php爬虫学习笔记1 PHP Simple HTML DOM Parser
常用爬虫。
0.
2.OpenWebSpider
OpenWebSpider是一个开源多线程Web Spider(robot:机器人,crawler:爬虫)和包含许多有趣功能的搜索引擎。
- 授权协议: 未知
- 开发语言: PHP
- 操作系统: 跨平台
特点:开源多线程网络爬虫,有许多有趣的功能
3.PhpDig
PhpDig是一个采用PHP开发的Web爬虫和搜索引擎。通过对动态和静态页面进行索引建立一个词汇表。当搜索查询时,它将按一定的排序规则显示包含关 键字的搜索结果页面。PhpDig包含一个模板系统并能够索引PDF,Word,Excel,和PowerPoint文档。PHPdig适用于专业化更 强、层次更深的个性化搜索引擎,利用它打造针对某一领域的垂直搜索引擎是最好的选择。
演示:http://www.phpdig.net/navigation.php?action=demo
- 授权协议: GPL
- 开发语言: PHP
- 操作系统: 跨平台
特点:具有采集网页内容、提交表单功能
4.ThinkUp
ThinkUp 是一个可以采集推特,facebook等社交网络数据的社会媒体视角引擎。通过采集个人的社交网络账号中的数据,对其存档以及处理的交互分析工具,并将数据图形化以便更直观的查看。
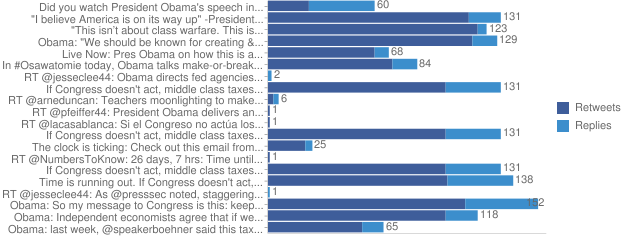
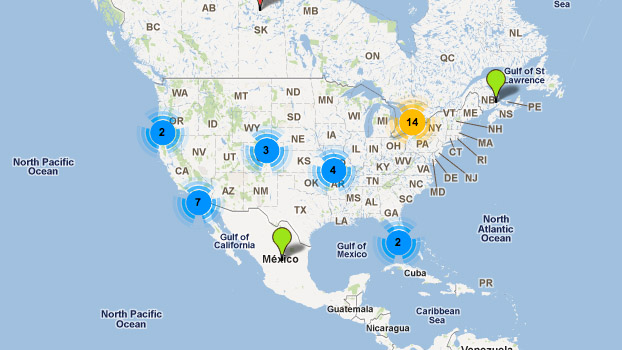
- 授权协议: GPL
- 开发语言: PHP
- 操作系统: 跨平台
github源码:https://github.com/ThinkUpLLC/ThinkUp
特点:采集推特、脸谱等社交网络数据的社会媒体视角引擎,可进行交互分析并将结果以可视化形式展现
5.微购
微购社会化购物系统是一款基于ThinkPHP框架开发的开源的购物分享系统,同时它也是一套针对站长、开源的的淘宝客网站程序,它整合了淘宝、天猫、淘宝客等300多家商品数据采集接口,为广大的淘宝客站长提供傻瓜式淘客建站服务,会HTML就会做程序模板,免费开放下载,是广大淘客站长的首选。
授权协议: GPL
开发语言: PHP
操作系统: 跨平台
6.phpQuery - jQuery port to PHP
https://github.com/TobiaszCudnik/phpquery
http://querylist.cc/
7.Ganon - Fast (HTML DOM) parser written in PHP
https://github.com/Shemahmforash/Ganon
///////////////////////////////////////////////////////////////////////////////////////////////////////////////
<?php
//PHP Simple HTML DOM Parser Manual
require 'E:\wamp\www\php-simple-html-dom-parser-1.5.0\Src\Sunra\PhpSimple\simplehtmldom_1_5\simple_html_dom.php';
//获取element元素********************************//
/*
$html = file_get_html('http://www.baidu.com/');
// Find all images 获取图片链接
foreach($html->find('img') as $element)
echo $element->src . '<br>';
echo "22222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222";
// Find all links 获取所有链接
foreach($html->find('a') as $element)
echo $element->href . '<br>';
*/
//修改element元素 属性 和值
/*
// Create DOM from string
$html = str_get_html('<div id="hello">Hello</div><div id="world">World</div>');
$html->find('div', 1)->class = 'bar';//改变div的class 1表示第二个div(总结:找什么元素(元素的id是什么) 第几个)-》要改变的是
$html->find('div[id=hello]', 0)->innertext = 'foo';
echo $html; // Output: <div id="hello">foo</div><div id="world" class="bar">World</div>
*/
/*
//// Dump contents (without tags) from HTML 打印出全部内容 只是内容
echo file_get_html('http://www.ycu.edu.cn/B20110603182545.html')->plaintext;
//plaintext 可以取到标签的纯文本
*/
/************************************从特定网页获取信息 根据相关的标签****/
/*
// Create DOM from URL
$html = file_get_html('http://tech.sina.com.cn/d/i/2015-11-10/doc-ifxkniur3014232.shtml');
//$aaa = $html->find('table',13);var_dump($aaa);die;
// Find all article blocks
// 利用网页源代码的标签页进行局部信息的采集
