【TIDB】2、TIDB进阶
0、TIDB优势
1、和MySql相比,具备OLAP能力。省去了很多数据仓库搭建成本和学习成本。这在业务层是非常受欢迎的。可以在其他分库分表业务中,通过 syncer 同步,进行合并,然后进行统计分析
2、数据量增长极快的OLTP场景,这些数据库的数据在一年内轻松达到数百亿量级。TiDB 的所有特性都非常契合这种海量高并发的 OLTP 场景。
3、弥补单机容量上限,支持水平扩展,无限扩容存储
4、传统 Sharding 方案查询维度单一,TIDB支持多维度查询
5、支持在线 DDL 这个特性特别适合这些业务,有需要业务更改不会阻塞业务,业务快速迭代比较需要
6、在MySQL上要分库分表,但是又需要分布式事务的业务。支持分布式事务
7、支持读写QPS需要弹性扩容、缩容的业务
1、语言技术栈
SQL层和调度层为Go,KV层Rust,引擎C++
2、协议兼容性
兼容80% MySQL协议
3、分布式时序
全局单点授时服务
4、分布式事务的支持
无论是一个地方的几个节点,还是跨多个数据中心的多个节点,TiDB 均支持 ACID 分布式事务。
TiDB 事务模型灵感源自 Google Percolator 模型,主体是一个两阶段提交协议,并进行了一些实用的优化。该模型依赖于一个时间戳分配器,为每个事务分配单调递增的时间戳,这样就检测到事务冲突。在 TiDB 集群中,PD 承担时间戳分配器的角色。
TiKV 的事务采用乐观锁,事务的执行过程中,不会检测写写冲突,只有在提交过程中,才会做冲突检测,冲突的双方中比较早完成提交的会写入成功,另一方会尝试重新执行整个事务。当业务的写入冲突不严重的情况下,这种模型性能会很好,比如随机更新表中某一行的数据,并且表很大。但是如果业务的写入冲突严重,性能就会很差,举一个极端的例子,就是计数器,多个客户端同时修改少量行,导致冲突严重的,造成大量的无效重试
5、并发控制
乐观锁
6、一致性
强一致的raft
7、存储
7.1、TiKV 没有选择直接向磁盘上写数据,而是把数据保存在 RocksDB 中,具体的数据落地由 RocksDB 负责。这个选择的原因是开发一个单机存储引擎工作量很大,特别是要做一个高性能的单机引擎,需要做各种细致的优化,而 RocksDB 是一个非常优秀的开源的单机存储引擎,可以满足我们对单机引擎的各种要求,而且还有 Facebook 的团队在做持续的优化
7.2、Raft协议保证存储的高可用
Raft 是一个一致性协议,提供几个重要的功能:
- Leader 选举
- 成员变更
- 日志复制
TiKV 利用 Raft 来做数据复制,每个数据变更都会落地为一条 Raft 日志,通过 Raft 的日志复制功能,将数据安全可靠地同步到 Group 的多数节点中。
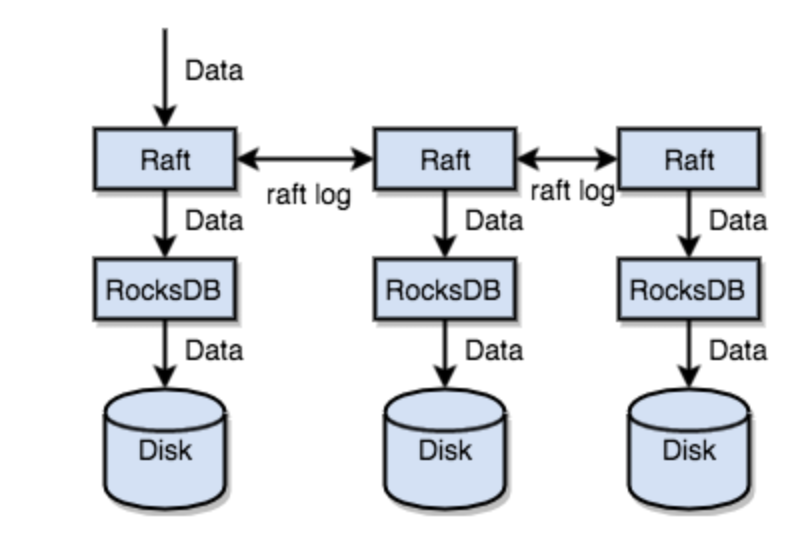
通过单机的 RocksDB,我们可以将数据快速地存储在磁盘上;通过 Raft,我们可以将数据复制到多台机器上,以防单机失效。数据的写入是通过 Raft 这一层的接口写入,而不是直接写 RocksDB。通过实现 Raft,我们拥有了一个分布式的 KV,现在再也不用担心某台机器挂掉了
7.3、存储数据的基本单位:Region
- 以 Region 为单位,将数据分散在集群中所有的节点上,并且尽量保证每个节点上服务的 Region 数量差不多
- 以 Region 为单位做 Raft 的复制和成员管理
7.4、多版本控制(MVCC)
设想这样的场景,两个 Client 同时去修改一个 Key 的 Value,如果没有 MVCC,就需要对数据上锁,在分布式场景下,可能会带来性能以及死锁问题。 TiKV 的 MVCC 实现是通过在 Key 后面添加 Version 来实现
7.5、行存还是列存?
