TCP拥塞控制算法
本篇文章介绍了几种经典的TCP拥塞控制算法,包括算法原理及各自适用场景。
回顾上篇文章:浅谈 redis 延迟
前言
TCP 通过维护一个拥塞窗口来进行拥塞控制,拥塞控制的原则是,只要网络中没有出现拥塞,拥塞窗口的值就可以再增大一些,以便把更多的数据包发送出去,但只要网络出现拥塞,拥塞窗口的值就应该减小一些,以减少注入到网络中的数据包数。
TCP 拥塞控制算法发展的过程中出现了如下几种不同的思路:
基于丢包的拥塞控制:将丢包视为出现拥塞,采取缓慢探测的方式,逐渐增大拥塞窗口,当出现丢包时,将拥塞窗口减小,如 Reno、Cubic 等。
基于时延的拥塞控制:将时延增加视为出现拥塞,延时增加时增大拥塞窗口,延时减小时减小拥塞窗口,如 Vegas、FastTCP 等。
基于链路容量的拥塞控制:实时测量网络带宽和时延,认为网络上报文总量大于带宽时延乘积时出现了拥塞,如 BBR。
基于学习的拥塞控制:没有特定的拥塞信号,而是借助评价函数,基于训练数据,使用机器学习的方法形成一个控制策略,如 Remy。
拥塞控制算法的核心是选择一个有效的策略来控制拥塞窗口的变化,下面介绍几种经典的拥塞控制算法。
Vegas
Vegas[1] 将时延 RTT 的增加作为网络出现拥塞的信号,RTT 增加,拥塞窗口减小,RTT 减小,拥塞窗口增加。具体来说,Vegas 通过比较实际吞吐量和期望吞吐量来调节拥塞窗口的大小,
期望吞吐量:Expected = cwnd / BaseRTT,
实际吞吐量:Actual = cwnd / RTT,
diff = (Expected-Actual) * BaseRTT,
BaseRTT 是所有观测来回响应时间的最小值,一般是建立连接后所发的第一个数据包的 RTT,cwnd 是目前的拥塞窗口的大小。Vegas 定义了两个阈值 a,b,当 diff > b 时,拥塞窗口减小,当 a <= diff <=b 时,拥塞窗口不变,当 diff < a 时,拥塞窗口增加。
Vegas 算法采用 RTT 的改变来判断网络的可用带宽,能精确地测量网络的可用带宽,效率比较好。但是,网络中 Vegas 与其它算法共存的情况下,基于丢包的拥塞控制算法会尝试填满网络中的缓冲区,导致 Vegas 计算的 RTT 增大,进而降低拥塞窗口,使得传输速度越来越慢,因此 Vegas 未能在 Internet 上普遍采用。
适用场景:
适用于网络中只存在 Vegas 一种拥塞控制算法,竞争公平的情况。
Reno
Reno[2] 将拥塞控制的过程分为四个阶段:慢启动、拥塞避免、快重传和快恢复,是现有的众多拥塞控制算法的基础,下面详细说明这几个阶段。
