C++解析(28):异常处理
0.目录
1.C语言异常处理
2.C++中的异常处理
3.小结
1.C语言异常处理
异常的概念:
- 程序在运行过程中可能产生异常
- 异常(Exception)与 Bug 的区别
- 异常是程序运行时可预料的执行分支
- Bug 是程序的错误,是不被预期的运行方式
异常(Exception)与 Bug 的对比:
- 异常
- 运行时产生除0的情况
- 需要打开的外部文件不存在
- 数组访问时越界
- Bug
- 使用野指针
- 堆数组使用结束后未释放
- 选择排序无法处理长度为0的数组
异常处理的方式:
C语言经典处理方式:if ... else ...

示例——除法操作异常处理:
#include <iostream>
using namespace std;
double divide(double a, double b, int* valid)
{
const double delta = 0.000000000000001;
double ret = 0;
if( !((-delta < b) && (b < delta)) )
{
ret = a / b;
*valid = 1;
}
else
{
*valid = 0;
}
return ret;
}
int main(int argc, char *argv[])
{
int valid = 0;
double r = divide(1, 0, &valid);
if( valid )
{
cout << "r = " << r << endl;
}
else
{
cout << "Divided by zero..." << endl;
}
return 0;
}
运行结果为:
[root@bogon Desktop]# g++ test.cpp
[root@bogon Desktop]# ./a.out
Divided by zero...
缺陷:
- divide函数有3个参数,难以理解其用法
- divide函数调用后必须判断valid代表的结果
- 当valid为true时,运算结果正常
- 当valid为false时,运算结果出现异常
通过 setjmp() 和 longjmp() 进行优化:
int setjmp(jmp_buf env)- 将当前上下文保存在jmp_buf结构体中
void longjmp(jmp_buf env, int val)- 从jmp_buf结构体中恢复setjmp()保存的上下文
- 最终从setjmp函数调用点返回,返回值为val
示例——除法操作异常处理优化:
#include <iostream>
#include <csetjmp>
using namespace std;
static jmp_buf env;
double divide(double a, double b)
{
const double delta = 0.000000000000001;
double ret = 0;
if( !((-delta < b) && (b < delta)) )
{
ret = a / b;
}
else
{
longjmp(env, 1);
}
return ret;
}
int main(int argc, char *argv[])
{
if( setjmp(env) == 0 )
{
double r = divide(1, 0);
cout << "r = " << r << endl;
}
else
{
cout << "Divided by zero..." << endl;
}
return 0;
}
运行结果为:
[root@bogon Desktop]# g++ test.cpp
[root@bogon Desktop]# ./a.out
Divided by zero...
setjmp() 和 longjmp() 的引入:
- 必然涉及到使用全局变量
- 暴力跳转导致代码可读性降低
- 本质还是if ... else ... 异常处理方式
C语言中的经典异常处理方式会使得程序中逻辑中混入大量的处理异常的代码。
正常逻辑代码和异常处理代码混合在一起,导致代码迅速膨胀,难以维护。。。
示例——异常处理代码分析:
#include <iostream>
using namespace std;
#define SUCCESS 0
#define INVALID_POINTER -1
#define INVALID_LENGTH -2
#define INVALID_PARAMETER -3
int MemSet(void* dest, unsigned int length, unsigned char v)
{
if( dest == NULL )
{
return INVALID_POINTER;
}
if( length < 4 )
{
return INVALID_LENGTH;
}
if( (v < 0) || (v > 9) )
{
return INVALID_PARAMETER;
}
unsigned char* p = (unsigned char*)dest;
for(int i=0; i<length; i++)
{
p[i] = v;
}
return SUCCESS;
}
int main(int argc, char *argv[])
{
int ai[5];
int ret = MemSet(ai, sizeof(ai), 0);
if( ret == SUCCESS )
{
}
else if( ret == INVALID_POINTER )
{
}
else if( ret == INVALID_LENGTH )
{
}
else if( ret == INVALID_PARAMETER )
{
}
return ret;
}
2.C++中的异常处理
C++内置了异常处理的语法元素try ... catch ...:
- try语句处理正常代码逻辑
- catch语句处理异常情况
- try语句中的异常由对应的catch语句处理

C++通过throw语句抛出异常信息:

throw抛出的异常必须被catch处理:
- 当前函数能够处理异常,程序继续往下执行
- 当前函数无法处理异常,则函数停止执行,并返回
未被处理的异常会顺着函数调用栈向上传播,直到被处理为止,否则程序将停止执行。

示例——C++异常处理:
#include <iostream>
using namespace std;
double divide(double a, double b)
{
const double delta = 0.000000000000001;
double ret = 0;
if( !((-delta < b) && (b < delta)) )
{
ret = a / b;
}
else
{
throw 0;
}
return ret;
}
int main(int argc, char *argv[])
{
try
{
double r = divide(1, 0);
cout << "r = " << r << endl;
}
catch(...)