TiDB 面向的首要目标是 OLTP 业务,这类业务需要支持快速地读取、保存、修改、删除一行数据,所以采用行存是比较合适的
8、关系模型到 Key-Value 模型的映射
8.1、一个 Table 内部所有的 Row 都有相同的前缀,一个 Index 的数据也都有相同的前缀。这样具体相同的前缀的数据,在 TiKV 的 Key 空间内,是排列在一起。同时只要我们小心地设计后缀部分的编码方案,保证编码前和编码后的比较关系不变,那么就可以将 Row 或者 Index 数据有序地保存在 TiKV 中
8.2、数据元数据处理(表结构)
一般数据库在进行 DDL 操作时都会锁表,导致线上对此表的 DML 操作全部进入等待状态(有些数据支持读操作,但是也以消耗大量内存为代价),即很多涉及此表的业务都处于阻塞状态,表越大,影响时间越久
TiDB 使用 Google F1 的 Online Schema 变更算法,有一个后台线程在不断的检查 TiKV 上面存储的 Schema 版本是否发生变化,并且保证在一定时间内一定能够获取版本的变化(如果确实发生了变化)。这部分的具体实现参见 TiDB 的异步 schema 变更实现一文。
8.3、分布式sql计算
我们将 Filter 也下推到存储节点进行计算,这样只需要返回有效的行,避免无意义的网络传输。最后,我们可以将聚合函数、GroupBy 也下推到存储节点,进行预聚合,每个节点只需要返回一个 Count 值即可,再由 tidb-server 将 Count 值 Sum 起来
提高计算速度的优化:
- MPP:Massively Parallel Processing,即大规模并行处理。计算数据是分在不同的节点上,并且很可能不在一台机器上,它们通过高速的网络连接,让每个节点都自己去处理数据,处理完数据之后再汇总在一起,最后给用户返回结果。节点之间的计算是相互不知道的,然后他们只执行自己的事情,不需要去交换数据
- SMP:Symmetric Multi-Processor,对称多处理器结构。它是一种 share everything 的架构。每一个共享的环节都可能造成SMP服务器扩展时的瓶颈,而最受限制的则是内存。由于每个CPU必须通过相同的内存总线访问相同的内存资源,因此随着CPU数量的增加,内存访问冲突将迅速增加,最终会造成CPU资源的浪费,使 CPU性能的有效性大大降低
- TiDB:结合MPP和SMP。 SQL layer 是用 Go 来写的,Go 在多核机器上能够发挥并发优势,它的 Goroutine 调度的开销很小,我们可以建很多 Goroutine,利用现在 CPU 越来越多的这个特性,去提高计算的并行度
9、调度模块。PD
整个系统也是在动态变化,Region 分裂、节点加入、节点失效、访问热点变化等情况会不断发生,整个调度系统也需要在动态中不断向最优状态前进,如果没有一个掌握全局信息,可以对全局进行调度,并且可以配置的组件,就很难满足这些需求。因此我们需要一个中心节点,来对系统的整体状况进行把控和调整,所以有了 PD 这个模块
1、信息收集
TiKV 节点(Store)与 PD 之间存在心跳包,一方面 PD 通过心跳包检测每个 Store 是否存活,以及是否有新加入的 Store;还包括以下信息:
- 总磁盘容量
- 可用磁盘容量
- 承载的 Region 数量
- 数据写入速度
- 发送/接受的 Snapshot 数量(Replica 之间可能会通过 Snapshot 同步数据)
- 是否过载
- 标签信息(标签是具备层级关系的一系列 Tag)
每个 Raft Group 的 Leader 和 PD 之间存在心跳包,用于汇报这个 Region 的状态,主要包括下面几点信息:
- Leader 的位置
- Followers 的位置
- 掉线 Replica 的个数
- 数据写入/读取的速度
PD 还可以通过管理接口接受额外的信息,用来做更准确的决策。
2、调度策略
- 一个 Region 的 Replica 数量正确
一个 Raft Group 中的多个 Replica 不在同一个位置
副本在 Store 之间的分布均匀分配。每个副本中存储的数据容量上限是固定的,所以我们维持每个节点上面,副本数量的均衡,会使得总体的负载更均衡。
Leader 数量在 Store 之间均匀分配
访问热点数量在 Store 之间均匀分配
各个 Store 的存储空间占用大致相等
控制调度速度,避免影响在线服务
- 支持手动下线节点
参考资料:
TIDB对Raft 的优化 https://zhuanlan.zhihu.com/p/25735592
https://pingcap.com/blog-cn/tidb-internal-1/
https://pingcap.com/blog-cn/tidb-internal-3/
【TIDB】2、TIDB进阶的更多相关文章
- tidb 架构 ~Tidb学习系列(5)
一 简介:今天我们继续学习tidb的增量传输 二 说明: tidb高度兼容mysql,可以仿照mysql的主从同步复制机制实现mysql->tidb的增量传输 三 实验: 1 下载tidb官方工 ...
