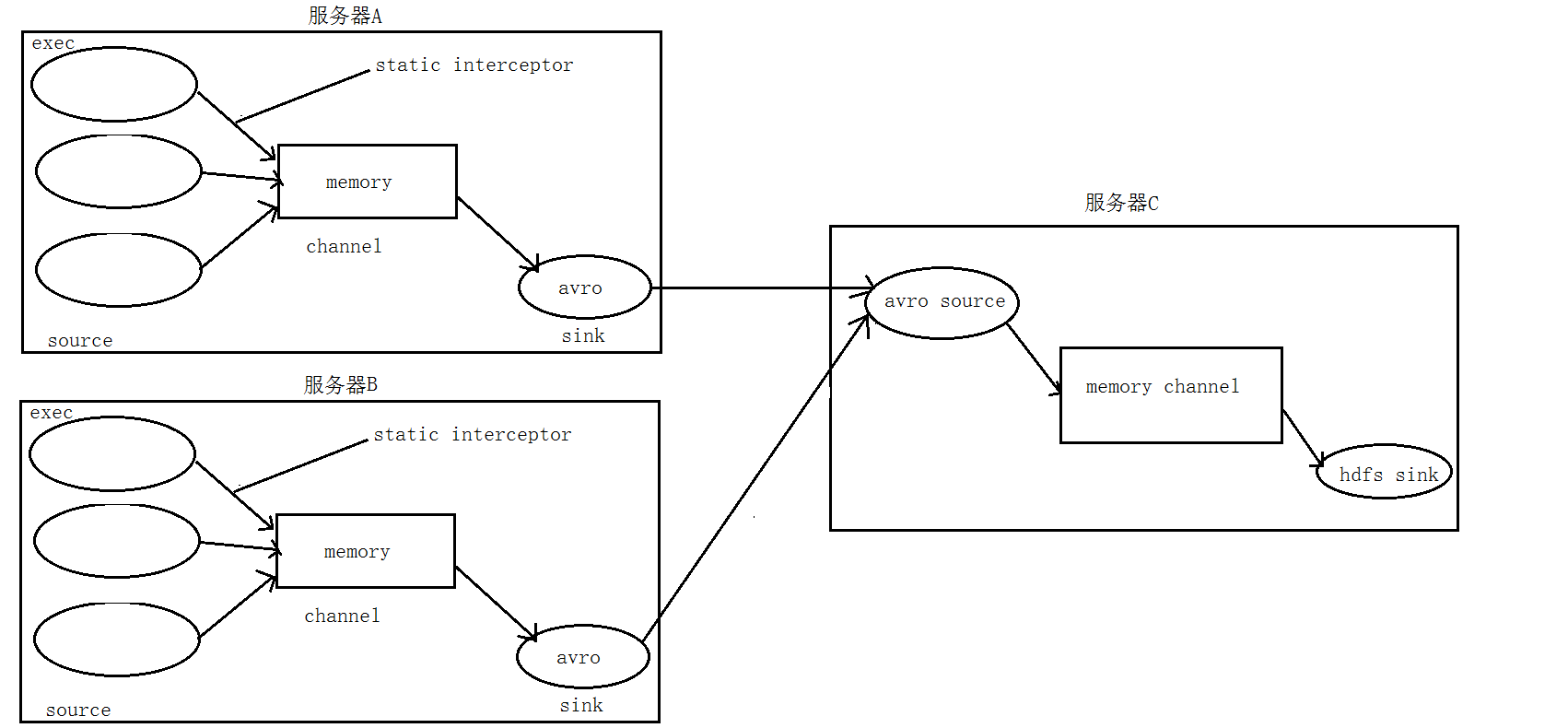
4. 实现
服务器A对应的IP为 192.168.200.102
服务器B对应的IP为 192.168.200.103
服务器C对应的IP为 192.168.200.101
① 在服务器A和服务器B上的$FLUME_HOME/conf 创建配置文件 exec_source_avro_sink.conf 文件内容为
exec_source_avro_sink.conf 文件内容为 # Name the components on this agent
a1.sources = r1 r2 r3
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/data/access.log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
## static拦截器的功能就是往采集到的数据的header中插入自己定## 义的key-value对
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = access a1.sources.r2.type = exec
a1.sources.r2.command = tail -F /root/data/nginx.log
a1.sources.r2.interceptors = i2
a1.sources.r2.interceptors.i2.type = static
a1.sources.r2.interceptors.i2.key = type
a1.sources.r2.interceptors.i2.value = nginx a1.sources.r3.type = exec
a1.sources.r3.command = tail -F /root/data/web.log
a1.sources.r3.interceptors = i3
a1.sources.r3.interceptors.i3.type = static
a1.sources.r3.interceptors.i3.key = type
a1.sources.r3.interceptors.i3.value = web # Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.200.101
a1.sinks.k1.port = # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sources.r2.channels = c1
a1.sources.r3.channels = c1
a1.sinks.k1.channel = c1
② 在服务器C上的$FLUME_HOME/conf 创建配置文件 avro_source_hdfs_sink.conf 文件内容为
#定义agent名, source、channel、sink的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1 #定义source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = #添加时间拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder #定义channels
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = #定义sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path=hdfs://192.168.200.101:9000/source/logs/%{type}/%Y%m%d
a1.sinks.k1.hdfs.filePrefix =events
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
#时间类型
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件不按条数生成
a1.sinks.k1.hdfs.rollCount =
#生成的文件按时间生成
a1.sinks.k1.hdfs.rollInterval =
#生成的文件按大小生成
a1.sinks.k1.hdfs.rollSize =
#批量写入hdfs的个数
a1.sinks.k1.hdfs.batchSize =
flume操作hdfs的线程数(包括新建,写入等)
a1.sinks.k1.hdfs.threadsPoolSize=
#操作hdfs超时时间
a1.sinks.k1.hdfs.callTimeout= #组装source、channel、sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
③ 配置完成之后,在服务器A和B上的/root/data有数据文件access.log、nginx.log、web.log。先启动服务器C上的flume,启动命令
在flume安装目录下执行 :
bin/flume-ng agent -c conf -f conf/avro_source_hdfs_sink.conf -name a1 -Dflume.root.logger=DEBUG,console
