【转】Spark:Master High Availability(HA)高可用配置的2种实现
原博文出自于: 感谢!
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障的问题。如何解决这个单点故障的问题,Spark提供了两种方案:
- 基于文件系统的单点恢复(Single-Node Recovery with Local File System)
- 基于zookeeper的Standby Masters(Standby Masters with ZooKeeper) (企业里,一般用在这个)
ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个是Active的,其他的都是Standby。当Active的Master出现故障时,另外的一个Standby Master会被选举出来。由于集群的信息,包括Worker, Driver和Application的信息都已经持久化到文件系统,因此在切换的过程中只会影响新Job的提交,对于正在进行的Job没有任何的影响。加入ZooKeeper的集群整体架构如下图所示。

本文的测试是在Spark0.9.0 Standalone ,同样适用于Spark1.0.0 Standalone 以上版本。
1.基于文件系统的单点恢复
主要用于开发或测试环境。当spark提供目录保存spark Application和worker的注册信息,并将他们的恢复状态写入该目录中,这时,一旦Master发生故障,就可以通过重新启动Master进程(sbin/start-master.sh),恢复已运行的spark Application和worker的注册信息。
基于文件系统的单点恢复,主要是在spark-env里对SPARK_DAEMON_JAVA_OPTS设置:
| System property | Meaning |
|---|---|
spark.deploy.recoveryMode |
Set to FILESYSTEM to enable single-node recovery mode (default: NONE).(设成FILESYSTEM , 缺省值为NONE) |
spark.deploy.recoveryDirectory |
The directory in which Spark will store recovery state, accessible from the Master's perspective.(Spark 保存恢复状态的目录) |
可以考虑使用NFS的共享目录来保存Spark恢复状态。
1.1配置
[root@bigdata001 spark]# vi conf/spark-env.sh
添加property
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/nfs/spark/recovery"
1.2测试
1.启动Spark Standalone集群:[root@bigdata001 spark]# ./sbin/start-all.sh
2.启动一个spark-shell客户端并做部分操作后,然后用sbin/stop-master.sh杀死Master进程
[root@bigdata003 spark]# MASTER=spark://bigdata001:7077 bin/spark-shell
[root@bigdata001 spark]# ./sbin/stop-master.sh
3.测试结果:可以在bigdata003看到information,连接不上master。
14/08/26 13:54:01 WARN AppClient$ClientActor: Connection to akka.tcp://sparkMaster@bigdata001:7077 failed; waiting for master to reconnect...
14/08/26 13:54:01 WARN SparkDeploySchedulerBackend: Disconnected from Spark cluster! Waiting for reconnection...
14/08/26 13:54:01 WARN AppClient$ClientActor: Connection to akka.tcp://sparkMaster@bigdata001:7077 failed; waiting for master to reconnect...
14/08/26 13:54:01 WARN AppClient$ClientActor: Could not connect to akka.tcp://sparkMaster@bigdata001:7077: akka.remote.EndpointAssociationException: Association failed with [akka.tcp://sparkMaster@bigdata001:7077]
4.重新启动一下master,可以恢复正常:
[root@bigdata001 spark]# ./sbin/start-master.sh
2.Standby Masters with ZooKeeper
用于生产模式。其基本原理是通过zookeeper来选举一个Master,其他的Master处于Standby状态。
将Standalone集群连接到同一个ZooKeeper实例并启动多个Master,利用zookeeper提供的选举和状态保存功能,可以使一个Master被选举,而其他Master处于Standby状态。如果现任Master死去,另一个Master会通过选举产生,并恢复到旧的Master状态,然后恢复调度。整个恢复过程可能要1-2分钟。
注意:
- 这个过程只会影响新Application的调度,对于在故障期间已经运行的 application不会受到影响。
- 因为涉及到多个Master,所以对于应用程序的提交就有了一点变化,因为应用程序需要知道当前的Master的IP地址和端口。这种HA方案处理这种情况很简单,只需要在SparkContext指向一个Master列表就可以了,如spark://host1:port1,host2:port2,host3:port3,应用程序会轮询列表。
该HA方案使用起来很简单,首先启动一个ZooKeeper集群,然后在不同节点上启动Master,注意这些节点需要具有相同的zookeeper配置(ZooKeeper URL 和目录)。
| System property | Meaning |
|---|---|
spark.deploy.recoveryMode |
Set to ZOOKEEPER to enable standby Master recovery mode (default: NONE). |
spark.deploy.zookeeper.url |
The ZooKeeper cluster url (e.g., 192.168.1.100:2181,192.168.1.101:2181). |
spark.deploy.zookeeper.dir |
The directory in ZooKeeper to store recovery state (default: /spark). |
Master可以在任何时候添加或移除。如果发生故障切换,新的Master将联系所有以前注册的Application和Worker告知Master的改变。
注意:不能将Master定义在conf/spark-env.sh里了,而是直接在Application中定义。涉及的参数是 export SPARK_MASTER_IP=bigdata001,这项不配置或者为空。否则,无法启动多个master。
比如,我这里。