慢启动阶段,在没有出现丢包时每收到一个 ACK 就将拥塞窗口大小加一(单位是 MSS,最大单个报文段长度),每轮次发送窗口增加一倍,呈指数增长,若出现丢包,则将拥塞窗口减半,进入拥塞避免阶段;当窗口达到慢启动阈值或出现丢包时,进入拥塞避免阶段,窗口每轮次加一,呈线性增长;当收到对一个报文的三个重复的 ACK 时,认为这个报文的下一个报文丢失了,进入快重传阶段,立即重传丢失的报文,而不是等待超时重传;快重传完成后进入快恢复阶段,将慢启动阈值修改为当前拥塞窗口值的一半,同时拥塞窗口值等于慢启动阈值,然后进入拥塞避免阶段,重复上诉过程。Reno 拥塞控制过程如图 1 所示。
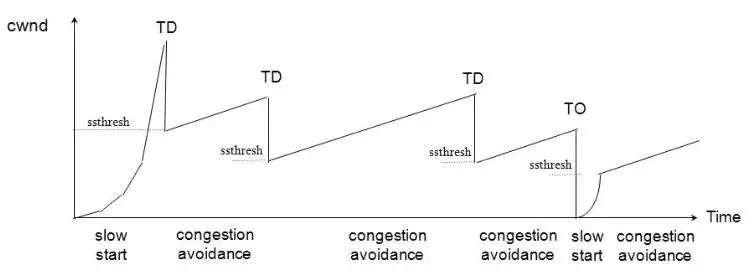
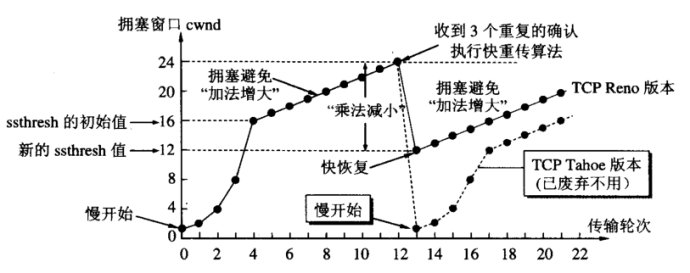
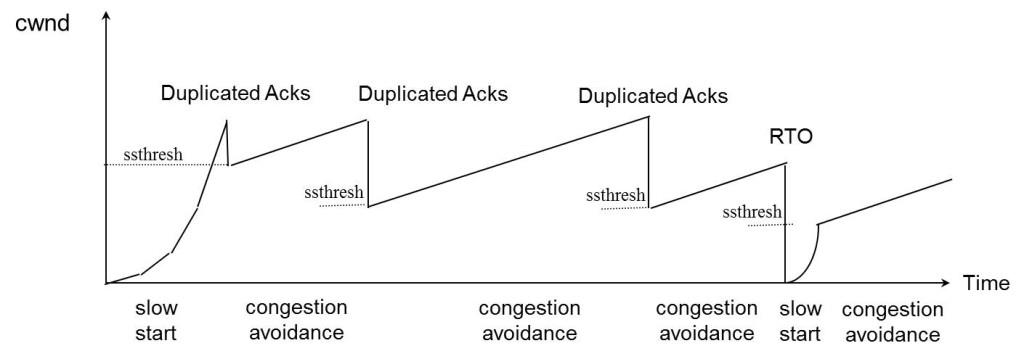
图 1、TCP Reno 拥塞控制过程
Reno 算法将收到 ACK 这一信号作为拥塞窗口增长的依据,在早期低带宽、低时延的网络中能够很好的发挥作用,但是随着网络带宽和延时的增加,Reno 的缺点就渐渐体现出来了,发送端从发送报文到收到 ACK 经历一个 RTT,在高带宽延时(High Bandwidth-Delay Product,BDP)网络中,RTT 很大,导致拥塞窗口增长很慢,传输速度需要经过很长时间才能达到最大带宽,导致带宽利用率将低。
适用场景:
适用于低延时、低带宽的网络。
Cubic
Cubic[3] 是 Linux 内核 2.6 之后的默认 TCP 拥塞控制算法,使用一个立方函数(cubic function)
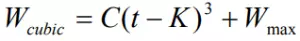
作为拥塞窗口的增长函数,其中,C 是调节因子,t 是从上一次缩小拥塞窗口经过的时间,Wmax 是上一次发生拥塞时的窗口大小,
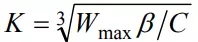
β是乘法减小因子。从函数中可以看出拥塞窗口的增长不再与 RTT 有关,而仅仅取决上次发生拥塞时的最大窗口和距离上次发生拥塞的时间间隔值。
Cubic 拥塞窗口增长曲线如下,凸曲线部分为稳定增长阶段,凹曲线部分为最大带宽探测阶段。如图 2 所示,在刚开始时,拥塞窗口增长很快,在接近 Wmax 口时,增长速度变的平缓,避免流量突增而导致丢包;在 Wmax 附近,拥塞窗口不再增加;之后开始缓慢地探测网络最大吞吐量,保证稳定性(在 Wmax 附近容易出现拥塞),在远离 Wmax 后,增大窗口增长的速度,保证了带宽的利用率。

图 2、TCP Cubic 拥塞窗口增长函数
当出现丢包时,将拥塞窗口进行乘法减小,再继续开始上述增长过程。此方式可以使得拥塞窗口一直维持在 Wmax 附近,从而保证了带宽的利用率。Cubic 的拥塞控制过程如图 3 所示:
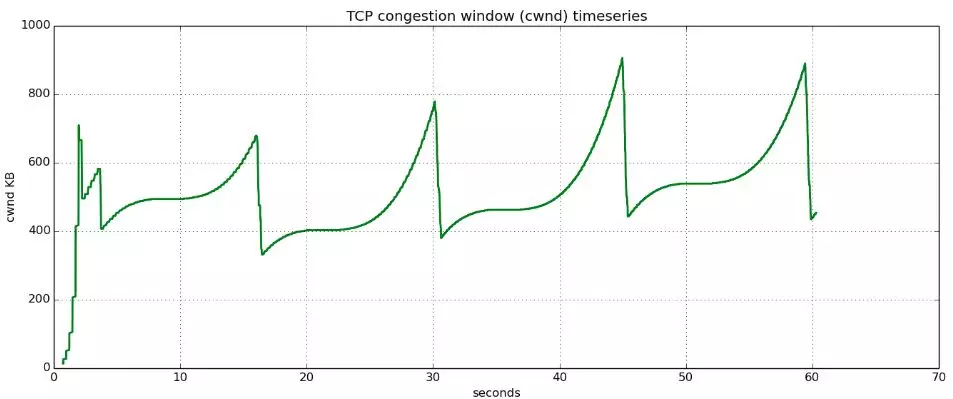