- tidb 架构 ~Tidb学习系列(4)
一 简介:今天我们继续学习tidb 二 集群管理 0 集群配置 验证 4台一组 3个kv 一个pd+server 上线 6台一组 1 动态添加kv服务 nohu ...
- tidb 架构 ~Tidb学习系列(3)
tidb集群安装测试1 环境 3台机器2 配置 server1 pd服务+tidb-server server2 tidb-kv server3 tidb-kv3 环境配置命令 ser ...
- tidb 架构 ~Tidb学习系列(2)
一 简介:咱们今天来学习导入数据篇 二 导入数据测试 1 工具 mysqldumper loader 2 下载tidb企业版工具 wget http://download.ping ...
- tidb 架构~tidb 理论学习(1)
一 简介:介绍新型NEW SQL数据库tidb 二 目的: tidb出现的目的,就是代替mysql+中间件,实现横向水平扩展 三 核心理论观点 1 MySQL 是单机数据库,只能通过 XA 来满足跨数 ...
- tidb 架构 ~Tidb学习系列(1)
一 简介:今天来研究Tidb 二 安装测试: 0 下载Tidb wget http://download.pingcap.org/tidb-latest-linux-amd64.tar.gz 按如 ...
- TiDB 5.0认证指南之PCTA PCTP
1. TiDB简介 TiDB 是 PingCAP 公司自主设计.研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analyt ...
- TiDB 作为 MySQL Slave 实现实时数据同步
由于 TiDB 本身兼容绝大多数的 MySQL 语法,所以对于绝大多数业务来说,最安全的切换数据库方式就是将 TiDB 作为现有数据库的从库接在主 MySQL 库的后方,这样对业务方实现完全没有侵入性 ...
- 分布式数据库TiDB的部署
转自:https://my.oschina.net/Kenyon/blog/908370 一.环境 CentOS Linux release 7.3.1611 (Core)172.26.11.91 ...
- TiDB 架构及设计实现
一. TiDB的核心特性 高度兼容 MySQL 大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移. 水平弹性扩展 ...
随机推荐
- sublime text 3(Build 3103)最新注冊码
原来注冊过的sublime text 3近期更新了.没想到原来的注冊码就失效了,只是我找到了最新的注冊码(Build 3103),与大家分享一下(第一个亲測可用). -– BEGIN LICENSE ...
- IOS开发 序列化与反序列化
原帖地址:http://blog.csdn.net/ally_ideveloper/article/details/7956942 不会用,记下自己有时间看 序列化与反序列化概述 序列化,它又称串行化 ...
- 使用Python实现一个简单的项目监控
在公司里做的一个接口系统,主要是对接第三方的系统接口,所以,这个系统里会和很多其他公司的项目交互.随之而来一个很蛋疼的问题,这么多公司的接口,不同公司接口的稳定性差别很大,访问量大的时候,有的不怎么行 ...
- Eclipse中git插件导入远程库和上传项目源代码到远程库
陆陆续续,从github,csdn的code.之前实习的小公司也是用git管理.发如今版本号控制方面确实比較方便.代码一敲完 . 自己由于完毕了新功能.加入一个新分支.然后提交上去,这就是程序猿一天干 ...
- MYSQL将时间格式化
SELECT *,DATE_FORMAT(FROM_UNIXTIME(createtime), "%Y/%m/%d %H:%i:%s") AS dateFormat FROM `I ...
- Linux下通过find命令进行rm文件删除的小技巧
我们常常会通过find命令进行批量操作.如:批量删除旧文件.批量改动.基于时间的文件统计.基于文件大小的文件统计等.在这些操作其中,因为rm删除操作会导致文件夹结构变化,假设要通过find结合r ...
- WebService(2)-XML系列之用Stax操作Xml
源代码下载:链接: http://pan.baidu.com/s/1ntL1a7R password: rwp1 本文主要讲述:利用Stax处理xml文档 一.读取xml 1.基于光标的查找 核心:X ...
- 2016/3/24 ①数据库与php连接 三种输出fetch_row()、fetch_all()、fetch_assoc() ②增删改时判断(布尔型) ③表与表之间的联动 ④下拉菜单 ⑤登陆 三个页面
①数据库与php连接 图表 header("content-type:text/html;charset=utf-8"); //第一种方式: //1,生成连接,连接到数据库上的 ...
- 【bzoj3224】Tyvj 1728 普通平衡树
交了一发pb_ds #include<ext/pb_ds/assoc_container.hpp> #include<algorithm> #include<iostre ...
- C 项目案例实践(1)数据结构之链表(0)
链表是通过一组任意的存储单元来存储线性表中的数据元素的,那么怎样表示出数据元素之间的线性关系呢?为建立数据元素之间的线性关系,对每个数据元素ai,除了存放数据元素的自身信息ai之外,还需要存放和ai一 ...