export JAVA_HOME=/usr/local/jdk/jdk1.8.0_60
export SCALA_HOME=/usr/local/scala/scala-2.10.4
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.6.0
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-2.6.0/etc/hadoop
export SPARK_MASTER_IP=SparkMaster
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MERMORY=1g
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_HOME=/usr/local/spark/spark-1.5.2-bin-hadoop2.6
export SPARK_JAR=/usr/local/spark/spark-1.5.2-bin-hadoop2.6/lib/spark-assembly-1.5.2-hadoop2.6.0.jar
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin





现在得去安装zookeeper,三台都要,经验起见,只需在SparkMaster安装即可,然后分发给SparkWorker1和SparkWorker2。
这里的安装步骤省略。


dataDir=/usr/local/data/zookeeper/zkdata
dataLogDir=/usr/local/data/zookeeper/zkdatalog
#server.
server.1=SparkMaster:2888:3888
server.2=SparkWorker1:2888:3888
server.3=SparkWorker2:2888:3888






现在呢,我把SparkMaster的Master杀死掉,然后,我在SparkWorker1启动Master。


root@SparkWorker1:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/sbin# ./start-master.sh



2.1 配置
[root@bigdata001 spark]# vi conf/spark-env.sh
添加Property
#ZK HA
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=bigdata001:2181,bigdata002:2181,bi
gdata003:2181 -Dspark.deploy.zookeeper.dir=/spark"
2.2 测试
1.前提:zookeeper集群已经启动。
2.关闭集群后,重新启动spark集群:
[root@bigdata001 spark]# ./sbin/stop-all.sh
[root@bigdata001 spark]# ./sbin/start-all.sh
3.在另一个节点上,启动新的master:[root@bigdata002 spark]# ./sbin/start-master.sh
4.查看Web UI:http://bigdata001:8081/
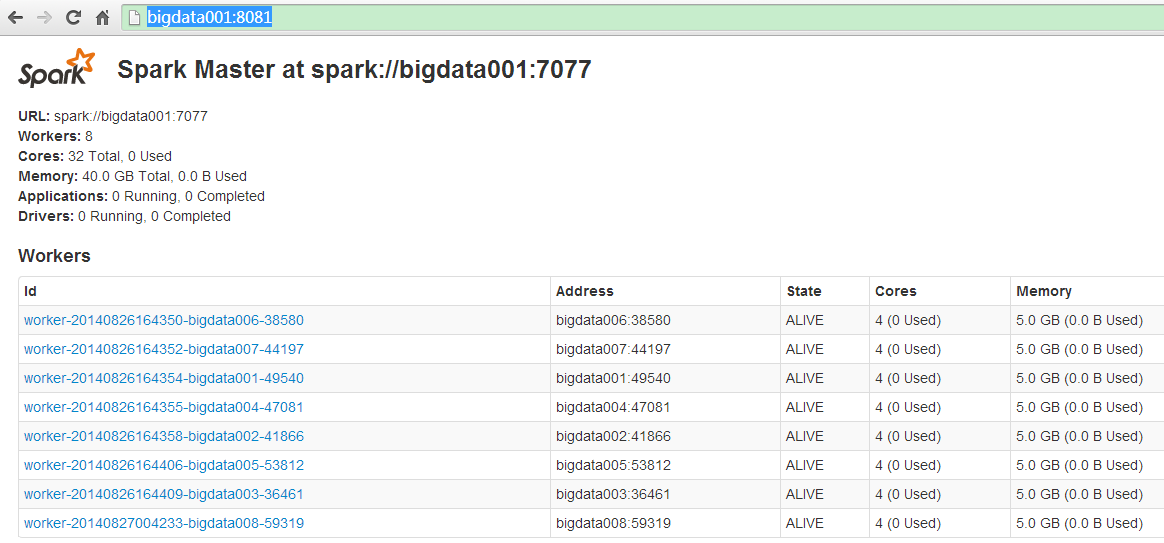
5.启动一个spark-shell客户端:[root@bigdata003 spark]# MASTER=spark://bigdata001:7077,bigdata002:7077 bin/spark-shell