{
cout << "Divided by zero..." << endl;
}
return 0;
}
运行结果为:
[root@bogon Desktop]# g++ test.cpp
[root@bogon Desktop]# ./a.out
Divided by zero...
同一个try语句可以跟上多个catch语句:
- catch语句可以定义具体处理的异常类型
- 不同类型的异常由不同的catch语句负责处理
- try语句中可以抛出任何类型的异常
- catch(...)用于处理所有类型的异常
- 任何异常都只能被捕获(catch)一次
异常处理的匹配规则:
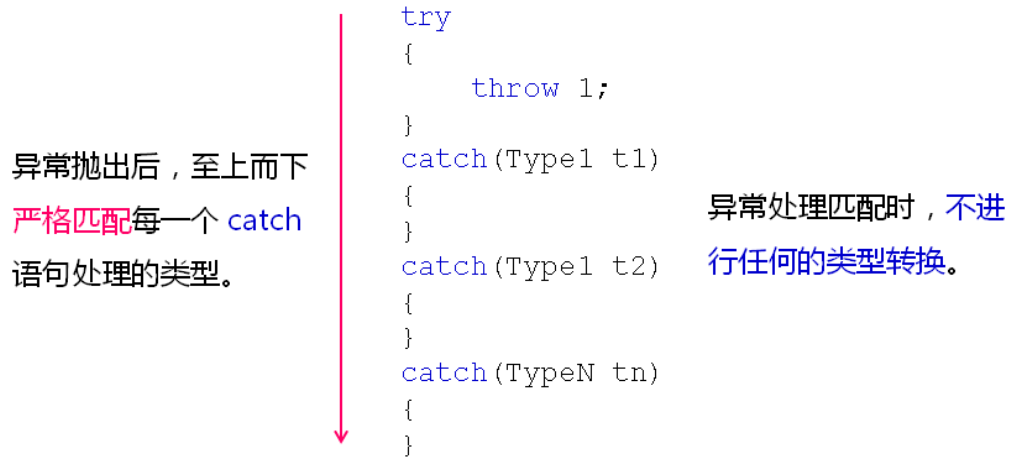
示例——异常类型匹配:
#include <iostream>
using namespace std;
void Demo1()
{
try
{
throw 'c';
}
catch(char c)
{
cout << "catch(char c)" << endl;
}
catch(short c)
{
cout << "catch(short c)" << endl;
}
catch(double c)
{
cout << "catch(double c)" << endl;
}
catch(...)
