推荐排序---Learning to Rank:从 pointwise 和 pairwise 到 listwise,经典模型与优缺点
转载:https://blog.csdn.net/lipengcn/article/details/80373744
Ranking 是信息检索领域的基本问题,也是搜索引擎背后的重要组成模块。
本文将对结合机器学习的 ranking 技术——learning2rank——做个系统整理,包括 pointwise、pairwise、listwise 三大类型,它们的经典模型,解决了什么问题,仍存在什么缺陷。
Pointwise 类方法,其 L2R 框架具有以下特征:
- 输入空间中样本是单个 doc(和对应 query)构成的特征向量;
- 输出空间中样本是单个 doc(和对应 query)的相关度;
- 假设空间中样本是打分函数;
- 损失函数评估单个 doc 的预测得分和真实得分之间差异。
Pairwise 类方法,其 L2R 框架具有以下特征:
- 输入空间中样本是(同一 query 对应的)两个 doc(和对应 query)构成的两个特征向量;
- 输出空间中样本是 pairwise preference;
- 假设空间中样本是二变量函数;
- 损失函数评估 doc pair 的预测 preference 和真实 preference 之间差异。
Listwise 类方法,其 L2R 框架具有以下特征:
- 输入空间中样本是(同一 query 对应的)所有 doc(与对应的 query)构成的多个特征向量(列表);
- 输出空间中样本是这些 doc(和对应 query)的相关度排序列表或者排列;
- 假设空间中样本是多变量函数,对于 docs 得到其排列,实践中,通常是一个打分函数,根据打分函数对所有 docs 的打分进行排序得到 docs 相关度的排列;
- 损失函数分成两类,一类是直接和评价指标相关的,还有一类不是直接相关的。具体后面介绍。
本文主要参考刘铁岩老师的《Learning to Rank for Information Retrieval》和李航老师的《Learning to rank for information retrieval and natural language processing》。
1、概述
1.1 Ranking
