HBase管理与监控——HMaster或HRegionServer自动停止挂掉
问题描述
HBase在运行一段时间后,会出现以下2种情况:
1、HMaster节点自动挂掉;
通过jps命令,发现HMaster进程没了,只剩下HRegionServer,此时应用还能正常往HBase写入数据
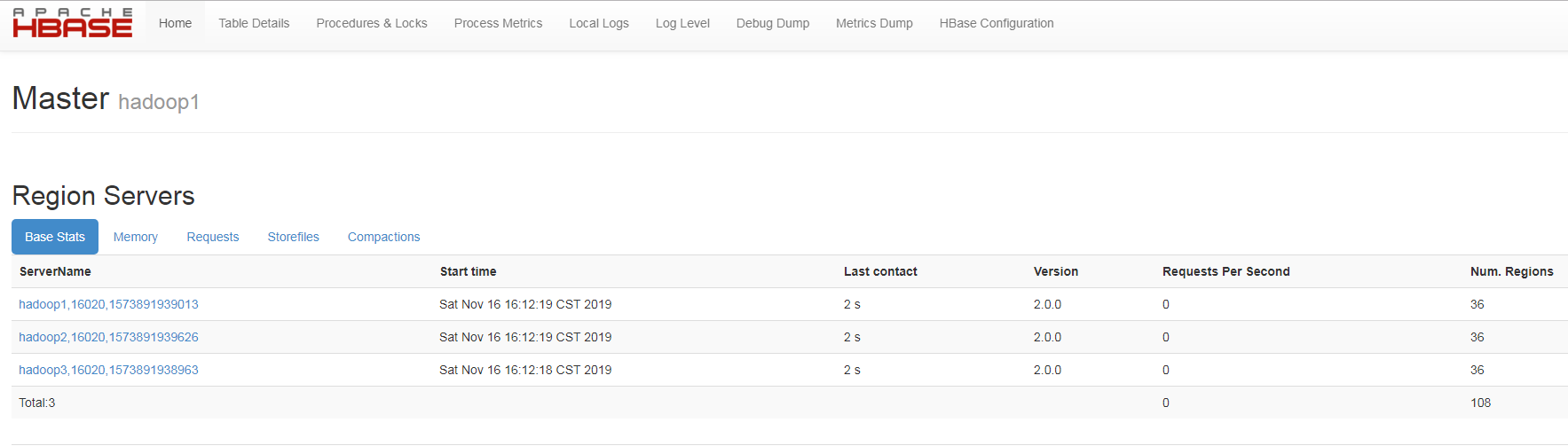
此时以下界面无法打开:
2、HRegionServer节点自动挂掉
通过jps命令,发现HRegionServer进程没了,此时应用往HBase写入数据时不报错

问题排查
问题1:查看HMaster节点的日志,出现一些异常信息,且跟zk有关。
以下标红的字说明:休眠了64293ms而不是3000ms,这可能是因为垃圾收集暂停时间太长
-- ::, WARN [ResponseProcessor for block BP--127.0.0.1-:blk_1085889831_12149164] hdfs.DFSClient: Slow ReadProcessor read fields took 30161ms (threshold=30000ms); ack: seqno: reply: SUCCESS reply: SUCCESS downstreamAckTimeNanos: flag: flag: , targets: [DatanodeInfoWithStorage[172.16.10.91:,DS-9402e3dd-982e-4f18-be39-3a7dfc0d2672,DISK], DatanodeInfoWithStorage[172.16.10.92:,DS-b2143ca2-8adf-450c-b662-17cc8210c565,DISK]]
-- ::, INFO [LruBlockCacheStatsExecutor] hfile.LruBlockCache: totalSize=884.18 KB, freeSize=1.15 GB, max=1.15 GB, blockCount=, accesses=, hits=, hitRatio=, cachingAccesses=, cachingHits=, cachingHitsRatio=,evictions=, evicted=, evictedPerRun=0.0
-- ::, INFO [master/hadoop1:.splitLogManager..Chore.] hbase.ScheduledChore: Chore: SplitLogManager Timeout Monitor missed its start time
-- ::, WARN [master/hadoop1:-SendThread(172.16.10.91:)] zookeeper.ClientCnxn: Client session timed out, have not heard from server in 73768ms for sessionid 0x1023619d3c30006
-- ::, INFO [LruBlockCacheStatsExecutor] hfile.LruBlockCache: totalSize=884.18 KB, freeSize=1.15 GB, max=1.15 GB, blockCount=, accesses=, hits=, hitRatio=, cachingAccesses=, cachingHits=, cachingHitsRatio=,evictions=, evicted=, evictedPerRun=0.0
-- ::, INFO [master/hadoop1:.splitLogManager..Chore.] hbase.ScheduledChore: Chore: SplitLogManager Timeout Monitor missed its start time
-- ::, WARN [master/hadoop1:] util.Sleeper: We slept 64293ms instead of 3000ms, this is likely due to a long garbage collecting pause and it's usually bad, see http://hbase.apache.org/book.html#trouble.rs.runtime.zkexpired
-- ::, WARN [main-SendThread(172.16.10.91:)] zookeeper.ClientCnxn: Client session timed out, have not heard from server in 64945ms for sessionid 0x1023619d3c30002
-- ::, INFO [master/hadoop1:-SendThread(172.16.10.91:)] zookeeper.ClientCnxn: Client session timed out, have not heard from server in 73768ms for sessionid 0x1023619d3c30006, closing socket connection and attempting reconnect
-- ::, INFO [main-SendThread(172.16.10.91:)] zookeeper.ClientCnxn: Client session timed out, have not heard from server in 64945ms for sessionid 0x1023619d3c30002, closing socket connection and attempting reconnect
-- ::, WARN [ResponseProcessor for block BP--127.0.0.1-:blk_1085889831_12149164] hdfs.DFSClient: DFSOutputStream ResponseProcessor exception for block BP--127.0.0.1-:blk_1085889831_12149164
java.io.EOFException: Premature EOF: no length prefix available
at org.apache.hadoop.hdfs.protocolPB.PBHelper.vintPrefixed(PBHelper.java:)
at org.apache.hadoop.hdfs.protocol.datatransfer.PipelineAck.readFields(PipelineAck.java:)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer$ResponseProcessor.run(DFSOutputStream.java:)
-- ::, WARN [DataStreamer for file /hbase/MasterProcWALs/pv2-.log block BP--127.0.0.1-:blk_1085889831_12149164] hdfs.DFSClient: Error Recovery for block BP--127.0.0.1-:blk_1085889831_12149164 in pipeline DatanodeInfoWithStorage[172.16.10.91:,DS-9402e3dd-982e-4f18-be39-3a7dfc0d2672,DISK], DatanodeInfoWithStorage[172.16.10.92:,DS-b2143ca2-8adf-450c-b662-17cc8210c565,DISK]: datanode (DatanodeInfoWithStorage[172.16.10.91:,DS-9402e3dd-982e-4f18-be39-3a7dfc0d2672,DISK]) is bad.