foreach($html->find('div.blkContainerSblk') as $article) {
$item['title'] = $article->find('h1#artibodyTitle', 0)->plaintext; //
$item['pubinfo'] = $article->find('div.artInfo', 0)->plaintext;
$item['date'] = $article->find('span#pub_date', 0)->plaintext;
$item['details'] = $article->find('div[id=artibody]', 0)->plaintext;
$articles[] = $item;
}
print_r($articles);
*/
/*
/************************************How to create HTML DOM object?*****/
//如何创建dom 对象
/*
//1 Create a DOM object from a string
$html1 = str_get_html('<html><body>Hello!</body></html>');
//2 Create a DOM object from a URL
$html2 = file_get_html('http://www.baidu.com/');
//3 Create a DOM object from a HTML file
$html3 = file_get_html('../aj.html');
*/
//面向对象的方法Object-oriented way
/*
// Create a DOM object
$html = new simple_html_dom();
// Load HTML from a string
$html->load('<html><body>Hello!word!</body></html>');
// Load HTML from a URL
$html->load_file('http://www.google.com/');
// Load HTML from a HTML file
$html->load_file('test.htm');
*/
/********************************************How to find HTML elements?******************************/
/*
///////////basic////////
// Find all anchors, returns a array of element objects
$ret = $html->find('a');
// Find (N)th anchor, returns element object or null if not found (zero based)
$ret = $html->find('a', 0);
// Find lastest anchor, returns element object or null if not found (zero based)
$ret = $html->find('a', -1);
// Find all <div> with the id attribute 找到所有有id的
$ret = $html->find('div[id]');
// Find all <div> which attribute id=foo 找到id为。。。的。
$ret = $html->find('div[id=foo]');
///////////////////advanced 高级的///////////////////////
// Find all element which id=foo
$ret = $html->find('#foo');
// Find all element which class="foo"
$ret = $html->find('.foo');
// Find all element has attribute id 有id属性
$ret = $html->find('*[id]');
// Find all anchors and images 找到所有 链接 和 图片
$ret = $html->find('a, img');
// Find all anchors and images with the "title" attribute找到所有拥有title属性的连接和图片
$ret = $html->find('a[title], img[title]');
///////////////后代选择器 /////////////////////////
// Find all <li> in <ul> 找到在ul里的li标签
$es = $html->find('ul li');
// Find Nested <div> tags 嵌套div
$es = $html->find('div div div');
// Find all <td> in <table> which class="hello"
$es = $html->find('table.hello td');
// Find all td tags with attribite align=center in table tags
$es = $html->find('table td[align=center]');
////////////////////嵌套选择器//////////////////////
///
// Find all <li> in <ul>
foreach($html->find('ul') as $ul)
{
foreach($ul->find('li') as $li)
{
// do something...
