DRF url控制 解析器 响应器 版本控制 分页(常规分页,偏移分页,cursor游标分页)
| url控制 |
第二种写法(只要继承了ViewSetMixin)
- url(r'^pub/$',views.Pub.as_view({'get':'list','post':'create'})), #获取所有记得路由后面加$结束符 #pub/?format=json
- url(r'^pub\.(?P<format>\w+)$',views.Pub.as_view({'get':'list','post':'create'})), #pub.json
- url(r'^pub/(?P<pk>\d+)$',views.Pub.as_view({'get':'retrieve','put':'update','delete':'destroy'})), #获取一条
第三种(自动生成路由,必须继承ModelViewSet)
- from django.conf.urls import url,include
SimpleRouter 自动生成两条路由
- from rest_framework.routers import SimpleRouter,DefaultRouter #路由控制
- router = SimpleRouter()
- router.register('pub',views.Pub)
- urlpatterns = [
- url(r'^admin/', admin.site.urls),
- #其他路由
- url(r'',include(router.urls)),]
DefaultRouter自动生成四条路由
- from rest_framework.routers import SimpleRouter,DefaultRouter #路由控制
- router = DefaultRouter()
- router.register('pub',views.Pub)
- urlpatterns = [
- url(r'^admin/', admin.site.urls),
- #其他路由
- url(r'',include(router.urls)),]
| 解析器(一般不需要动,项目最开始全局配置一下就可以了) |
作用:控制视图类能够解析前端传过来的格式是什么样的 (默认配置三种都有) 有application/json,x-www-form-urlencoded,form-data等格式
全局使用:在settings中配置:
- REST_FRAMEWORK = {
- "DEFAULT_PARSER_CLASSES":[
- 'rest_framework.parsers.JSONParser',]
- }
局部使用:
- from rest_framework.parsers import JSONParser,FormParser,MultiPartParser,FileUploadParser
- #json字典 urlencoded form-data 文件
在视图类中
- parser_classes=[JSONParser,]
源码流程
当调用request.data的时候去执行解析方法

-->根据传过来的编码方式选择一个解析器对象

--->调用解析器对象的parser方法完成解析
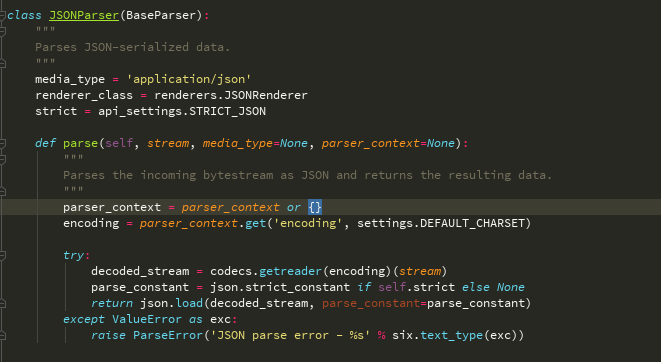
- 在调用request.data时,才进行解析,由此入手
- @property
- def data(self):
- if not _hasattr(self, '_full_data'):
- self._load_data_and_files()
- return self._full_data
- 查看self._load_data_and_files()方法---->self._data, self._files = self._parse()
- def _parse(self):
- #用户请求头里content_type的值
- media_type = self.content_type
- #self.parsers 就是用户配置的parser_classes = [FileUploadParser,FormParser ]
- #self里就有content_type,传入此函数
- parser = self.negotiator.select_parser(self, self.parsers)
- 查看self.negotiator.select_parser(self, self.parsers)
- def select_parser(self, request, parsers):
- #同过media_type和request.content_type比较,来返回解析器,然后调用解析器的解析方法
- #每个解析器都有media_type = 'multipart/form-data'属性
- for parser in parsers:
- if media_type_matches(parser.media_type, request.content_type):
- return parser
- return None
- 最终调用parser的解析方法来解析parsed = parser.parse(stream, media_type, self.parser_context)
源码注释
- Request实例化,parsers=self.get_parsers()
- Request(
- request,
- parsers=self.get_parsers(),
- authenticators=self.get_authenticators(),
- negotiator=self.get_content_negotiator(),
- parser_context=parser_context
- )
- get_parsers方法,循环实例化出self.parser_classes中类对象
- def get_parsers(self):
- return [parser() for parser in self.parser_classes]
- self.parser_classes 先从类本身找,找不到去父类找即APIVIew 中的
- parser_classes = api_settings.DEFAULT_PARSER_CLASSES
- api_settings是一个对象,对象里找DEFAULT_PARSER_CLASSES属性,找不到,会到getattr方法
- def __getattr__(self, attr):
- if attr not in self.defaults:
- raise AttributeError("Invalid API setting: '%s'" % attr)
- try:
- #调用self.user_settings方法,返回一个字典,字典再取attr属性
- val = self.user_settings[attr]
- except KeyError:
- # Fall back to defaults
- val = self.defaults[attr]
- # Coerce import strings into classes
- if attr in self.import_strings:
- val = perform_import(val, attr)
- # Cache the result
- self._cached_attrs.add(attr)
- setattr(self, attr, val)
- return val
- user_settings方法 ,通过反射去setting配置文件里找REST_FRAMEWORK属性,找不到,返回空字典
- @property
- def user_settings(self):
- if not hasattr(self, '_user_settings'):
- self._user_settings = getattr(settings, 'REST_FRAMEWORK', {})
- return self._user_settings
源码注释2
| 响应器 |
解析成字符串 还是一个浏览器页面
- from rest_framework.renderers import JSONRenderer,BrowsableAPIRenderer #解析成字符串 还是浏览器样式的
- # 不用动,就用全局配置即可默认配置中两个都有
全局使用
在settings中配置 settings默认配置中两个都有
- REST_FRAMEWORK = {
- 'DEFAULT_PARSER_CLASSES':[
- 'rest_framework.parsers.JSONParser',
- ],
- # 响应器 默认配置两个都由 这个是全局使用
- # 'DEFAULT_PARSER_CLASSES':[ 'rest_framework.renderers.JSONRenderer',
- # 'rest_framework.renderers.BrowsableAPIRenderer',]
- }
局部使用
在试图类中配置
- renderer_classes = [JSONRenderer, BrowsableAPIRenderer]
| 版本控制 |
作用用于控制版本 视图中 版本问题需要接受版本传过来的参数 注意是单个没有复数
内置版本控制
- from rest_framework.versioning import QueryParameterVersioning,AcceptHeaderVersioning,NamespaceVersioning,URLPathVersioning
- #基于url的get传参方式:QueryParameterVersioning------>如:/users?version=v1
- #基于url的正则方式:URLPathVersioning------>/v1/users/
- #基于 accept 请求头方式:AcceptHeaderVersioning------>Accept: application/json; version=1.0
- #基于主机名方法:HostNameVersioning------>v1.example.com
- #基于django路由系统的namespace:NamespaceVersioning------>example.com/v1/users/
局部使用
- #在CBV类中加入
- versioning_class = URLPathVersioning
- url中需要写
- url(r'(?P<version>[v1|v2])/register/$',views.Register.as_view()),
- url(r'(?P<version>[v1|v2])/register\.(?P<format>\w+)$',views.Register.as_view()),
- url(r'(?P<version>[v1|v2])/register/(?P<pk>\d+)$',views.Register.as_view()),
写访问路由的的时候要写上版本

全局使用
在settings中配置
- REST_FRAMEWORK = {
- "DEFAULT_PARSER_CLASSES":[
- 'rest_framework.parsers.JSONParser',
- ],
- 'DEFAULT_VERSIONING_CLASS':'rest_framework.versioning.URLPathVersioning',
- 'DEFAULT_VERSION': 'v1', # 默认版本(从request对象里取不到,显示的默认值)
- 'ALLOWED_VERSIONS': ['v1', 'v2'], # 允许的版本
- 'VERSION_PARAM': 'version', # URL中获取值的key
- }
路由不要写
- url(r'register/$',views.Register.as_view()),
但是访问路由的时候需要写上版本

在试图类中就可以通过,request.vesrsion取出当前访问哪个版本,相应的去执行相应版本的代码
示例
基于正则的方式
- from django.conf.urls import url, include
- from web.views import TestView
- urlpatterns = [
- url(r'^(?P<version>[v1|v2]+)/test/', TestView.as_view(), name='test'),
- ]
- url
- from rest_framework.views import APIView
- from rest_framework.response import Response
- from rest_framework.versioning import URLPathVersioning
- class TestView(APIView):
- versioning_class = URLPathVersioning
- def get(self, request, *args, **kwargs):
- # 获取版本
- print(request.version)
- # 获取版本管理的类
- print(request.versioning_scheme)
- # 反向生成URL
- reverse_url = request.versioning_scheme.reverse('test', request=request)
- print(reverse_url)
- return Response('GET请求,响应内容')
- views.py
View.py
- # 基于django内置,反向生成url
- from django.urls import reverse
- url2=reverse(viewname='ttt',kwargs={'version':'v2'})
- print(url2)
源码分析
- #执行determine_version,返回两个值,放到request对象里
