Hystrix服务容错保护
一、什么是灾难性雪崩效应?
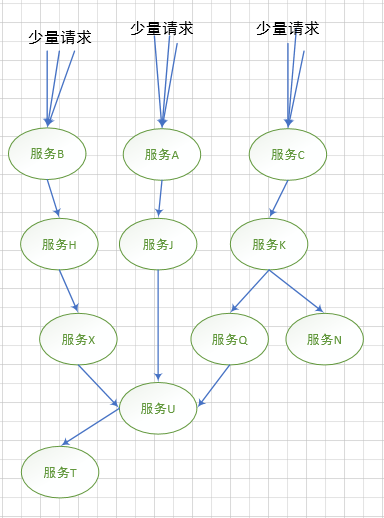


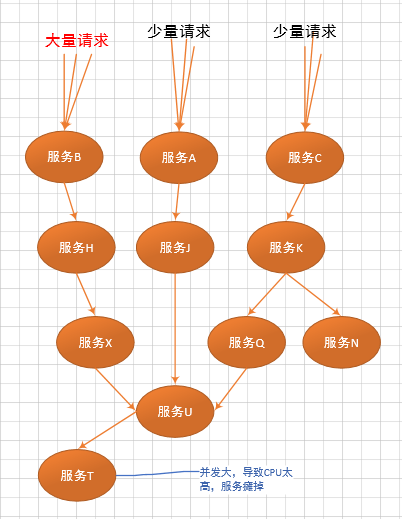
造成灾难性雪崩效应的原因,可以简单归结为下述三种:
服务提供者不可用。如:硬件故障、程序BUG、缓存击穿、并发请求量过大等。
重试加大流量。如:用户重试、代码重试逻辑等。
服务调用者不可用。如:同步请求阻塞造成的资源耗尽等。
雪崩效应最终的结果就是:服务链条中的某一个服务不可用,导致一系列的服务不可用,最终造成服务逻辑崩溃。这种问题造成的后果,往往是无法预料的。
二、如何解决灾难性雪崩效应?
解决灾难性雪崩效应的方式通常有:降级、隔离、熔断、请求缓存、请求合并。
在Spring cloud中处理服务雪崩效应,都需要依赖hystrix组件。
在pom文件中都需要引入下述依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
通常来说,开发的时候,使用ribbon处理服务灾难雪崩效应,开发的成本低。维护成本高。使用feign技术处理服务灾难雪崩效应,开发的成本较高,维护成本低。
2.1 降级
降级是指,当请求超时、资源不足等情况发生时进行服务降级处理,不调用真实服务逻辑,而是使用快速失败(fallback)方式直接返回一个托底数据,保证服务链条的完整,避免服务雪崩。
解决服务雪崩效应,都是避免application client请求application service时,出现服务调用错误或网络问题。处理手法都是在application client中实现。我们需要在application client相关工程中导入hystrix依赖信息。并在对应的启动类上增加新的注解@EnableCircuitBreaker,这个注解是用于开启hystrix熔断器的,简言之,就是让代码中的hystrix相关注解生效。
启动器代码片段
@EnableDiscoveryClient
@SpringBootApplication
@EnableHystrix
@EnableCircuitBreaker
public class HystrixApplicationClientApplication { public static void main(String[] args) {
SpringApplication.run(HystrixApplicationClientApplication.class, args);
} }
在调用application service相关代码中,增加新的方法注解@HystrixCommand,代表当前方法启用Hystrix处理服务雪崩效应。
@HystrixCommand注解中的属性:
fallbackMethod - 代表当调用的application service出现问题时,调用哪个fallback快速失败处理方法返回托底数据。
@Autowired
private LoadBalancerClient loadBalancerClient; /**
* 服务降级处理。
* 当前方法远程调用application service服务的时候,如果service服务出现了任何错误(超时,异常等)
* 不会将异常抛到客户端,而是使用本地的一个fallback(错误返回)方法来返回一个托底数据。
* 避免客户端看到错误页面。
* 使用注解来描述当前方法的服务降级逻辑。
*
* @HystrixCommand - 开启Hystrix命令的注解。代表当前方法如果出现服务调用问题,使用Hystrix逻辑来处理。
* 重要属性 - fallbackMethod 错误返回方法名。
* 如果当前方法调用服务,远程服务出现问题的时候,
* 调用本地的哪个方法得到托底数据。
*
* Hystrix会调用fallbackMethod指定的方法,获取结果,并返回给客户端。
*/
@HystrixCommand(fallbackMethod="downgradeFallback")
public List<Map<String, Object>> testDowngrade() {
System.out.println("testDowngrade method : " + Thread.currentThread().getName());
ServiceInstance si = this.loadBalancerClient.choose("eureka-application-service");
StringBuilder sb = new StringBuilder();
sb.append("http://").append(si.getHost()).append(":").append(si.getPort()).append("/test");
System.out.println("request application service URL : " + sb.toString());
RestTemplate rt = new RestTemplate();
ParameterizedTypeReference<List<Map<String, Object>>> type = new ParameterizedTypeReference<List<Map<String, Object>>>() {};
