【Python网络】HTTP
HTTP概述
HTTP(hypertext transport protocol),即超文本传输协议。这个协议详细规定了浏览器和万维网服务器之间互相通信的规则。
HTTP就是一个通信规则,通信规则规定了客户端发送给服务器的内容格式,也规定了服务器发送给客户端的内容格式。
客户端发送给服务器的格式叫“请求协议”;服务器发送给客户端的格式叫“响应协议”。
特点:
HTTP叫超文本传输协议,基于请求/响应模式!
HTTP是无状态协议。无状态是指协议对于事务处理没有记忆能力,服务器不知道客户端是什么状态。
URL:统一资源定位符,就是一个网址:协议名://域名:端口/路径
请求协议
请求协议的格式如下:
请求首行; // 请求方式 请求路径 协议和版本,例如:GET /index.html HTTP/1.1
请求头信息;// 请求头名称:请求头内容,即为key:value格式,例如:Host:localhost
空行; // 用来与请求体分隔开
请求体。 // GET没有请求体,只有POST有请求体。
GET请求
HTTP默认的请求方法就是GET
没有请求体
数据必须在1K之内!
GET请求数据会暴露在浏览器的地址栏中
GET请求常用的操作:
在浏览器的地址栏中直接给出URL,那么就一定是GET请求
点击页面上的超链接也一定是GET请求
提交表单时,表单默认使用GET请求,但可以设置为POST
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Encoding:gzip, deflate, sdch
Accept-Language:zh-CN,zh;q=0.8
Cache-Control:no-cache
Connection:keep-alive
Cookie:csrftoken=z5H43ZwARx7AIJ82OEizBOWbsAQA2LPk
Host:127.0.0.1:8090
Pragma:no-cache
Upgrade-Insecure-Requests:1
User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.89 Safari/537.36
Name
login/
1 requests ❘ 737 B transferred ❘ Finish: 5 ms ❘ DOMContentLoaded: 14 ms ❘ Load: 14 ms
GET 127.0.0.1:8090/login HTTP/1.1:GET请求,请求服务器路径为 127.0.0.1:8090/login ,协议为1.1;
Host:localhost:请求的主机名为localhost;
*User-Agent: Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0:与浏览器和OS相关的信息。有些网站会显示用户的系统版本和浏览器版本信息,这都是通过获取User-Agent头信息而来的;
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8:告诉服务器,当前客户端可以接收的文档类型,其实这里包含了*/*,就表示什么都可以接收;
Accept-Language: zh-cn,zh;q=0.5:当前客户端支持的语言,可以在浏览器的工具选项中找到语言相关信息;
Accept-Encoding: gzip, deflate:支持的压缩格式。数据在网络上传递时,可能服务器会把数据压缩后再发送;
Accept-Charset: GB2312,utf-8;q=0.7,*;q=0.7:客户端支持的编码;
Connection: keep-alive:客户端支持的链接方式,保持一段时间链接,默认为3000ms;
Cookie: JSESSIONID=369766FDF6220F7803433C0B2DE36D98:因为不是第一次访问这个地址,所以会在请求中把上一次服务器响应中发送过来的Cookie在请求中一并发送去过;这个Cookie的名字为JSESSIONID。
注意:
HTTP是一个无状态的面向连接的协议,无状态不代表HTTP不能保持TCP连接,更不能代表HTTP使用的是UDP协议(无连接)
从HTTP/1.1起,默认都开启了Keep-Alive,保持连接特性,简单地说,当一个网页打开完成后,客户端和服务器之间用于传输 HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接
Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间
POST请求
数据不会出现在地址栏中
数据的大小没有上限
有请求体
请求体中如果存在中文,会使用URL编码!
