seq2seq聊天模型(三)—— attention 模型
注意力seq2seq模型
大部分的seq2seq模型,对所有的输入,一视同仁,同等处理。
但实际上,输出是由输入的各个重点部分产生的。
比如:
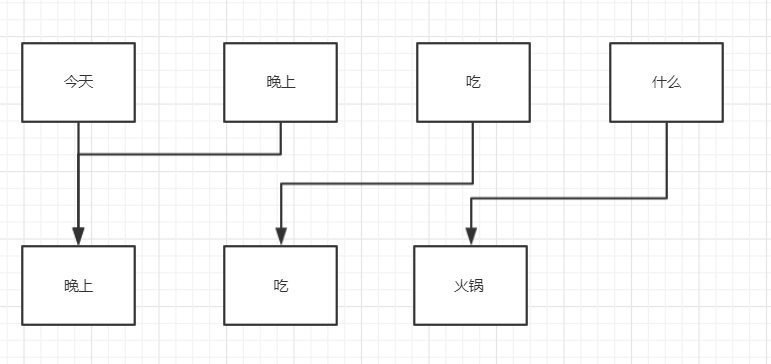
(举例使用,实际比重不是这样)
对于输出“晚上”,
各个输入所占比重: 今天-50%,晚上-50%,吃-100%,什么-0%
对于输出“吃”,
各个输入所占比重: 今天-0%,晚上-0%,吃-100%,什么-0%
特别是在seq2seq的看图说话应用情景中

睡觉还握着笔的baby
这里的重点就是baby,笔!通过这些重点,生成描述。
下面这个图,就是attention的关键原理

tensorlfow 代码
encoder 和常规的seq2seq中的encoder一样,只是在attention模型中,不再需要encoder累计的state状态,需要的是各个各个分词的outputs输出。
在训练的时候,将这个outputs与一个权重值一起拟合逼进目标值。
这个权重值,就是各个输入对目标值的贡献占比,也就是注意力机制!
dec_cell = self.cell(self.hidden_size)
attn_mech = tf.contrib.seq2seq.LuongAttention(
num_units=self.attn_size, # 注意机制权重的size
memory=self.enc_outputs, # 主体的记忆,就是decoder输出outputs
memory_sequence_length=self.enc_sequence_length,
# normalize=False,
name='LuongAttention')
dec_cell = tf.contrib.seq2seq.AttentionWrapper(
cell=dec_cell,
attention_mechanism=attn_mech,
attention_layer_size=self.attn_size,
# attention_history=False, # (in ver 1.2)
name='Attention_Wrapper')
initial_state = dec_cell.zero_state(dtype=tf.float32, batch_size=batch_size)
# output projection (replacing `OutputProjectionWrapper`)
output_layer = Dense(dec_vocab_size + 2, name='output_projection')
# lstm的隐藏层size和attention 注意机制权重的size要相同
seq2seq聊天模型(三)—— attention 模型的更多相关文章
- seq2seq聊天模型(一)
原创文章,转载请注明出处 最近完成了sqe2seq聊天模型,磕磕碰碰的遇到不少问题,最终总算是做出来了,并符合自己的预期结果. 本文目的 利用流程图,从理论方面,回顾,总结seq2seq模型, seq ...
- 深度学习之seq2seq模型以及Attention机制
RNN,LSTM,seq2seq等模型广泛用于自然语言处理以及回归预测,本期详解seq2seq模型以及attention机制的原理以及在回归预测方向的运用. 1. seq2seq模型介绍 seq2se ...
- 从Seq2seq到Attention模型到Self Attention
Seq2seq Seq2seq全名是Sequence-to-sequence,也就是从序列到序列的过程,是近年当红的模型之一.Seq2seq被广泛应用在机器翻译.聊天机器人甚至是图像生成文字等情境. ...
- [转] 图解Seq2Seq模型、RNN结构、Encoder-Decoder模型 到 Attention
from : https://caicai.science/2018/10/06/attention%E6%80%BB%E8%A7%88/ 一.Seq2Seq 模型 1. 简介 Sequence-to ...
- Seq2Seq模型 与 Attention 策略
Seq2Seq模型 传统的机器翻译的方法往往是基于单词与短语的统计,以及复杂的语法结构来完成的.基于序列的方式,可以看成两步,分别是 Encoder 与 Decoder,Encoder 阶段就是将输入 ...
- 文本分类实战(五)—— Bi-LSTM + Attention模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- Attention模型
李宏毅深度学习 https://www.bilibili.com/video/av9770302/?p=8 Generation 生成模型基本结构是这样的, 这个生成模型有个问题是我不能干预数据生成, ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:Attention模型--训练
import tensorflow as tf # 1.参数设置. # 假设输入数据已经转换成了单词编号的格式. SRC_TRAIN_DATA = "F:\\TensorFlowGoogle ...
- SDN三种模型解析
数十年前,计算机科学家兼网络作家Andrew S. Tanenbaum讽刺标准过多难以选择,当然现在也是如此,比如软件定义网络模型的数量也很多.但是在考虑部署软件定义网络(SDN)或者试点之前,首先需 ...
随机推荐
- uboot中打开 debug调试信息的方法
在uboot目录下include/common.h中, 原理:只需要让 _DEBUG 的值为 1即可. 最简单的做法就是在下图第一行之前添加 #define DEBUG
- 【爬虫集合】Python爬虫
一.爬虫学习教程 1. https://www.jianshu.com/u/c32d557edfa3 2. WebMagic是一个简单灵活的Java爬虫框架.基于WebMagic,你可以快速开发出一个 ...
- 减少打包组件vue.config.js——Webpack的externals的使用
vue.config.js module.exports = { configureWebpack:{ externals: { vue: 'Vue', 'vue-router':'VueRouter ...
- call、apply、bind一直是不求甚解!
一直感觉代码中有call和apply就很高大上(看不懂),但是都草草略过,今天非要弄明白!以前总是死记硬背:call.apply.bind 都是用来修改函数中的this,传参时,call是一个个传参, ...
- SVN配置使用及移植
使用svn作为配置管理工具及其普遍的用于项目开发中,网上有很多关于svn的原理介绍及命令行管理教程.这里仅仅分享下个人配置及使用的过程,不通过命令行,可简单的上手操作.如有遗漏欢迎留言交流. 配置及使 ...
- perl自定义简易的面向对象的栈与队列类
perl中的数组其实已经具备了栈与队列的特点,下面是对数组经过一些封装的stack,queue对象 1.Stack类 创建一个Stack.pm文件 package Stack; sub new{ $s ...
- curl: (7) couldn't connect to host 解决方法
使用curl命令访问网站时报错: [root@bqh-119 ~]# curl -I www.test.com curl: (7) couldn't connect to host [root@bqh ...
- Computer Vision_18_Image Stitching:Automatic Panoramic Image Stitching using Invariant Features——2007
此部分是计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面.对于自己不太熟悉的领域比如摄像机标定和立体视觉,仅仅列出上google上引用次数比较多的文献.有一些刚刚出版的 ...
- Octave基本语法
基本运算 octave:3> 5+6 ans = 11 octave:4> 3-2 ans = 1 octave:5> 8*9 ans = 72 octave:6> 8/4 a ...
- socket 编程的一些应用例子
1.#传输文件的例子 import socketfrom socket import *import osimport requests import time,socketserver,struct ...