Python爬虫:抓取手机APP的数据
摘要
大多数APP里面返回的是json格式数据,或者一堆加密过的数据 。这里以超级课程表APP为例,抓取超级课程表里用户发的话题。
1.抓取APP数据包
表单:

表单中包括了用户名和密码,当然都是加密过了的,还有一个设备信息,直接post过去就是。
另外必须加header,一开始我没有加header得到的是登录错误,所以要带上header信息。
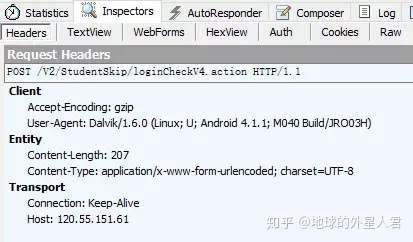
3.登录
登录代码:
import urllib2
from cookielib import CookieJar
loginUrl = 'http://120.55.151.61/V2/StudentSkip/loginCheckV4.action' headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Dalvik/1.6.0 (Linux; U; Android 4.1.1; M040 Build/JRO03H)',
'Host': '120.55.151.61',
'Connection': 'Keep-Alive',
'Accept-Encoding': 'gzip',
'Content-Length': '207',
}
loginData = 'phoneBrand=Meizu&platform=1&deviceCode=868033014919494&account=FCF030E1F2F6341C1C93BE5BBC422A3D&phoneVersion=16&password=A55B48BB75C79200379D82A18C5F47D6&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&'
cookieJar = CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookieJar))
req = urllib2.Request(loginUrl, loginData, headers)
loginResult = opener.open(req).read()
print loginResult
登录成功 会返回一串账号信息的json数据

和抓包时返回数据一样,证明登录成功
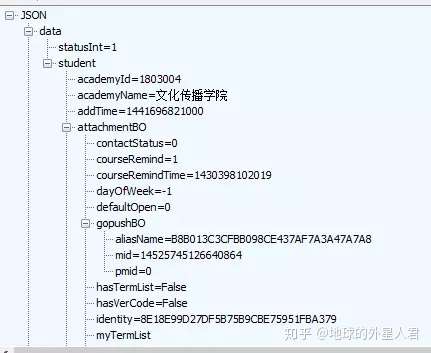
3.抓取数据
用同样方法得到话题的url和post参数
做法就和模拟登录网站一样。
下见最终代码,有主页获取和下拉加载更新。可以无限加载话题内容。
#!/usr/local/bin/python2.7 # -*- coding: utf8 -*- """
超级课程表话题抓取
""" import urllib2
from cookielib import CookieJar
import json
''' 读Json数据 ''' def fetch_data(json_data):
data = json_data['data']
timestampLong = data['timestampLong']
messageBO = data['messageBOs']
topicList = []
for each in messageBO:
topicDict = {}
if each.get('content', False):
topicDict['content'] = each['content']
topicDict['schoolName'] = each['schoolName']
topicDict['messageId'] = each['messageId']
topicDict['gender'] = each['studentBO']['gender']
topicDict['time'] = each['issueTime']
print each['schoolName'],each['content']
topicList.append(topicDict)
return timestampLong, topicList
''' 加载更多 ''' def load(timestamp, headers, url):
headers['Content-Length'] = '159'
loadData = 'timestamp=%s&phoneBrand=Meizu&platform=1&genderType=-1&topicId=19&phoneVersion=16&selectType=3&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&' % timestamp
req = urllib2.Request(url, loadData, headers)
loadResult = opener.open(req).read()
loginStatus = json.loads(loadResult).get('status', False)
if loginStatus == 1:
print 'load successful!'
timestamp, topicList = fetch_data(json.loads(loadResult))
load(timestamp, headers, url)
else:
print 'load fail'
print loadResult
return False loginUrl = 'http://120.55.151.61/V2/StudentSkip/loginCheckV4.action' topicUrl = 'http://120.55.151.61/V2/Treehole/Message/getMessageByTopicIdV3.action' headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Dalvik/1.6.0 (Linux; U; Android 4.1.1; M040 Build/JRO03H)',
'Host': '120.55.151.61',
'Connection': 'Keep-Alive',
'Accept-Encoding': 'gzip',
'Content-Length': '207',
}
''' ---登录部分--- '''
loginData = 'phoneBrand=Meizu&platform=1&deviceCode=868033014919494&account=FCF030E1F2F6341C1C93BE5BBC422A3D&phoneVersion=16&password=A55B48BB75C79200379D82A18C5F47D6&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&'
cookieJar = CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookieJar))
req = urllib2.Request(loginUrl, loginData, headers)
loginResult = opener.open(req).read()
loginStatus = json.loads(loginResult).get('data', False)
if loginResult:
print 'login successful!' else:
print 'login fail'
print loginResult
''' ---获取话题--- '''
topicData = 'timestamp=0&phoneBrand=Meizu&platform=1&genderType=-1&topicId=19&phoneVersion=16&selectType=3&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&'
headers['Content-Length'] = '147'
topicRequest = urllib2.Request(topicUrl, topicData, headers)
topicHtml = opener.open(topicRequest).read()
topicJson = json.loads(topicHtml)
topicStatus = topicJson.get('status', False)
print topicJson
if topicStatus == 1:
print 'fetch topic success!'
timestamp, topicList = fetch_data(topicJson)
load(timestamp, headers, topicUrl)
结果:

