目标检测之车辆行人(tensorflow版yolov3)
背景:
在自动驾驶中,基于摄像头的视觉感知,如同人的眼睛一样重要。而目前主流方案基本都采用深度学习方案(tensorflow等),而非传统图像处理(opencv等)。
接下来我们就以YOLOV3为基本网络模型,Tensorflow为基本框架,搭建一套能够自动识别路面上动态目标,如车辆,行人,骑行人等。
正文:
原生YOLOV3是基于darknet(纯C编写)开发的,这里我们会将YOLOV3架构在Tensorflow平台上(Python,C++跨平台多语言)。
关键点介绍:
一、基本的网络结构图:
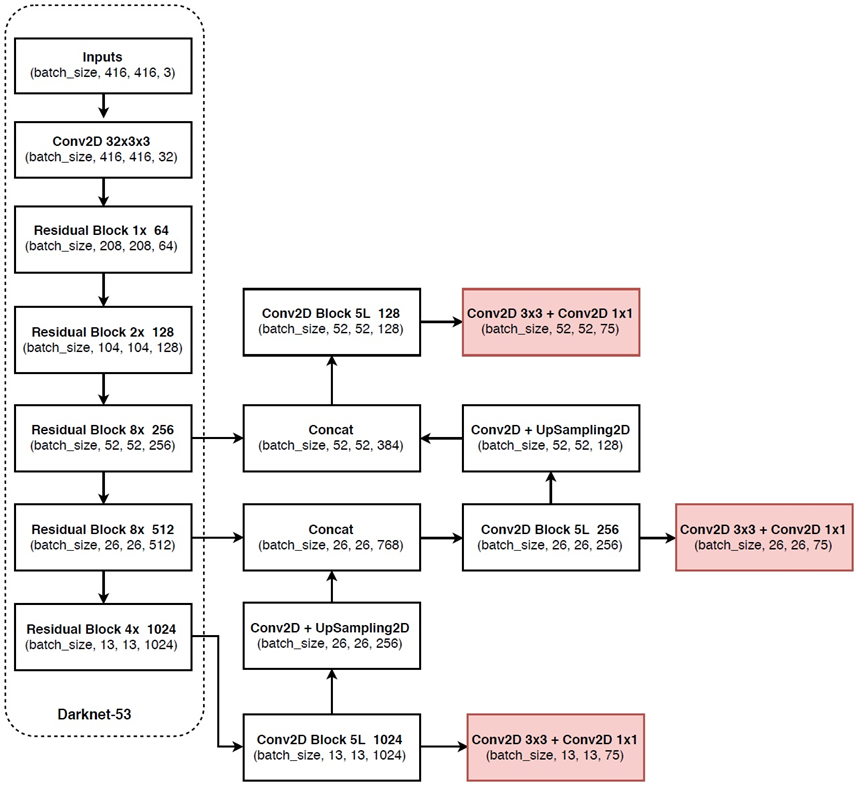
模型流程图如下:

基础主干网Darknet53:
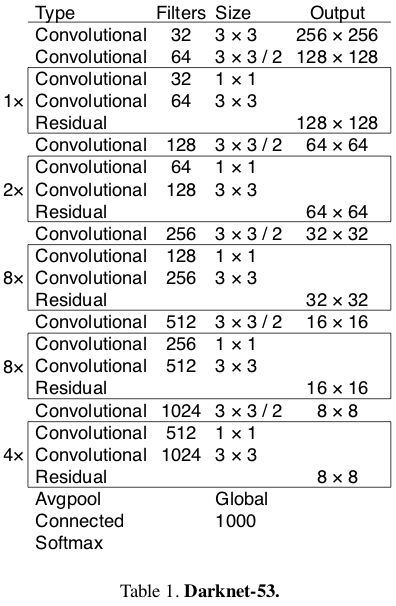
二、代码结构:
tf_yolov3
|-------extract_voc.py #从原始文件中生成训练所需数据格式
import os
import argparse
import xml.etree.ElementTree as ET # sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
sets=[('', 'train'), ('', 'val')] classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"] parser = argparse.ArgumentParser()
parser.add_argument("--voc_path", default="/home/yang/test/VOCdevkit/train/")
parser.add_argument("--dataset_info_path", default="./")
flags = parser.parse_args() def convert_annotation(year, image_id, list_file):
xml_path = os.path.join(flags.voc_path, 'VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
in_file = open(xml_path)
tree=ET.parse(in_file)
root = tree.getroot() for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text))
list_file.write(" " + " ".join([str(a) for a in b]) + " " + str(cls_id)) for year, image_set in sets:
text_path = os.path.join(flags.voc_path, 'VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set))
if not os.path.exists(text_path): continue
image_ids = open(text_path).read().strip().split()
list_file_path = os.path.join(flags.dataset_info_path, '%s_%s.txt'%(year, image_set))
list_file = open(list_file_path, 'w')
for image_id in image_ids:
image_path = os.path.join(flags.voc_path, 'VOCdevkit/VOC%s/JPEGImages/%s.jpg'%(year, image_id))
print("=>", image_path)
list_file.write(image_path)
convert_annotation(year, image_id, list_file)
list_file.write('\n')
list_file.close()
|-------make_voc_tfrecord.sh #制作tfrecord格式
python scripts/extract_voc.py --voc_path /home/yang/test/VOC/train/ --dataset_info_path ./
cat ./2007_train.txt ./2007_val.txt > voc_train.txt
python scripts/extract_voc.py --voc_path /home/yang/test/VOC/test/ --dataset_info_path ./
cat ./2007_test.txt > voc_test.txt
python core/convert_tfrecord.py --dataset_txt ./voc_train.txt --tfrecord_path_prefix /home/yang/test/VOC/train/voc_train
python core/convert_tfrecord.py --dataset_txt ./voc_test.txt --tfrecord_path_prefix /home/yang/test/VOC/test/voc_test
|-------convert_tfrecord.py # 转换原始数据成TFReocord格式
import sys
import argparse
import numpy as np
import tensorflow as tf def main(argv):
parser = argparse.ArgumentParser()
parser.add_argument("--dataset_txt", default='./data/dataset.txt')
parser.add_argument("--tfrecord_path_prefix", default='./data/tfrecords/dataset')
flags = parser.parse_args() dataset = {}
#
with open(flags.dataset_txt,'r') as f:
for line in f.readlines():
example = line.split(' ')
image_path = example[0]
boxes_num = len(example[1:]) // 5
boxes = np.zeros([boxes_num, 5], dtype=np.float32)
for i in range(boxes_num):
boxes[i] = example[1+i*5:6+i*5]
dataset[image_path] = boxes image_paths = list(dataset.keys())
images_num = len(image_paths)
print(">> Processing %d images" %images_num) tfrecord_file = flags.tfrecord_path_prefix+".tfrecords"
with tf.python_io.TFRecordWriter(tfrecord_file) as record_writer:
for i in range(images_num):
image = tf.gfile.FastGFile(image_paths[i], 'rb').read()
boxes = dataset[image_paths[i]]
boxes = boxes.tostring() example = tf.train.Example(features = tf.train.Features(
feature={
'image' :tf.train.Feature(bytes_list = tf.train.BytesList(value = [image])),
'boxes' :tf.train.Feature(bytes_list = tf.train.BytesList(value = [boxes])),
}
)) record_writer.write(example.SerializeToString())
print(">> Saving %d images in %s" %(images_num, tfrecord_file))
|-------dataset.py # 图片数据增强,数据加载
import cv2
import numpy as np
from core import utils
import tensorflow as tf class Parser(object):
def __init__(self, image_h, image_w, anchors, num_classes, debug=False): self.anchors = anchors
self.num_classes = num_classes
self.image_h = image_h
self.image_w = image_w
self.debug = debug def flip_left_right(self, image, gt_boxes): w = tf.cast(tf.shape(image)[1], tf.float32)
image = tf.image.flip_left_right(image) xmin, ymin, xmax, ymax, label = tf.unstack(gt_boxes, axis=1)
xmin, ymin, xmax, ymax = w-xmax, ymin, w-xmin, ymax
gt_boxes = tf.stack([xmin, ymin, xmax, ymax, label], axis=1) return image, gt_boxes def random_distort_color(self, image, gt_boxes): image = tf.image.random_brightness(image, max_delta=32./255.)
image = tf.image.random_saturation(image, lower=0.8, upper=1.2)
image = tf.image.random_hue(image, max_delta=0.2)
image = tf.image.random_contrast(image, lower=0.8, upper=1.2) return image, gt_boxes def random_blur(self, image, gt_boxes): gaussian_blur = lambda image: cv2.GaussianBlur(image, (5, 5), 0)
h, w = image.shape.as_list()[:2]
image = tf.py_func(gaussian_blur, [image], tf.uint8)
image.set_shape([h, w, 3]) return image, gt_boxes def random_crop(self, image, gt_boxes, min_object_covered=0.8, aspect_ratio_range=[0.8, 1.2], area_range=[0.5, 1.0]): h, w = tf.cast(tf.shape(image)[0], tf.float32), tf.cast(tf.shape(image)[1], tf.float32)
xmin, ymin, xmax, ymax, label = tf.unstack(gt_boxes, axis=1)
bboxes = tf.stack([ ymin/h, xmin/w, ymax/h, xmax/w], axis=1)
bboxes = tf.clip_by_value(bboxes, 0, 1)
begin, size, dist_boxes = tf.image.sample_distorted_bounding_box(
tf.shape(image),
bounding_boxes=tf.expand_dims(bboxes, axis=0),
min_object_covered=min_object_covered,
aspect_ratio_range=aspect_ratio_range,
area_range=area_range)