}
}
// Find first <li> in first <ul>
$e = $html->find('ul', 0)->find('li', 0);
///////////////////////属性选择器 //////////////////////////////////
/*
Supports these operators in attribute selectors:
Filter Description
[attribute] Matches elements that have the specified attribute.
[!attribute] Matches elements that don't have the specified attribute.
[attribute=value] Matches elements that have the specified attribute with a certain value.
[attribute!=value] Matches elements that don't have the specified attribute with a certain value.
[attribute^=value] Matches elements that have the specified attribute and it starts with a certain value. 属性值的 起始 为特定的值
[attribute$=value] Matches elements that have the specified attribute and it ends with a certain value.
属性值的 结束 为特定的值
[attribute*=value] Matches elements that have the specified attribute and it contains a certain value.
属性值的 包含 特定的值
//////////////////////查找所有文本块 评论内容/////////////////////////////////////
// Find all text blocks
$es = $html->find('text');
// Find all comment (<!--...-->) blocks
$es = $html->find('comment');
*/
/*********************How to access the HTML element's attributes? 如何访问html元素的属性********/
/*
// Get a attribute ( If the attribute is non-value attribute (eg. checked, selected...), it will returns true or false)
$value = $e->href; //获得
// Set a attribute(If the attribute is non-value attribute (eg. checked, selected...), set it's value as true or false)
$e->href = 'my link'; //设置 赋值
// Remove a attribute, set it's value as null!
$e->href = null; //移除 置空
// Determine whether a attribute exist? 判断元素是否存在
if(isset($e->href))
echo 'href exist!';
//魔法属性
// Example
$html = str_get_html("<div>foo <b>bar</b> </div>");
$e = $html->find("div", 0);
echo $e->tag; // Returns: " div" //标签
echo $e->outertext; // Returns: " <div>foo <b>bar</b></div>" 获取到的所有 显示的只有 foo bar 但是都是带着属性的,比如颜色啊还有黑体等等
echo $e->innertext; // Returns: " foo <b>bar</b>" 标签内部的 只显示内部的。内部的标签属性还是可以现实的。
echo "<br>";
echo $e->plaintext; // Returns: " foo bar" 纯文本的 不带标签属性 只是纯文本 其他的颜色 字体等等 都没了。
// Attribute Name Usage
// $e->tag Read or write the tag name of element.
// $e->outertext Read or write the outer HTML text of element.
// $e->innertext Read or write the inner HTML text of element.
// $e->plaintext Read or write the plain text of element.
////////////////小技巧///////////////////////////////////
// Extract contents from HTML
echo $html->plaintext;
// Wrap a element 包裹一个元素
$e->outertext = '<div class="wrap">' . $e->outertext . '<div>';
// Remove a element, set it's outertext as an empty string 移除
$e->outertext = '';
// Append a element
$e->outertext = $e->outertext . '<div>foo<div>'; //附加元素 后面
// Insert a element 插入元素(在元素前面)
$e->outertext = '<div>foo<div>' . $e->outertext;
*/
/*************************How to traverse the DOM tree?*****遍历dom树*************************************/
// Example
//echo $html->find("#div1", 0)->children(1)->children(1)->children(2)->id;
// or
//echo $html->getElementById("div1")->childNodes(1)->childNodes(1)->childNodes(2)->getAttribute('id');
/*
Method Description
mixed$e->children ( [int $index] ) Returns the Nth child object if index is set, otherwise return an array of children.
element$e->parent () Returns the parent of element.
element$e->first_child () Returns the first child of element, or null if not found.
element$e->last_child () Returns the last child of element, or null if not found.
element$e->next_sibling () Returns the next sibling of element, or null if not found.
element$e->prev_sibling () Returns the previous sibling of element, or null if not found.