Ranking 模型可以粗略分为基于相关度和基于重要性进行排序的两大类。
- 基于相关度的模型,通常利用 query 和 doc 之间的词共现特性(如布尔模型)、VSM向量空间模型(如 TFIDF、LSI 等)、概率排序思想(BM25、LMIR 等)等方式。
- 基于重要性的模型,利用的是 doc 本身的重要性,如 PageRank、TrustRank 等。
这里我们关注基于相关度的 ranking。
相关度的标注
最流行也相对好实现的一样方式时,人工标注 MOS,即相关度等级。
其次是,人工标注 pairwise preference,即一个 doc 是否相对另一个 doc 与该 query 更相关。
最 costly 的方式是,人工标注 docs 与 query 的整体相关度排序。
评估指标
即评估 query 与 docs 之间的真实排序与预测排序的差异。
大部分评估指标都是针对每组 query-docs 进行定义,然后再在所有组上进行平均。常用的基于度量的 ranking 错误率如下
MAP
首先,suppose we have binary judgment for the documents, i.e., the label is one for relevant documents and zero for irrelevant documents,定义docs 排序列表 π 中位置 k 的 precision 为
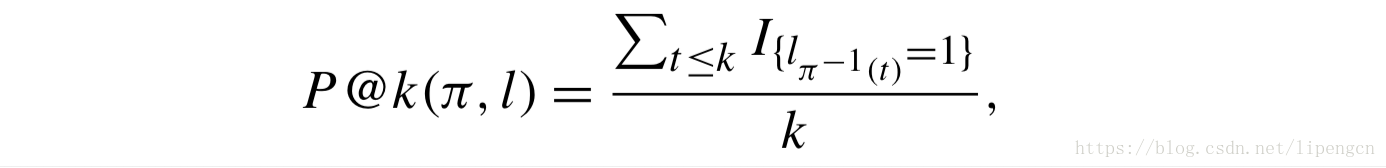
其次,令 m 为该 query 对应的 docs 数量,m_1 为该 query 对应的标签为1的 docs 数量,则有 average precision(AP)为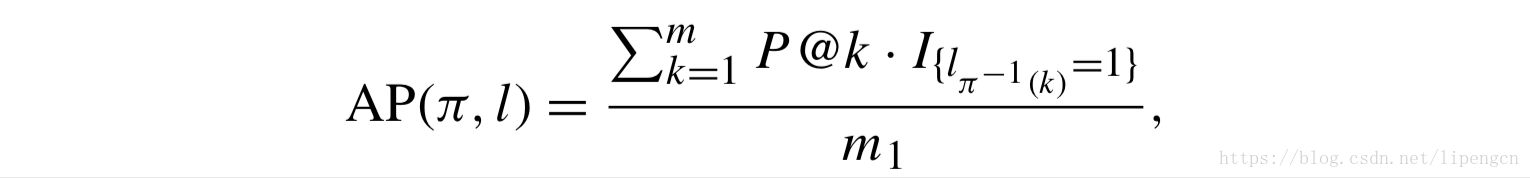
最后,对所有 query 求得 AP 进行平均,即得到 MAP。
NDCG
首先,Discounted cumulative gain (DCG)考量了 relevance judgment in terms of multiple ordered categories,以及对位置信息进行了折扣考量。定义 docs 排序列表 π 中位置 k 的 DCG 为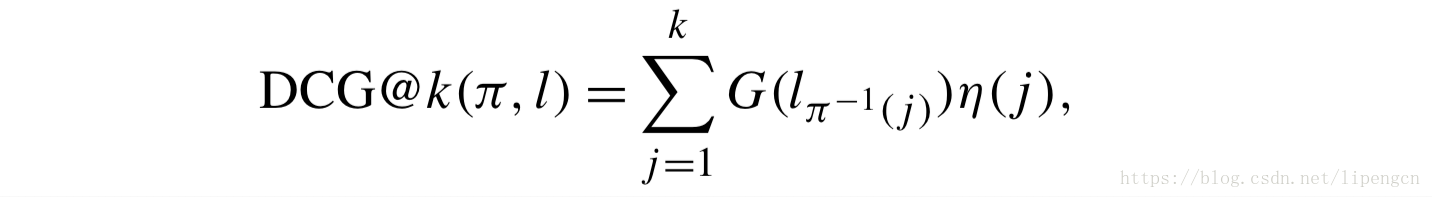