# NOTE dist_boxes with shape: [ymin, xmin, ymax, xmax] and in values in range(0, 1)
# Employ the bounding box to distort the image.
croped_box = [dist_boxes[0,0,1]*w, dist_boxes[0,0,0]*h, dist_boxes[0,0,3]*w, dist_boxes[0,0,2]*h] croped_xmin = tf.clip_by_value(xmin, croped_box[0], croped_box[2])-croped_box[0]
croped_ymin = tf.clip_by_value(ymin, croped_box[1], croped_box[3])-croped_box[1]
croped_xmax = tf.clip_by_value(xmax, croped_box[0], croped_box[2])-croped_box[0]
croped_ymax = tf.clip_by_value(ymax, croped_box[1], croped_box[3])-croped_box[1] image = tf.slice(image, begin, size)
gt_boxes = tf.stack([croped_xmin, croped_ymin, croped_xmax, croped_ymax, label], axis=1) return image, gt_boxes def preprocess(self, image, gt_boxes): ################################# data augmentation ##################################
# data_aug_flag = tf.to_int32(tf.random_uniform(shape=[], minval=-5, maxval=5)) # caseO = tf.equal(data_aug_flag, 1), lambda: self.flip_left_right(image, gt_boxes)
# case1 = tf.equal(data_aug_flag, 2), lambda: self.random_distort_color(image, gt_boxes)
# case2 = tf.equal(data_aug_flag, 3), lambda: self.random_blur(image, gt_boxes)
# case3 = tf.equal(data_aug_flag, 4), lambda: self.random_crop(image, gt_boxes) # image, gt_boxes = tf.case([caseO, case1, case2, case3], lambda: (image, gt_boxes)) image, gt_boxes = utils.resize_image_correct_bbox(image, gt_boxes, self.image_h, self.image_w) if self.debug: return image, gt_boxes y_true_13, y_true_26, y_true_52 = tf.py_func(self.preprocess_true_boxes, inp=[gt_boxes],
Tout = [tf.float32, tf.float32, tf.float32])
image = image / 255. return image, y_true_13, y_true_26, y_true_52 def preprocess_true_boxes(self, gt_boxes):
"""
Preprocess true boxes to training input format
Parameters:
-----------
:param true_boxes: numpy.ndarray of shape [T, 4]
T: the number of boxes in each image.
4: coordinate => x_min, y_min, x_max, y_max
:param true_labels: class id
:param input_shape: the shape of input image to the yolov3 network, [416, 416]
:param anchors: array, shape=[9,2], 9: the number of anchors, 2: width, height
:param num_classes: integer, for coco dataset, it is 80
Returns:
----------
y_true: list(3 array), shape like yolo_outputs, [13, 13, 3, 85]
13:cell szie, 3:number of anchors
85: box_centers, box_sizes, confidence, probability
"""
num_layers = len(self.anchors) // 3
anchor_mask = [[6,7,8], [3,4,5], [0,1,2]] if num_layers==3 else [[3,4,5], [1,2,3]]
grid_sizes = [[self.image_h//x, self.image_w//x] for x in (32, 16, 8)] box_centers = (gt_boxes[:, 0:2] + gt_boxes[:, 2:4]) / 2 # the center of box
box_sizes = gt_boxes[:, 2:4] - gt_boxes[:, 0:2] # the height and width of box gt_boxes[:, 0:2] = box_centers
gt_boxes[:, 2:4] = box_sizes y_true_13 = np.zeros(shape=[grid_sizes[0][0], grid_sizes[0][1], 3, 5+self.num_classes], dtype=np.float32)
y_true_26 = np.zeros(shape=[grid_sizes[1][0], grid_sizes[1][1], 3, 5+self.num_classes], dtype=np.float32)
y_true_52 = np.zeros(shape=[grid_sizes[2][0], grid_sizes[2][1], 3, 5+self.num_classes], dtype=np.float32) y_true = [y_true_13, y_true_26, y_true_52]
anchors_max = self.anchors / 2.
anchors_min = -anchors_max
valid_mask = box_sizes[:, 0] > 0 # Discard zero rows.
wh = box_sizes[valid_mask]
# set the center of all boxes as the origin of their coordinates
# and correct their coordinates
wh = np.expand_dims(wh, -2)
boxes_max = wh / 2.
boxes_min = -boxes_max intersect_mins = np.maximum(boxes_min, anchors_min)
intersect_maxs = np.minimum(boxes_max, anchors_max)
intersect_wh = np.maximum(intersect_maxs - intersect_mins, 0.)
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
box_area = wh[..., 0] * wh[..., 1] anchor_area = self.anchors[:, 0] * self.anchors[:, 1]
iou = intersect_area / (box_area + anchor_area - intersect_area)
# Find best anchor for each true box
best_anchor = np.argmax(iou, axis=-1) for t, n in enumerate(best_anchor):
for l in range(num_layers):
if n not in anchor_mask[l]: continue i = np.floor(gt_boxes[t,0]/self.image_w*grid_sizes[l][1]).astype('int32')
j = np.floor(gt_boxes[t,1]/self.image_h*grid_sizes[l][0]).astype('int32') k = anchor_mask[l].index(n)
c = gt_boxes[t, 4].astype('int32') y_true[l][j, i, k, 0:4] = gt_boxes[t, 0:4]
y_true[l][j, i, k, 4] = 1.
y_true[l][j, i, k, 5+c] = 1. return y_true_13, y_true_26, y_true_52 def parser_example(self, serialized_example): features = tf.parse_single_example(
serialized_example,
features = {
'image' : tf.FixedLenFeature([], dtype = tf.string),
'boxes' : tf.FixedLenFeature([], dtype = tf.string),
}
) image = tf.image.decode_jpeg(features['image'], channels = 3)
image = tf.image.convert_image_dtype(image, tf.uint8) gt_boxes = tf.decode_raw(features['boxes'], tf.float32)
gt_boxes = tf.reshape(gt_boxes, shape=[-1,5]) return self.preprocess(image, gt_boxes) class dataset(object):
def __init__(self, parser, tfrecords_path, batch_size, shuffle=None, repeat=True):
self.parser = parser
self.filenames = tf.gfile.Glob(tfrecords_path)
self.batch_size = batch_size
self.shuffle = shuffle
self.repeat = repeat
self._buildup() def _buildup(self):
try:
self._TFRecordDataset = tf.data.TFRecordDataset(self.filenames)
except:
raise NotImplementedError("No tfrecords found!") self._TFRecordDataset = self._TFRecordDataset.map(map_func = self.parser.parser_example,
num_parallel_calls = 10)
self._TFRecordDataset = self._TFRecordDataset.repeat() if self.repeat else self._TFRecordDataset if self.shuffle is not None:
self._TFRecordDataset = self._TFRecordDataset.shuffle(self.shuffle) self._TFRecordDataset = self._TFRecordDataset.batch(self.batch_size).prefetch(self.batch_size)
self._iterator = self._TFRecordDataset.make_one_shot_iterator() def get_next(self):
return self._iterator.get_next()
|-------utils.py # NMS,画检测框,从PB文件读取Tensors,计算MAP,FREEZE_GRAPH,加载权重文件,IOU计算
import colorsys
import numpy as np
import tensorflow as tf
from collections import Counter
from PIL import ImageFont, ImageDraw # Discard all boxes with low scores and high IOU
def gpu_nms(boxes, scores, num_classes, max_boxes=50, score_thresh=0.3, iou_thresh=0.5):
"""
/*----------------------------------- NMS on gpu ---------------------------------------*/ Arguments:
boxes -- tensor of shape [1, 10647, 4] # 10647 boxes
scores -- tensor of shape [1, 10647, num_classes], scores of boxes
classes -- the return value of function `read_coco_names`
Note:Applies Non-max suppression (NMS) to set of boxes. Prunes away boxes that have high
intersection-over-union (IOU) overlap with previously selected boxes. max_boxes -- integer, maximum number of predicted boxes you'd like, default is 20
score_thresh -- real value, if [ highest class probability score < score_threshold]
then get rid of the corresponding box
iou_thresh -- real value, "intersection over union" threshold used for NMS filtering
""" boxes_list, label_list, score_list = [], [], []
max_boxes = tf.constant(max_boxes, dtype='int32') # since we do nms for single image, then reshape it
boxes = tf.reshape(boxes, [-1,4]) # '-1' means we don't konw the exact number of boxes
# confs = tf.reshape(confs, [-1,1])
score = tf.reshape(scores, [-1,num_classes]) # Step 1: Create a filtering mask based on "box_class_scores" by using "threshold".
