20190724-Python网络数据采集/第 2 章 复杂HTML解析-导航树/正则表达式
1. 导航树
经典的HTML树状结构

直接看下面的代码示例:(注意目标网页的标签大小写等细节,易出bug)
from urllib.request import urlopen
from bs4 import BeautifulSoup html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsobj = BeautifulSoup(html) print(bsobj) # 打印giftlist表格中所有产品的数据行,注意代码中标签的大小写格式
for child in bsobj.find("table", {"id":"giftList"}).children: # 打印所有的后代标签
for child in bsobj.find("table", {"id":"giftList"}).descendants:
print(child) # 处理兄弟标签,可以选择表格中除标题(标签本身)外的所有行,或者所有兄弟标签
for sibling in bsobj.find("table",{"id":"giftList"}).tr.next_siblings:
print(sibling)
# 处理父标签,
# 1)选择图片标签src=".../";
# 2)选择图片标签的父标签(在示例中是<td>标签);
# 3)选择<td>标签的前一个兄弟标签previous_sibling(在示例中是包含美元价格的<td>标签);
# 4)选择标签中的文字,“$15.00”.
print(bsobj.find("img",{"src":".../img/gifts/img1.jpg"
}).parent.previous_sibing.get_text())
核心知识点,4个函数:
.children,处理子标签;
.descendants,处理后代标签;
.next_siblings,处理兄弟标签,尤其适用于处理表格,可以通过该函数选择表格中除标题行外的所有行。(1.对象不能把自己作为兄弟标签;2.该函数只调用后面的兄弟标签)
.parent,处理父标签,应用相对较少。 2. 正则表达式
正则表达式,识别 正则字符串。上手快,记住/懂常用规则/勤查文档即可,运行很快,比如在要求快速浏览大文档查,以查找像电话号码或者邮箱地址等类似的字符串时,非常方便。
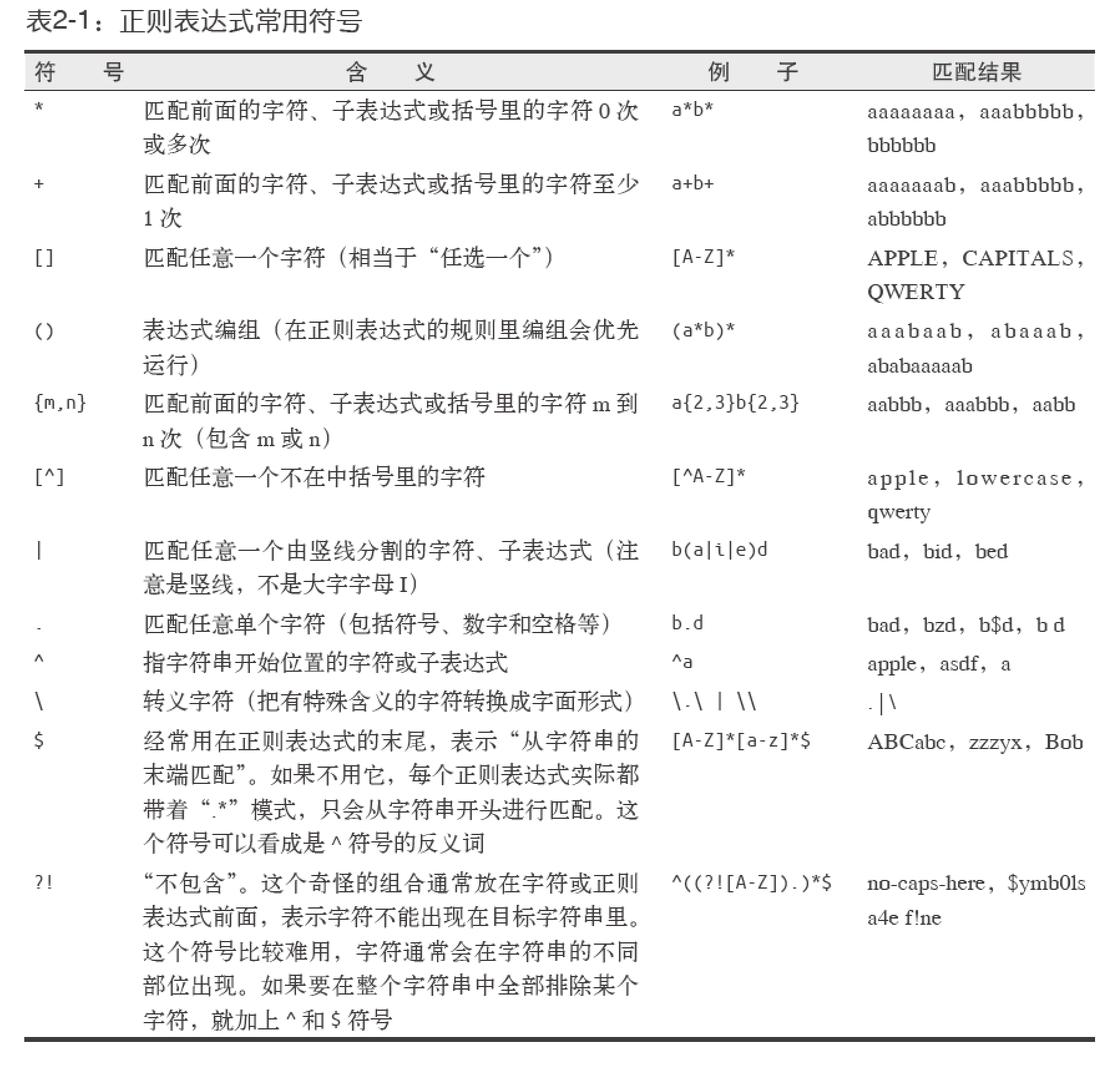
3. 正则表达式和BeautifulSoup
写正则表达式前,先写一个步骤列表描述出目标字符串结构。
正则表达式可以作为BeautifulSoup语句的任意一个参数。
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsobj = BeautifulSoup(html,"lxml") # 源网页图片路径代码 <img src="../img/gifts/img1.jpg">
images = bsobj.findAll("img",{"src":re.compile("\.\.\/img\/gifts/img.*\.jpg")})
for image in images:
print(image["src"]) 打印结果:
../img/gifts/img1.jpg
../img/gifts/img2.jpg
../img/gifts/img3.jpg
../img/gifts/img4.jpg
../img/gifts/img6.jpg
还有获取属性操作。。。
20190724-Python网络数据采集/第 2 章 复杂HTML解析-导航树/正则表达式的更多相关文章
- 20190716-Python网络数据采集/第 2 章 复杂HTML解析
# P29/9# 解析,要考虑到可持续性问题,对方反爬修改后,仍继续有效,方为优秀代码# 解析一个目标网页前,需要做到以下几点:(1)明确目标内容:(2)寻找“打印此页”的链接,或查看网站有无HTML ...
- 20190715《Python网络数据采集》第 1 章
<Python网络数据采集>7月8号-7月10号,这三天将该书精读一遍,脑海中有了一个爬虫大体框架后,对于后续学习将更加有全局感. 此前,曾试验看视频学习,但是一个视频基本2小时,全部拿下 ...
- Python网络数据采集PDF
Python网络数据采集(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/16c4GjoAL_uKzdGPjG47S4Q 提取码:febb 复制这段内容后打开百度网盘手 ...
- Python网络数据采集PDF高清完整版免费下载|百度云盘
百度云盘:Python网络数据采集PDF高清完整版免费下载 提取码:1vc5 内容简介 本书采用简洁强大的Python语言,介绍了网络数据采集,并为采集新式网络中的各种数据类型提供了全面的指导.第 ...
- 笔记之Python网络数据采集
笔记之Python网络数据采集 非原创即采集 一念清净, 烈焰成池, 一念觉醒, 方登彼岸 网络数据采集, 无非就是写一个自动化程序向网络服务器请求数据, 再对数据进行解析, 提取需要的信息 通常, ...
- Python网络数据采集7-单元测试与Selenium自动化测试
Python网络数据采集7-单元测试与Selenium自动化测试 单元测试 Python中使用内置库unittest可完成单元测试.只要继承unittest.TestCase类,就可以实现下面的功能. ...
- Python网络数据采集6-隐含输入字段
Python网络数据采集6-隐含输入字段 selenium的get_cookies可以轻松获取所有cookie. from pprint import pprint from selenium imp ...
- Python网络数据采集4-POST提交与Cookie的处理
Python网络数据采集4-POST提交与Cookie的处理 POST提交 之前访问页面都是用的get提交方式,有些网页需要登录才能访问,此时需要提交参数.虽然在一些网页,get方式也能提交参.比如h ...
- Python网络数据采集3-数据存到CSV以及MySql
Python网络数据采集3-数据存到CSV以及MySql 先热热身,下载某个页面的所有图片. import requests from bs4 import BeautifulSoup headers ...
随机推荐
- intel官方的手册
最近在学习汇编语言,需要用到intel的手册,无论是csdn还是其他的,都要下载币,还不便宜,也很老的资料了. 直接到这个地址:https://software.intel.com/en-us/art ...
- Ubuntu: Linux下查看本机显示器分辨率(xrandr)
版权声明:转载请注明出处 https://blog.csdn.net/JNingWei/article/details/75044598 Linux下查看本机显示器分辨率: $ xrandr Sc ...
- idea 使用maven 下载源码包
方式1:全量下载源码包 方式二:下载单个源码包 随便找个源码可以看到文件上有download (标识下载源码包) choose sources表示选择那个版本的源码包
- 全国计算机等级考试二级教程2019年版——Python语言程序设计参考答案
第二章 Python语言基本语法元素 一.选择题C B B C A D B A D B二.编程题1.获得用户输入的一个整数N,计算并输出N的32次方.在这里插入图片描述2.获得用户输入的一段文字,将这 ...
- I am a legend: Hacking Hearthstone with machine-learning Defcon talk wrap-up
I am a legend: Hacking Hearthstone with machine-learning Defcon talk wrap-up: video and slides avail ...
- ForkJoinPool 源码分析
ForkJoinPool ForkJoinPool 是一个运行 ForkJoinTask 任务.支持工作窃取和并行计算的线程池 核心参数+创建实例 // 工作者线程驻留任务队列索引位 static f ...
- Markdown使用TOC自动生成导航栏
经常使用markdown 的玩家一定很想要一个自动生成的导航栏吧,自己写的基本思路就是 轮询监听滚动条的位置,通过抛锚和跳锚实现,这里介绍一下今天的主角,markdown-toc插件: https:/ ...
- [maven]maven插件 tomcat7-maven-plugin 的使用
使用 tomcat7-maven-plugin,可以将tomcat内嵌到web项目中,直接运行webapp项目. 第一步.pom.xml的配置: <build> <plugins&g ...
- Qt自定义类添加qvector报错
PtsData& PtsData::operator=(const PtsData& obj){ return *this;} PtsData::~PtsData(){ }
- MR21修改标准价
转自:https://blog.csdn.net/qq_21813647/article/details/79195731 物料帐下只有物料的状态是初始状态才允许修改价格. 如果状态为已输入数量和值也 ...