ResponseEntity<List<Map<String, Object>>> response = rt.exchange(sb.toString(), HttpMethod.GET, null, type);
List<Map<String, Object>> result = response.getBody();
return result;
} /**
* fallback方法。本地定义的。用来处理远程服务调用错误时,返回的基础数据。
*/
@SuppressWarnings("unused")
private List<Map<String, Object>> downgradeFallback(){
List<Map<String, Object>> result = new ArrayList<>(); Map<String, Object> data = new HashMap<>();
data.put("id", -1);
data.put("name", "downgrade fallback datas");
data.put("age", 0); result.add(data); return result;
}
2.2 缓存
缓存是指请求缓存。通常意义上说,就是将同样的GET请求结果缓存起来,使用缓存机制(如redis、mongodb)提升请求响应效率。
使用请求缓存时,需要注意非幂等性操作对缓存数据的影响。
请求缓存是依托某一缓存服务来实现的。在案例中使用redis作为缓存服务器,那么可以使用spring-data-redis来实现redis的访问操作。
需要在application client相关工程中导入下述依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
在Spring Cloud应用中,启用spring对cache的支持,需要在启动类中增加注解@EnableCaching,此注解代表当前应用开启spring对cache的支持。简言之就是使spring-data-redis相关的注解生效,如:@CacheConfig、@Cacheable、@CacheEvict等。
spring cloud会检查每个幂等性请求,如果请求完全相同(路径、参数等完全一致),则首先访问缓存redis,查看缓存数据,如果缓存中有数据,则不调用远程服务application service。如果缓存中没有数据,则调用远程服务,并将结果缓存到redis中,供后续请求使用。
如果请求是一个非幂等性操作,则会根据方法的注解来动态管理redis中的缓存数据,避免数据不一致。
注意:使用请求缓存会导致很多的隐患,如:缓存管理不当导致的数据不同步、问题排查困难等。在商业项目中,解决服务雪崩效应不推荐使用请求缓存。
2.3 请求合并
略
2.4 熔断
当一定时间内,异常请求比例(请求超时、网络故障、服务异常等)达到阀值时,启动熔断器,熔断器一旦启动,则会停止调用具体服务逻辑,通过fallback快速返回托底数据,保证服务链的完整。
熔断有自动恢复机制,如:当熔断器启动后,每隔5秒,尝试将新的请求发送给服务提供者,如果服务可正常执行并返回结果,则关闭熔断器,服务恢复。如果仍旧调用失败,则继续返回托底数据,熔断器持续开启状态。
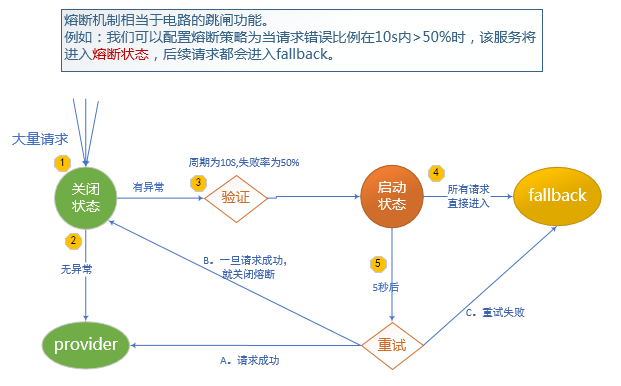
熔断的实现是在调用远程服务的方法上增加@HystrixCommand注解。当注解配置满足则开启或关闭熔断器。
注解属性描述:
CIRCUIT_BREAKER_ENABLED
"circuitBreaker.enabled";
是否开启熔断策略。默认值为true。
CIRCUIT_BREAKER_REQUEST_VOLUME_THRESHOLD
"circuitBreaker.requestVolumeThreshold";
10ms内,请求并发数超出则触发熔断策略。默认值为20。
CIRCUIT_BREAKER_SLEEP_WINDOW_IN_MILLISECONDS
"circuitBreaker.sleepWindowInMilliseconds";
当熔断策略开启后,延迟多久尝试再次请求远程服务。默认为5秒。
CIRCUIT_BREAKER_ERROR_THRESHOLD_PERCENTAGE
"circuitBreaker.errorThresholdPercentage";
10ms内,出现错误的请求百分比达到限制,则触发熔断策略。默认为50%。
CIRCUIT_BREAKER_FORCE_OPEN
"circuitBreaker.forceOpen";
是否强制开启熔断策略。即所有请求都返回fallback托底数据。默认为false。
CIRCUIT_BREAKER_FORCE_CLOSED
"circuitBreaker.forceClosed";
是否强制关闭熔断策略。即所有请求一定调用远程服务。默认为false。
/**
* 熔断机制
* 相当于一个强化的服务降级。 服务降级是只要远程服务出错,立刻返回fallback结果。
* 熔断是收集一定时间内的错误比例,如果达到一定的错误率。则启动熔断,返回fallback结果。
* 间隔一定时间会将请求再次发送给application service进行重试。如果重试成功,熔断关闭。