mask = tf.greater_equal(score, tf.constant(score_thresh))
# Step 2: Do non_max_suppression for each class
for i in range(num_classes):
# Step 3: Apply the mask to scores, boxes and pick them out
filter_boxes = tf.boolean_mask(boxes, mask[:,i])
filter_score = tf.boolean_mask(score[:,i], mask[:,i])
nms_indices = tf.image.non_max_suppression(boxes=filter_boxes,
scores=filter_score,
max_output_size=max_boxes,
iou_threshold=iou_thresh, name='nms_indices')
label_list.append(tf.ones_like(tf.gather(filter_score, nms_indices), 'int32')*i)
boxes_list.append(tf.gather(filter_boxes, nms_indices))
score_list.append(tf.gather(filter_score, nms_indices)) boxes = tf.concat(boxes_list, axis=0)
score = tf.concat(score_list, axis=0)
label = tf.concat(label_list, axis=0) return boxes, score, label def py_nms(boxes, scores, max_boxes=50, iou_thresh=0.5):
"""
Pure Python NMS baseline. Arguments: boxes => shape of [-1, 4], the value of '-1' means that dont know the
exact number of boxes
scores => shape of [-1,]
max_boxes => representing the maximum of boxes to be selected by non_max_suppression
iou_thresh => representing iou_threshold for deciding to keep boxes
"""
assert boxes.shape[1] == 4 and len(scores.shape) == 1 x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3] areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1] keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]]) w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter) inds = np.where(ovr <= iou_thresh)[0]
order = order[inds + 1] return keep[:max_boxes] def cpu_nms(boxes, scores, num_classes, max_boxes=50, score_thresh=0.3, iou_thresh=0.5):
"""
/*----------------------------------- NMS on cpu ---------------------------------------*/
Arguments:
boxes ==> shape [1, 10647, 4]
scores ==> shape [1, 10647, num_classes]
""" boxes = boxes.reshape(-1, 4)
scores = scores.reshape(-1, num_classes)
# Picked bounding boxes
picked_boxes, picked_score, picked_label = [], [], [] for i in range(num_classes):
indices = np.where(scores[:,i] >= score_thresh)
filter_boxes = boxes[indices]
filter_scores = scores[:,i][indices]
if len(filter_boxes) == 0: continue
# do non_max_suppression on the cpu
indices = py_nms(filter_boxes, filter_scores,
max_boxes=max_boxes, iou_thresh=iou_thresh)
picked_boxes.append(filter_boxes[indices])
picked_score.append(filter_scores[indices])
picked_label.append(np.ones(len(indices), dtype='int32')*i)
if len(picked_boxes) == 0: return None, None, None boxes = np.concatenate(picked_boxes, axis=0)
score = np.concatenate(picked_score, axis=0)
label = np.concatenate(picked_label, axis=0) return boxes, score, label def resize_image_correct_bbox(image, boxes, image_h, image_w): origin_image_size = tf.to_float(tf.shape(image)[0:2])
image = tf.image.resize_images(image, size=[image_h, image_w]) # correct bbox
xx1 = boxes[:, 0] * image_w / origin_image_size[1]
yy1 = boxes[:, 1] * image_h / origin_image_size[0]
xx2 = boxes[:, 2] * image_w / origin_image_size[1]
yy2 = boxes[:, 3] * image_h / origin_image_size[0]
idx = boxes[:, 4] boxes = tf.stack([xx1, yy1, xx2, yy2, idx], axis=1)
return image, boxes def draw_boxes(image, boxes, scores, labels, classes, detection_size,
font='./data/font/FiraMono-Medium.otf', show=True):
"""
:param boxes, shape of [num, 4]
:param scores, shape of [num, ]
:param labels, shape of [num, ]
:param image,
:param classes, the return list from the function `read_coco_names`
"""
if boxes is None: return image
draw = ImageDraw.Draw(image)
# draw settings
font = ImageFont.truetype(font = font, size = np.floor(2e-2 * image.size[1]).astype('int32'))
hsv_tuples = [( x / len(classes), 0.9, 1.0) for x in range(len(classes))]
colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
colors = list(map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)), colors))
for i in range(len(labels)): # for each bounding box, do:
bbox, score, label = boxes[i], scores[i], classes[labels[i]]
bbox_text = "%s %.2f" %(label, score)
text_size = draw.textsize(bbox_text, font)
# convert_to_original_size
detection_size, original_size = np.array(detection_size), np.array(image.size)
ratio = original_size / detection_size
bbox = list((bbox.reshape(2,2) * ratio).reshape(-1)) draw.rectangle(bbox, outline=colors[labels[i]], width=3)
text_origin = bbox[:2]-np.array([0, text_size[1]])
draw.rectangle([tuple(text_origin), tuple(text_origin+text_size)], fill=colors[labels[i]])
# # draw bbox
draw.text(tuple(text_origin), bbox_text, fill=(0,0,0), font=font) image.show() if show else None
return image def read_coco_names(class_file_name):
names = {}
with open(class_file_name, 'r') as data:
for ID, name in enumerate(data):
names[ID] = name.strip('\n')
return names def freeze_graph(sess, output_file, output_node_names): output_graph_def = tf.graph_util.convert_variables_to_constants(
sess,
sess.graph.as_graph_def(),
output_node_names,
) with tf.gfile.GFile(output_file, "wb") as f:
f.write(output_graph_def.SerializeToString()) print("=> {} ops written to {}.".format(len(output_graph_def.node), output_file)) def read_pb_return_tensors(graph, pb_file, return_elements): with tf.gfile.FastGFile(pb_file, 'rb') as f:
frozen_graph_def = tf.GraphDef()
frozen_graph_def.ParseFromString(f.read()) with graph.as_default():
return_elements = tf.import_graph_def(frozen_graph_def,
return_elements=return_elements)
input_tensor, output_tensors = return_elements[0], return_elements[1:] return input_tensor, output_tensors def load_weights(var_list, weights_file):
"""
Loads and converts pre-trained weights.
:param var_list: list of network variables.
:param weights_file: name of the binary file.
:return: list of assign ops
"""
with open(weights_file, "rb") as fp:
np.fromfile(fp, dtype=np.int32, count=5)
weights = np.fromfile(fp, dtype=np.float32) ptr = 0
i = 0
assign_ops = []
while i < len(var_list) - 1:
var1 = var_list[i]
print("=> loading ", var1.name)
var2 = var_list[i + 1]
print("=> loading ", var2.name)
# do something only if we process conv layer
if 'Conv' in var1.name.split('/')[-2]:
# check type of next layer
if 'BatchNorm' in var2.name.split('/')[-2]:
# load batch norm params
gamma, beta, mean, var = var_list[i + 1:i + 5]
batch_norm_vars = [beta, gamma, mean, var]
for var in batch_norm_vars:
shape = var.shape.as_list()
num_params = np.prod(shape)
var_weights = weights[ptr:ptr + num_params].reshape(shape)
ptr += num_params
assign_ops.append(tf.assign(var, var_weights, validate_shape=True))
# we move the pointer by 4, because we loaded 4 variables
i += 4
elif 'Conv' in var2.name.split('/')[-2]:
# load biases
bias = var2
bias_shape = bias.shape.as_list()
bias_params = np.prod(bias_shape)
bias_weights = weights[ptr:ptr +
bias_params].reshape(bias_shape)
ptr += bias_params
assign_ops.append(tf.assign(bias, bias_weights, validate_shape=True))
# we loaded 1 variable
i += 1
# we can load weights of conv layer
shape = var1.shape.as_list()
num_params = np.prod(shape) var_weights = weights[ptr:ptr + num_params].reshape(
(shape[3], shape[2], shape[0], shape[1]))
# remember to transpose to column-major
var_weights = np.transpose(var_weights, (2, 3, 1, 0))
ptr += num_params
assign_ops.append(
tf.assign(var1, var_weights, validate_shape=True))
i += 1 return assign_ops def get_anchors(anchors_path, image_h, image_w):
'''loads the anchors from a file'''
with open(anchors_path) as f:
anchors = f.readline()
anchors = np.array(anchors.split(), dtype=np.float32)
anchors = anchors.reshape(-1,2)
anchors[:, 1] = anchors[:, 1] * image_h
anchors[:, 0] = anchors[:, 0] * image_w
return anchors.astype(np.int32) def bbox_iou(A, B): intersect_mins = np.maximum(A[:, 0:2], B[:, 0:2])
intersect_maxs = np.minimum(A[:, 2:4], B[:, 2:4])
intersect_wh = np.maximum(intersect_maxs - intersect_mins, 0.)
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1] A_area = np.prod(A[:, 2:4] - A[:, 0:2], axis=1)
B_area = np.prod(B[:, 2:4] - B[:, 0:2], axis=1) iou = intersect_area / (A_area + B_area - intersect_area) return iou def evaluate(y_pred, y_true, iou_thresh=0.5, score_thresh=0.3): num_images = y_true[0].shape[0]
num_classes = y_true[0][0][..., 5:].shape[-1]
true_labels_dict = {i:0 for i in range(num_classes)} # {class: count}
pred_labels_dict = {i:0 for i in range(num_classes)}
true_positive_dict = {i:0 for i in range(num_classes)} for i in range(num_images):
true_labels_list, true_boxes_list = [], []
for j in range(3): # three feature maps
true_probs_temp = y_true[j][i][...,5: ]
true_boxes_temp = y_true[j][i][...,0:4] object_mask = true_probs_temp.sum(axis=-1) > 0 true_probs_temp = true_probs_temp[object_mask]
true_boxes_temp = true_boxes_temp[object_mask] true_labels_list += np.argmax(true_probs_temp, axis=-1).tolist()
true_boxes_list += true_boxes_temp.tolist() if len(true_labels_list) != 0:
for cls, count in Counter(true_labels_list).items(): true_labels_dict[cls] += count pred_boxes = y_pred[0][i:i+1]
pred_confs = y_pred[1][i:i+1]
pred_probs = y_pred[2][i:i+1] pred_boxes, pred_scores, pred_labels = cpu_nms(pred_boxes, pred_confs*pred_probs, num_classes,
score_thresh=score_thresh, iou_thresh=iou_thresh) true_boxes = np.array(true_boxes_list)
box_centers, box_sizes = true_boxes[:,0:2], true_boxes[:,2:4] true_boxes[:,0:2] = box_centers - box_sizes / 2.
true_boxes[:,2:4] = true_boxes[:,0:2] + box_sizes
pred_labels_list = [] if pred_labels is None else pred_labels.tolist() if len(pred_labels_list) != 0:
for cls, count in Counter(pred_labels_list).items(): pred_labels_dict[cls] += count
else:
continue detected = []
for k in range(len(pred_labels_list)):
# compute iou between predicted box and ground_truth boxes
iou = bbox_iou(pred_boxes[k:k+1], true_boxes)
m = np.argmax(iou) # Extract index of largest overlap
if iou[m] >= iou_thresh and pred_labels_list[k] == true_labels_list[m] and m not in detected:
true_positive_dict[true_labels_list[m]] += 1
detected.append(m) recall = sum(true_positive_dict.values()) / (sum(true_labels_dict.values()) + 1e-6)
precision = sum(true_positive_dict.values()) / (sum(pred_labels_dict.values()) + 1e-6) return recall, precision def compute_ap(recall, precision):
""" Compute the average precision, given the recall and precision curves.
Code originally from https://github.com/rbgirshick/py-faster-rcnn.
# Arguments
recall: The recall curve (list).
precision: The precision curve (list).
# Returns
The average precision as computed in py-faster-rcnn.