*/
/*
//How to dump contents of DOM object? 如何转存dom对象
$str = $html;
// Print it!
echo $html;
//面向对象方式
// Dumps the internal DOM tree back into string 存为字符串
$str = $html->save();
// Dumps the internal DOM tree back into a file 存到文件
$html->save('result.htm');
//How to customize the parsing behavior? 如何自定义解析行为
// Write a function with parameter "$element"
function my_callback($element) {
// Hide all <b> tags
if ($element->tag=='b')
$element->outertext = '';
}
// Register the callback function with it's function name
$html->set_callback('my_callback');
// Callback function will be invoked while dumping
echo $html;
*/
api
Index
API Reference
| Name | Description |
|---|---|
| objectstr_get_html ( string $content ) | Creates a DOM object from a string. |
| objectfile_get_html ( string $filename ) | Creates a DOM object from a file or a URL. |
DOM methods & properties
| Name | Description |
|---|---|
|
void
__construct ( [string $filename] ) |
Constructor, set the filename parameter will automatically load the contents, either text or file/url. |
|
string
plaintext |
Returns the contents extracted from HTML. |
|
void
clear () |
Clean up memory. |
|
void
load ( string $content ) |
Load contents from a string. |
|
string
save ( [string $filename] ) |
Dumps the internal DOM tree back into a string. If the $filename is set, result string will save to file. |
|
void
load_file ( string $filename ) |
Load contents from a from a file or a URL. |
|
void
set_callback ( string $function_name ) |
Set a callback function. |
|
mixed
find ( string $selector [, int $index] ) |
Find elements by the CSS selector. Returns the Nth element object if index is set, otherwise return an array of object. |
Element methods & properties
| Name | Description |
|---|---|
|
string
[attribute] |
Read or write element's attribure value. |
|
string
tag |
Read or write the tag name of element. |
|
string
outertext |
Read or write the outer HTML text of element. |
|
string
innertext |
Read or write the inner HTML text of element. |
|
string
plaintext |
Read or write the plain text of element. |
|
mixed
find ( string $selector [, int $index] ) |
Find children by the CSS selector. Returns the Nth element object if index is set, otherwise, return an array of object. |
DOM traversing
| Name | Description |
|---|---|
|
mixed
$e->children ( [int $index] ) |
Returns the Nth child object if index is set, otherwise return an array of children. |
|
element
$e->parent () |
Returns the parent of element. |
|
element
$e->first_child () |
Returns the first child of element, or null if not found. |
|
element
$e->last_child () |
Returns the last child of element, or null if not found. |
|
element
$e->next_sibling () |
Returns the next sibling of element, or null if not found. |
|
element
$e->prev_sibling () |
Returns the previous sibling of element, or null if not found. |
Camel naming convertions
| Method | Mapping |
|---|---|
|
array
$e->getAllAttributes () |
array
$e->attr |
|
string
$e->getAttribute ( $name ) |
string
$e->attribute |
|
void
$e->setAttribute ( $name, $value ) |
void
$value = $e->attribute |
|
bool
$e->hasAttribute ( $name ) |
bool
isset($e->attribute) |
|
void
$e->removeAttribute ( $name ) |
void
$e->attribute = null |
|
element
$e->getElementById ( $id ) |
mixed
$e->find ( "#$id", 0 ) |
|
mixed
$e->getElementsById ( $id [,$index] ) |
mixed
$e->find ( "#$id" [, int $index] ) |
|
element
$e->getElementByTagName ($name ) |
mixed
$e->find ( $name, 0 ) |
|
mixed
$e->getElementsByTagName ( $name [, $index] ) |
mixed
$e->find ( $name [, int $index] ) |
|
element
$e->parentNode () |
element
$e->parent () |
|
mixed
$e->childNodes ( [$index] ) |
mixed
$e->children ( [int $index] ) |
|
element
$e->firstChild () |
element
$e->first_child () |
|
element
$e->lastChild () |
element
$e->last_child () |
|
element
$e->nextSibling () |
element
$e->next_sibling () |
|
element
$e->previousSibling () |
element
$e->prev_sibling () |
php爬虫学习笔记1 PHP Simple HTML DOM Parser的更多相关文章
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- PHP Simple HTML DOM Parser Manual-php解析DOM
PHP Simple HTML DOM Parser Manual http://www.lupaworld.com/doc-doc-api-770.html PHP Simple HTML DOM ...