URL编码只是简单的在特殊字符的各个字节前加上%
例如,我们对 name1=va&lu=e1 会产生奇异的字符进行URL编码后结果:
“name1=va%26lu%3D”,这样服务端会把紧跟在“%”后的字节当成普通的字节,就是不会把它当成各个参数或键值对的分隔符。
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Encoding:gzip, deflate
Accept-Language:zh-CN,zh;q=0.8
Cache-Control:no-cache
Connection:keep-alive
Content-Length:13
Content-Type:application/x-www-form-urlencoded
Cookie:csrftoken=z5H43ZwARx7AIJ82OEizBOWbsAQA2LPk
Host:127.0.0.1:8090
Origin:http://127.0.0.1:8090
Pragma:no-cache
Referer:http://127.0.0.1:8090/login/
Upgrade-Insecure-Requests:1
User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_1)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.89 Safari/537.36 Form Data
username:admin
POST请求是可以有体的,而GET请求不能有请求体。
Referer: http://localhost:8080/hello/index.jsp:请求来自哪个页面,
例如你在百度上点击链接到了这里,那么Referer:http://www.baidu.com;如果你是在浏览器的地址栏中直接输入的地址,那么就没有Referer这个请求头了;
Content-Type: application/x-www-form-urlencoded:表单的数据类型,说明会使用url格式编码数据;url编码的数据都是以“%”为前缀,后面跟随两位的16进制。
Content-Length:13:请求体的长度,这里表示13个字节。
keyword=hello:请求体内容!hello是在表单中输入的数据,keyword是表单字段的名字。
响应协议
响应协议的格式如下:
响应首行;
响应头信息;
空行;
响应体。
响应内容是由服务器发送给浏览器的内容,浏览器会根据响应内容来显示。
遇到<img src=''>会开一个新的线程加载,所以有时图片多的话,内容会先显示出来,然后图片才一张张加载出来。
Request URL:http://127.0.0.1:8090/login/
Request Method:GET