{
cout << "catch(...)" << endl;
}
}
void Demo2()
{
throw string("HelloWorld!");
}
int main(int argc, char *argv[])
{
Demo1();
try
{
Demo2();
}
catch(char* s)
{
cout << "catch(char *s)" << endl;
}
catch(const char* cs)
{
cout << "catch(const char *cs)" << endl;
}
catch(string ss)
{
cout << "catch(string ss)" << endl;
}
return 0;
}
运行结果为:
[root@bogon Desktop]# g++ test.cpp
[root@bogon Desktop]# ./a.out
catch(char c)
catch(string ss)
catch语句块中可以抛出异常:
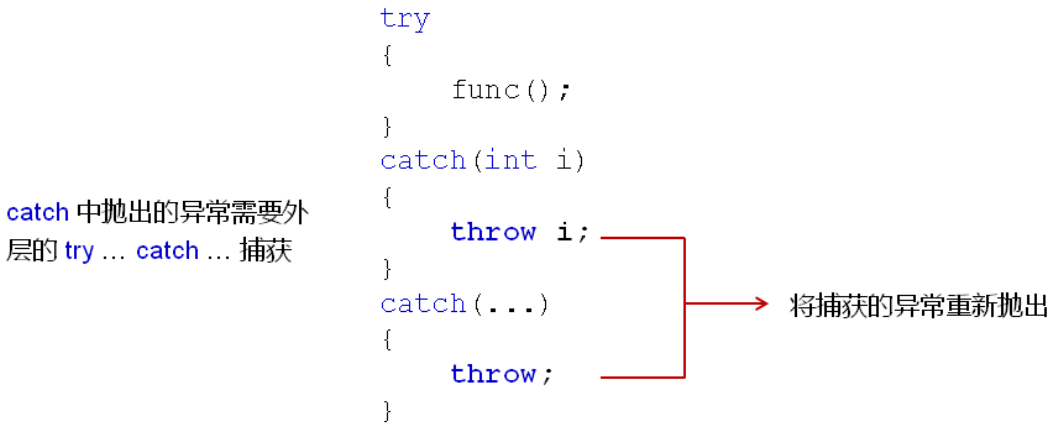
为什么要在catch中重新抛出异常?
- catch中捕获的异常可以被重新解释后抛出
- 工程开发中使用这样的方式统一异常类型
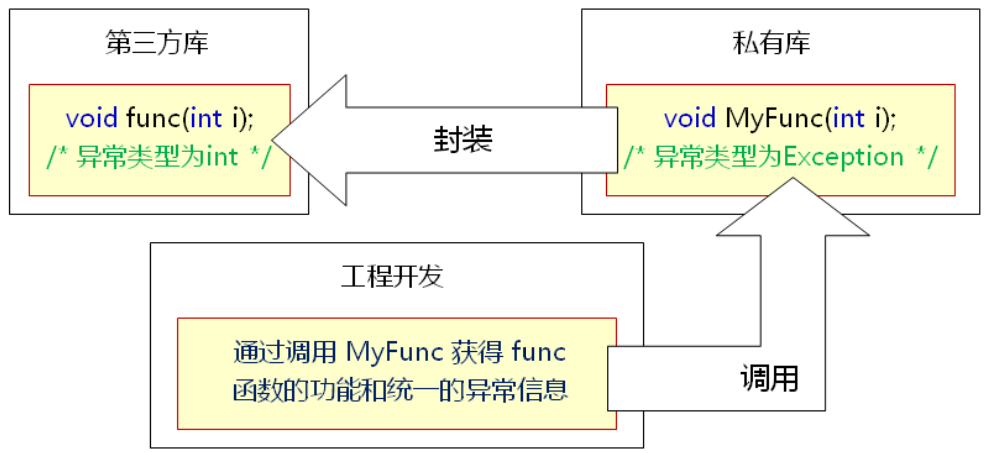
示例——在catch中重新抛出异常:
#include <iostream>
using namespace std;
void Demo()
{
try
{
try
{
throw 'c';
}
catch(int i)
{
cout << "Inner: catch(int i)" << endl;
throw i;
}
catch(...)
{
cout << "Inner: catch(...)" << endl;
throw;
}
}
catch(...)
{
cout << "Outer: catch(...)" << endl;
}
}
int main(int argc, char *argv[])
{
Demo();
return 0;
}
运行结果为:
[root@bogon Desktop]# g++ test.cpp
[root@bogon Desktop]# ./a.out
Inner: catch(...)
Outer: catch(...)
