python ConfigParser读取配置文件,及解决报错(去掉BOM)ConfigParser.MissingSectionHeaderError: File contains no section headers的方法
先说一下在读取配置文件时报错的问题--ConfigParser.MissingSectionHeaderError: File contains no section headers
问题描述:
在练习ConfigParser读取配置文件时,cmd一直报一个错:ConfigParser.MissingSectionHeaderError: File contains no section headers.如图:
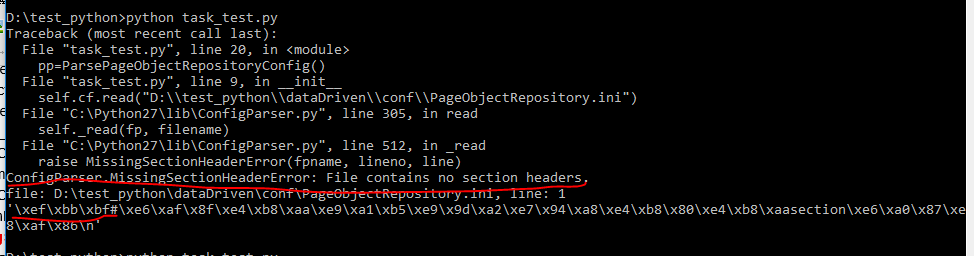
D:\test_python>python task_test.py
Traceback (most recent call last):
File "task_test.py", line 20, in <module>
pp=ParsePageObjectRepositoryConfig()
File "task_test.py", line 9, in __init__
self.cf.read("D:\\test_python\\dataDriven\\conf\\PageObjectRepository.ini")
File "C:\Python27\lib\ConfigParser.py", line 305, in read
self._read(fp, filename)
File "C:\Python27\lib\ConfigParser.py", line 512, in _read
raise MissingSectionHeaderError(fpname, lineno, line)
ConfigParser.MissingSectionHeaderError: File contains no section headers.
file: D:\test_python\dataDriven\conf\PageObjectRepository.ini, line: 1
'\xef\xbb\xbf#\xe6\xaf\x8f\xe4\xb8\xaa\xe9\xa1\xb5\xe9\x9d\xa2\xe7\x94\xa8\xe4\xb8\x80\xe4\xb8\xaasection\xe6\xa0\x87\xe8\xaf\x86\n'
百度了一下网上的解决方案,
报错是因为配置文件PageObjectRepository.ini在windows下经过notepad编辑后保存为UTF-8或者unicode格式的话,会在文件的开头加上两个字节“\xff\xfe”或者三个字节“\xef\xbb\xbf”。 就是--》BOM, BOM是什么?请看结尾
解决的办法就是在配置文件被读取前,把DOM字节个去掉。
网上也给了一个用正则去掉BOM字节的函数:就是把对应的字节替换成空字符串
remove_BOM()函数定义:
def remove_BOM(config_path):
content = open(config_path).read()
content = re.sub(r"\xfe\xff","", content)
content = re.sub(r"\xff\xfe","", content)
content = re.sub(r"\xef\xbb\xbf","", content)
open(config_path, 'w').write(content)
下面贴一下我的配置文件和读取配置文件的代码--:

代码:
#encoding=utf-8
from ConfigParser import ConfigParser
import re
def remove_BOM(config_path):#去掉配置文件开头的BOM字节
content = open(config_path).read()
content = re.sub(r"\xfe\xff","", content)
content = re.sub(r"\xff\xfe","", content)
content = re.sub(r"\xef\xbb\xbf","", content)
open(config_path, 'w').write(content)
class ParsePageObjectRepositoryConfig(object):
def __init__(self,config_path):
self.cf=ConfigParser()#生成解析器
self.cf.read(config_path)
print "-"*80
print "cf.read(config_path):\n", self.cf.read(config_path)
def getItemsFromSection(self,sectionName):
print self.cf.items(sectionName)
return dict(self.cf.items(sectionName))
def getOptionValue(self,sectionName,optionName):#返回一个字典
return self.cf.get(sectionName,optionName)
if __name__=='__main__':
remove_BOM("D:\\test_python\\PageObjectRepository.ini")
pp=ParsePageObjectRepositoryConfig("D:\\test_python\\PageObjectRepository.ini")
remove_BOM
print "-"*80
print "items of '126mail_login':\n",pp.getItemsFromSection("126mail_login")
print "-"*80
print "value of 'login_page.username' under section '126mail_login':\n",pp.getOptionValue("126mail_login","login_page.username")
结果:
D:\test_python>python task_test.py
--------------------------------------------------------------------------------
cf.read(config_path):
['D:\\test_python\\PageObjectRepository.ini']
--------------------------------------------------------------------------------
items of '126mail_login':
[('login_page.frame', 'id>x-URS-iframe'), ('login_page.username', "xpath>//input[@name='email']"), ('login_page.password', "xpath>//input[@name='password']"), ('login_page.loginbutton', 'id>dologin')]
{'login_page.loginbutton': 'id>dologin', 'login_page.username': "xpath>//input[@name='email']", 'login_page.frame': 'id>x-URS-iframe', 'login_page.password': "xpath>//input[@name='password']"}
--------------------------------------------------------------------------------
value of 'login_page.username' under section '126mail_login':
xpath>//input[@name='email']
BOM概念:
BOM(Byte Order Mark),字节顺序标记,出现在文本文件头部,Unicode编码标准中用于标识文件是采用哪种格式的编码。
UTF-8 不需要 BOM 来表明字节顺序,但可以用 BOM 来表明编码方式。字符 “Zero Width No-Break Space” 的
UTF-8 编码是 EF BB BF。所以如果接收者收到以 EF BB BF 开头的字节流,就知道这是 UTF-8编码了。Windows
就是使用 BOM
来标记文本文件的编码方式的。类似WINDOWS自带的记事本等软件,在保存一个以UTF-8编码的文件时,会在文件开始的地方插入三个不可见的字符(0xEF
0xBB 0xBF,即BOM)。它是一串隐藏的字符,用于让记事本等编辑器识别这个文件是否以UTF-8编码。
从堆栈信息中可以看到UTF8编码的字符有BOM的字符串前边有:\xef\xbb\xbf
'\xef\xbb\xbf#\xe6\xaf\x8f\xe4\xb8\xaa\xe9\xa1\xb5\xe9\x9d\xa2\xe7\x94\xa8\xe4\xb8\x80\xe4\xb8\xaasection\xe6\xa0\x87\xe8\xaf\x86\n'
python ConfigParser读取配置文件,及解决报错(去掉BOM)ConfigParser.MissingSectionHeaderError: File contains no section headers的方法的更多相关文章
- ConfigParser.MissingSectionHeaderError: File contains no section headers.