MASTER is spark://bigdata001:7077,bigdata002:7077=-====
-----------------------/home/zjw/tachyon/tachyon-0.4.1/target/tachyon-0.4.1-jar-with-dependencies.jar:/home/zjw/tachyon/tachyon-0.4.1/target/tachyon-0.4.1-jar-with-dependencies.jar:/home/zjw/tachyon/tachyon-0.4.1/target/tachyon-0.4.1-jar-with-dependencies.jar:/home/zjw/tachyon/tachyon-0.4.1/target/tachyon-0.4.1-jar-with-dependencies.jar::/src/java/target/mesos-0.19.0.jar:/src/java/target/mesos-0.19.0.jar:/root/spark/conf:/root/spark/assembly/target/scala-2.10/spark-assembly-0.9.0-incubating-hadoop2.2.0.jar
*********RUNNER=/home/zjw/jdk1.7/jdk1.7.0_51//bin/java
*********CLASSPATH=/home/zjw/tachyon/tachyon-0.4.1/target/tachyon-0.4.1-jar-with-dependencies.jar:/home/zjw/tachyon/tachyon-0.4.1/target/tachyon-0.4.1-jar-with-dependencies.jar:/home/zjw/tachyon/tachyon-0.4.1/target/tachyon-0.4.1-jar-with-dependencies.jar:/home/zjw/tachyon/tachyon-0.4.1/target/tachyon-0.4.1-jar-with-dependencies.jar::/src/java/target/mesos-0.19.0.jar:/src/java/target/mesos-0.19.0.jar:/root/spark/conf:/root/spark/assembly/target/scala-2.10/spark-assembly-0.9.0-incubating-hadoop2.2.0.jar
*********JAVA_OPTS=-Dspark.executor.uri=hdfs://192.168.1.101:8020/user/spark/spark-0.9.2.tar.gz -Dspark.akka.frameSize=20 -Djava.library.path= -Xms512m -Xmx512m
6.停掉正在service的Master:[root@bigdata001 spark]# ./sbin/stop-master.sh
spark-shell输出如下信息:用sbin/stop-master.sh杀死bigdata001 的Master进程,这时saprk-shell花费了30秒左右的时候切换到bigdata002 上的Master了。
14/08/26 13:54:01 WARN AppClient$ClientActor: Connection to akka.tcp://sparkMaster@bigdata001:7077 failed; waiting for master to reconnect...
14/08/26 13:54:01 WARN SparkDeploySchedulerBackend: Disconnected from Spark cluster! Waiting for reconnection...
14/08/26 13:54:01 WARN AppClient$ClientActor: Connection to akka.tcp://sparkMaster@bigdata001:7077 failed; waiting for master to reconnect...
14/08/26 13:54:01 WARN AppClient$ClientActor: Could not connect to akka.tcp://sparkMaster@bigdata001:7077: akka.remote.EndpointAssociationException: Association failed with [akka.tcp://sparkMaster@bigdata001:7077]
14/08/26 13:54:01 WARN AppClient$ClientActor: Connection to akka.tcp://sparkMaster@bigdata001:7077 failed; waiting for master to reconnect...
14/08/26 13:54:01 WARN AppClient$ClientActor: Could not connect to akka.tcp://sparkMaster@bigdata001:7077: akka.remote.EndpointAssociationException: Association failed with [akka.tcp://sparkMaster@bigdata001:7077]
14/08/26 13:54:01 WARN AppClient$ClientActor: Connection to akka.tcp://sparkMaster@bigdata001:7077 failed; waiting for master to reconnect...
14/08/26 13:54:01 WARN AppClient$ClientActor: Could not connect to akka.tcp://sparkMaster@bigdata001:7077: akka.remote.EndpointAssociationException: Association failed with [akka.tcp://sparkMaster@bigdata001:7077]
14/08/26 13:54:01 WARN AppClient$ClientActor: Connection to akka.tcp://sparkMaster@bigdata001:7077 failed; waiting for master to reconnect...
