elasticsearch学习笔记-倒排索引以及中文分词
我们使用数据库的时候,如果查询条件太复杂,则会涉及到很多问题
1、无法维护,各种嵌套查询,各种复杂的查询,想要优化都无从下手
2、效率低下,一般语句复杂了之后,比如使用or,like %,,%查询之后数据库的索引就没有办法利用到了,这个时候的搜索就会全表扫描,数据量少的时候可能性能还能接受,但是数据量大了之后性能会直线下降,速度慢的一塌胡萝卜。。
但是呢,数据库的聚集索引查询还是极快的,
所以我们可以利用这一点尝试建立一下这样的索引结构--就是把数据库里面的每一条记录作为一个键,相同记录的Id的集合作为值,这样我们查询记录的时候就可以通过记录快速定位到数据表的id,从而就可以快速查询到这条数据了如图所示

如果要搜索咪咪虾条的话,就可以带出这些value值,我们都知道key-value的查询是非常快的,所以这个耗时会很短,然后通过id来查询就会使得效率高出很多,这个思路可以用在所有字段上,但是对空间的使用会多一些,不过存储这东东还是蛮便宜的,毕竟体验才是最重要的对吧,这种就叫基本的倒排索引。
但是如果用户只搜索咪咪呢,如何能够定位到这条咪咪虾条的记录呢?
这里就涉及到了另一项比较重要的技术--中文分词
这里简要说明下中文分词:
中文分词里面有个东西必不可少,就是词库
假设我们的词库很简单,就这么几条词:1、咪咪,2、虾,3、虾条
这个时候,我们存入一条咪咪虾条,id是10000的记录的时候呢
分词就会这么干,先读第一个字,咪,然后发现没有单个的这个词,但是有一个咪咪,然后就会读取第二个字,第二个字还是咪,这个时候咪咪是一个词,然后读取第三个字,虾,发现虾是单个的一个字,词典里也有这个字,咪虾不存在,咪咪虾更加不存在,那么咪咪这个词就确定了,继续往下读,发现条,然后发现虾是一个词语,虾条也是一个词语,而现在已经读完了,所以现在分词有两种组合,虾和条,虾条,显然第一条有点扯淡,条不能作为一个词,所以就取后者,这样虾条这个词就出来了。
接着我们存入一条咪咪id 为10002的数据的时候,方法同上
然后存到搜索引擎的数据的就是这样
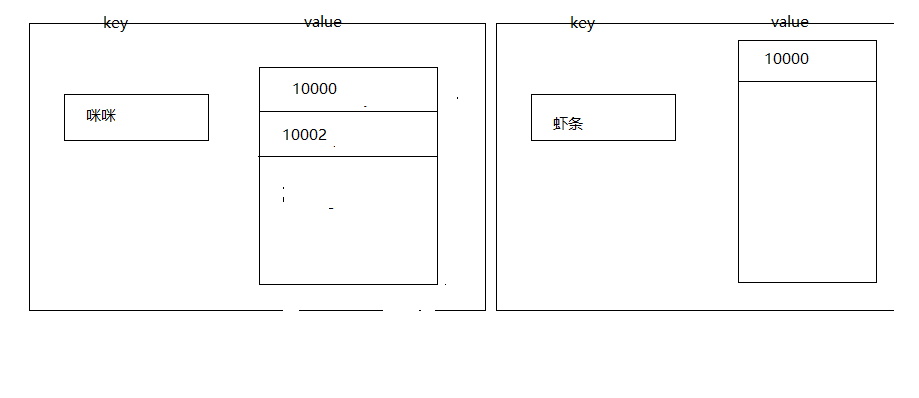
这个时候就有两条记录,咪咪对应的有两条记录,虾条对应一条
如果我们搜索虾条的话,10000就会被搜索出来,如果搜索咪咪的话,那10002和10000就会被搜索出来
如果我们搜索咪咪虾条的话,就会按照上面的分词逻辑将我们的搜索条件进行分词,然后分出来咪咪和虾条两个词,然后查询,再merge最终得到两个id:10000,10002
分词这块就我所理解也就这样了。
说了这么多,具体怎么做呢?其实很简单,一个插件就搞定,我用的是IK分词插件,安装简单,地址在这里,里面也有安装说明,安装完之后重启下就ok了
https://github.com/medcl/elasticsearch-analysis-ik
中文分词插件
目前就这么多,本人也是刚学这个,写的有什么问题欢迎指出,谢谢~
elasticsearch学习笔记-倒排索引以及中文分词的更多相关文章
- solr学习笔记-增加mmesg4J中文分词
solr版本6.1.centos6.7.mmesg4j版本2.30 solr安装目录:/usr/local/solr-6.1.0 1.下载mmesg4j包: 地址:https://github.com ...
