通过爬虫爬取四川省公共资源交易平台上最近的招标信息 --- URLConnection
通过爬虫爬取公共资源交易平台(四川省)最近的招标信息
一:引入JSON的相关的依赖
<dependency>
<groupId>net.sf.json-lib</groupId>
<artifactId>json-lib</artifactId>
<version>2.4</version>
<classifier>jdk15</classifier>
</dependency>
二:通过请求的url获取URLConnection连接
package com.svse.pachong;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;import org.apache.log4j.Logger;
/**
* 通过请求的url获取URLConnection连接
* @author lenovo
* @date 2019年1月22日
* description:
*/
public class open_url_test {public static Logger logger = Logger.getLogger(open_url_test.class);
public boolean openurl(String url_infor) throws Exception{
URL url = new URL(url_infor);
// 连接类的父类,抽象类
URLConnection urlConnection = url.openConnection();// http的连接类
HttpURLConnection httpURLConnection = (HttpURLConnection) urlConnection;/* 设定请求的方法,默认是GET(对于知识库的附件服务器必须是GET,如果是POST会返回405。
流程附件迁移功能里面必须是POST,有所区分。)*/
httpURLConnection.setRequestMethod("GET");
// 设置字符编码 httpURLConnection.setRequestProperty("Charset", "UTF-8");
// 打开到此 URL引用的资源的通信链接(如果尚未建立这样的连接)。
int code = httpURLConnection.getResponseCode();
System.out.println("code:"+code); //连接成功 200
try {
InputStream inputStream = httpURLConnection.getInputStream();
System.out.println("连接成功");
logger.info("打开"+url_infor+"成功!");
return true;
}catch (Exception exception){
logger.info("打开"+url_infor+"失败!");
return false;
}
}
}
三:通过爬取的url解析想要的数据,并以json的格式返回
package com.svse.pachong;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.nio.charset.Charset;
import net.sf.json.JSONException;
import net.sf.json.JSONObject;/**
* 通过爬取的url解析想要的数据,并以json的格式返回
* @param urlString 需要爬取的网站url路径
* @return 返回json结果的数据
* @throws IOException
* @throws JSONException
*/
public class readData {public static JSONObject readData(String urlString) throws IOException, JSONException{
InputStream is = new URL(urlString).openStream();
try {
BufferedReader rd = new BufferedReader(new InputStreamReader(is, Charset.forName("UTF-8")));
StringBuilder sb = new StringBuilder();
int cp;
while ((cp = rd.read()) != -1) {
sb.append((char) cp);
}