-- ::, INFO [master/hadoop1:-SendThread(172.16.10.92:)] zookeeper.ClientCnxn: Opening socket connection to server 172.16.10.92/172.16.10.92:. Will not attempt to authenticate using SASL (unknown error)
-- ::, INFO [master/hadoop1:-SendThread(172.16.10.92:)] zookeeper.ClientCnxn: Socket connection established to 172.16.10.92/172.16.10.92:, initiating session
-- ::, INFO [main-SendThread(172.16.10.92:)] zookeeper.ClientCnxn: Opening socket connection to server 172.16.10.92/172.16.10.92:. Will not attempt to authenticate using SASL (unknown error)
-- ::, WARN [master/hadoop1:-SendThread(172.16.10.92:)] zookeeper.ClientCnxn: Unable to reconnect to ZooKeeper service, session 0x1023619d3c30006 has expired
-- ::, INFO [master/hadoop1:-SendThread(172.16.10.92:)] zookeeper.ClientCnxn: Unable to reconnect to ZooKeeper service, session 0x1023619d3c30006 has expired, closing socket connection
-- ::, INFO [main-SendThread(172.16.10.92:)] zookeeper.ClientCnxn: Socket connection established to 172.16.10.92/172.16.10.92:, initiating session
-- ::, INFO [master/hadoop1:-EventThread] zookeeper.ClientCnxn: EventThread shut down for session: 0x1023619d3c30006
-- ::, INFO [master/hadoop1:.splitLogManager..Chore.] hbase.ScheduledChore: Chore: SplitLogManager Timeout Monitor missed its start time
-- ::, WARN [main-SendThread(172.16.10.92:)] zookeeper.ClientCnxn: Unable to reconnect to ZooKeeper service, session 0x1023619d3c30002 has expired
-- ::, INFO [main-SendThread(172.16.10.92:)] zookeeper.ClientCnxn: Unable to reconnect to ZooKeeper service, session 0x1023619d3c30002 has expired, closing socket connection
-- ::, WARN [master/hadoop1:.Chore.] zookeeper.ZKUtil: master:-0x1023619d3c30002, quorum=172.16.10.91:,172.16.10.92:,172.16.10.93:, baseZNode=/hbase Unable to list children of znode /hbase/replication/peers
org.apache.zookeeper.KeeperException$SessionExpiredException: KeeperErrorCode = Session expired for /hbase/replication/peers
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.ZooKeeper.getChildren(ZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper.getChildren(RecoverableZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.listChildrenAndWatchForNewChildren(ZKUtil.java:)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.listChildrenAndWatchThem(ZKUtil.java:)
at org.apache.hadoop.hbase.replication.ReplicationPeersZKImpl.getAllPeerIds(ReplicationPeersZKImpl.java:)
at org.apache.hadoop.hbase.master.cleaner.ReplicationZKNodeCleaner.getUnDeletedQueues(ReplicationZKNodeCleaner.java:)
at org.apache.hadoop.hbase.master.cleaner.ReplicationZKNodeCleanerChore.chore(ReplicationZKNodeCleanerChore.java:)
at org.apache.hadoop.hbase.ScheduledChore.run(ScheduledChore.java:)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$(ScheduledThreadPoolExecutor.java:)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:)
at org.apache.hadoop.hbase.JitterScheduledThreadPoolExecutorImpl$JitteredRunnableScheduledFuture.run(JitterScheduledThreadPoolExecutorImpl.java:)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:)
at java.lang.Thread.run(Thread.java:)
-- ::, ERROR [master/hadoop1:.Chore.] zookeeper.ZKWatcher: master:-0x1023619d3c30002, quorum=172.16.10.91:,172.16.10.92:,172.16.10.93:, baseZNode=/hbase Received unexpected KeeperException, re-throwing exception