图 3、TCP Cubic 拥塞控制过程
Cubic 算法的优点在于只要没有出现丢包,就不会主动降低自己的发送速度,可以最大程度的利用网络剩余带宽,提高吞吐量,在高带宽、低丢包率的网络中可以发挥较好的性能。
但是,Cubic 同之前的拥塞控制算法一样,无法区分拥塞丢包和传输错误丢包,只要发现丢包,就会减小拥塞窗口,降低发送速率,而事实上传输错误丢包时网络不一定发生了拥塞,但是传输错误丢包的概率很低,所以对 Cubic 算法的性能影响不是很大。
Cubic 算法的另一个不足之处是过于激进,在没有出现丢包时会不停地增加拥塞窗口的大小,向网络注入流量,将网络设备的缓冲区填满,出现 Bufferbloat(缓冲区膨胀)。由于缓冲区长期趋于饱和状态,新进入网络的的数据包会在缓冲区里排队,增加无谓的排队时延,缓冲区越大,时延就越高。另外 Cubic 算法在高带宽利用率的同时依然在增加拥塞窗口,间接增加了丢包率,造成网络抖动加剧。
适用场景:
适用于高带宽、低丢包率网络,能够有效利用带宽。
BBR
BBR[4] 是谷歌在 2016 年提出的一种新的拥塞控制算法,已经在 Youtube 服务器和谷歌跨数据中心广域网上部署,据 Youtube 官方数据称,部署 BBR 后,在全球范围内访问 Youtube 的延迟降低了 53%,在时延较高的发展中国家,延迟降低了 80%。目前 BBR 已经集成到 Linux 4.9 以上版本的内核中。
BBR 算法不将出现丢包或时延增加作为拥塞的信号,而是认为当网络上的数据包总量大于瓶颈链路带宽和时延的乘积时才出现了拥塞,所以 BBR 也称为基于拥塞的拥塞控制算法(Congestion-Based Congestion Control)。BBR 算法周期性地探测网络的容量,交替测量一段时间内的带宽极大值和时延极小值,将其乘积作为作为拥塞窗口大小(交替测量的原因是极大带宽和极小时延不可能同时得到,带宽极大时网络被填满造成排队,时延必然极大,时延极小时需要数据包不被排队直接转发,带宽必然极小),使得拥塞窗口始的值始终与网络的容量保持一致。
由于 BBR 的拥塞窗口是精确测量出来的,不会无限的增加拥塞窗口,也就不会将网络设备的缓冲区填满,避免了出现 Bufferbloat 问题,使得时延大大降低。如图 4 所示,网络缓冲区被填满时时延为 250ms,Cubic 算法会继续增加拥塞窗口,使得时延持续增加到 500ms 并出现丢包,整个过程 Cubic 一直处于高时延状态,而 BBR 由于不会填满网络缓冲区,时延一直处于较低状态。
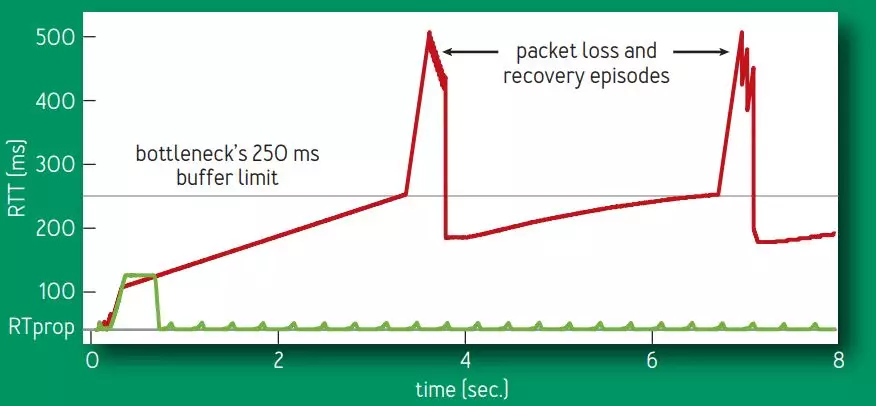
图 4、Cubic 和 BBR RTT 对比