示例——异常的重新解释:
#include <iostream>
using namespace std;
/*
假设: 当前的函数式第三方库中的函数,因此,我们无法修改源代码
函数名: void func(int i)
抛出异常的类型: int
-1 ==》 参数异常
-2 ==》 运行异常
-3 ==》 超时异常
*/
void func(int i)
{
if( i < 0 )
{
throw -1;
}
if( i > 100 )
{
throw -2;
}
if( i == 11 )
{
throw -3;
}
cout << "Run func..." << endl;
}
void MyFunc(int i)
{
try
{
func(i);
}
catch(int i)
{
switch(i)
{
case -1:
throw "Invalid Parameter";
break;
case -2:
throw "Runtime Exception";
break;
case -3:
throw "Timeout Exception";
break;
}
}
}
int main(int argc, char *argv[])
{
try
{
MyFunc(11);
}
catch(const char* cs)
{
cout << "Exception Info: " << cs << endl;
}
return 0;
}
运行结果为:
[root@bogon Desktop]# g++ test.cpp
[root@bogon Desktop]# ./a.out
Exception Info: Timeout Exception
C++中的异常处理:
- 异常的类型可以是自定义类类型
- 对于类类型异常的匹配依旧是至上而下严格匹配
- 赋值兼容性原则在异常匹配中依然适用
- 一般而言
- 匹配子类异常的catch放在上部
- 匹配父类异常的catch放在下部
(根据赋值兼容性原则:子类的异常对象可以被父类的catch语句块抓住。)
C++中的异常处理:
- 在工程中会定义一系列的异常类
- 每个类代表工程中可能出现的一种异常类型
- 代码复用时可能需要重解释不同的异常类
- 在定义catch语句块时推荐使用引用作为参数
示例——类类型的异常:
#include <iostream>
using namespace std;
class Base
{
};
class Exception : public Base
{
int m_id;
string m_desc;
public:
Exception(int id, string desc)
{
m_id = id;
m_desc = desc;
}
int id() const
{
return m_id;
}
string description() const
{
return m_desc;
}
};
/*
假设: 当前的函数式第三方库中的函数,因此,我们无法修改源代码
函数名: void func(int i)
抛出异常的类型: int
-1 ==》 参数异常
-2 ==》 运行异常
-3 ==》 超时异常
*/
void func(int i)
{
if( i < 0 )
{
throw -1;
}
if( i > 100 )
{
throw -2;
}
if( i == 11 )
{
throw -3;
}
cout << "Run func..." << endl;
}
void MyFunc(int i)
{
try
{
func(i);
}
catch(int i)
{
switch(i)
{
case -1:
throw Exception(-1, "Invalid Parameter");
break;
case -2:
throw Exception(-2, "Runtime Exception");
break;
case -3:
throw Exception(-3, "Timeout Exception");
break;
}
}
}
int main(int argc, char *argv[])
{
try
{
MyFunc(11);
}
catch(const Exception& e)
{
cout << "Exception Info: " << endl;
cout << " ID: " << e.id() << endl;
cout << " Description: " << e.description() << endl;
}
catch(const Base& e)
{
cout << "catch(const Base& e)" << endl;
}
return 0;
}
运行结果为:
[root@bogon Desktop]# g++ test.cpp
[root@bogon Desktop]# ./a.out
Exception Info:
ID: -3
Description: Timeout Exception
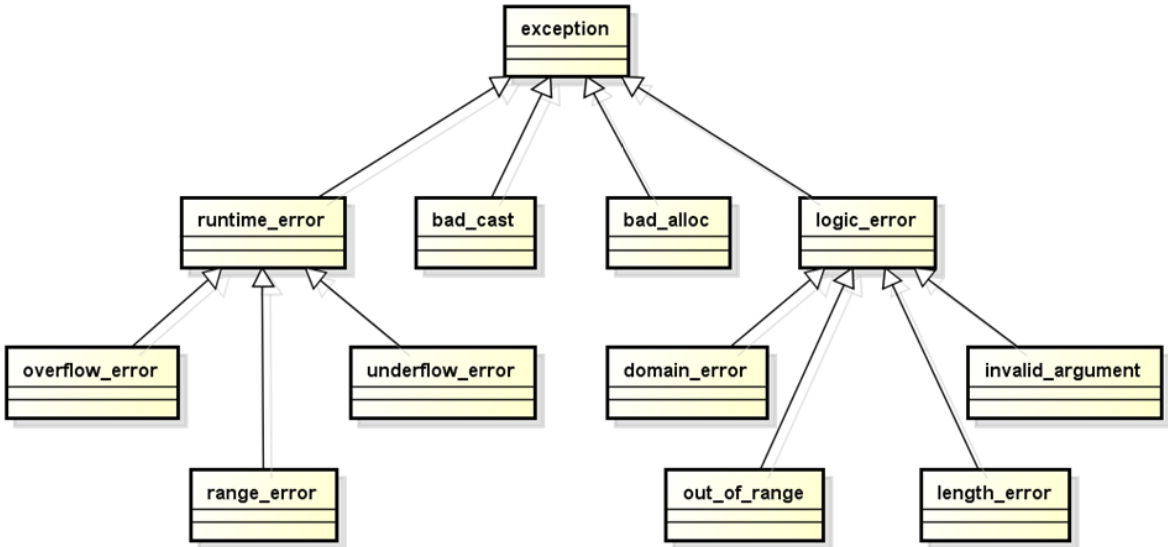
C++中的异常处理:
- C++标准库中提供了实用异常类族
- 标准库中的异常都是从exception类派生的
- exception类有两个主要的分支
- logic_error——常用于程序中的可避免逻辑错误
- runtime_error——常用于程序中无法避免的恶性错误
标准库中的异常:
示例——标准库中的异常使用(优化之前的Array.h和HeapArray.h):
// Array.h
#ifndef _ARRAY_H_
#define _ARRAY_H_
#include <stdexcept>
using namespace std;
template
< typename T, int N >
class Array
{
T m_array[N];
public:
int length() const;
bool set(int index, T value);
bool get(int index, T& value);
T& operator[] (int index);
T operator[] (int index) const;
virtual ~Array();
};
template
< typename T, int N >
int Array<T, N>::length() const
{
return N;
}
template
< typename T, int N >
bool Array<T, N>::set(int index, T value)
{
bool ret = (0 <= index) && (index < N);
if( ret )
{
m_array[index] = value;
}
return ret;
}
template
< typename T, int N >
bool Array<T, N>::get(int index, T& value)
{
bool ret = (0 <= index) && (index < N);
if( ret )
{
value = m_array[index];
}
return ret;
}
template
< typename T, int N >
T& Array<T, N>::operator[] (int index)
{
if( (0 <= index) && (index < N) )
{
return m_array[index];
}
else
{
throw out_of_range("T& Array<T, N>::operator[] (int index)");
}
}
template
< typename T, int N >
T Array<T, N>::operator[] (int index) const
{
if( (0 <= index) && (index < N) )
{
return m_array[index];
}
else
{
throw out_of_range("T Array<T, N>::operator[] (int index) const");
}
}
template
< typename T, int N >
Array<T, N>::~Array()
{
}
#endif
// HeapArray.h
#ifndef _HEAPARRAY_H_
#define _HEAPARRAY_H_
#include <stdexcept>
using namespace std;
template
< typename T >
class HeapArray
{
private:
int m_length;
T* m_pointer;
HeapArray(int len);
HeapArray(const HeapArray<T>& obj);
bool construct();
public:
static HeapArray<T>* NewInstance(int length);
int length() const;
bool get(int index, T& value);
bool set(int index ,T value);
T& operator [] (int index);
T operator [] (int index) const;
HeapArray<T>& self();
const HeapArray<T>& self() const;
~HeapArray();
};
template
< typename T >
HeapArray<T>::HeapArray(int len)
{
m_length = len;
}
template
< typename T >
bool HeapArray<T>::construct()
{
m_pointer = new T[m_length];
return m_pointer != NULL;
}
template
< typename T >
HeapArray<T>* HeapArray<T>::NewInstance(int length)
{
HeapArray<T>* ret = new HeapArray<T>(length);
if( !(ret && ret->construct()) )
{
delete ret;
ret = 0;
}
return ret;
}
template
< typename T >
int HeapArray<T>::length() const
{
return m_length;
}
template
< typename T >
bool HeapArray<T>::get(int index, T& value)
{
bool ret = (0 <= index) && (index < length());
if( ret )
{