"""
# correct AP calculation
# first append sentinel values at the end
mrec = np.concatenate(([0.0], recall, [1.0]))
mpre = np.concatenate(([0.0], precision, [0.0])) # compute the precision envelope
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i]) # to calculate area under PR curve, look for points
# where X axis (recall) changes value
i = np.where(mrec[1:] != mrec[:-1])[0] # and sum (\Delta recall) * prec
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap
|-------common.py # 卷积层Pad 使用Slim
import tensorflow as tf
slim = tf.contrib.slim def _conv2d_fixed_padding(inputs, filters, kernel_size, strides=1):
if strides > 1: inputs = _fixed_padding(inputs, kernel_size)
inputs = slim.conv2d(inputs, filters, kernel_size, stride=strides,
padding=('SAME' if strides == 1 else 'VALID'))
return inputs @tf.contrib.framework.add_arg_scope
def _fixed_padding(inputs, kernel_size, *args, mode='CONSTANT', **kwargs):
"""
Pads the input along the spatial dimensions independently of input size. Args:
inputs: A tensor of size [batch, channels, height_in, width_in] or
[batch, height_in, width_in, channels] depending on data_format.
kernel_size: The kernel to be used in the conv2d or max_pool2d operation.
Should be a positive integer.
mode: The mode for tf.pad. Returns:
A tensor with the same format as the input with the data either intact
(if kernel_size == 1) or padded (if kernel_size > 1).
"""
pad_total = kernel_size - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg padded_inputs = tf.pad(inputs, [[0, 0], [pad_beg, pad_end],
[pad_beg, pad_end], [0, 0]], mode=mode)
return padded_inputs
|-------yolov3.py #定义Darknet53,yolov3
import tensorflow as tf
from core import common
slim = tf.contrib.slim class darknet53(object):
"""network for performing feature extraction""" def __init__(self, inputs):
self.outputs = self.forward(inputs) def _darknet53_block(self, inputs, filters):
"""
implement residuals block in darknet53
"""
shortcut = inputs
inputs = common._conv2d_fixed_padding(inputs, filters * 1, 1)
inputs = common._conv2d_fixed_padding(inputs, filters * 2, 3) inputs = inputs + shortcut
return inputs def forward(self, inputs): inputs = common._conv2d_fixed_padding(inputs, 32, 3, strides=1)
inputs = common._conv2d_fixed_padding(inputs, 64, 3, strides=2)
inputs = self._darknet53_block(inputs, 32)
inputs = common._conv2d_fixed_padding(inputs, 128, 3, strides=2) for i in range(2):
inputs = self._darknet53_block(inputs, 64) inputs = common._conv2d_fixed_padding(inputs, 256, 3, strides=2) for i in range(8):
inputs = self._darknet53_block(inputs, 128) route_1 = inputs
inputs = common._conv2d_fixed_padding(inputs, 512, 3, strides=2) for i in range(8):
inputs = self._darknet53_block(inputs, 256) route_2 = inputs
inputs = common._conv2d_fixed_padding(inputs, 1024, 3, strides=2) for i in range(4):
inputs = self._darknet53_block(inputs, 512) return route_1, route_2, inputs class yolov3(object): def __init__(self, num_classes, anchors,
batch_norm_decay=0.9, leaky_relu=0.1): # self._ANCHORS = [[10 ,13], [16 , 30], [33 , 23],
# [30 ,61], [62 , 45], [59 ,119],
# [116,90], [156,198], [373,326]]
self._ANCHORS = anchors
self._BATCH_NORM_DECAY = batch_norm_decay
self._LEAKY_RELU = leaky_relu
self._NUM_CLASSES = num_classes
self.feature_maps = [] # [[None, 13, 13, 255], [None, 26, 26, 255], [None, 52, 52, 255]] def _yolo_block(self, inputs, filters):
inputs = common._conv2d_fixed_padding(inputs, filters * 1, 1)
inputs = common._conv2d_fixed_padding(inputs, filters * 2, 3)
inputs = common._conv2d_fixed_padding(inputs, filters * 1, 1)
inputs = common._conv2d_fixed_padding(inputs, filters * 2, 3)
inputs = common._conv2d_fixed_padding(inputs, filters * 1, 1)
route = inputs
inputs = common._conv2d_fixed_padding(inputs, filters * 2, 3)
return route, inputs def _detection_layer(self, inputs, anchors):
num_anchors = len(anchors)
feature_map = slim.conv2d(inputs, num_anchors * (5 + self._NUM_CLASSES), 1,
stride=1, normalizer_fn=None,
activation_fn=None,
biases_initializer=tf.zeros_initializer())
return feature_map def _reorg_layer(self, feature_map, anchors): num_anchors = len(anchors) # num_anchors=3
grid_size = feature_map.shape.as_list()[1:3]
# the downscale image in height and weight
stride = tf.cast(self.img_size // grid_size, tf.float32) # [h,w] -> [y,x]
feature_map = tf.reshape(feature_map, [-1, grid_size[0], grid_size[1], num_anchors, 5 + self._NUM_CLASSES]) box_centers, box_sizes, conf_logits, prob_logits = tf.split(
feature_map, [2, 2, 1, self._NUM_CLASSES], axis=-1) box_centers = tf.nn.sigmoid(box_centers) grid_x = tf.range(grid_size[1], dtype=tf.int32)
grid_y = tf.range(grid_size[0], dtype=tf.int32) a, b = tf.meshgrid(grid_x, grid_y)
x_offset = tf.reshape(a, (-1, 1))
y_offset = tf.reshape(b, (-1, 1))
x_y_offset = tf.concat([x_offset, y_offset], axis=-1)
x_y_offset = tf.reshape(x_y_offset, [grid_size[0], grid_size[1], 1, 2])
x_y_offset = tf.cast(x_y_offset, tf.float32) box_centers = box_centers + x_y_offset
box_centers = box_centers * stride[::-1] box_sizes = tf.exp(box_sizes) * anchors # anchors -> [w, h]
boxes = tf.concat([box_centers, box_sizes], axis=-1)
return x_y_offset, boxes, conf_logits, prob_logits @staticmethod
def _upsample(inputs, out_shape): new_height, new_width = out_shape[1], out_shape[2]
inputs = tf.image.resize_nearest_neighbor(inputs, (new_height, new_width))
inputs = tf.identity(inputs, name='upsampled') return inputs # @staticmethod
# def _upsample(inputs, out_shape):
# """
# replace resize_nearest_neighbor with conv2d_transpose To support TensorRT 5 optimization
# """
# new_height, new_width = out_shape[1], out_shape[2]
# filters = 256 if (new_height == 26 and new_width==26) else 128
# inputs = tf.layers.conv2d_transpose(inputs, filters, kernel_size=3, padding='same',
# strides=(2,2), kernel_initializer=tf.ones_initializer())
# return inputs def forward(self, inputs, is_training=False, reuse=False):
"""
Creates YOLO v3 model. :param inputs: a 4-D tensor of size [batch_size, height, width, channels].
Dimension batch_size may be undefined. The channel order is RGB.
:param is_training: whether is training or not.
:param reuse: whether or not the network and its variables should be reused.
:return:
"""
# it will be needed later on
self.img_size = tf.shape(inputs)[1:3]
# set batch norm params
batch_norm_params = {
'decay': self._BATCH_NORM_DECAY,
'epsilon': 1e-05,
'scale': True,
'is_training': is_training,
'fused': None, # Use fused batch norm if possible.
} # Set activation_fn and parameters for conv2d, batch_norm.
with slim.arg_scope([slim.conv2d, slim.batch_norm, common._fixed_padding],reuse=reuse):
with slim.arg_scope([slim.conv2d], normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params,
biases_initializer=None,
activation_fn=lambda x: tf.nn.leaky_relu(x, alpha=self._LEAKY_RELU)):
with tf.variable_scope('darknet-53'):
route_1, route_2, inputs = darknet53(inputs).outputs with tf.variable_scope('yolo-v3'):
route, inputs = self._yolo_block(inputs, 512)
feature_map_1 = self._detection_layer(inputs, self._ANCHORS[6:9])
feature_map_1 = tf.identity(feature_map_1, name='feature_map_1') inputs = common._conv2d_fixed_padding(route, 256, 1)
upsample_size = route_2.get_shape().as_list()
inputs = self._upsample(inputs, upsample_size)
inputs = tf.concat([inputs, route_2], axis=3) route, inputs = self._yolo_block(inputs, 256)
feature_map_2 = self._detection_layer(inputs, self._ANCHORS[3:6])
feature_map_2 = tf.identity(feature_map_2, name='feature_map_2') inputs = common._conv2d_fixed_padding(route, 128, 1)
upsample_size = route_1.get_shape().as_list()
inputs = self._upsample(inputs, upsample_size)
inputs = tf.concat([inputs, route_1], axis=3) route, inputs = self._yolo_block(inputs, 128)
feature_map_3 = self._detection_layer(inputs, self._ANCHORS[0:3])
feature_map_3 = tf.identity(feature_map_3, name='feature_map_3') return feature_map_1, feature_map_2, feature_map_3 def _reshape(self, x_y_offset, boxes, confs, probs): grid_size = x_y_offset.shape.as_list()[:2]
boxes = tf.reshape(boxes, [-1, grid_size[0]*grid_size[1]*3, 4])
confs = tf.reshape(confs, [-1, grid_size[0]*grid_size[1]*3, 1])
probs = tf.reshape(probs, [-1, grid_size[0]*grid_size[1]*3, self._NUM_CLASSES]) return boxes, confs, probs def predict(self, feature_maps):
"""
Note: given by feature_maps, compute the receptive field
and get boxes, confs and class_probs
input_argument: feature_maps -> [None, 13, 13, 255],
[None, 26, 26, 255],
[None, 52, 52, 255],
"""
feature_map_1, feature_map_2, feature_map_3 = feature_maps
feature_map_anchors = [(feature_map_1, self._ANCHORS[6:9]),
(feature_map_2, self._ANCHORS[3:6]),
(feature_map_3, self._ANCHORS[0:3]),] results = [self._reorg_layer(feature_map, anchors) for (feature_map, anchors) in feature_map_anchors]
boxes_list, confs_list, probs_list = [], [], [] for result in results:
boxes, conf_logits, prob_logits = self._reshape(*result) confs = tf.sigmoid(conf_logits)
probs = tf.sigmoid(prob_logits) boxes_list.append(boxes)
confs_list.append(confs)
probs_list.append(probs) boxes = tf.concat(boxes_list, axis=1)
confs = tf.concat(confs_list, axis=1)
probs = tf.concat(probs_list, axis=1) center_x, center_y, width, height = tf.split(boxes, [1,1,1,1], axis=-1)
x0 = center_x - width / 2.
y0 = center_y - height / 2.
x1 = center_x + width / 2.
y1 = center_y + height / 2. boxes = tf.concat([x0, y0, x1, y1], axis=-1)
return boxes, confs, probs def compute_loss(self, pred_feature_map, y_true, ignore_thresh=0.5, max_box_per_image=8):
"""
Note: compute the loss
Arguments: y_pred, list -> [feature_map_1, feature_map_2, feature_map_3]
the shape of [None, 13, 13, 3*85]. etc
"""
loss_xy, loss_wh, loss_conf, loss_class = 0., 0., 0., 0.
total_loss = 0.