- version, scheme = self.determine_version(request, *args, **kwargs)
- request.version, request.versioning_scheme = version, scheme
- def determine_version(self, request, *args, **kwargs):
- #当配置上版本类之后,就会实例化
- if self.versioning_class is None:
- return (None, None)
- scheme = self.versioning_class()
- return (scheme.determine_version(request, *args, **kwargs), scheme)
| 分页 |
常规分页 查看第n页 每页显示多少条
- #分页 #常规分页 偏移分页 cursor游标分页
- from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination
- class PublishView(APIView):
- versioning_class = URLPathVersioning
- parser_classes = [JSONRenderer,] #解析器
- def get(self,request,*args,**kwargs):
- #第一种方法,普通分页
- '''
- 查询出所有数据
- 实例化产生一个普通分页对象
- 每页显示多少条
- 查询指定查询那一页的key值
- '''
- ret= models.Publish.objects.all()
- page = PageNumberPagination()
- page.page_size = 3 #每页显示多少条
- page.page_query_param = 'page' #按照page名词显示那一页
- # 前端控制每页显示多少条的查看key值必然要size=9,表示一页显示9条
- page.page_size_query_param = 'size'
- #控制每页最大显示多少,size如果传100,最多也是显示10
- page.max_page_size = 10
- ret_page = page.paginate_queryset(ret,request,self)
- #序列化
- pub_ser = PublishSerlizers(ret_page,many=True)
- #去settings中配置每页显示多少条 这个是全局配置的话 局部配置全局可以不配置
- return Response(pub_ser.data)
settings中配置
- REST_FRAMEWORK = {
- # 每页显示两条
- 'PAGE_SIZE':2
- }
路由
- url(r'^(?P<version>[v1|v2]+)/publish/',views.PublishView.as_view())
serializer
- from rest_framework.serializers import ModelSerializer
- from app01 import models
- class PublishSerlizers(ModelSerializer):
- class Meta:
- model = models.Publish
- fields = '__all__'
偏移分页 在第n个位置向前向后查询第n个位置
- #分页 #常规分页 偏移分页 cursor游标分页
- from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination
- class PublishView(APIView):
- versioning_class = URLPathVersioning
- parser_classes = [JSONRenderer,] #解析器
- def get(self,request,*args,**kwargs): #偏移分页
- ret = models.Publish.objects.all()
- #实例化产生一个偏移分页对象
- page= LimitOffsetPagination()
- # 四个参数:
- # 从标杆位置往后取几个,默认取3个,可以指定
- page.default_limit = 3
- # 每条取得条数
- page.limit_query_param ='limit'
- # 标杆值,现象偏移到那个位置,如果offset=6, 表示当前在第6条位置上,往后取
- page.offset_query_param = 'offset'
- # 最大取10条
- page.max_limit = 10
- ret_page = page.paginate_queryset(ret,request,self)
- #序列化
- pub_ser= PublishSerlizers(ret_page,many=True)
- #取settings中配置每页显示多少条
- return page.get_paginated_response(pub_ser.data)
cursor游标分页
- from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination
- class PublishView(APIView):
- versioning_class = URLPathVersioning
- parser_classes=[JSONParser,]
- def get(self, request, *args, **kwargs):
- ret = models.Publish.objects.all()
- # 实例化产生一个偏移分页对象
- page = CursorPagination()
- #三个参数:
- #每页显示的大小
- page.page_size=3
- #查询的key值
- page.cursor_query_param='cursor'
- # 按什么排序
- page.ordering='id'
- ret_page = page.paginate_queryset(ret, request, self)
- # 序列化
- pub_ser = serializer.PublishSerializers(ret_page, many=True)
- # 去setting中配置每页显示多少条
- return page.get_paginated_response(pub_ser.data)
DRF url控制 解析器 响应器 版本控制 分页(常规分页,偏移分页,cursor游标分页)的更多相关文章
- drf 解析器,响应器,路由控制
解析器 作用: 根据请求头 content-type 选择对应的解析器对请求体内容进行处理. 有application/json,x-www-form-urlencoded,form-data等格式 ...