String jsonText = sb.toString();
JSONObject json = JSONObject.fromObject(jsonText);
return json;
} finally {
is.close();
}
}
}
四:爬取入口
package com.svse.pachong;
import java.io.IOException;
import net.sf.json.JSONArray;
import net.sf.json.JSONException;
import net.sf.json.JSONObject;/**
* 爬取的入口
* @author lenovo
* @date 2019年1月22日
* description:
*/
public class Main {static String urlString = "http://www.scggzy.gov.cn/Info/GetInfoListNew?keywords=×=4×Start=×End=&province=&area=&businessType=&informationType=&industryType=&page=1&parm=1534929604640";
@SuppressWarnings("static-access")
public static void main(String[] args) {open_url_test oUrl = new open_url_test();
try {
if (oUrl.openurl(urlString)) {
readData rData = new readData();
JSONObject json = rData.readData(urlString);
JSONObject ob=JSONObject.fromObject(json);String data=ob.get("data").toString(); //JSONObject 转 String
data="["+data.substring(1,data.length()-1)+"]";JSONArray json2=JSONArray.fromObject(data); //String 转 JSONArray
for (int i = 0; i < 10; i++) {
JSONObject jsonObject = (JSONObject) json2.get(i);
System.out.println("--------------------------------------------");
System.out.println("项目: "+jsonObject.get("Title"));
System.out.println("时间: "+jsonObject.get("CreateDateStr"));
System.out.println(jsonObject.get("TableName"));
System.out.println(jsonObject.get("Link"));
System.out.println( jsonObject.get("province") +" "+jsonObject.get("username")+" "+jsonObject.get("businessType")+" "+jsonObject.get("NoticeType"));
}
}else{
System.out.println("解析数据失败!");
}
} catch (JSONException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}}
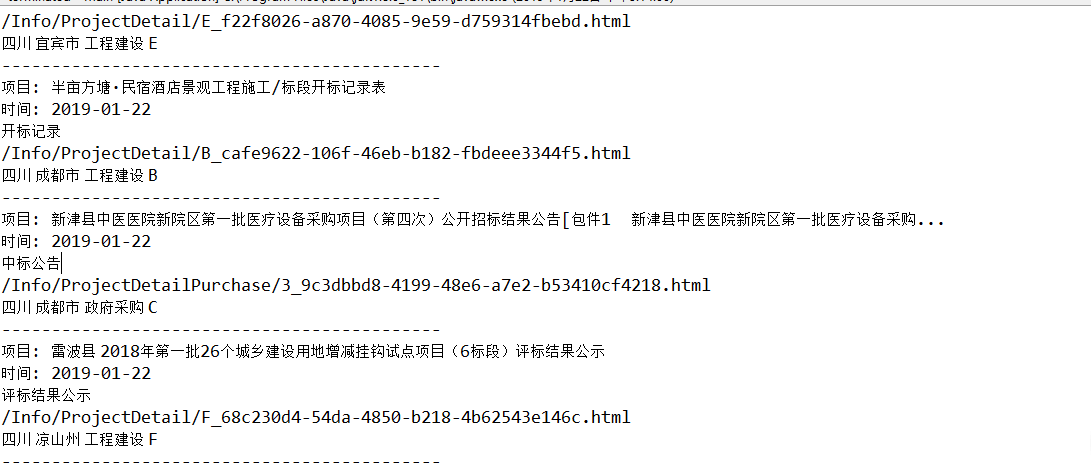
四:测试结果
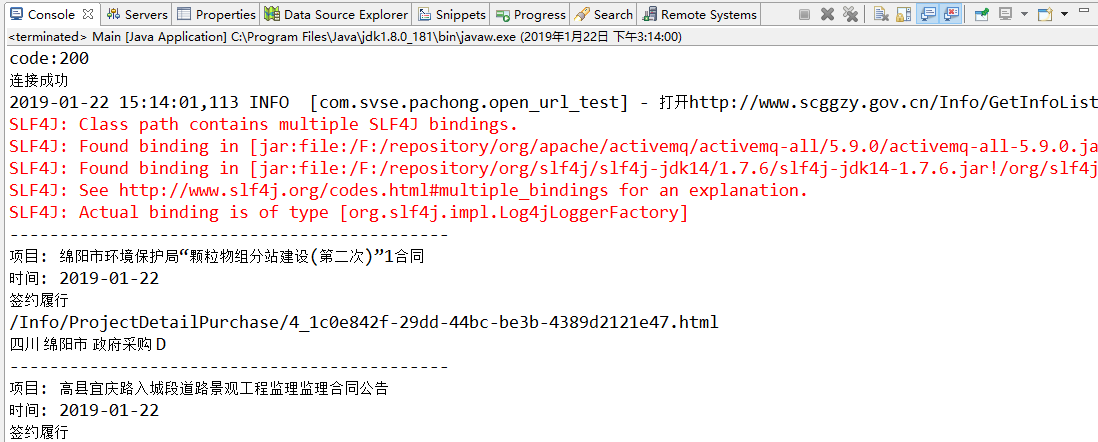

至此,整个爬取的任务就结束了!
通过爬虫爬取四川省公共资源交易平台上最近的招标信息 --- URLConnection的更多相关文章
- python爬虫爬取京东、淘宝、苏宁上华为P20购买评论
爬虫爬取京东.淘宝.苏宁上华为P20购买评论 1.使用软件 Anaconda3 2.代码截图 三个网站代码大同小异,因此只展示一个 3.结果(部分) 京东 淘宝 苏宁 4.分析 这三个网站上的评论数据 ...
- Java爬虫爬取网站电影下载链接
之前有看过一段时间爬虫,了解了爬虫的原理,以及一些实现的方法,本项目完成于半年前,一直放在那里,现在和大家分享出来. 网络爬虫简单的原理就是把程序想象成为一个小虫子,一旦进去了一个大门,这个小虫子就像 ...