其中,函数 G 是 对应 doc 的 rating 值,通常采用指数函数,如 G(x)=2^x-1,函数 η 即位置折扣因子,通常采用 η(j)=1/log(j+1)。
其次,对 DCG@k 进行归一化,规整到0-1,Z_k 表示 DCG@k 的可能最大值,从而有 NDCG
可以发现,这些评估指标具备两大特性:
基于 query ,即不管一个 query 对应的 docs 排序有多糟糕,也不会严重影响整体的评价过程,因为每组 query-docs 对平均指标都是相同的贡献。
基于 position ,即显式的利用了排序列表中的位置信息,这个特性的副作用就是上述指标是离散不可微的。
一方面,这些指标离散不可微,从而没法应用到某些学习算法模型上;另一方面,这些评估指标较为权威,通常用来评估基于各类方式训练出来的 ranking 模型。因此,即使某些模型提出新颖的损失函数构造方式,也要受这些指标启发,符合上述两个特性才可以。这些细节在后面会慢慢体会到。
1.2 Learning to Rank
Learning2Rank 即将 ML 技术应用到 ranking 问题,训练 ranking 模型。通常这里应用的是判别式监督 ML 算法。经典 L2R 框架如下
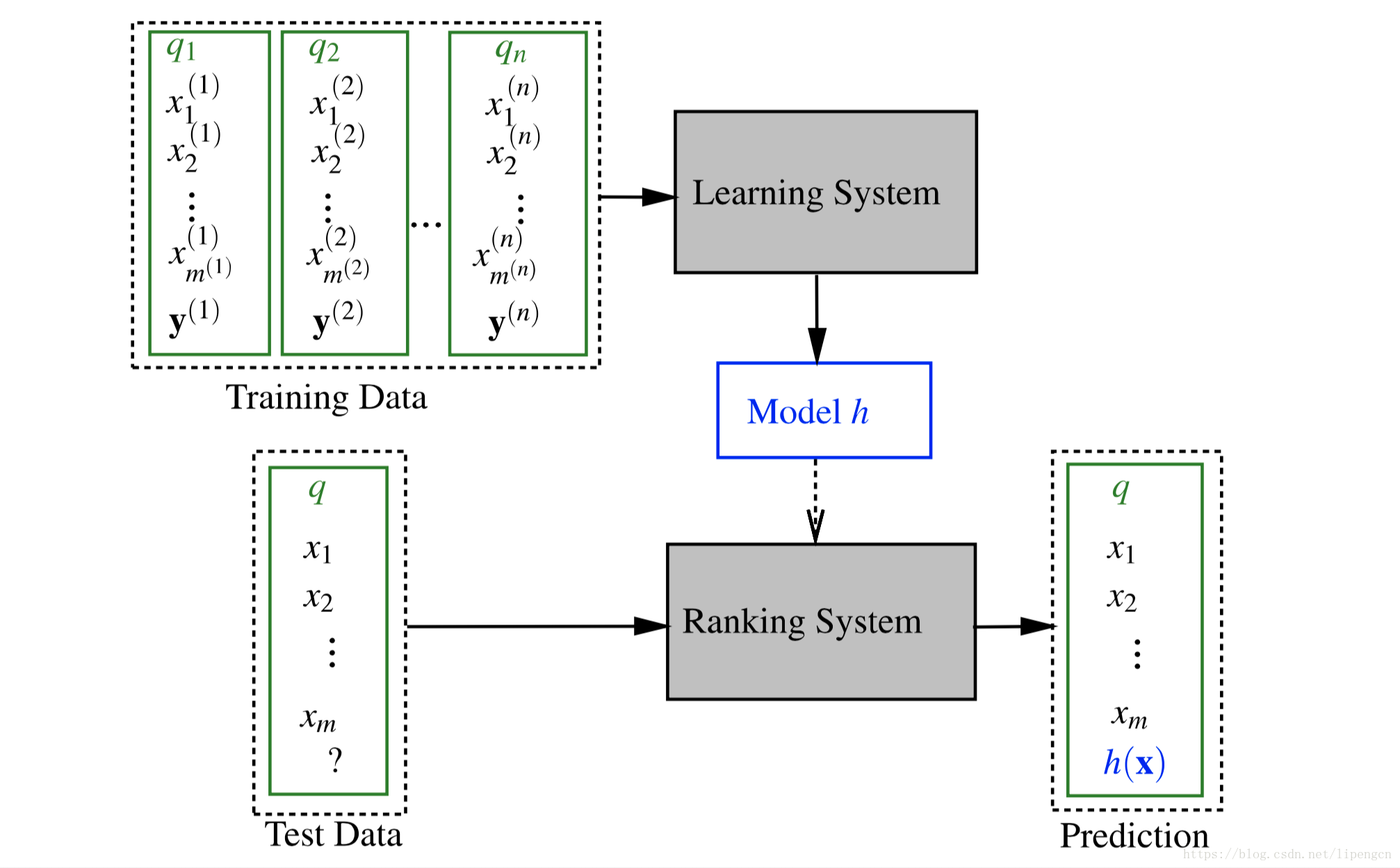
- 特征向量 x 反映的是某 query 及其对应的某 doc 之间的相关性,通常前面提到的传统 ranking 相关度模型都可以用来作为一个维度使用。
- L2R 中使用的监督机器学习方法主要是判别式类。
推荐排序---Learning to Rank:从 pointwise 和 pairwise 到 listwise,经典模型与优缺点的更多相关文章
- Learning to Rank:Point-wise、Pair-wise 和 List-wise区别
机器学习的 ranking 技术——learning2rank,包括 pointwise.pairwise.listwise 三大类型. [Ref-1]给出的: <Point wise rank ...
- Learning to Rank:pointwise, pairwise, listwise 总结
值得看: 刘铁岩老师的<Learning to Rank for Information Retrieval>和李航老师的<Learning to rank for informat ...