org.apache.zookeeper.KeeperException$SessionExpiredException: KeeperErrorCode = Session expired for /hbase/replication/peers
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.ZooKeeper.getChildren(ZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper.getChildren(RecoverableZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.listChildrenAndWatchForNewChildren(ZKUtil.java:)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.listChildrenAndWatchThem(ZKUtil.java:)
at org.apache.hadoop.hbase.replication.ReplicationPeersZKImpl.getAllPeerIds(ReplicationPeersZKImpl.java:)
at org.apache.hadoop.hbase.master.cleaner.ReplicationZKNodeCleaner.getUnDeletedQueues(ReplicationZKNodeCleaner.java:)
at org.apache.hadoop.hbase.master.cleaner.ReplicationZKNodeCleanerChore.chore(ReplicationZKNodeCleanerChore.java:)
at org.apache.hadoop.hbase.ScheduledChore.run(ScheduledChore.java:)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$(ScheduledThreadPoolExecutor.java:)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:)
at org.apache.hadoop.hbase.JitterScheduledThreadPoolExecutorImpl$JitteredRunnableScheduledFuture.run(JitterScheduledThreadPoolExecutorImpl.java:)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:)
at java.lang.Thread.run(Thread.java:)
-- ::, ERROR [main-EventThread] master.HMaster: Master server abort: loaded coprocessors are: []
-- ::, ERROR [master/hadoop1:.Chore.] master.HMaster: Master server abort: loaded coprocessors are: []
-- ::, ERROR [main-EventThread] master.HMaster: ***** ABORTING master hadoop1,,: master:-0x1023619d3c30002, quorum=172.16.10.91:,172.16.10.92:,172.16.10.93:, baseZNode=/hbase master:-0x1023619d3c30002 received expired from ZooKeeper, aborting *****
org.apache.zookeeper.KeeperException$SessionExpiredException: KeeperErrorCode = Session expired
at org.apache.hadoop.hbase.zookeeper.ZKWatcher.connectionEvent(ZKWatcher.java:)
at org.apache.hadoop.hbase.zookeeper.ZKWatcher.process(ZKWatcher.java:)
at org.apache.zookeeper.ClientCnxn$EventThread.processEvent(ClientCnxn.java:)
at org.apache.zookeeper.ClientCnxn$EventThread.run(ClientCnxn.java:)
-- ::, ERROR [master/hadoop1:.Chore.] master.HMaster: ***** ABORTING master hadoop1,,: Cannot get the list of peers *****
org.apache.zookeeper.KeeperException$SessionExpiredException: KeeperErrorCode = Session expired for /hbase/replication/peers
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.ZooKeeper.getChildren(ZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper.getChildren(RecoverableZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.listChildrenAndWatchForNewChildren(ZKUtil.java:)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.listChildrenAndWatchThem(ZKUtil.java:)
at org.apache.hadoop.hbase.replication.ReplicationPeersZKImpl.getAllPeerIds(ReplicationPeersZKImpl.java:)
at org.apache.hadoop.hbase.master.cleaner.ReplicationZKNodeCleaner.getUnDeletedQueues(ReplicationZKNodeCleaner.java:)
at org.apache.hadoop.hbase.master.cleaner.ReplicationZKNodeCleanerChore.chore(ReplicationZKNodeCleanerChore.java:)
at org.apache.hadoop.hbase.ScheduledChore.run(ScheduledChore.java:)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$(ScheduledThreadPoolExecutor.java:)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:)