你想更深入了解学习Python知识体系,你可以看一下我们花费了一个多月整理了上百小时的几百个知识点体系内容:
【超全整理】《Python自动化全能开发从入门到精通》python基础教程笔记
Python爬虫:抓取手机APP的数据的更多相关文章
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- Fiddler抓取手机APP程序数据包
1.下载并安装Fiddler 下载地址:https://www.telerik.com/download/fiddler 2.设置Fiddler可监听远程通讯 前提条件:需要监听的手机和Fiddler ...
- Python3爬虫:利用Fidder抓取手机APP的数据
1.什么是Fiddler? Fiddler是一个http协议调试代理工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,设置断点,查看所有的“进出”Fiddler的数据(指cookie,ht ...
- Fiddler高级用法-抓取手机app数据包
在上一篇中介绍了Fiddler的基本使用方法.通过上一篇的操作我们可以直接抓取浏览器的数据包.但在APP测试中,我们需要抓取手机APP上的数据包,应该怎么操作呢? Andriod配置方法 1)确保手机 ...
- 使用Fiddler抓取手机APP数据包--360WIFI
使用Fiddler抓取手机APP流量--360WIFI 操作步骤:1.打开Fiddler,Tools-Fiddler Options-Connections,勾选Allow remote comput ...
- python 爬虫抓取心得
quanwei9958 转自 python 爬虫抓取心得分享 urllib.quote('要编码的字符串') 如果你要在url请求里面放入中文,对相应的中文进行编码的话,可以用: urllib.quo ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- jmeter旅程第一站:Jmeter抓包浏览器或者抓取手机app的包
学习jmeter?从实际出发,我也是一个初学者,会优先考虑先用来做一些简单的抓包.接口测试,在实践的过程中学习jmeter用途.那么接下来,这篇文章我会以jmeter抓包开启我的jmeter旅程. 这 ...
- Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据 1.豆瓣地址:https://movie.douban.com/top250?start=25&filter= 2.主要流程是抓取该网址下的Top25 ...
随机推荐
- Android 4.4.2 动态加入JNI库方法记录 (一 JNI库层)
欢迎转载,务必注明出处.http://blog.csdn.net/wang_shuai_ww/article/details/44456755 本篇是继<s5p4418 Android 4.4. ...
- (七)Java 变量类型
Java 变量类型 在Java语言中,所有的变量在使用前必须声明.声明变量的基本格式如下: type identifier [ = value][, identifier [= value] ...] ...
- gradle使用笔记
1 gradle user home 默认情况下是-/.gradle目录.可以使用gradle -g [directory]修改. 1.1 ./gradle/caches gradle下载的所有的依赖 ...
- java8新特性-方法引用
方法引用:若 Lambda 体中的功能,已经有方法提供了实现,可以使用方法引用 (可以将方法引用理解为 Lambda 表达式的另外一种表现形式) 1. 对象的引用 :: 实例方法名2. 类名 :: 静 ...
- HQL 查询数据 (获取页面输入的查询条件字段)
/* * 查询提取位置表所有数据 * */ public String ListEtlExtractPositionOfAll(){ // 接受数据库中传送的code int code = Integ ...
- 洛谷 P1570【NOIP2013】花匠
题目描述 花匠栋栋种了一排花,每株花都有自己的高度.花儿越长越大,也越来越挤.栋栋决定 把这排中的一部分花移走,将剩下的留在原地,使得剩下的花能有空间长大,同时,栋栋希 望剩下的花排列得比较别致. 具 ...
- [NOI2018]冒泡排序
https://www.zybuluo.com/ysner/note/1261482 题面 戳我 \(8pts\ n\leq9\) \(44pts\ n\leq18\) \(ex12pts\ q_i= ...
- POJ1743 Musical Theme 最长重复子串 利用后缀数组
POJ1743 题目意思是求不重叠的最长相同变化的子串,输出该长度 比如1 2 3 4 5 6 7 8 9 10,最长长度为5,因为子串1 2 3 4 5 和 6 7 8 9 10变化都一样的 思路: ...
- 0626-TP整理二(调试模式,空操作,跨控制器调用,跨方法跳转--redirect(),框架语法,创建model模型)
一.调试模式(入口文件:index.php) define('APP_DEBUG', true); //调试模式 define('APP_DEBUG', FALSE); //运行模式 开启日志信息 ...
- [App Store Connect帮助]六、测试 Beta 版本(4.2) 管理 Beta 版构建版本:查看构建版本状态和指标
必要职能:“帐户持有人”职能.“管理”职能.“App 管理”职能.“开发者”职能或“营销”职能.请参见职能权限. 在首页上,点按“我的 App”,选择您的 App,然后在工具栏中点按“TestFlig ...