- 搜索排序-learning to Rank简介
Learning to Rank pointwise \[ L\left(f ; x_{j}, y_{j}\right)=\left(y_{j}-f\left(x_{j}\right)\right)^ ...
- Learning to rank相关的pointwise,pairwise,listwise
论文分享--- >Learning to Rank: From Pairwise Approach to Listwise Approach 学习排序 Learning to Rank 小结 [ ...
- Learning to rank 介绍
PS:文章主要转载自CSDN大神hguisu的文章"机器学习排序": http://blog.csdn.net/hguisu/article/details/79 ...
- Learning to rank基本算法
搜索排序相关的方法,包括 Learning to rank 基本方法 Learning to rank 指标介绍 LambdaMART 模型原理 FTRL 模型原理 Learning to rank ...
- [Machine Learning] Learning to rank算法简介
声明:以下内容根据潘的博客和crackcell's dustbin进行整理,尊重原著,向两位作者致谢! 1 现有的排序模型 排序(Ranking)一直是信息检索的核心研究问题,有大量的成熟的方法,主要 ...
- learning to rank
Learning to Rank入门小结 + 漫谈 Learning to Rank入门小结 Table of Contents 1 前言 2 LTR流程 3 训练数据的获取4 特征抽取 3.1 人工 ...
- Learning to Rank 简介
转自:http://www.cnblogs.com/kemaswill/archive/2013/06/01/3109497.html,感谢分享! 本文将对L2R做一个比较深入的介绍,主要参考了刘铁岩 ...
随机推荐
- 2.app自动化测试--adb常用API
adb常用API Driver.current_activity 获取当前运行应用界面的启动名 Driver.current_package 获取当前运行应用的包名 Driver.contexts ...
- C语言获取文件大小相关操作
C语言获取文件大小相关操作 声明:引用请注明出处http://blog.csdn.net/lg1259156776/ 说明 通常在希望从文件中把数据全都出来赋值给一个数组或者某一个指针,然后再进行相关 ...
- Python数据分析练手:分析知乎大V
原文链接:https://zhuanlan.zhihu.com/p/92768131?utm_source=tuicool&utm_medium=referral 知乎,可以说是国内目前最大的 ...
- ROS学习(二)运行keyboard
1.ssh连接机器人 ./dora*.sh 启动roscore,相当于启动ros系统 roscore 2.另启终端,也就意味着重新ssh连接机器人, ./dora*.sh 运行wheel驱动 rosr ...
- 用户字符串操作,这里面包括字符串的decode、encode、substract等等操作
工具类描述:用户字符串操作,这里面包括字符串的decode.encode.substract等等操作 package cn.hgnulb; import java.io.UnsupportedEnco ...
- jmeter BeanShell实例-----两个变量之间的断言对比(转)
jmeter BeanShell实例-----两个变量之间的断言对比 在jmeter的中,断言没法对两个变量的进行对比后判断,只能使用Bean Shell断言来进行,总是有人来问怎么写呢.这里写一个简 ...
- T100——错误信息提示传入参数显示
LET l_str1 = l_xccc.xccc901LET l_str2 = l_inat015LET l_str = l_str1.trim(),'|',l_str2.trim() CALL cl ...
- scratch少儿编程第一季——04、想要做到有的放矢,瞄准方向很重要
各位小伙伴大家好: 上期我们学习了动作模块的前面三个指令,今天我们继续学习下面的5个指令. 首先来看第一个(控制方向): 面向90方向默认就是屏幕的右边. 点击白色文本框上面的▼可以打开下拉菜单. 大 ...
- 双重检查加锁机制(并发insert情况下数据重复插入问题的解决方案)
双重检查加锁机制(并发insert情况下数据重复插入问题的解决方案) c#中单例模式和双重检查锁 转:https://blog.csdn.net/zhongliangtang/article/deta ...
- sql 时间获取
现在时间:GETDATE() 昨天时间:CONVERT(VARCHAR(16),DATEADD(d,-1,GETDATE()),120)