关联规则&Apriori算法
2017-12-02 14:27:18
一、术语
Items:项,简记I
Transaction:所有项的一个非空子集,简记T

Dataset:Transaction的一个集合,简记D
关联规则:
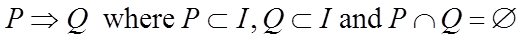
一个Dataset的例子:
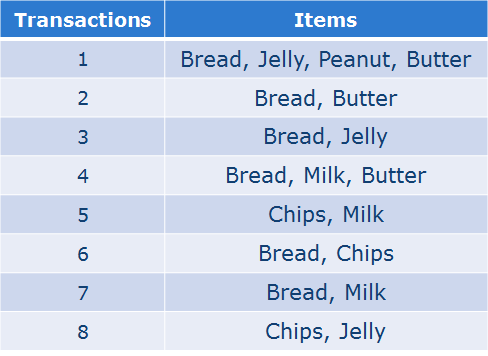
我们的目的就是找到类似买了面包->黄油这样的关联关系。
二、支持度与置信度
- 支持度
支持度就是相应的Item或者ItemSet在Dataset中出现的频率:

比如上图的D中的支持度为:
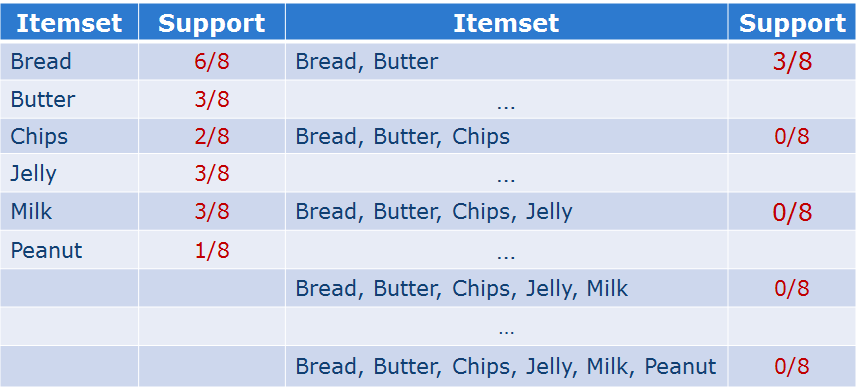
从这个图中我们可以看到一般来说支持度是单调不增的,也就是说,随着商品的增加,支持度是会减小的。
另外,类似X->Y这种购买了X又购买了Y的支持度就是这两者同时购买的频率:
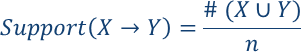
- 置信度
关联规则X->Y的置信度就是T中包含X,Y的交易数目比上单独出现X的交易数目。
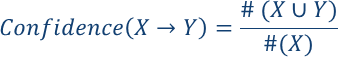
也可以理解为条件概率
 ,
,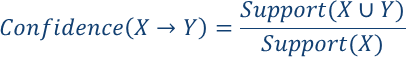
举个例子:

一般来说会给出支持度和置信度的一个下限,也就是规定了支持度和置信度要高于某个阈值才表示当前的规则是有效的:

所以一个关联规则的问题就是:

一个简单的思想就是首先找到所有的频繁项,然后对频繁项中的数据进行排列组合找出其中符合条件的规则。但是这种暴力检索的方式是非常麻烦的,主要问题就是排列组合的过程中的算法的复杂度会达到指数级。
三、Apriori算法
我们必须设法降低产生频繁项集的计算复杂度。此时我们可以利用支持度对候选项集进行剪枝。
Apriori定律1:如果一个集合是频繁项集,则它的所有子集都是频繁项集。
Apriori定律2:如果一个集合不是频繁项集,则它的所有超集都不是频繁项集。
举个例子:
下图表示当我们发现{A,B}是非频繁集时,就代表所有包含它的超级也是非频繁的,即可以将它们都剪除。

算法的具体步骤:

关键的步骤是如何生成Ck+1;

通过上述的算法就可以生成一个Ck+1,算法的步骤是前k-1项相同,第k项不同,将不同的项合并就可以生成一个k+1的C。不过这种算法也会有出错的时候比如:

证明该种生成算法有效的过程如下:

举个例子:

一个更具体的例子如下:



保留了所有的频繁集之后再来进行计算置信度:
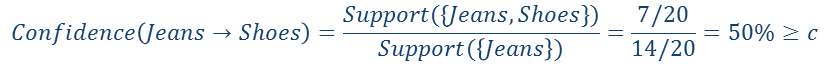
这里需要警惕的是,P(X|Y)<=P(X)的时候,这条关联规则就没有什么作用。
四、序列模式
序列是前后有一定关系的元素的列表。

子序列的概念:

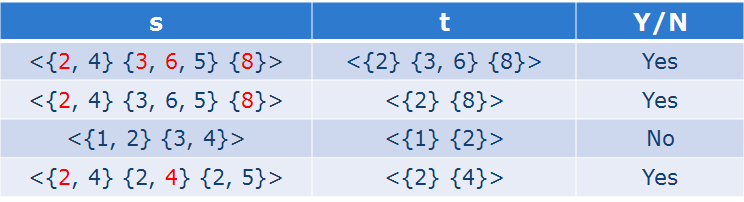
注意,这里的子序列中的前后是有顺序的概念的,也就说,子序列中2在3前面,那么在原序列中也应该是这个顺序。
序列中的支持度:
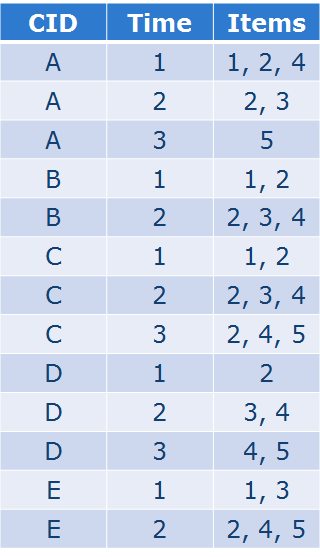
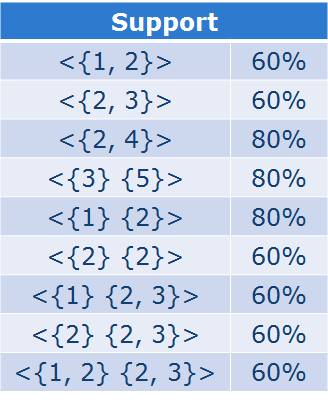
序列的组合要更为复杂:

那么这里就需要一种新的生成算法:

关联规则&Apriori算法的更多相关文章
- Python两步实现关联规则Apriori算法,参考机器学习实战,包括频繁项集的构建以及关联规则的挖掘
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 一步步教你轻松学关联规则Apriori算法
一步步教你轻松学关联规则Apriori算法 (白宁超 2018年10月22日09:51:05) 摘要:先验算法(Apriori Algorithm)是关联规则学习的经典算法之一,常常应用在商业等诸多领 ...
- 详细介绍关联规则Apriori算法及实现
看了很多博客,关于关联规则的介绍想做一个详细的汇总: 一.概念 ...
- python实现简单关联规则Apriori算法
from itertools import combinations from copy import deepcopy # 导入数据,并剔除支持度计数小于min_support的1项集 def lo ...
- 数据挖掘:关联规则的apriori算法在weka的源码分析
相对于机器学习,关联规则的apriori算法更偏向于数据挖掘. 1) 测试文档中调用weka的关联规则apriori算法,如下 try { File file = new File("F:\ ...
- 海量数据挖掘MMDS week2: 频繁项集挖掘 Apriori算法的改进:非hash方法
http://blog.csdn.net/pipisorry/article/details/48914067 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 海量数据挖掘MMDS week2: 频繁项集挖掘 Apriori算法的改进:基于hash的方法
http://blog.csdn.net/pipisorry/article/details/48901217 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 关联规则挖掘之apriori算法
前言: 众所周知,关联规则挖掘是数据挖掘中重要的一部分,如著名的啤酒和尿布的问题.今天要学习的是经典的关联规则挖掘算法--Apriori算法 一.算法的基本原理 由k项频繁集去导出k+1项频繁集. 二 ...
- 关联规则—频繁项集Apriori算法
频繁模式和对应的关联或相关规则在一定程度上刻画了属性条件与类标号之间的有趣联系,因此将关联规则挖掘用于分类也会产生比较好的效果.关联规则就是在给定训练项集上频繁出现的项集与项集之间的一种紧密的联系.其 ...
随机推荐
- PL/SQL常用设置
tools-->preferences-->user interface-->editor-->AutoReplace AutoReplaceWhen enabled, you ...
- 学习认识Spring原理
学习认识Spring原理 Spring 是一种业务层框架.搭建Spring框架需要Spring开发包和commons-logging包.Spring的核心思想是控制反转也称依赖注入(创建者--(实例) ...
- MySQL监控、性能分析——工具篇(转载)
MySQL越来越被更多企业接受,随着企业发展,MySQL存储数据日益膨胀,MySQL的性能分析.监控预警.容量扩展议题越来越多.“工欲善其事,必先利其器”,那么我们如何在进行MySQL性能分析.监控预 ...
- 向Docx4j生成的word文档中添加布局--第二部分
原文标题:Adding layout to your Docx4j-generated word documents, part 2 原文链接:http://blog.iprofs.nl/2012/1 ...
- nginx简介和配置gd
转自:https://www.cnblogs.com/zhouxinfei/p/7862285.html nginx概述 nginx是一款自由的.开源的.高性能的HTTP服务器和反向代理服务器:同时也 ...
- Docker+Jenkins_自动化持续集成环境搭建
前一篇文章里已经在内网环境搭建好docker 详见:https://www.cnblogs.com/befer/p/9107503.html, 现在接着搭建一个Docker+Jenkins的集成环境 ...
- sql server 用脚本管理作业
转自:https://blog.csdn.net/yunye114105/article/details/6594826 摘要: 在SQL SERVER中用脚本管理作业,在绝大部分场景下,脚本都比UI ...
- python 面向对象 公有属性
公有属性定义 公有属性也叫作类变量 静态字段 class role(): # 传参数 # 公有属性都在这里定义 # 在类里直接定义的属性即是公有属性 nationality = 'JP' def ...
- centos单用户 救援 运行级别 yum,单用户模式,救援模式,inittab :启动级别 e2fsck wetty mingetty 物理终端 /dev/console 虚拟终端 /dev/tty(0,6) 模拟终端 /dev/pts/# grub-md5-crypt 给grub加密码 initrd 第二节课
centos单用户 救援 运行级别 yum,单用户模式,救援模式,inittab :启动级别 e2fsck wetty mingetty 物理终端 /dev/console 虚拟终端 /d ...
- PAT 1111 Online Map[Dijkstra][dfs]
1111 Online Map(30 分) Input our current position and a destination, an online map can recommend seve ...