# total_loss, rec_50, rec_75, avg_iou = 0., 0., 0., 0.
_ANCHORS = [self._ANCHORS[6:9], self._ANCHORS[3:6], self._ANCHORS[0:3]] for i in range(len(pred_feature_map)):
result = self.loss_layer(pred_feature_map[i], y_true[i], _ANCHORS[i])
loss_xy += result[0]
loss_wh += result[1]
loss_conf += result[2]
loss_class += result[3] total_loss = loss_xy + loss_wh + loss_conf + loss_class
return [total_loss, loss_xy, loss_wh, loss_conf, loss_class] def loss_layer(self, feature_map_i, y_true, anchors):
# size in [h, w] format! don't get messed up!
grid_size = tf.shape(feature_map_i)[1:3]
grid_size_ = feature_map_i.shape.as_list()[1:3] y_true = tf.reshape(y_true, [-1, grid_size_[0], grid_size_[1], 3, 5+self._NUM_CLASSES]) # the downscale ratio in height and weight
ratio = tf.cast(self.img_size / grid_size, tf.float32)
# N: batch_size
N = tf.cast(tf.shape(feature_map_i)[0], tf.float32) x_y_offset, pred_boxes, pred_conf_logits, pred_prob_logits = self._reorg_layer(feature_map_i, anchors)
# shape: take 416x416 input image and 13*13 feature_map for example:
# [N, 13, 13, 3, 1]
object_mask = y_true[..., 4:5]
# shape: [N, 13, 13, 3, 4] & [N, 13, 13, 3] ==> [V, 4]
# V: num of true gt box
valid_true_boxes = tf.boolean_mask(y_true[..., 0:4], tf.cast(object_mask[..., 0], 'bool')) # shape: [V, 2]
valid_true_box_xy = valid_true_boxes[:, 0:2]
valid_true_box_wh = valid_true_boxes[:, 2:4]
# shape: [N, 13, 13, 3, 2]
pred_box_xy = pred_boxes[..., 0:2]
pred_box_wh = pred_boxes[..., 2:4] # calc iou
# shape: [N, 13, 13, 3, V]
iou = self._broadcast_iou(valid_true_box_xy, valid_true_box_wh, pred_box_xy, pred_box_wh) # shape: [N, 13, 13, 3]
best_iou = tf.reduce_max(iou, axis=-1)
# get_ignore_mask
ignore_mask = tf.cast(best_iou < 0.5, tf.float32)
# shape: [N, 13, 13, 3, 1]
ignore_mask = tf.expand_dims(ignore_mask, -1)
# get xy coordinates in one cell from the feature_map
# numerical range: 0 ~ 1
# shape: [N, 13, 13, 3, 2]
true_xy = y_true[..., 0:2] / ratio[::-1] - x_y_offset
pred_xy = pred_box_xy / ratio[::-1] - x_y_offset # get_tw_th, numerical range: 0 ~ 1
# shape: [N, 13, 13, 3, 2]
true_tw_th = y_true[..., 2:4] / anchors
pred_tw_th = pred_box_wh / anchors
# for numerical stability
true_tw_th = tf.where(condition=tf.equal(true_tw_th, 0),
x=tf.ones_like(true_tw_th), y=true_tw_th)
pred_tw_th = tf.where(condition=tf.equal(pred_tw_th, 0),
x=tf.ones_like(pred_tw_th), y=pred_tw_th) true_tw_th = tf.log(tf.clip_by_value(true_tw_th, 1e-9, 1e9))
pred_tw_th = tf.log(tf.clip_by_value(pred_tw_th, 1e-9, 1e9)) # box size punishment:
# box with smaller area has bigger weight. This is taken from the yolo darknet C source code.
# shape: [N, 13, 13, 3, 1]
#why use box_loss_scale?
box_loss_scale = 2. - (y_true[..., 2:3] / tf.cast(self.img_size[1], tf.float32)) * (y_true[..., 3:4] / tf.cast(self.img_size[0], tf.float32)) # shape: [N, 13, 13, 3, 1]
xy_loss = tf.reduce_sum(tf.square(true_xy - pred_xy) * object_mask * box_loss_scale) / N
wh_loss = tf.reduce_sum(tf.square(true_tw_th - pred_tw_th) * object_mask * box_loss_scale) / N # shape: [N, 13, 13, 3, 1]
conf_pos_mask = object_mask
conf_neg_mask = (1 - object_mask) * ignore_mask
conf_loss_pos = conf_pos_mask * tf.nn.sigmoid_cross_entropy_with_logits(labels=object_mask, logits=pred_conf_logits)
conf_loss_neg = conf_neg_mask * tf.nn.sigmoid_cross_entropy_with_logits(labels=object_mask, logits=pred_conf_logits)
conf_loss = tf.reduce_sum(conf_loss_pos + conf_loss_neg) / N # shape: [N, 13, 13, 3, 1]
class_loss = object_mask * tf.nn.sigmoid_cross_entropy_with_logits(labels=y_true[..., 5:], logits=pred_prob_logits)
class_loss = tf.reduce_sum(class_loss) / N return xy_loss, wh_loss, conf_loss, class_loss def _broadcast_iou(self, true_box_xy, true_box_wh, pred_box_xy, pred_box_wh):
'''
maintain an efficient way to calculate the ios matrix between ground truth true boxes and the predicted boxes
note: here we only care about the size match
'''
# shape:
# true_box_??: [V, 2]
# pred_box_??: [N, 13, 13, 3, 2] # shape: [N, 13, 13, 3, 1, 2]
pred_box_xy = tf.expand_dims(pred_box_xy, -2)
pred_box_wh = tf.expand_dims(pred_box_wh, -2) # shape: [1, V, 2]
true_box_xy = tf.expand_dims(true_box_xy, 0)
true_box_wh = tf.expand_dims(true_box_wh, 0) # [N, 13, 13, 3, 1, 2] & [1, V, 2] ==> [N, 13, 13, 3, V, 2]
intersect_mins = tf.maximum(pred_box_xy - pred_box_wh / 2.,
true_box_xy - true_box_wh / 2.)
intersect_maxs = tf.minimum(pred_box_xy + pred_box_wh / 2.,
true_box_xy + true_box_wh / 2.)