* 如果重试失败,熔断持续开启,并返回fallback数据。
* @HystrixCommand 描述方法。
* fallbackMethod - fallback方法名
* commandProperties - 具体的熔断标准。类型是HystrixProperty数组。
* 可以通过字符串或常亮类配置。
* CIRCUIT_BREAKER_REQUEST_VOLUME_THRESHOLD - 错误数量。在10毫秒内,出现多少次远程服务调用错误,则开启熔断。
* 默认20个。 10毫秒内有20个错误请求则开启熔断。
* CIRCUIT_BREAKER_ERROR_THRESHOLD_PERCENTAGE - 错误比例。在10毫秒内,远程服务调用错误比例达标则开启熔断。
* CIRCUIT_BREAKER_SLEEP_WINDOW_IN_MILLISECONDS - 熔断开启后,间隔多少毫秒重试远程服务调用。默认5000毫秒。
*/
@HystrixCommand(fallbackMethod = "breakerFallback",
commandProperties = {
// 默认20个;10s内请求数大于20个时就启动熔断器,当请求符合熔断条件时将触发getFallback()。
@HystrixProperty(name=HystrixPropertiesManager.CIRCUIT_BREAKER_REQUEST_VOLUME_THRESHOLD,
value="10"),
// 请求错误率大于50%时就熔断,然后for循环发起请求,当请求符合熔断条件时将触发getFallback()。
@HystrixProperty(name=HystrixPropertiesManager.CIRCUIT_BREAKER_ERROR_THRESHOLD_PERCENTAGE,
value="50"),
// 默认5秒;熔断多少秒后去尝试请求
@HystrixProperty(name=HystrixPropertiesManager.CIRCUIT_BREAKER_SLEEP_WINDOW_IN_MILLISECONDS,
value="5000")}
)
public List<Map<String, Object>> testBreaker() {
System.out.println("testBreaker method thread name : " + Thread.currentThread().getName());
ServiceInstance si = this.loadBalancerClient.choose("eureka-application-service");
StringBuilder sb = new StringBuilder();
sb.append("http://").append(si.getHost()).append(":").append(si.getPort()).append("/test");
System.out.println("request application service URL : " + sb.toString());
RestTemplate rt = new RestTemplate();
ParameterizedTypeReference<List<Map<String, Object>>> type =
new ParameterizedTypeReference<List<Map<String, Object>>>() {
};
ResponseEntity<List<Map<String, Object>>> response = rt.exchange(sb.toString(), HttpMethod.GET, null, type);
List<Map<String, Object>> result = response.getBody();
return result;
} @SuppressWarnings("unused")
private List<Map<String, Object>> breakerFallback(){
System.out.println("breakerFallback method thread name : " + Thread.currentThread().getName());
List<Map<String, Object>> result = new ArrayList<>(); Map<String, Object> data = new HashMap<>();
data.put("id", -1);
data.put("name", "breaker fallback datas");
data.put("age", 0);
result.add(data);
return result;
}
2.5 隔离
2.5.1 线程池隔离
2.5.2 信号量隔离
略
Hystrix服务容错保护的更多相关文章
- 笔记:Spring Cloud Hystrix 服务容错保护
由于每个单元都在不同的进程中运行,依赖通过远程调用的方式执行,这样就有可能因为网络原因或是依赖服务自身问题出现调用故障或延迟,而这些问题会直接导致调用方的对外服务也出现延迟,若此时调用方的请求不断增加 ...