at org.apache.hadoop.hbase.JitterScheduledThreadPoolExecutorImpl$JitteredRunnableScheduledFuture.run(JitterScheduledThreadPoolExecutorImpl.java:)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:)
at java.lang.Thread.run(Thread.java:)
-- ::, INFO [master/hadoop1:.Chore.] regionserver.HRegionServer: ***** STOPPING region server 'hadoop1,16000,1573889992279' *****
-- ::, INFO [master/hadoop1:.Chore.] regionserver.HRegionServer: STOPPED: Stopped by master/hadoop1:.Chore.
-- ::, INFO [main-EventThread] regionserver.HRegionServer: ***** STOPPING region server 'hadoop1,16000,1573889992279' *****
-- ::, INFO [main-EventThread] regionserver.HRegionServer: STOPPED: Stopped by main-EventThread
-- ::, WARN [master/hadoop1:.Chore.] zookeeper.ZKUtil: master:-0x1023619d3c30002, quorum=172.16.10.91:,172.16.10.92:,172.16.10.93:, baseZNode=/hbase Unable to get data of znode /hbase/master
org.apache.zookeeper.KeeperException$SessionExpiredException: KeeperErrorCode = Session expired for /hbase/master
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.ZooKeeper.getData(ZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper.getData(RecoverableZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.getData(ZKUtil.java:)
at org.apache.hadoop.hbase.zookeeper.MasterAddressTracker.getMasterAddress(MasterAddressTracker.java:)
at org.apache.hadoop.hbase.master.ActiveMasterManager.stop(ActiveMasterManager.java:)
at org.apache.hadoop.hbase.master.HMaster.stop(HMaster.java:)
at org.apache.hadoop.hbase.master.HMaster.stopMaster(HMaster.java:)
at org.apache.hadoop.hbase.master.HMaster.abort(HMaster.java:)
at org.apache.hadoop.hbase.replication.ReplicationPeersZKImpl.getAllPeerIds(ReplicationPeersZKImpl.java:)
at org.apache.hadoop.hbase.master.cleaner.ReplicationZKNodeCleaner.getUnDeletedQueues(ReplicationZKNodeCleaner.java:)
at org.apache.hadoop.hbase.master.cleaner.ReplicationZKNodeCleanerChore.chore(ReplicationZKNodeCleanerChore.java:)
at org.apache.hadoop.hbase.ScheduledChore.run(ScheduledChore.java:)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$(ScheduledThreadPoolExecutor.java:)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:)
at org.apache.hadoop.hbase.JitterScheduledThreadPoolExecutorImpl$JitteredRunnableScheduledFuture.run(JitterScheduledThreadPoolExecutorImpl.java:)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:)
at java.lang.Thread.run(Thread.java:)
-- ::, WARN [main-EventThread] zookeeper.ZKUtil: master:-0x1023619d3c30002, quorum=172.16.10.91:,172.16.10.92:,172.16.10.93:, baseZNode=/hbase Unable to get data of znode /hbase/master
org.apache.zookeeper.KeeperException$SessionExpiredException: KeeperErrorCode = Session expired for /hbase/master
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.ZooKeeper.getData(ZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper.getData(RecoverableZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.getData(ZKUtil.java:)
at org.apache.hadoop.hbase.zookeeper.MasterAddressTracker.getMasterAddress(MasterAddressTracker.java:)
at org.apache.hadoop.hbase.master.ActiveMasterManager.stop(ActiveMasterManager.java:)
at org.apache.hadoop.hbase.master.HMaster.stop(HMaster.java:)
at org.apache.hadoop.hbase.master.HMaster.stopMaster(HMaster.java:)
at org.apache.hadoop.hbase.master.HMaster.abort(HMaster.java:)
at org.apache.hadoop.hbase.zookeeper.ZKWatcher.connectionEvent(ZKWatcher.java:)
at org.apache.hadoop.hbase.zookeeper.ZKWatcher.process(ZKWatcher.java:)