intersect_wh = tf.maximum(intersect_maxs - intersect_mins, 0.) # shape: [N, 13, 13, 3, V]
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
# shape: [N, 13, 13, 3, 1]
pred_box_area = pred_box_wh[..., 0] * pred_box_wh[..., 1]
# shape: [1, V]
true_box_area = true_box_wh[..., 0] * true_box_wh[..., 1]
# [N, 13, 13, 3, V]
iou = intersect_area / (pred_box_area + true_box_area - intersect_area) return iou
|-------convert_weight.py 将darknet(c版)yolov3权重转换成tensorflow版pb
import os
import sys
import wget
import time
import argparse
import tensorflow as tf
from core import yolov3, utils class parser(argparse.ArgumentParser): def __init__(self,description):
super(parser, self).__init__(description) self.add_argument(
"--ckpt_file", "-cf", default='./checkpoint/yolov3.ckpt', type=str,
help="[default: %(default)s] The checkpoint file ...",
metavar="<CF>",
) self.add_argument(
"--num_classes", "-nc", default=80, type=int,
help="[default: %(default)s] The number of classes ...",
metavar="<NC>",
) self.add_argument(
"--anchors_path", "-ap", default="./data/coco_anchors.txt", type=str,
help="[default: %(default)s] The path of anchors ...",
metavar="<AP>",
) self.add_argument(
"--weights_path", "-wp", default='./checkpoint/yolov3.weights', type=str,
help="[default: %(default)s] Download binary file with desired weights",
metavar="<WP>",
) self.add_argument(
"--convert", "-cv", action='store_true',
help="[default: %(default)s] Downloading yolov3 weights and convert them",
) self.add_argument(
"--freeze", "-fz", action='store_true',
help="[default: %(default)s] freeze the yolov3 graph to pb ...",
) self.add_argument(
"--image_h", "-ih", default=416, type=int,
help="[default: %(default)s] The height of image, 416 or 608",
metavar="<IH>",
) self.add_argument(
"--image_w", "-iw", default=416, type=int,
help="[default: %(default)s] The width of image, 416 or 608",
metavar="<IW>",
) self.add_argument(
"--iou_threshold", "-it", default=0.5, type=float,
help="[default: %(default)s] The iou_threshold for gpu nms",
metavar="<IT>",
) self.add_argument(
"--score_threshold", "-st", default=0.5, type=float,
help="[default: %(default)s] The score_threshold for gpu nms",
metavar="<ST>",
) def main(argv): flags = parser(description="freeze yolov3 graph from checkpoint file").parse_args()
print("=> the input image size is [%d, %d]" %(flags.image_h, flags.image_w))
anchors = utils.get_anchors(flags.anchors_path, flags.image_h, flags.image_w)
model = yolov3.yolov3(flags.num_classes, anchors) with tf.Graph().as_default() as graph:
sess = tf.Session(graph=graph)
inputs = tf.placeholder(tf.float32, [1, flags.image_h, flags.image_w, 3]) # placeholder for detector inputs
print("=>", inputs) with tf.variable_scope('yolov3'):
feature_map = model.forward(inputs, is_training=False) boxes, confs, probs = model.predict(feature_map)
scores = confs * probs
print("=>", boxes.name[:-2], scores.name[:-2])
cpu_out_node_names = [boxes.name[:-2], scores.name[:-2]]
boxes, scores, labels = utils.gpu_nms(boxes, scores, flags.num_classes,
score_thresh=flags.score_threshold,
iou_thresh=flags.iou_threshold)
print("=>", boxes.name[:-2], scores.name[:-2], labels.name[:-2])
gpu_out_node_names = [boxes.name[:-2], scores.name[:-2], labels.name[:-2]]
feature_map_1, feature_map_2, feature_map_3 = feature_map
saver = tf.train.Saver(var_list=tf.global_variables(scope='yolov3')) if flags.convert:
if not os.path.exists(flags.weights_path):
url = 'https://github.com/YunYang1994/tensorflow-yolov3/releases/download/v1.0/yolov3.weights'
for i in range(3):
time.sleep(1)
print("=> %s does not exists ! " %flags.weights_path)
print("=> It will take a while to download it from %s" %url)
print('=> Downloading yolov3 weights ... ')
wget.download(url, flags.weights_path) load_ops = utils.load_weights(tf.global_variables(scope='yolov3'), flags.weights_path)
sess.run(load_ops)
save_path = saver.save(sess, save_path=flags.ckpt_file)
print('=> model saved in path: {}'.format(save_path)) if flags.freeze:
saver.restore(sess, flags.ckpt_file)
print('=> checkpoint file restored from ', flags.ckpt_file)
utils.freeze_graph(sess, './checkpoint/yolov3_cpu_nms.pb', cpu_out_node_names)
utils.freeze_graph(sess, './checkpoint/yolov3_gpu_nms.pb', gpu_out_node_names) if __name__ == "__main__": main(sys.argv)
|------yolov3_train.py #加载参数,数据,训练
import tensorflow as tf
from core import utils, yolov3
from core.dataset import dataset, Parser
sess = tf.Session() IMAGE_H, IMAGE_W = 416, 416
BATCH_SIZE = 8
STEPS = 2500
LR = 0.001 # if Nan, set 0.0005, 0.0001
DECAY_STEPS = 100
DECAY_RATE = 0.9
SHUFFLE_SIZE = 200
CLASSES = utils.read_coco_names('./data/raccoon.names')
ANCHORS = utils.get_anchors('./data/raccoon_anchors.txt', IMAGE_H, IMAGE_W)
NUM_CLASSES = len(CLASSES)
EVAL_INTERNAL = 100
SAVE_INTERNAL = 500 train_tfrecord = "./raccoon_dataset/raccoon_train.tfrecords"
test_tfrecord = "./raccoon_dataset/raccoon_test.tfrecords" parser = Parser(IMAGE_H, IMAGE_W, ANCHORS, NUM_CLASSES)
trainset = dataset(parser, train_tfrecord, BATCH_SIZE, shuffle=SHUFFLE_SIZE)
testset = dataset(parser, test_tfrecord , BATCH_SIZE, shuffle=None) is_training = tf.placeholder(tf.bool)
example = tf.cond(is_training, lambda: trainset.get_next(), lambda: testset.get_next()) images, *y_true = example
model = yolov3.yolov3(NUM_CLASSES, ANCHORS) with tf.variable_scope('yolov3'):
pred_feature_map = model.forward(images, is_training=is_training)
loss = model.compute_loss(pred_feature_map, y_true)
y_pred = model.predict(pred_feature_map) tf.summary.scalar("loss/coord_loss", loss[1])
tf.summary.scalar("loss/sizes_loss", loss[2]) tf.summary.scalar("loss/confs_loss", loss[3])
tf.summary.scalar("loss/class_loss", loss[4]) global_step = tf.Variable(0, trainable=False, collections=[tf.GraphKeys.LOCAL_VARIABLES])
write_op = tf.summary.merge_all()
writer_train = tf.summary.FileWriter("./data/train")
writer_test = tf.summary.FileWriter("./data/test") saver_to_restore = tf.train.Saver(var_list=tf.contrib.framework.get_variables_to_restore(include=["yolov3/darknet-53"]))
update_vars = tf.contrib.framework.get_variables_to_restore(include=["yolov3/yolo-v3"])
learning_rate = tf.train.exponential_decay(LR, global_step, decay_steps=DECAY_STEPS, decay_rate=DECAY_RATE, staircase=True)
optimizer = tf.train.AdamOptimizer(learning_rate) # set dependencies for BN ops
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = optimizer.minimize(loss[0], var_list=update_vars, global_step=global_step) sess.run([tf.global_variables_initializer(), tf.local_variables_initializer()])
saver_to_restore.restore(sess, "./checkpoint/yolov3.ckpt")
saver = tf.train.Saver(max_to_keep=2) for step in range(STEPS):
run_items = sess.run([train_op, write_op, y_pred, y_true] + loss, feed_dict={is_training:True}) if (step+1) % EVAL_INTERNAL == 0:
train_rec_value, train_prec_value = utils.evaluate(run_items[2], run_items[3]) writer_train.add_summary(run_items[1], global_step=step)
writer_train.flush() # Flushes the event file to disk
if (step+1) % SAVE_INTERNAL == 0:
saver.save(sess, save_path="./checkpoint/yolov3.ckpt", global_step=step+1) print("=> STEP %10d [TRAIN]:\tloss_xy:%7.4f \tloss_wh:%7.4f \tloss_conf:%7.4f \tloss_class:%7.4f"
%(step+1, run_items[5], run_items[6], run_items[7], run_items[8])) run_items = sess.run([write_op, y_pred, y_true] + loss, feed_dict={is_training:False})
if (step+1) % EVAL_INTERNAL == 0:
test_rec_value, test_prec_value = utils.evaluate(run_items[1], run_items[2])
print("\n=======================> evaluation result <================================\n")
print("=> STEP %10d [TRAIN]:\trecall:%7.4f \tprecision:%7.4f" %(step+1, train_rec_value, train_prec_value))
print("=> STEP %10d [VALID]:\trecall:%7.4f \tprecision:%7.4f" %(step+1, test_rec_value, test_prec_value))
print("\n=======================> evaluation result <================================\n") writer_test.add_summary(run_items[0], global_step=step)
writer_test.flush() # Flushes the event file to disk
|------evaluate.py # 评估模型效果
import sys
import numpy as np
import tensorflow as tf
from tqdm import tqdm
from PIL import Image
from core import utils, yolov3
from core.dataset import dataset, Parser
sess = tf.Session() IMAGE_H, IMAGE_W = 416, 416
CLASSES = utils.read_coco_names('./data/raccoon.names')
NUM_CLASSES = len(CLASSES)
ANCHORS = utils.get_anchors('./data/raccoon_anchors.txt', IMAGE_H, IMAGE_W)
CKPT_FILE = "./checkpoint/yolov3.ckpt-2500"
IOU_THRESH = 0.5
SCORE_THRESH = 0.3 all_detections = []
all_annotations = []
all_aver_precs = {CLASSES[i]:0. for i in range(NUM_CLASSES)} test_tfrecord = "./raccoon_dataset/raccoon_*.tfrecords"
parser = Parser(IMAGE_H, IMAGE_W, ANCHORS, NUM_CLASSES)
testset = dataset(parser, test_tfrecord , batch_size=1, shuffle=None, repeat=False) images_tensor, *y_true_tensor = testset.get_next()
model = yolov3.yolov3(NUM_CLASSES, ANCHORS)
with tf.variable_scope('yolov3'):
pred_feature_map = model.forward(images_tensor, is_training=False)
y_pred_tensor = model.predict(pred_feature_map) saver = tf.train.Saver()
saver.restore(sess, CKPT_FILE) try:
image_idx = 0
while True:
y_pred, y_true, image = sess.run([y_pred_tensor, y_true_tensor, images_tensor])
pred_boxes = y_pred[0][0]
pred_confs = y_pred[1][0]
pred_probs = y_pred[2][0]
image = Image.fromarray(np.uint8(image[0]*255)) true_labels_list, true_boxes_list = [], []
for i in range(3):
true_probs_temp = y_true[i][..., 5: ]
true_boxes_temp = y_true[i][..., 0:4]
object_mask = true_probs_temp.sum(axis=-1) > 0 true_probs_temp = true_probs_temp[object_mask]
true_boxes_temp = true_boxes_temp[object_mask] true_labels_list += np.argmax(true_probs_temp, axis=-1).tolist()
true_boxes_list += true_boxes_temp.tolist() pred_boxes, pred_scores, pred_labels = utils.cpu_nms(pred_boxes, pred_confs*pred_probs, NUM_CLASSES,
score_thresh=SCORE_THRESH, iou_thresh=IOU_THRESH)
# image = utils.draw_boxes(image, pred_boxes, pred_scores, pred_labels, CLASSES, [IMAGE_H, IMAGE_W], show=True)
true_boxes = np.array(true_boxes_list)
box_centers, box_sizes = true_boxes[:,0:2], true_boxes[:,2:4] true_boxes[:,0:2] = box_centers - box_sizes / 2.
true_boxes[:,2:4] = true_boxes[:,0:2] + box_sizes
pred_labels_list = [] if pred_labels is None else pred_labels.tolist() all_detections.append( [pred_boxes, pred_scores, pred_labels_list])
all_annotations.append([true_boxes, true_labels_list])
image_idx += 1
if image_idx % 100 == 0:
sys.stdout.write(".")