- 如何使用robots禁止各大搜索引擎爬虫爬取网站
ps:由于公司网站配置的测试环境被百度爬虫抓取,干扰了线上正常环境的使用,刚好看到每次搜索淘宝时,都会有一句由于robots.txt文件存在限制指令无法提供内容描述,于是便去学习了一波 1.原来一般来 ...
- node:爬虫爬取网页图片
代码地址如下:http://www.demodashi.com/demo/13845.html 前言 周末自己在家闲着没事,刷着微信,玩着手机,发现自己的微信头像该换了,就去网上找了一下头像,看着图片 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 简单的python爬虫--爬取Taobao淘女郎信息
最近在学Python的爬虫,顺便就练习了一下爬取淘宝上的淘女郎信息:手法简单,由于淘宝网站本上做了很多的防爬措施,应此效果不太好! 爬虫的入口:https://mm.taobao.com/json/r ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- python3爬虫爬取网页思路及常见问题(原创)
学习爬虫有一段时间了,对遇到的一些问题进行一下总结. 爬虫流程可大致分为:请求网页(request),获取响应(response),解析(parse),保存(save). 下面分别说下这几个过程中可以 ...
- python网络爬虫(10)分布式爬虫爬取静态数据
目的意义 爬虫应该能够快速高效的完成数据爬取和分析任务.使用多个进程协同完成一个任务,提高了数据爬取的效率. 以百度百科的一条为起点,抓取百度百科2000左右词条数据. 说明 参阅模仿了:https: ...
随机推荐
- hdu4085(斯坦纳树)
题意: 给你n,m,k ,分别表示有n个点,m条边,每条边有一个权值,表示修复这条边需要的代价,从前k个点中任取一个使其和后k个点中的某一个点,通过边连接,并且必须是一一对应,问最小的代价是多少. 分 ...
- codeforces 892E(离散化+可撤销并查集)
题意 给出一个n个点m条边的无向联通图(n,m<=5e5),有q(q<=5e5)个询问 每个询问询问一个边集{Ei},回答这些边能否在同一个最小生成树中 分析 要知道一个性质,就是权值不同 ...
- 从壹开始前后端分离【重要】║最全的部署方案 & 最丰富的错误分析
缘起 哈喽大家好!今天是周一了,这几天趁着午休的时间又读了一本书<偷影子的人>,可以看看
- Python访问MySQL数据库并实现其增删改查功能
概述:对于访问MySQL数据库的操作,我想大家也都有一些了解.不过,因为最近在学习Python,以下就用Python来实现它.其中包括创建数据库和数据表.插入记录.删除记录.修改记录数据.查询数据.删 ...
- 鸟哥的Linux私房菜-----13、账号管理
- mutex 的 可重入
在所有的线程同步方法中,恐怕互斥锁(mutex)的出场率远远高于其它方法.互斥锁的理解和基本使用方法都很容易,这里不做更多介绍了. Mutex可以分为递归锁(recursive mutex)和非递归锁 ...
- Memcache应用场景介绍
面临的问题 对于高并发高訪问的Web应用程序来说,数据库存取瓶颈一直是个令人头疼的问题.特别当你的程序架构还是建立在单数据库模式,而一个数据池连接数峰 值已经达到500的时候,那你的程序执行离崩溃的边 ...
- POI 的使用
POI 使用 一. POI简介 Apache POI是Apache软件基金会的开放源码函式库,POI提供API给Java程序对Microsoft Office格式档案读和写的功能..NET的开发人员则 ...
- I2C上拉电阻取值范围
I2C总线是微电子通信控制领域中常用的一种总线标准,具备接线少,控制简单,速率高等优点.在I2C电路中常见的上拉电阻有1k.1.5k.2.2k.4.7k.5.1k.10k等等,但是应该如何根据开发要求 ...
- 游戏server设计的一些感悟
Author:Echo Chen(陈斌) Email:chenb19870707@gmail.com Blog:Blog.csdn.net/chen19870707 Date:September 30 ...