14/08/26 13:54:30 INFO AppClient$ClientActor: Master has changed, new master is at spark://bigdata002:7077
7.查看UI监控器,这是Active Master是bigdata002。正在运行的Application资源没发生变化。
http://bigdata002:8082/
设计理念
为了解决Standalone模式下的Master的SPOF,Spark采用了ZooKeeper提供的选举功能。Spark并没有采用ZooKeeper原生的Java API,而是采用了Curator,一个对ZooKeeper进行了封装的框架。采用了Curator后,Spark不用管理与ZooKeeper的连接,这些对于Spark来说都是透明的。Spark仅仅使用了100行代码,就实现了Master的HA。
进阶源码学习:Spark技术内幕:Master基于ZooKeeper的High Availability(HA)源码实现
参考资料:
http://www.cnblogs.com/hseagle/p/3673147.html
https://spark.apache.org/docs/0.9.0/spark-standalone.html#standby-masters-with-zookeeper
【转】Spark:Master High Availability(HA)高可用配置的2种实现的更多相关文章
- Spark:Master High Availability(HA)高可用配置的2种实现
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障的问题.如何解决这个单点故障的问题,Spar ...
- hadoop2.5.0 HA高可用配置
hadoop2.5.0 HA配置 1.修改hadoop中的配置文件 进入/usr/local/src/hadoop-2.5.0-cdh5.3.6/etc/hadoop目录,修改hadoop-env.s ...
- HA高可用配置
HA 即 (high available)高可用,又被叫做双机热备,用于关键性业务. 简单理解就是,有两台机器A和B,正常是A提供服务,B待命闲置,当A宕机或服务宕掉,会切换至B机器继续提供服务. 下 ...
- 【阿圆实验】Alertmanager HA 高可用配置
注意:没有使用supervisor进程管理器的,只参考配置,忽略和supervisor相关命令.并且alertmanager的版本不得低于0.15.2,低版本alert不支持集群配置. 一.alert ...
- CentOS7+Hadoop2.7.2(HA高可用+Federation联邦)+Hive1.2.1+Spark2.1.0 完全分布式集群安装
1 2 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 2.9.1 2.9.2 2.9.2.1 2.9.2.2 2.9.3 2.9.3.1 2.9.3.2 2.9.3.3 2. ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Spark入门:第2节 Spark集群安装:1 - 3;第3节 Spark HA高可用部署:1 - 2
三. Spark集群安装 3.1 下载spark安装包 下载地址spark官网:http://spark.apache.org/downloads.html 这里我们使用 spark-2.1.3-bi ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- Kubeadm 1.9 HA 高可用集群本地离线镜像部署【已验证】
k8s介绍 k8s 发展速度很快,目前很多大的公司容器集群都基于该项目,如京东,腾讯,滴滴,瓜子二手车,易宝支付,北森等等. kubernetes1.9版本发布2017年12月15日,每三个月一个迭代 ...
随机推荐
- Mysql入门实战中
前面一章主要解说了mysql的入门学习.包括数据库,表的管理,以及对数据的增删改,本章主要介绍mysql最重要的语句select的使用方法.将select的大部分使用方法进行分别解说. 全部代码下载( ...
- CentOS 7加强安全性:
CentOS 7加强安全性:1. 更改 root 密码************************************************************************* ...
- CentOS 7最小安装后,手动连接网络
时间:2015-12-12 00:53来源:blog.51cto.com 作者:XD 举报 点击:3679次 CentOS中最小安装,由于默认的网卡没有激活,所以无法连接到网络. 设置如下: sucd ...
- android/java经常使用的工具类源代码
anroid.java经常使用的工具类源代码,当中包含文件操作.MD5算法.文件操作.字符串操作.调试信息log.base64等等. 下载地址:http://download.csdn.net/det ...
- LintCode 近期公共祖先
中等 近期公共祖先 查看执行结果 34% 通过 给定一棵二叉树,找到两个节点的近期公共父节点(LCA). 近期公共祖先是两个节点的公共的祖先节点且具有最大深度. 您在真实的面试中是否遇到过这个题? Y ...
- Android studio 插件之 GsonFormat (自己主动生成javabean)
概述 相信大家在做开发的过程中都写过非常多的javabean ,非常多情况下 都是一个列表数据就是一个单独的javabean.假设大家自己敲的话费时费力 还非常easy敲错. 今天给大家推荐一个插件 ...
- SpringMVC DispatcherServlet初始化过程
先来上一张类的结构图: 图里仅仅画了跟初始化相关的方法. 首先DispatcherServlet也是一个Servlet,初始化从init()方法開始. 以下就详细看看ini()是怎么实现的吧. 1.S ...
- MySql command line client 命令系列
—————————————————————————————————————————————————————————— 一.启动与退出 1.进入MySQL:启动MySQL Command Line Cl ...
- Chrome插件(扩展)
[干货]Chrome插件(扩展)开发全攻略 写在前面 我花了将近一个多月的时间断断续续写下这篇博文,并精心写下完整demo,写博客的辛苦大家懂的,所以转载务必保留出处.本文所有涉及到的大部分代码均 ...
- hdu1863
#include<cstdio> #include<algorithm> using namespace std; int N,M; struct edge { int u,v ...