然后在启动服务器上的A和B,启动命令
在flume安装目录下执行 :
bin/flume-ng agent -c conf -f conf/exec_source_avro_sink.conf -name a1 -Dflume.root.logger=DEBUG,console
5. 项目实现截图


大数据学习——flume日志分类采集汇总的更多相关文章
- 大数据学习——flume拦截器
flume 拦截器(interceptor)1.flume拦截器介绍拦截器是简单的插件式组件,设置在source和channel之间.source接收到的事件event,在写入channel之前,拦截 ...
- 大数据学习——flume安装部署
1.Flume的安装非常简单,只需要解压即可,当然,前提是已有hadoop环境 上传安装包到数据源所在节点上 然后解压 tar -zxvf apache-flume-1.6.0-bin.tar.gz ...
- 大数据学习路线,来qun里分享干货,
一.Linux lucene: 全文检索引擎的架构 solr: 基于lucene的全文搜索服务器,实现了可配置.可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面. 推荐一个大数据学习群 ...
- 大数据学习系列之—HBASE
hadoop生态系统 zookeeper负责协调 hbase必须依赖zookeeper flume 日志工具 sqoop 负责 hdfs dbms 数据转换 数据到关系型数据库转换 大数据学习群119 ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 大数据(9) - Flume的安装与使用
Flume简介 --(实时抽取数据的工具) 1) Flume提供一个分布式的,可靠的,对大数据量的日志进行高效收集.聚集.移动的服务,Flume只能在Unix环境下运行. 2) Flume基于流式架构 ...
- 大数据学习day31------spark11-------1. Redis的安装和启动,2 redis客户端 3.Redis的数据类型 4. kafka(安装和常用命令)5.kafka java客户端
1. Redis Redis是目前一个非常优秀的key-value存储系统(内存的NoSQL数据库).和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
随机推荐
- DataGridView 绑定List<>数据的更新
使用BindingSource做为中间数据源,使用 bindingSource1.DataSource = productOrderList;dataGridView1.DataSource = bi ...
- K-th Number 线段树的区间第K大
http://poj.org/problem?id=2104 由于这题的时间限制不紧,所以用线段树水一水. 每个节点保存的是一个数组. 就是对应区间排好序的数组. 建树的时间复杂度需要nlogn 然后 ...
- Super Mario 树状数组离线 || 线段树
Super Mario Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total ...
- 生产环境中配置的samba
实验需求: 由于实验室纳新一帮新孩子,搭建samba主要是临时共享一些学习资源的,基本上大家用的都是windows.而且这个服务可以让他们在校园的里的个个角落都可以访问到,所以给挂了学校的公网,不过我 ...
- 使用预定义的action值启动系统应用
1.启动浏览器 Intent intent = new Intent(); intent.setAction(Intent.ACTION_WEB_SEARCH); //可以传一个搜索关键字,会直接显示 ...
- fedora kde桌面系统配置
本文向大家分享个人将fedora操作系统作为工作生活首选桌面系统的一些配置经验,系统版本与fedora最新版本保持一致,当前为fedora 25. #添加rpm源su -c 'dnf install ...
- ubuntu 下service php5-fpm restart 报错 stop: Unknown instance: 解决
问题描述: 在安装完扩展后,重启php-fpm,发现一直停止报错 stop: Unknown instance: 通过查看进程,也查询不到该主进程 解决办法: 干掉现在正在执行的进程 pkill ph ...
- Qt窗口-仅显示关闭按钮
环境: Qt5.3.1, mac os x 10.10.1 setWindowFlags(Qt::Window | Qt::WindowTitleHint | Qt::CustomizeWindowH ...
- web页面调用IOS的事件
/** * js 调用ios的方法 * @param callback */ function connectWebViewJavascriptBridge(callback) { if (windo ...
- 如何处理Docker的错误消息request canceled:Docker代理问题
在本地安装Kubernetes时,遇到错误消息: request canceled while waiting for connection(Client.Timeout exceeded while ...