value = m_pointer[index];
}
return ret;
}
template
< typename T >
bool HeapArray<T>::set(int index, T value)
{
bool ret = (0 <= index) && (index < length());
if( ret )
{
m_pointer[index] = value;
}
return ret;
}
template
< typename T >
T& HeapArray<T>::operator [] (int index)
{
if( (0 <= index) && (index < length()) )
{
return m_pointer[index];
}
else
{
throw out_of_range("T& HeapArray<T>::operator [] (int index)");
}
}
template
< typename T >
T HeapArray<T>::operator [] (int index) const
{
if( (0 <= index) && (index < length()) )
{
return m_pointer[index];
}
else
{
throw out_of_range("T HeapArray<T>::operator [] (int index) const");
}
}
template
< typename T >
HeapArray<T>& HeapArray<T>::self()
{
return *this;
}
template
< typename T >
const HeapArray<T>& HeapArray<T>::self() const
{
return *this;
}
template
< typename T >
HeapArray<T>::~HeapArray()
{
delete[]m_pointer;
}
#endif
// test.cpp
#include <iostream>
#include "Array.h"
#include "HeapArray.h"
using namespace std;
void TestArray()
{
Array<int, 5> a;
for(int i=0; i<a.length(); i++)
{
a[i] = i;
}
for(int i=0; i<a.length(); i++)
{
cout << a[i] << endl;
}
}
void TestHeapArray()
{
HeapArray<double>* pa = HeapArray<double>::NewInstance(5);
if( pa != NULL )
{
HeapArray<double>& array = pa->self();
for(int i=0; i<array.length(); i++)
{
array[i] = i;
}
for(int i=0; i<array.length(); i++)
{
cout << array[i] << endl;
}
}
delete pa;
}
int main(int argc, char *argv[])
{
try
{
TestArray();
cout << endl;
TestHeapArray();
}
catch(...)
{
cout << "Exception" << endl;
}
return 0;
}
运行结果为:
[root@bogon Desktop]# g++ test.cpp
[root@bogon Desktop]# ./a.out
0
1
2
3
4
0
1
2
3
4
3.小结
- 程序中不可避免的会发生异常
- 异常是在开发阶段就可以预见的运行时问题
- C语言中通过经典的if .... else ... 方式处理异常
- C++中存在更好的异常处理方式
- C++中直接支持异常处理的概念
- try ... catch ... 是C++中异常处理的专用语句
- try语句处理正常代码逻辑,catch语句处理异常情况
- 同一个try语句可以跟上多个catch语句
- 异常处理必须严格匹配,不进行任何的类型转换
- catch语句块中可以抛出异常
- 异常的类型可以是自定义类类型
- 赋值兼容性原则在异常匹配中依然适用
- 标准库中的异常都是从exception类派生的
C++解析(28):异常处理的更多相关文章
- drf框架的解析模块-异常处理模块-响应模块-序列化模块
解析模块 为什么要配置解析模块 (1).drf给我们通过了多种解析数据包方式的解析类. (2).我们可以通过配置来控制前台提交的那些格式的数据台解析,那些数据不解析. (3).全局配置就是针对一个视图 ...
- SpringMVC源码解析 - HandlerMethod
HandlerMethod及子类主要用于封装方法调用相关信息,子类还提供调用,参数准备和返回值处理的职责. 分析下各个类的职责吧(顺便做分析目录): HandlerMethod 封装方法定义相关的信息 ...
- springboot优雅实现异常处理
前言 在平时的 API 开发过程中,总会遇到一些错误异常没有捕捉到的情况.那有的小伙伴可能会想,这还不简单么,我在 API 最外层加一个 try...catch 不就完事了. 哈哈哈,没错.这种方法简 ...