at org.apache.zookeeper.ClientCnxn$EventThread.processEvent(ClientCnxn.java:)
at org.apache.zookeeper.ClientCnxn$EventThread.run(ClientCnxn.java:)
-- ::, ERROR [main-EventThread] zookeeper.ZKWatcher: master:-0x1023619d3c30002, quorum=172.16.10.91:,172.16.10.92:,172.16.10.93:, baseZNode=/hbase Received unexpected KeeperException, re-throwing exception
org.apache.zookeeper.KeeperException$SessionExpiredException: KeeperErrorCode = Session expired for /hbase/master
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.ZooKeeper.getData(ZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper.getData(RecoverableZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.getData(ZKUtil.java:)
at org.apache.hadoop.hbase.zookeeper.MasterAddressTracker.getMasterAddress(MasterAddressTracker.java:)
at org.apache.hadoop.hbase.master.ActiveMasterManager.stop(ActiveMasterManager.java:)
at org.apache.hadoop.hbase.master.HMaster.stop(HMaster.java:)
at org.apache.hadoop.hbase.master.HMaster.stopMaster(HMaster.java:)
at org.apache.hadoop.hbase.master.HMaster.abort(HMaster.java:)
at org.apache.hadoop.hbase.zookeeper.ZKWatcher.connectionEvent(ZKWatcher.java:)
at org.apache.hadoop.hbase.zookeeper.ZKWatcher.process(ZKWatcher.java:)
at org.apache.zookeeper.ClientCnxn$EventThread.processEvent(ClientCnxn.java:)
at org.apache.zookeeper.ClientCnxn$EventThread.run(ClientCnxn.java:)
-- ::, ERROR [master/hadoop1:.Chore.] zookeeper.ZKWatcher: master:-0x1023619d3c30002, quorum=172.16.10.91:,172.16.10.92:,172.16.10.93:, baseZNode=/hbase Received unexpected KeeperException, re-throwing exception
org.apache.zookeeper.KeeperException$SessionExpiredException: KeeperErrorCode = Session expired for /hbase/master
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.ZooKeeper.getData(ZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper.getData(RecoverableZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.getData(ZKUtil.java:)
at org.apache.hadoop.hbase.zookeeper.MasterAddressTracker.getMasterAddress(MasterAddressTracker.java:)
at org.apache.hadoop.hbase.master.ActiveMasterManager.stop(ActiveMasterManager.java:)
at org.apache.hadoop.hbase.master.HMaster.stop(HMaster.java:)
at org.apache.hadoop.hbase.master.HMaster.stopMaster(HMaster.java:)
at org.apache.hadoop.hbase.master.HMaster.abort(HMaster.java:)
at org.apache.hadoop.hbase.replication.ReplicationPeersZKImpl.getAllPeerIds(ReplicationPeersZKImpl.java:)
at org.apache.hadoop.hbase.master.cleaner.ReplicationZKNodeCleaner.getUnDeletedQueues(ReplicationZKNodeCleaner.java:)
at org.apache.hadoop.hbase.master.cleaner.ReplicationZKNodeCleanerChore.chore(ReplicationZKNodeCleanerChore.java:)
at org.apache.hadoop.hbase.ScheduledChore.run(ScheduledChore.java:)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$(ScheduledThreadPoolExecutor.java:)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:)
at org.apache.hadoop.hbase.JitterScheduledThreadPoolExecutorImpl$JitteredRunnableScheduledFuture.run(JitterScheduledThreadPoolExecutorImpl.java:)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:)
at java.lang.Thread.run(Thread.java:)
-- ::, INFO [main-EventThread] zookeeper.ClientCnxn: EventThread shut down for session: 0x1023619d3c30002
-- ::, ERROR [master/hadoop1:.Chore.] hbase.ScheduledChore: Caught error
java.lang.NullPointerException
at java.util.HashSet.<init>(HashSet.java:)
at org.apache.hadoop.hbase.master.cleaner.ReplicationZKNodeCleaner.getUnDeletedQueues(ReplicationZKNodeCleaner.java:)