Status Code:200 OK
Remote Address:127.0.0.1:8090
Response Headers
view source
Content-Type:text/html; charset=utf-8
Date:Wed, 26 Oct 2017 07:00:00 GMT
Server:WSGIServer/0.2 CPython/3.5.2
X-Frame-Options:SAMEORIGIN
HTTP/1.1 200 OK:响应协议为HTTP1.1,状态码为200,表示请求成功,OK是对状态码的解释;
Server:WSGIServer/0.2 CPython/3.5.2:服务器的版本信息;
Content-Type: text/html;charset=UTF-8:响应体使用的编码为UTF-8;
Content-Length: 724:响应体为724字节;
Set-Cookie: JSESSIONID=C97E2B4C55553EAB46079A4F263435A4; Path=/hello:响应给客户端的Cookie;
Date: Wed, 25 Sep 2012 04:15:03 GMT:响应的时间,这可能会有8小时的时区差;
状态码
响应码对浏览器来说很重要,它说明了响应的真正含义。例如200表示响应成功了,302表示重定向,这说明浏览器需要再发一个新的请求。
200:请求成功,浏览器会把响应体内容(通常是html)显示在浏览器中;
404:请求的资源没有找到,说明客户端错误的请求了不存在的资源;
500:请求资源找到了,但服务器内部出现了错误;
302:重定向,当响应码为302时,表示服务器要求浏览器重新再发一个请求,服务器会发送一个响应头Location,它指定了新请求的URL地址;
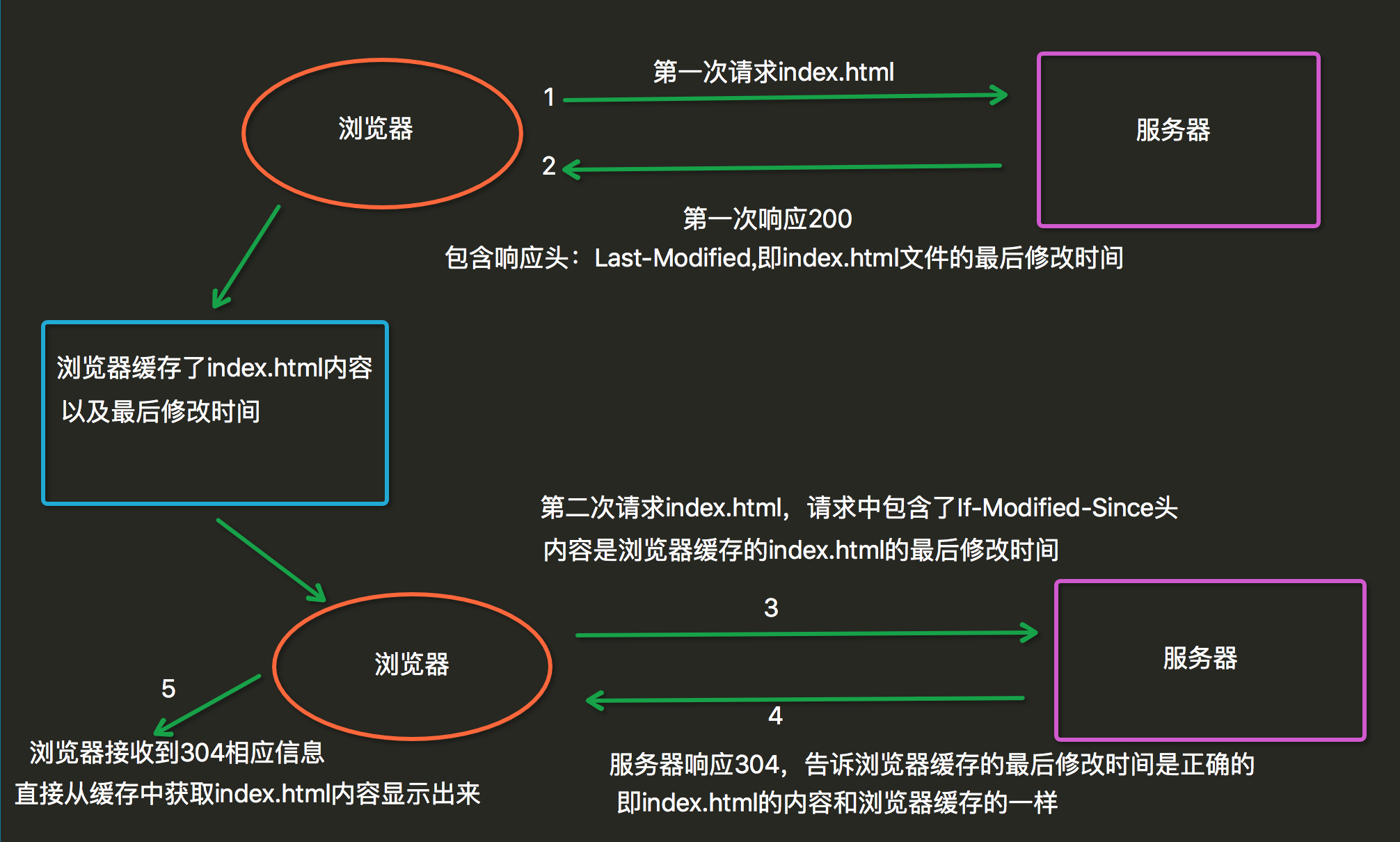
其他响应头
告诉浏览器不要缓存的响应头:
Expires: -1;
Cache-Control: no-cache;
Pragma: no-cache;
自动刷新响应头,浏览器会在3秒之后请求http://www.baidu.com:
- Refresh: 3;url=http://www.baidu.com
HTML中指定响应头
<meta http-equiv="Refresh" content="3;url=http://www.baidu.com">,表示浏览器只会显示index.html页面3秒,然后自动跳转到http://www.baidu.com.
【Python网络】HTTP的更多相关文章
- Python 网络编程(二)
Python 网络编程 上一篇博客介绍了socket的基本概念以及实现了简单的TCP和UDP的客户端.服务器程序,本篇博客主要对socket编程进行更深入的讲解 一.简化版ssh实现 这是一个极其简单 ...