- 使用php simple html dom parser解析html标签
转自:http://www.blhere.com/1243.html 使用php simple html dom parser解析html标签 用了一下 PHP Simple HTML DOM Par ...
- python网络爬虫学习笔记(二)BeautifulSoup库
Beautiful Soup库也称为beautiful4库.bs4库,它可用于解析HTML/XML,并将所有文件.字符串转换为'utf-8'编码.HTML/XML文档是与“标签树一一对应的.具体地说, ...
- python网络爬虫学习笔记(一)Request库
一.Requests库的基本说明 引入Rquests库的代码如下 import requests 库中支持REQUEST, GET, HEAD, POST, PUT, PATCH, DELETE共7个 ...
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- 网络请求 爬虫学习笔记 一 requsets 模块的使用 get请求和post请求初识别,代理,session 和ssl证书
前情提要: 为了养家糊口,为了爱与正义,为了世界和平, 从新学习一个爬虫技术,做一个爬虫学习博客记录 学习内容来自各大网站,网课,博客. 如果觉得食用不良,你来打我啊 requsets 个人觉得系统自 ...
- python爬虫学习笔记
爬虫的分类 1.通用爬虫:通用爬虫是搜索引擎(Baidu.Google.Yahoo等)“抓取系统”的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 简单来讲就是尽可 ...
- Python、pip和scrapy的安装——Python爬虫学习笔记1
Python作为爬虫语言非常受欢迎,近期项目需要,很是学习了一番Python,在此记录学习过程:首先因为是初学,而且当时要求很快速的出demo,所以首先想到的是框架,一番查找选用了Python界大名鼎 ...
随机推荐
- linux学习笔记三:防火墙设置
请注意:centOS7和7之前的版本在防火墙设置上不同,只有正确的设置防火墙才能实现window下访问linux中的web应用. centOS6添加端口: vi /ets/sysconfig/ipta ...
- windows 使用npm安装webpack 4.0以及配置问题的解决办法
输入cmd点击打开 输入node -v 出现nodejs版本号 输入npm -v 出现npm版本号则安装npm安装成功, 2.安装webpack 桌面新建一个webpack-test文件夹,点击进入文 ...
- 网页中的图像<img>
插入图像 img标记的属性及描述 属性 值 描述 alt text 定义有关图形的短描述 src URL 要显示图像的URL height pixels% 定义图像的高度 width pixels% ...
- C语言中的强制类型转换
先直接放程序吧,后面还有总结. -------------------------------------------start------------------------------------ ...
- 【转】Excel-VBA操作文件四大方法之三
三.利用FileSystemObject对象来处理文件 FileSystemObject对象模型,是微软提供的专门用来访问计算机文件系统的,具有大量的属性.方法和事件.其使用面向对象的“object. ...
- 20155233 《Java程序设计》实验四 Android开发基础
20155233 <Java程序设计>实验四 Android开发基础 实验内容 1.基于Android Studio开发简单的Android应用并部署测试; 2.了解Android组件.布 ...
- 【LOJ6433】【PKUSC2018】最大前缀和
[LOJ6433][PKUSC2018]最大前缀和 题面 题目描述 小 C 是一个算法竞赛爱好者,有一天小 C 遇到了一个非常难的问题:求一个序列的最大子段和. 但是小 C 并不会做这个题,于是小 C ...
- 【BZOJ3527】[ZJOI3527]力
[BZOJ3527][ZJOI3527]力 题面 bzoj 洛谷 题解 易得 \[ E_i=\sum_{j<i}\frac{q_j}{(i-j)^2}-\sum_{j>i}\frac{q_ ...
- 1018: [SHOI2008]堵塞的交通traffic
1018: [SHOI2008]堵塞的交通traffic 链接 分析: 用线段树维护区间的四个端点的联通情况,然后查询的时候,把所有覆盖到的区间合并起来即可. 六种情况左上到右上(左边到右边的情况)… ...
- tidb测试环境安装,离线部署
1.环境以及规划 机器:centos7.5 ; 文件系统为ext4:内存16g:cpu8核,共三个节点: ip hostname roles --- tidb tipd tikv --- tidb t ...