- Django框架深入了解_04(DRF之url控制、解析器、响应器、版本控制、分页)
一.url控制 基本路由写法:最常用 from django.conf.urls import url from django.contrib import admin from app01 impo ...
- DRF的解析器和渲染器
解析器 解析器的作用 解析器的作用就是服务端接收客户端传过来的数据,把数据解析成自己可以处理的数据.本质就是对请求体中的数据进行解析. 在了解解析器之前,我们要先知道Accept以及ContentTy ...
- DRF 的解析器和渲染器
一.解析器 解析器作用 解析器的作用就是服务端接收客户端传过来的数据,把数据解析成自己可以处理的数据.本质就是对请求体中的数据进行解析. 在了解解析器之前,我们要先知道Accept以及ContentT ...
- 【DRF解析器和渲染器】
目录 解析器 Django中的解析器 DRF中的解析器 DRF中的渲染器 @ *** 解析器 解析器的作用就是服务端接收客户端传过来的数据,把数据解析成自己想要的数据类型的过程. 本质就是对请求体中的 ...
- Django REST framework解析器和渲染器
解析器 解析器的作用 解析器的作用就是服务端接收客户端传过来的数据,把数据解析成自己可以处理的数据.本质就是对请求体中的数据进行解析. 在了解解析器之前,我们要先知道Accept以及ContentTy ...
- 打造属于前端的Uri解析器
今天和大家一起讨论一下如何打造一个属于前端的url参数解析器.如果你是一个Web开发工程师,如果你了解过后端开发语言,譬如:PHP,Java等,那么你对下面的代码应该不会陌生: $kw = $_GET ...
- 高性能Java解析器实现过程详解
如果你没有指定数据或语言标准的或开源的Java解析器, 可能经常要用Java实现你自己的数据或语言解析器.或者,可能有很多解析器可选,但是要么太慢,要么太耗内存,或者没有你需要的特定功能.或者开源解析 ...
- Django REST framework基础:解析器和渲染器
解析器 解析器的作用 解析器的作用就是服务端接收客户端传过来的数据,把数据解析成自己可以处理的数据.本质就是对请求体中的数据进行解析. 在了解解析器之前,我们要先知道Accept以及ContentTy ...
随机推荐
- csp-s模拟84
T1: 考虑如何能按顺序生成光滑数.对每个质数用队列维护包含此质数的候选集合,每次从所有队首取出最小的作为一个光滑数,用每个质数乘上这个光滑数并加入相应候选集合.这样不会漏掉一个光滑数,但会有重复.比 ...
- python 二进制加法
bin(int(a,2)+int(b,2))[2:]
- app支付宝充值
首先支付宝需要开通app 支付 然后登录支付宝 ,点击合作伙伴, 进入 开放平台,申请一个应用. 下载支付宝开放平台助手, 生成应用公钥,点击上传 设置进入之前申请的应用,支付宝自动生成支付宝公钥,设 ...
- 手把手教你在Linux系统下安装MongoDB
1. 下载最新的stable版MongoDB [root@spirit-of-fire ~]# wget http://downloads.mongodb.org/linux/mongodb-linu ...
- 整合spring boot时操作数据库时报错Caused by: java.lang.InstantiationException: tk.mybatis.mapper.provider.base.B
原文:https://blog.csdn.net/u__f_o/article/details/82756701 一般出现这种情况,应该是没有扫描到对应的mapper包,即在启动类下配置MapperS ...
- map,实现技巧,id
cf #include<iostream> #include<cstdio> #include<algorithm> #include<vector> ...
- php屏蔽电话号码中间四位
php屏蔽电话号码中间四位 一.总结 一句话总结: 直接就是substr_replace函数:$str = substr_replace("13966778888",'****', ...
- [log4j]Error:The method getLogger(String) in the type Logger is not applicable for the arguments
原因:本该导入import org.apache.log4j.Logger; 结果成了import java.util.logging.Logger; 如果硬把private static Logge ...
- JVM | JVM的核心技术
说到JVM,很多工作多年的老铁,可能就有点发憷了,因为搬砖多年,一直使用java这个工具,对于JVM没有了解过,有句话面试造航母,上班拧螺丝,要啥自行车啊,知道如何搬砖就可以了,为啥要懂这么多,如果你 ...
- openstack核心组件--cinder存储服务(6)
一.cinder 介绍: 理解 Block Storage 操作系统获得存储空间的方式一般有两种: 通过某种协议(SAS,SCSI,SAN,iSCSI 等)挂接裸硬盘,然后分区.格式化.创建文件系 ...