- ElasticSearch学习笔记(超详细)
文章目录 初识ElasticSearch 什么是ElasticSearch ElasticSearch特点 ElasticSearch用途 ElasticSearch底层实现 ElasticSearc ...
- elasticsearch学习笔记——相关插件和使用场景
logstash-input-jdbc学习 ES(elasticsearch缩写)的一大优点就是开源,插件众多.所以扩展起来非常的方便,这也造成了它的生态系统越来越强大.这种开源分享的思想真是与天朝格 ...
- Elasticsearch学习笔记一
Elasticsearch Elasticsearch(以下简称ES)是一款Java语言开发的基于Lucene的高效全文搜索引擎.它提供了一个分布式多用户能力的基于RESTful web接口的全文搜索 ...
- Elasticsearch笔记六之中文分词器及自定义分词器
中文分词器 在lunix下执行下列命令,可以看到本来应该按照中文"北京大学"来查询结果es将其分拆为"北","京","大" ...
- ElasticSearch学习笔记(一)-- 查询索引分词
# 查看所有索引 GET _cat/indices # 创建一个索引 PUT /test_index # 插入一条数据(指定id)PUT /test_index/doc/ { "userna ...
- elasticsearch学习笔记001
<Elasticsearch 核心技术与实战>课程Github代码 https://github.com/onebirdrocks/geektime-ELK 运行的环境: windows ...
- 【转】Elasticsearch学习笔记
一.常用术语 索引(Index).类型(Type).文档(Document) 索引Index是含有相同属性的文档集合.索引在ES中是通过一个名字来识别的,且必须是英文字母小写,且不含中划线(-):可类 ...
- Elasticsearch学习笔记三
PS:前面两章已经介绍了ES的基础及REST API,本文主要介绍ES常用的插件安装及使用. Elasticsearch-Head Head是一个用于管理Elasticsearch的web前端插件,该 ...
随机推荐
- 2016/3/16 45道MySQL 查询练习题
一. 设有一数据库,包括四个表:学生表(Student).课程表(Course).成绩表(Score)以及教师信息表(Teacher).四个表的结构分别如表1-1的表(一)~表( ...
- 设计模式-(17)策略模式 (swift版)
一,概念: 策略模式定义了一系列的算法,并将每一个算法封装起来,而且使他们可以相互替换,让算法独立于使用它的客户而独立变化. 二,使用场景 1.针对同一类型问题的多种处理方式,仅仅是具体行为有差别时: ...
- casperjs userAgent的一些问题
casperjs 的options内的userAgent若设置为非正常浏览器的字符串,可能导致form无法正确提交. 表现为,this.click()失效,或evaluate(function(){$ ...
- 什么是以太坊私钥储存(Keystore)文件
进入keystore管理以太坊私钥的障碍很大,主要是因为以太坊客户端在直接的命令行或图形界面下隐藏了大部分的密码复杂性. 例如,用geth: $ geth account new Your new a ...
- 数据库sqlite3的使用-代码实例应用
一.使用代码的方式批量添加(导入)数据到数据库中 1.执行SQL语句在数据库中添加一条信息 插入一条数据的sql语句: 点击run执行语句之后,刷新数据 2.在ios项目中使用代码批量添加多行数据 ...
- bzoj 3232 圈地游戏 —— 01分数规划+最小割建图(最大权闭合子图)
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=3232 心烦意乱的时候调这道题真是...越调越气,就这样过了一晚上... 今天再认真看看,找出 ...
- IJ:IJ来了2-调试开发环境
ylbtech-IJ:IJ来了2 1.返回顶部 1. 2. 3. 4. 2. 配置SVN返回顶部 1.SVN安装时,要选上command line client tools 2. 3. 4. 3. ...
- UI:数据的解析XML与JSON
XML 和 JSON 语言 本篇博客来自互联网参考 XML 和 JSON 的互相转化 有属性的转化为对象,无属性的转化为字符串 节点的顺序性不可逆,XML有顺序,JSON 无顺序 XML 和 J ...
- 【黑金教程笔记之001】veriloghdl 扫盲文—笔记&勘误
001_veriloghdl 扫盲文—笔记&勘误 2014/10/31 原文作者:akuei2 联系方式:blog.ednchina.con/akuei2 勘误001: Page 3 0.1 ...
- 版本控制系统Git
常用的版本控制系统有VSS.SVN.CVS等等,Git是最近几年使用得比较多的分布式版本控制系统,存在即合理,Git的出现总有它出现的理由,以前的版本控制系统肯定有一些不足的地方,所以才出现了Git. ...