- 2. C/C++笔试面试经典题目二
1. C和C++中struct有什么区别? [参考答案] [解析]C中的struct没有保护行为,没有public,private,protected,内部不能有函数,但可以有函数指针. 2. C++ ...
- java中堆栈(stack)和堆(heap)(还在问静态变量放哪里,局部变量放哪里,静态区在哪里.....进来)
(1)内存分配的策略 按照编译原理的观点,程序运行时的内存分配有三种策略,分别是静态的,栈式的,和堆式的. 静态存储分配是指在编译时就能确定每个数据目标在运行时刻的存储空间需求,因而在编 译时就可以给 ...
- 四、Spring——Spring MVC
Spring MVC 1.Spring MVC概述 Spring MVC框架围绕DispatcherServlet这个核心展开,DispatcherServlet负责截获请求并将其分配给响应的处理器处 ...
- Java内存分配和内存管理
首先是概念层面的几个问题: Java中运行时内存结构有哪几种? Java中为什么要设计堆栈分离? Java多线程中是如何实现数据共享的? Java反射的基础是什么? 然后是运用层面: 引用类型变量和对 ...
- The P4 Language Specification v1.0.2 Parser
<p4规范>解析器部分详解 p4解析器是根据有限状态机的思想来设计的. 解析器中解析的过程可以被一个解析图(parser graph)所表示,解析图中所表示的某一个状态(或者说,在P4语言 ...
- servlet&jsp高级:第二部分
声明:原创作品,转载时请注明文章来自SAP师太技术博客( 博/客/园www.cnblogs.com):www.cnblogs.com/jiangzhengjun,并以超链接形式标明文章原始出处,否则将 ...
随机推荐
- Session丢失——解决方案
先抄下别人的作业(原帖:http://www.cnblogs.com/zhc088/archive/2011/07/24/2115497.html) Session丢失已经是一种习以为常的问题了,在自 ...
- 四、Django设置相关
1.全局设置 setttings文件 import os import sys # Build paths inside the project like this: os.path.join(BAS ...
- linux部署MantisBT(一)部署apache
一.部署apache 1.下载apache安装包及依赖包 http://httpd.apache.org/download.cgi#apache24(apache2)http://apr.apache ...
- Vue 编程之路(一)——父子组件之间的数据传递
最近公司的一个项目中使用 Vue 2.0 + element UI 实现一个后台管理系统的前端部分,属于商城类型.其中部分页面是数据管理页,所以有很多可以复用的表格,故引入自定义组件.在这里分享一下开 ...
- JavaScript学习笔记(一)——JS速览
第一章 JS速览 1 限制时间处理事件 <script> setTomeout(wakeUpUser,5000); function wakeUpUser() { alert(" ...
- 【C#】人脸识别 视频数据转图片数据
使用虹软人脸识别的开发过程中遇到了转换的问题 因为不会用C#直接打开摄像头,就只能用第三方dll.一开始用Aforge,后来发现有个问题,关闭摄像头老是陷入等待,所以抛弃了.前一阵子开始用封装了Ope ...
- 译 - 高可用的mesos计算框架设计
原文地址 http://mesos.apache.org/documentation/latest/high-availability-framework-guide/ 阅读建议:有写过或者看过Mes ...
- centos7.2 apache开启.htaccess
打开httpd.conf(在那里? APACHE目录的CONF目录里面),用文本编纂器打开后,查找 (1) AllowOverride None 改为 AllowOverride All (2)去掉下 ...
- redis 学习记录
http://www.yiibai.com/redis/redis_quick_guide.html Redis 是一款依据BSD开源协议发行的高性能Key-Value存储系统(cache and s ...
- 欢迎来怼—第三次Scrum会议
一.会议成员 队名:欢迎来怼队长:田继平队员:李圆圆,葛美义,王伟东,姜珊,邵朔,冉华小组照片: 二.会议时间 2017年10月15日 17:15-17:41 总用时26min 三.会议地点 ...