今天使用ConfigParser解析一个ini文件,报出如下错误: config.read(logFile) File "C:\Python26\lib\ConfigParser.py&qu ...
- python在读取配置文件存入列表中,去掉回车符号
self.receiver = map(lambda x: x.strip(), receiver_list) # 去掉list中的回车符号
- 记一次用python 的ConfigParser读取配置文件编码报错
记一次用python 的ConfigParser读取配置文件编码报错 ...... raise MissingSectionHeaderError(fpname, lineno, line)Confi ...
- ConfigParser读取配置文件时报错:ConfigParser.MissingSectionHeaderError
使用ConfigParser来读取配置文件,经常会发现经过记事本.notepad++修改后的配置文件读取时出现下面的问题: ConfigParser.MissingSectionHeaderError ...
- python之读取配置文件模块configparser(二)参数详解
configparser.ConfigParser参数详解 从configparser的__ini__中可以看到有如下参数: def __init__(self, defaults=None, dic ...
- Python读取CSV文件,报错:UnicodeDecodeError: 'gbk' codec can't decode byte 0xa7 in position 727: illegal multibyte sequence
Python读取CSV文件,报错:UnicodeDecodeError: 'gbk' codec can't decode byte 0xa7 in position 727: illegal mul ...
- python中引入包的时候报错AttributeError: module 'sys' has no attribute 'setdefaultencoding'解决方法?
python中引入包的时候报错:import unittestimport smtplibimport timeimport osimport sysimp.reload(sys)sys.setdef ...
- python中读取配置文件ConfigParser
在程序中使用配置文件来灵活的配置一些参数是一件很常见的事情,配置文件的解析并不复杂,在python里更是如此,在官方发布的库中就包含有做这件事情的库,那就是ConfigParser,这里简单的做一些介 ...
- DB2读取CLOB字段-was报错:操作无效:已关闭 Lob。 ERRORCODE=-4470, SQLSTATE=null
DB2读取CLOB字段-was报错:操作无效:已关闭 Lob. ERRORCODE=-4470, SQLSTATE=null 解决方法,在WAS中要用的数据源里面配置连个定制属性: progressi ...
随机推荐
- lodash(一)数组
前言: lodash是一个具有一致接口.模块化.高性能等特性的JavaScript工具库(官网地址:http://lodashjs.com/docs/#_differencearray-values) ...
- C++预处理和头文件保护符
一预处理 1.常见的预处理功能 预处理器的主要作用就是把通过预处理的内建功能对一个资源进行等价替换,最常见的预处理有:文件包含,条件编译.布局控制和宏替换4种.文件包含:#include 是一种最为常 ...
- Android 系统镜像: boot.img kernel.img ramdisk.img system.img userdata.img cache.img recovery.img
boot.img(kernel.img+ramdisk.img) ramdisk.img(/) system.img(/system) userdata.img(/data) cache.img(/c ...
- sencha touch 入门系列 (一)sencha touch 简介
参考链接:http://mobile.51cto.com/others-278381.htm Sencha touch 是基于JavaScript编写的Ajax框架ExtJS,将现有的ExtJS整合J ...
- WCF(四) 深入契约
服务契约中的请求-响应操作 1.请求-响应模式 [OperationContract]//1默认就是 请求-相应 Requst- Replay DateTime GetDateTime(); [Ope ...
- Java多线程(4)----线程的四种状态
与人有生老病死一样,线程也同样要经历开始(等待).运行.挂起和停止四种不同的状态.这四种状态都可以通过Thread类中的方法进行控制.下面给出了Thread类中和这四种状态相关的方法. 1 // 开始 ...
- 防止独立IP被其它恶意域名恶意解析
一:什么是恶意域名解析 一般情况下,要使域名能访问到网站需要两步,第一步,将域名解析到网站所在的主机,第二步,在web服务器中将域名与相应的网站绑定.但是,如果通过主机IP能直接访问某网站,那么把域名 ...
- ubuntu下安装meshlab
PPA 安装,打开终端,输入以下命令: sudo add-apt-repository ppa:zarquon42/meshlab sudo apt-get update sudo apt-get i ...
- opencv中Mat格式的数据访问.at
opencv3中图形存储基本为Mat格式,如果我们想获取像素点的灰度值或者RGB值,可以通过image.at<uchar>(i,j)的方式轻松获取. Mat类中的at方法对于获取图像矩阵某 ...
- Golang OOP、继承、组合、接口
http://www.cnblogs.com/jasonxuli/p/6836399.html 传统 OOP 概念 OOP(面向对象编程)是对真实世界的一种抽象思维方式,可以在更高的层次上对所 ...