sys.stdout.flush() except tf.errors.OutOfRangeError:
pass for idx in range(NUM_CLASSES):
true_positives = []
scores = []
num_annotations = 0 for i in tqdm(range(len(all_annotations)), desc="Computing AP for class %12s" %(CLASSES[idx])):
pred_boxes, pred_scores, pred_labels_list = all_detections[i]
true_boxes, true_labels_list = all_annotations[i]
detected = []
num_annotations += true_labels_list.count(idx) for k in range(len(pred_labels_list)):
if pred_labels_list[k] != idx: continue scores.append(pred_scores[k])
ious = utils.bbox_iou(pred_boxes[k:k+1], true_boxes)
m = np.argmax(ious)
if ious[m] > IOU_THRESH and pred_labels_list[k] == true_labels_list[m] and m not in detected:
detected.append(m)
true_positives.append(1)
else:
true_positives.append(0) num_predictions = len(true_positives)
true_positives = np.array(true_positives)
false_positives = np.ones_like(true_positives) - true_positives
# sorted by score
indices = np.argsort(-np.array(scores))
false_positives = false_positives[indices]
true_positives = true_positives[indices]
# compute false positives and true positives
false_positives = np.cumsum(false_positives)
true_positives = np.cumsum(true_positives)
# compute recall and precision
recall = true_positives / np.maximum(num_annotations, np.finfo(np.float64).eps)
precision = true_positives / np.maximum(num_predictions, np.finfo(np.float64).eps)
# compute average precision
average_precision = utils.compute_ap(recall, precision)
all_aver_precs[CLASSES[idx]] = average_precision for idx in range(NUM_CLASSES):
cls_name = CLASSES[idx]
print("=> Class %10s - AP: %.4f" %(cls_name, all_aver_precs[cls_name])) print("=> mAP: %.4f" %(sum(all_aver_precs.values()) / NUM_CLASSES))
|------yolov3.py # 使用训练好的模型推理
import numpy as np
import tensorflow as tf
from PIL import Image
from core import utils IMAGE_H, IMAGE_W = 416, 416
classes = utils.read_coco_names('./data/raccoon.names')
num_classes = len(classes)
image_path = "./raccoon_dataset/images/raccoon-182.jpg" # 181,
img = Image.open(image_path)
img_resized = np.array(img.resize(size=(IMAGE_W, IMAGE_H)), dtype=np.float32)
img_resized = img_resized / 255.
cpu_nms_graph = tf.Graph() input_tensor, output_tensors = utils.read_pb_return_tensors(cpu_nms_graph, "./checkpoint/yolov3_cpu_nms.pb",
["Placeholder:0", "concat_9:0", "mul_6:0"])
with tf.Session(graph=cpu_nms_graph) as sess:
boxes, scores = sess.run(output_tensors, feed_dict={input_tensor: np.expand_dims(img_resized, axis=0)})
boxes, scores, labels = utils.cpu_nms(boxes, scores, num_classes, score_thresh=0.3, iou_thresh=0.5)
image = utils.draw_boxes(img, boxes, scores, labels, classes, [IMAGE_H, IMAGE_W], show=True)
|------show_input_image.py #显示输入图片及BBOX
import cv2
import numpy as np
import tensorflow as tf
from core import utils
from PIL import Image
from core.dataset import Parser, dataset
sess = tf.Session() IMAGE_H, IMAGE_W = 416, 416
BATCH_SIZE = 1
SHUFFLE_SIZE = 1 train_tfrecord = "./raccoon_dataset/raccoon_*.tfrecords"
anchors = utils.get_anchors('./data/raccoon_anchors.txt', IMAGE_H, IMAGE_W)
classes = utils.read_coco_names('./data/raccoon.names')
num_classes = len(classes) parser = Parser(IMAGE_H, IMAGE_W, anchors, num_classes, debug=True)
trainset = dataset(parser, train_tfrecord, BATCH_SIZE, shuffle=SHUFFLE_SIZE) is_training = tf.placeholder(tf.bool)
example = trainset.get_next() for l in range(10):
image, boxes = sess.run(example)
image, boxes = image[0], boxes[0] n_box = len(boxes)
for i in range(n_box):
image = cv2.rectangle(image,(int(float(boxes[i][0])),
int(float(boxes[i][1]))),
(int(float(boxes[i][2])),
int(float(boxes[i][3]))), (255,0,0), 1)
label = classes[boxes[i][4]]
image = cv2.putText(image, label, (int(float(boxes[i][0])),int(float(boxes[i][1]))),
cv2.FONT_HERSHEY_SIMPLEX, .6, (0, 255, 0), 1, 2) image = Image.fromarray(np.uint8(image))
image.show()
|------kmeans.py #计算输入数据中anchors的数据
import cv2
import argparse
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
current_palette = list(sns.xkcd_rgb.values()) def iou(box, clusters):
"""
Calculates the Intersection over Union (IoU) between a box and k clusters.
param:
box: tuple or array, shifted to the origin (i. e. width and height)
clusters: numpy array of shape (k, 2) where k is the number of clusters
return:
numpy array of shape (k, 0) where k is the number of clusters
"""
x = np.minimum(clusters[:, 0], box[0])
y = np.minimum(clusters[:, 1], box[1])
if np.count_nonzero(x == 0) > 0 or np.count_nonzero(y == 0) > 0:
raise ValueError("Box has no area") intersection = x * y
box_area = box[0] * box[1]
cluster_area = clusters[:, 0] * clusters[:, 1] iou_ = intersection / (box_area + cluster_area - intersection) return iou_ def kmeans(boxes, k, dist=np.median,seed=1):
"""
Calculates k-means clustering with the Intersection over Union (IoU) metric.
:param boxes: numpy array of shape (r, 2), where r is the number of rows
:param k: number of clusters
:param dist: distance function
:return: numpy array of shape (k, 2)
"""
rows = boxes.shape[0]
distances = np.empty((rows, k)) ## N row x N cluster
last_clusters = np.zeros((rows,)) np.random.seed(seed) # initialize the cluster centers to be k items
clusters = boxes[np.random.choice(rows, k, replace=False)] while True:
# Step 1: allocate each item to the closest cluster centers
for icluster in range(k): # I made change to lars76's code here to make the code faster
distances[:,icluster] = 1 - iou(clusters[icluster], boxes) nearest_clusters = np.argmin(distances, axis=1) if (last_clusters == nearest_clusters).all():
break # Step 2: calculate the cluster centers as mean (or median) of all the cases in the clusters.
for cluster in range(k):
clusters[cluster] = dist(boxes[nearest_clusters == cluster], axis=0)
last_clusters = nearest_clusters return clusters, nearest_clusters, distances def parse_anno(annotation_path):
anno = open(annotation_path, 'r')
result = []
for line in anno:
s = line.strip().split(' ')
image = cv2.imread(s[0])
image_h, image_w = image.shape[:2]
s = s[1:]
box_cnt = len(s) // 5
for i in range(box_cnt):
x_min, y_min, x_max, y_max = float(s[i*5+0]), float(s[i*5+1]), float(s[i*5+2]), float(s[i*5+3])
width = (x_max - x_min) / image_w
height = (y_max - y_min) / image_h
result.append([width, height])
result = np.asarray(result)
return result def plot_cluster_result(clusters,nearest_clusters,WithinClusterSumDist,wh,k):
for icluster in np.unique(nearest_clusters):
pick = nearest_clusters==icluster
c = current_palette[icluster]
plt.rc('font', size=8)
plt.plot(wh[pick,0],wh[pick,1],"p",
color=c,
alpha=0.5,label="cluster = {}, N = {:6.0f}".format(icluster,np.sum(pick)))
plt.text(clusters[icluster,0],
clusters[icluster,1],
"c{}".format(icluster),
fontsize=20,color="red")
plt.title("Clusters=%d" %k)
plt.xlabel("width")
plt.ylabel("height")
plt.legend(title="Mean IoU = {:5.4f}".format(WithinClusterSumDist))
plt.tight_layout()
plt.savefig("./kmeans.jpg")
plt.show() if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--dataset_txt", type=str, default="./raccoon_dataset/train.txt")
parser.add_argument("--anchors_txt", type=str, default="./data/raccoon_anchors.txt")
parser.add_argument("--cluster_num", type=int, default=9)
args = parser.parse_args()
anno_result = parse_anno(args.dataset_txt)
clusters, nearest_clusters, distances = kmeans(anno_result, args.cluster_num) # sorted by area
area = clusters[:, 0] * clusters[:, 1]
indice = np.argsort(area)
clusters = clusters[indice]
with open(args.anchors_txt, "w") as f:
for i in range(args.cluster_num):
width, height = clusters[i]
f.writelines(str(width) + " " + str(height) + " ") WithinClusterMeanDist = np.mean(distances[np.arange(distances.shape[0]),nearest_clusters])
plot_cluster_result(clusters, nearest_clusters, 1-WithinClusterMeanDist, anno_result, args.cluster_num)
|------test_video.py #视频方式测试模型效果
import cv2
import time
import numpy as np
import tensorflow as tf
from PIL import Image
from core import utils IMAGE_H, IMAGE_W = 416, 416
video_path = "./data/demo_data/road.mp4"
video_path = 0 # use camera
classes = utils.read_coco_names('./data/coco.names')
num_classes = len(classes)
input_tensor, output_tensors = utils.read_pb_return_tensors(tf.get_default_graph(),
"./checkpoint/yolov3_cpu_nms.pb",
["Placeholder:0", "concat_9:0", "mul_6:0"])
with tf.Session() as sess:
vid = cv2.VideoCapture(video_path)
while True:
return_value, frame = vid.read()
if return_value:
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
image = Image.fromarray(frame)
else:
raise ValueError("No image!")
img_resized = np.array(image.resize(size=(IMAGE_H, IMAGE_W)), dtype=np.float32)
img_resized = img_resized / 255.