由于 BBR 算法不将丢包作为拥塞信号,所以在丢包率较高的网络中,BBR 依然有极高的吞吐量,如图 5 所示,在 1% 丢包率的网络环境下,Cubic 的吞吐量已经降低 90% 以上,而 BBR 的吞吐量几乎没有受到影响,当丢包率大于 15% 时,BBR 的吞吐量才大幅下降。
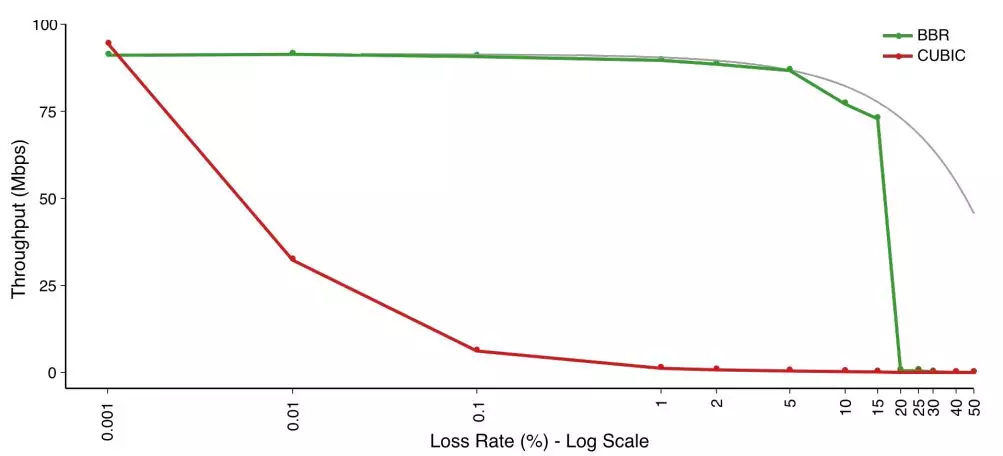
图 5、Cubic 和 BBR 传输速率与丢包率关系对比
BBR 算法是反馈驱动的,有自主调节机制,不受 TCP 拥塞控制状态机的控制,通过测量网络容量来调整拥塞窗口,发送速率由自己掌控,而传统的拥塞控制算法只负责计算拥塞窗口,而不管发送速率(pacing rate),怎么发由 TCP 自己决定,这样会在瓶颈带宽附近因发送速率的激增导致数据包排队或出现丢包。
经过测试,在高延时、高丢包率的环境下,BBR 相对于 Cubic 算法在传输速度上有较大的提升,具体的测试结果表 1 所示:
表1 200ms 延时下 Cubic 与 BBR 传输速度对比

BBR 算法的不足之处在于设备队列缓存较大时,BBR 可能会竞争不过 Cubic 等比较激进算法,原因是 BBR 不主动去占据队列缓存,如果 Cubic 的流量长期占据队列缓存,会使得 BBR 在多个周期内测量的极小 RTT 增大,进而使 BBR 的带宽减小。
适用场景:
适用于高带宽、高时延、有一定丢包率的长肥网络,可以有效降低传输时延,并保证较高的吞吐量。
Remy
Remy[5] 也称为计算机生成的拥塞控制算法(computer-generated congestion-control algorithm),采用机器学习的方式生成拥塞控制算法模型。通过输入各种参数模型(如瓶颈链路速率、时延、瓶颈链路上的发送者数量等),使用一个目标函数定量判断算法的优劣程度,在生成算法的过程中,针对不同的网络状态采用不同的方式调整拥塞窗口,反复修改调节方式,直到目标函数最优,最终会生成一个网络状态到调节方式的映射表,在真实的网络中,根据特定的网络环境从映射表直接选取拥塞窗口的调节方式。
Remy 试图屏蔽底层网络环境的差异,采用一个通用的拥塞控制算法模型来处理不同的网络环境。这种方式比较依赖输入的训练集(历史网络模型),如果训练集能够全面覆盖所有可能出现的网络环境及拥塞调节算法,Remy 算法在应用到真实的网络环境中时能够表现的很好,但是如果真实网络与训练网络差异较大,Remy 算法的性能会比较差。
适用场景:网络环境为复杂的异构网络,希望计算机能够针对不同网络场景自动选择合适的拥塞控制方式,要求现有的网络模型能够覆盖所有可能出现情况。
总结
每一种拥塞控制算法都是在一定的网络环境下诞生的,适合特定的场景,没有一种一劳永逸的算法。网络环境越来越复杂,拥塞控制算法也在不断地演进。本文不是要去选择一个最好的算法,只是简单介绍了几种典型算法的设计思路、优缺点以及适用场景,希望能给大家带来一些启发。
参考论文