- Spring Cloud Hystrix 服务容错保护 5.1
Spring Cloud Hystrix介绍 在微服务架构中,通常会存在多个服务层调用的情况,如果基础服务出现故障可能会发生级联传递,导致整个服务链上的服务不可用为了解决服务级联失败这种问题,在分布式 ...
- Spring Cloud Hystrix 服务容错保护
目录 一.Hystrix 是什么 二.Hystrix断路器搭建 三.断路器优化 一.Hystrix 是什么 在微服务架构中,我们将系统拆分成了若干弱小的单元,单元与单元之间通过HTTP或者TCP等 ...
- spring cloud 入门系列四:使用Hystrix 实现断路器进行服务容错保护
在微服务中,我们将系统拆分为很多个服务单元,各单元之间通过服务注册和订阅消费的方式进行相互依赖.但是如果有一些服务出现问题了会怎么样? 比如说有三个服务(ABC),A调用B,B调用C.由于网络延迟或C ...
- Spring Cloud(四):服务容错保护 Hystrix【Finchley 版】
Spring Cloud(四):服务容错保护 Hystrix[Finchley 版] 发表于 2018-04-15 | 更新于 2018-05-07 | 分布式系统中经常会出现某个基础服务不可用 ...
- 白话SpringCloud | 第五章:服务容错保护(Hystrix)
前言 前一章节,我们知道了如何利用RestTemplate+Ribbon和Feign的方式进行服务的调用.在微服务架构中,一个服务可能会调用很多的其他微服务应用,虽然做了多集群部署,但可能还会存在诸如 ...
- Spring Cloud (8) 服务容错保护-Hystrix依赖隔离
依赖隔离 docker使用舱壁模式来实现进程的隔离,使容器与容器之间不会互相影响.而Hystrix则使用该模式实现线程池的隔离,它会为每一个Hystrix命令创建一个独立的线程池,这样就算在某个Hys ...
- SpringCould-------使用Hystrix 实现断路器进行服务容错保护
消费: <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.or ...
- SpringCloud+Hystrix服务容错
Netflix Hystrix — 应对复杂分布式系统中的延时和故障容错 +应用场景 分布式系统中经常会出现某个基础服务不可用造成整个系统不可用的情况, 这种现象被称为服务雪崩效应. 为了应对服务雪崩 ...
随机推荐
- python sqlite3查询表记录
1.查询数据库log_info表最后10条记录. desc - 指"降序" 解决的方法是:按照ID 逆序排列,选取前10个 select * from 'log_info' ord ...
- javascript中的Date数据类型
javascript中,Date代表日期对象,其常见的用法如下: 一.Date的构造函数 有四种形式的Date构造函数,详见下面代码的注释: //1.构造函数没有参数,则返回当前日期的Date对象 v ...
- LeetCode 132. 分割回文串 II(Palindrome Partitioning II)
题目描述 给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串. 返回符合要求的最少分割次数. 示例: 输入: "aab" 输出: 1 解释: 进行一次分割就可将 s ...
- 在linux上使用impdp命令时提示ORA-12154: TNS:could not resolve the connect identifier specified的问题
今天在一台linux服务器上用impdp命令导入dmp文件时出现了错误: ORA: TNS:could not resolve the connect identifier specified 我使用 ...
- leetcode-hard-array-179 Largest Number-NO
mycode 写的很复杂,还报错... 参考: class Solution: # @param {integer[]} nums # @return {string} def largestNum ...
- 【Java/csv】一个CSV文件解析类(转载)
/*下文写得不错,值得学习**/ import java.io.BufferedReader; import java.io.FileReader; import java.util.ArrayLis ...
- Hibernate3运行原理
Hibernate的运行过程如下: 1.应用程序先调用Configuration类,该类读取Hibernate配置文件及映射文件中的信息,2.并用这些信息生成一个SessionFactory对象,3. ...
- ShockUtil振动工具类
import android.app.Activity; import android.app.Service; import android.content.Context; import andr ...
- PackageUtils
import android.content.Context; import android.content.Intent; import android.content.pm.Application ...
- python之scrapy携带Cookies模拟登陆
知识点 """ scrapy两种模拟登陆: 1.直接携带cookie 2.找到发送post请求的url地址,带上信息,发送请求 应用场景: 1.cookie过期时间很长, ...