- Python 网络编程(一)
Python 网络编程 socket通常也称作"套接字",用于描述IP地址和端口,是一个通信链的句柄,应用程序通常通过"套接字"向网络发出请求或者应答网络请求. ...
- 笔记之Python网络数据采集
笔记之Python网络数据采集 非原创即采集 一念清净, 烈焰成池, 一念觉醒, 方登彼岸 网络数据采集, 无非就是写一个自动化程序向网络服务器请求数据, 再对数据进行解析, 提取需要的信息 通常, ...
- Python网络socket学习
Python 网络编程 Python 提供了两个级别访问的网络服务.: 低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统Socket接口的 ...
- Python学习(22)python网络编程
Python 网络编程 Python 提供了两个级别访问的网络服务.: 低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统Socket接口的 ...
- Day07 - Python 网络编程 Socket
1. Python 网络编程 Python 提供了两个级别访问网络服务: 低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统Socket接口 ...
- 关于Python网络爬虫实战笔记③
Python网络爬虫实战笔记③如何下载韩寒博客文章 Python网络爬虫实战笔记③如何下载韩寒博客文章 target:下载全部的文章 1. 博客列表页面规则 也就是, http://blog.sina ...
- 关于Python网络爬虫实战笔记①
python网络爬虫项目实战笔记①如何下载韩寒的博客文章 python网络爬虫项目实战笔记①如何下载韩寒的博客文章 1. 打开韩寒博客列表页面 http://blog.sina.com.cn/s/ar ...
- python网络编程-01
python网络编程 1.socket模块介绍 ①在网络编程中的一个基本组件就是套接字(socket),socket是两个程序之间的“信息通道”. ②套接字包括两个部分:服务器套接字.客户机套接字 ③ ...
- python 网络爬虫(二) BFS不断抓URL并放到文件中
上一篇的python 网络爬虫(一) 简单demo 还不能叫爬虫,只能说基础吧,因为它没有自动化抓链接的功能. 本篇追加如下功能: [1]广度优先搜索不断抓URL,直到队列为空 [2]把所有的URL写 ...
随机推荐
- Java时间处理
java.sql.PreparedStatement接口的setDate(int parameterIndex, java.sql.Date x)方法中的Date为java.sql包下的Date,而不 ...
- php 正则替换特殊字符 和检测是否是中文
如果是只想输入中文的话,就这么写,要注意是分gb2312和utf-8的哦: gb2312:if(!preg_match("/^[".chr(0xa1)."-". ...
- 并不对劲的复健训练-bzoj5253:loj2479:p4384:[2018多省联考]制胡窜
题目大意 给出一个字符串\(S\),长度为\(n\)(\(n\leq 10^5\)),\(S[l:r]\)表示\(S_l,S_{l+1}...,S_r\)这个子串.有\(m\)(\(m\leq 3\t ...
- 清除SQL日志文件
1.清除errorlog文件 MSSQL在 C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\LOG 目录下存放这一些日志文件,一共是7个,常常会 ...
- How to enable remote connections to SQL Server
<img src="https://miro.medium.com/max/1400/1*18lrHvJ8YtADJDT7hxIThA.jpeg" class="g ...
- WPF 遍历资源字典中的控件
object obItem=this.FindResource("canvasdt"); if (obItem is System.Windows.DataTemplate) { ...
- 【原创】大叔经验分享(62)kudu副本数量
kudu的副本数量是在表上设置,可以通过命令查看 # sudo -u kudu kudu cluster ksck $master ... Summary by table Name | RF | S ...
- 客户端相关知识学习(八)之Android“.9.png”
参考 Android中.9图片的含义及制作教程 .9.png Android .9.png 的介绍
- JS基础_嵌套的for循环
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title&g ...
- spring-test跟junit结合单元测试获取ApplicationContext实例的方法
步骤 1.继承AbstractJUnit4SpringContextTests 2.引入ApplicationContext 示例代码:(可以根据name或者类型获取bean) import or ...