[1] S.O. L. Brakmo and L. Peterson. TCP Vegas: New techniques for congestiondetection and avoidance. In SIGCOMM, 1994. Proceedings. 1994 InternationalConference on. ACM, 1994.
[2] V.Jacobson, “Congestion avoidance and control,” in ACM SIGCOMM ComputerCommunication Review, vol. 18. ACM, 1988, pp. 314–329.
[3] L. X. I. R. Sangtae Ha. Cubic: A new TCP -friendlyhigh-speed TCP variant. In SIGOPS-OSR, July 2008. ACM, 2008.
[4] C.S. G. S. H. Y. Neal Cardwell, Yuchung Cheng and V. Jacobson. BBR:congestion-based congestion control. ACM Queue, 14(5):20{53, 2016.
[5] K.Winstein and H. Balakrishnan. TCP Ex Machina: Computer-generated Congestion Control.In Proceedings of the ACM SIGCOMM 2013 Conference, 2013.
TCP拥塞控制算法的更多相关文章
- TCP拥塞控制算法 优缺点 适用环境 性能分析
[摘要]对多种TCP拥塞控制算法进行简要说明,指出它们的优缺点.以及它们的适用环境. [关键字]TCP拥塞控制算法 优点 缺点 适用环境公平性 公平性 公平性是在发生拥塞时各源端(或同一源端 ...
- 网络拥塞控制(三) TCP拥塞控制算法
为了防止网络的拥塞现象,TCP提出了一系列的拥塞控制机制.最初由V. Jacobson在1988年的论文中提出的TCP的拥塞控制由“慢启动(Slow start)”和“拥塞避免(Congestion ...
- 让人非常easy误解的TCP拥塞控制算法
正文 非常多人会觉得一个好的TCP拥塞控制算法会让连接加速,这样的观点是错误的.恰恰相反,全部的拥塞控制算法都是为了TCP能够在贪婪的时候悬崖勒马,大多数时候.拥塞控制是减少了数据发送的速度. 我在本 ...
- 浅谈TCP拥塞控制算法
TCP通过维护一个拥塞窗口来进行拥塞控制,拥塞控制的原则是,只要网络中没有出现拥塞,拥塞窗口的值就可以再增大一些,以便把更多的数据包发送出去,但只要网络出现拥塞,拥塞窗口的值就应该减小一些,以减少注入 ...