prev_time = time.time() boxes, scores = sess.run(output_tensors, feed_dict={input_tensor: np.expand_dims(img_resized, axis=0)})
boxes, scores, labels = utils.cpu_nms(boxes, scores, num_classes, score_thresh=0.4, iou_thresh=0.5)
image = utils.draw_boxes(image, boxes, scores, labels, classes, (IMAGE_H, IMAGE_W), show=False) curr_time = time.time()
exec_time = curr_time - prev_time
result = np.asarray(image)
info = "time: %.2f ms" %(1000*exec_time)
cv2.putText(result, text=info, org=(50, 70), fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=1, color=(255, 0, 0), thickness=2)
cv2.namedWindow("result", cv2.WINDOW_AUTOSIZE)
result = cv2.cvtColor(result, cv2.COLOR_RGB2BGR)
cv2.imshow("result", result)
if cv2.waitKey(1) & 0xFF == ord('q'): break
三、 Yolov3-tiny
由于YOLOV3的模型过于庞大,无法用于ARM芯片。所以,这里使用了Yolov3-tiny。
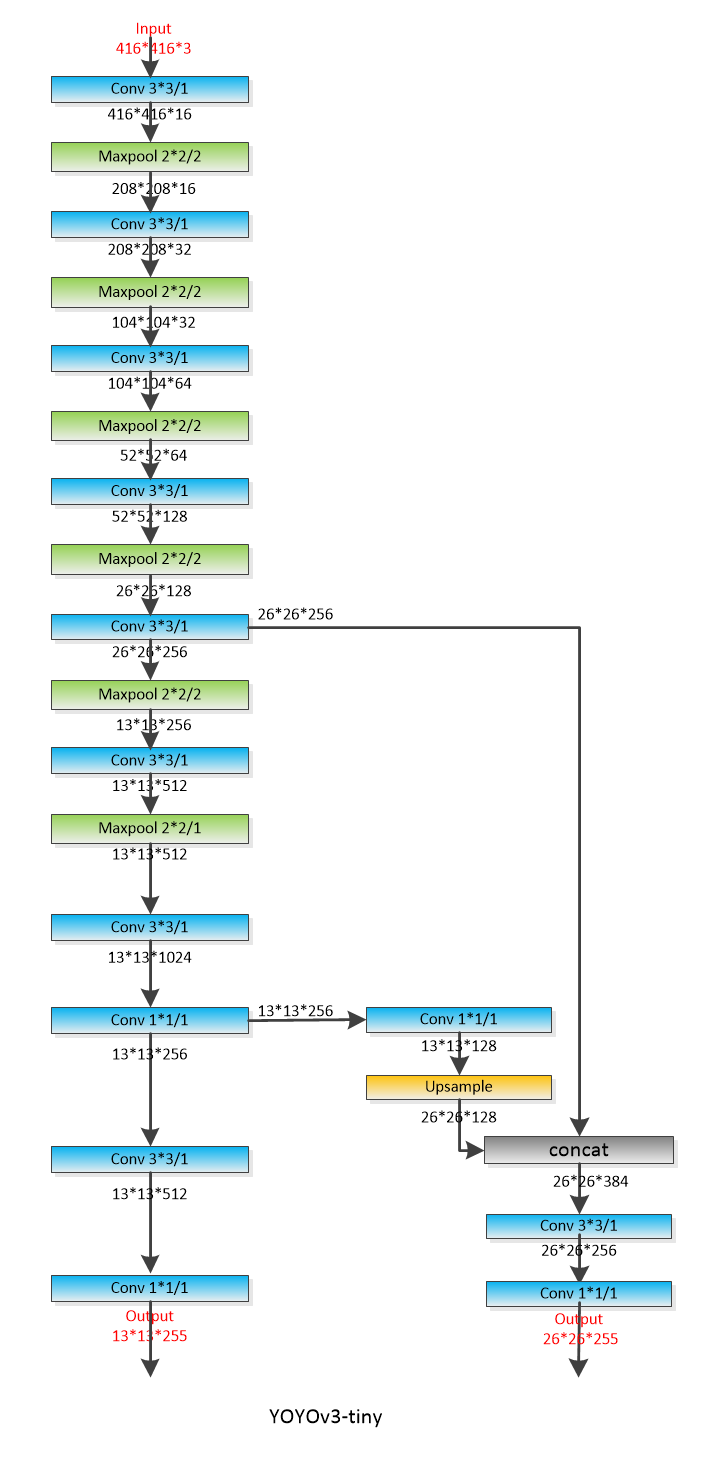
配置文件修改:
首先,我们需要对yolov3-tiny.cfg进行编辑,
在这个文件里,我们需要关注[yolo]和[yolo]前的一个[convolutional]
首先将所有[yolo]里面classes修改为需要识别的类别数
得到classes=4
classes的含义是有多少种需要被识别的物体,这里我训练yolo识别4种物体,所以设置为4
对所有[yolo]的前一个[convolutional]中的filters进行修改
其取值为filters = 3 * ( classes + 5 ),由于上一步中classes=4所以这里filters取27
到这里,yolov3-tiny.cfg就修改完毕了
然后是修改model_data中的car_classes.txt,将待检测物体的标签填写进去,每种标签占一行。
目标检测之车辆行人(tensorflow版yolov3)的更多相关文章
- 目标检测之车辆行人(darknet版yolov3)
序言 自动驾驶是目前非常有前景的行业,而视觉感知作为自动驾驶中的“眼睛”,有着非常重要的地位和作用.为了能有效地识别到行驶在路上的动态目标,如汽车.行人等,我们需要提前对这些目标的进行训练, ...
- 目标检测Object Detection概述(Tensorflow&Pytorch实现)
1999:SIFT 2001:Cascades 2003:Bag of Words 2005:HOG 2006:SPM/SURF/Region Covariance 2007:PASCAL VOC 2 ...
- 目标检测:yolo-v3与faster-rcnn
一. 算法背景 1. 机器视觉实际应用往往涉及包含多个物体的复杂场景,基于深度卷积神经网络的特征提取器,需要结合其他算法来准确定位多个目标,并进行识别. 2. 工业领域,目标检测算法在安防和质检系统都 ...
- Tensorflow Object_Detection 目标检测 笔记
Tensorflow models Code:https://github.com/tensorflow/models 编写时间:2017.7 记录在使用Object_Detection 中遇到的问题 ...
- 【目标检测】YOLO:
PPT 可以说是讲得相当之清楚了... deepsystems.io 中文翻译: https://zhuanlan.zhihu.com/p/24916786 图解YOLO YOLO核心思想:从R-CN ...
- 使用SlimYOLOv3框架实现实时目标检测
介绍 人类可以在几毫秒内在我们的视线中挑选出物体.事实上,你现在就环顾四周,你将观察到周围环境并快速检测到存在的物体,并且把目光回到我们这篇文章来.大概需要多长时间? 这就是实时目标检测.如果我们能让 ...
- 目标检测(六)YOLOv2__YOLO9000: Better, Faster, Stronger
项目链接 Abstract 在该论文中,作者首先介绍了对YOLOv1检测系统的各种改进措施.改进后得到的模型被称为YOLOv2,它使用了一种新颖的多尺度训练方法,使得模型可以在不同尺寸的输入上运行,并 ...
- 基于YOLOv3和Qt5的车辆行人检测(C++版本)
概述 YOLOv3: 车辆行人检测算法 GitHub Qt5: 制作简单的GUI OpenCV:主要用于putText.drawRec等 Step YOLOv3检测结果 Fig 1. input im ...
- GPU端到端目标检测YOLOV3全过程(下)
GPU端到端目标检测YOLOV3全过程(下) Ubuntu18.04系统下最新版GPU环境配置 安装显卡驱动 安装Cuda 10.0 安装cuDNN 1.安装显卡驱动 (1)这里采用的是PPA源的安装 ...
随机推荐
- openstack思维导图
RABBITMQ memcache keystone glance nova neutron cinder horizon
- delphi设置鼠标图形
//Screen.Cursor := crHourGlass;//忙 //Screen.Cursor := crDefault;//不忙时
- HDFS文件目录操作代码
分布式文件系统HDFS中对文件/目录的相关操作代码,整理了一下,大概包括以下部分: 文件夹的新建.删除.重命名 文件夹中子文件和目录的统计 文件的新建及显示文件内容 文件在local和remote间的 ...
- Linux(centos)安装vim
当在Linux环境下使用vim提示: vim command not found时,说明系统还没有安装vim. 安装步骤: 1.检查是否已安装 查看一下你本机已经存在的包,确认一下你的VIM是否已经安 ...
- OSS上传图片demo
demo整理来源https://help.aliyun.com/document_detail/32011.html /** * 示例说明 * <p> * HelloOSS是OSS Jav ...
- Git提交本地项目文件到GitHub的详细操作
因最近在使用git命令提交代码到github的操作,网上找了下教程,记录下过程,便于查看 添加整个文件夹及内容 git add 文件夹/ 添加目录中所有某种类型的文件 git add *.文件类型 `
- flume部署
参考: 笔记 https://www.cnblogs.com/yinzhengjie/p/11183988.html 官网: http://flume.apache.org/documentation ...
- c++学习笔记之多态和虚函数
有了虚函数,基类指针指向基类对象时就使用基类的成员(包括成员函数和成员变量),指向派生类对象时就使用派生类的成员.换句话说,基类指针可以按照基类的方式来做事,也可以按照派生类的方式来做事,它有多种形态 ...
- linux常用终端命令(三)远程管理命令
三.远程管理常用命令 关机/重启 shutdown 查看或配置网卡信息 ifconfig ping 远程登录和复制文件 ssh scp 1.关机/重启 序号 命令 对应英文 作用 01 shutdow ...
- Laravel-admin 消息提醒、播放音频、点击跳转
jquery-toastr 消息提醒.播放音频.点击跳转 应用情景,有新的订单生成,后台进行消息提醒并播放音频(这里用到轮询简单实现):下面附代码 1.找到laravel-admin 中的 index ...