- TCP拥塞控制算法纵横谈-Illinois和YeAH
周五晚上.终于下了雨.所以也终于能够乱七八糟多写点松散的东西了... 方法论问题. 这个题目太大以至于内容和题目的关联看起来有失偏颇.只是也无所谓,既然被人以为"没有方法论"而歧视 ...
- Linux TCP拥塞控制算法原理解析
这里只是简单梳理TCP各版本的控制原理,对于基本的变量定义,可以参考以下链接: TCP基本拥塞控制http://blog.csdn.net/sicofield/article/details/9708 ...
- TCP拥塞控制算法之NewReno和SACK
TCP拥塞控制算法之NewReno和SACK 2018年05月23日 19:10:03 吃吃爱学习 阅读数:1446 版权声明:程序媛吃吃的博客 https://blog.csdn.net/m0 ...
- 【转载】TCP拥塞控制算法 优缺点 适用环境 性能分析
[摘要]对多种TCP拥塞控制算法进行简要说明,指出它们的优缺点.以及它们的适用环境. [关键字]TCP拥塞控制算法 优点 缺点 适用环境公平性 公平性 公平性是在发生拥塞时各源端(或同一源端 ...
- TCP拥塞控制算法内核实现剖析(十)
内核版本:3.2.12 主要源文件:linux-3.2.12/ net/ ipv4/ tcp_veno.c 主要内容:Veno的原理和实现 Author:zhangskd @ csdn blog 概要 ...
随机推荐
- LeetCode 腾讯精选50题--求众数
由于众数是指数组中相同元素的个数超过数组长度的一半,所以有两种思路,一. 先排序,后取排序后的数组的中间位置的值:二. 统计,设定一个变量统计相同元素出现的次数,遍历数组,若与选定的元素相同,统计变量 ...
- 浏览器本质上是解析器javascript
浏览器本质上是解析器.用于将符合W3C的标记序列解析并还原到编码人员希望用户看到的呈现状态.实际上,Word本身也可以看作是一个文档文件浏览器,acdsee是一个图像文件解析器(浏览器).HTML文件 ...
- scroll滚动条掩藏
掩藏scroll滚动条::-webkit-scrollbar ::-webkit-scrollbar {} /* 1 */ ::-webkit-scrollbar-button {} /* 2 */ ...
- element ui的照片墙 默认显示照片
参考地址: element ui的照片墙 默认显示照片 照片显示的数据格式是:[{name: '', url: ''}],:file-list=""默认显示的图片 实际项目开发中需 ...
- Android SQLiteDatabase的使用
package com.shawn.test; import android.content.ContentValues; import android.content.Context; import ...
- 为什么有了uwsgi还要nginx这个“前端”服务器
相信每一个使用nginx+uwsgi+django部署过的人,都感到非常复杂.到底为什么一个项目的发布要经过这么多层级,他们每一层有什么理由存在?这就带大家宏观地看待一下 首先nginx 是对外的服务 ...
- 【2】Git仓库
一.获取 Git 仓库 初始化仓库 ##基于当前目录初始化仓库 $ git init ##指定demo目录初始化仓库 $ git init demo 克隆现有仓库 ##克隆现有的仓库,默认目录名:li ...
- Airflow安装异常:ERROR: flask-appbuilder 1.12.3 has requirement Flask<2,>=0.12, but you'll have flask 0.11.1 which is incompatible.
1 详细异常: ERROR: flask-appbuilder 1.12.3 has requirement Flask<2,>=0.12, but you'll have flask 0 ...
- Oralce问题之ORA-12560:TNS协议适配器错误
在Windows系统中,通过CMD命令打开命令窗口,通过命令:sqlplus / as sysdba回车后提示 协议适配器错误 可能原因: (1).Oralce数据库监听服务没启动起来 通过开始-&g ...
- windows BAT脚本2个服务器间传递文件
1. 脚本功能: 实现2个服务器间文件的传递,例如从A服务器往B服务器上传文件 2. 实现步骤: 2.1 服务器连结,找到指定路径,读取所需要上传的文件,将文件名称复制到一个文件下 (此处考虑可能需要 ...