at org.apache.hadoop.hbase.master.cleaner.ReplicationZKNodeCleanerChore.chore(ReplicationZKNodeCleanerChore.java:)
at org.apache.hadoop.hbase.ScheduledChore.run(ScheduledChore.java:)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$(ScheduledThreadPoolExecutor.java:)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:)
at org.apache.hadoop.hbase.JitterScheduledThreadPoolExecutorImpl$JitteredRunnableScheduledFuture.run(JitterScheduledThreadPoolExecutorImpl.java:)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:)
at java.lang.Thread.run(Thread.java:)
-- ::, INFO [master/hadoop1:.Chore.] hbase.ScheduledChore: Chore: hadoop1,,-ClusterStatusChore was stopped
-- ::, INFO [master/hadoop1:.Chore.] hbase.ScheduledChore: Chore: hadoop1,,-BalancerChore was stopped
-- ::, INFO [master/hadoop1:.Chore.] master.ReplicationLogCleaner: Stopping replicationLogCleaner-0x1023619d3c30006, quorum=172.16.10.91:,172.16.10.92:,172.16.10.93:, baseZNode=/hbase
-- ::, INFO [master/hadoop1:.Chore.] hbase.ScheduledChore: Chore: LogsCleaner was stopped
-- ::, INFO [master/hadoop1:.Chore.] hbase.ScheduledChore: Chore: HFileCleaner was stopped
-- ::, INFO [master/hadoop1:.Chore.] hbase.ScheduledChore: Chore: hadoop1,,-RegionNormalizerChore was stopped
-- ::, INFO [master/hadoop1:.Chore.] hbase.ScheduledChore: Chore: CatalogJanitor-hadoop1: was stopped
-- ::, INFO [master/hadoop1:] regionserver.HRegionServer: Stopping infoServer
-- ::, INFO [master/hadoop1:.splitLogManager..Chore.] hbase.ScheduledChore: Chore: SplitLogManager Timeout Monitor was stopped
-- ::, WARN [RpcServer.default.FPBQ.Fifo.handler=,queue=,port=] ipc.RpcServer: (responseTooSlow): {"call":"RegionServerReport(org.apache.hadoop.hbase.shaded.protobuf.generated.RegionServerStatusProtos$RegionServerReportRequest)","starttimems":,"responsesize":,"method":"RegionServerReport","param":"server host_name: \"hadoop1\" port: 16020 start_code: 1573889993445 load { numberOfRequests: 50 }","processingtimems":,"client":"172.16.10.91:56479","queuetimems":,"class":"HMaster"}
-- ::, INFO [master/hadoop1:] handler.ContextHandler: Stopped o.e.j.w.WebAppContext@38d17d80{/,null,UNAVAILABLE}{file:/usr/local/hbase-2.0./hbase-webapps/master}
-- ::, INFO [master/hadoop1:] server.AbstractConnector: Stopped ServerConnector@661f1c57{HTTP/1.1,[http/1.1]}{0.0.0.0:}
-- ::, INFO [master/hadoop1:] handler.ContextHandler: Stopped o.e.j.s.ServletContextHandler@36c0d0bd{/static,file:///usr/local/hbase-2.0.0/hbase-webapps/static/,UNAVAILABLE}
-- ::, INFO [master/hadoop1:] handler.ContextHandler: Stopped o.e.j.s.ServletContextHandler@2042ccce{/logs,file:///usr/local/hbase-2.0.0/logs/,UNAVAILABLE}
-- ::, INFO [master/hadoop1:] regionserver.HRegionServer: stopping server hadoop1,,
-- ::, INFO [master/hadoop1:] zookeeper.ReadOnlyZKClient: Close zookeeper connection 0x0ad0061b to 172.16.10.91:,172.16.10.92:,172.16.10.93:
-- ::, INFO [master/hadoop1:] regionserver.HRegionServer: stopping server hadoop1,,; all regions closed.
-- ::, INFO [master/hadoop1:] hbase.ChoreService: Chore service for: master/hadoop1: had [[ScheduledChore: Name: hadoop1,,-MobCompactionChore Period: Unit: SECONDS], [ScheduledChore: Name: hadoop1,,-ExpiredMobFileCleanerChore Period: Unit: SECONDS]] on shutdown
-- ::, INFO [master/hadoop1:] master.MasterMobCompactionThread: Waiting for Mob Compaction Thread to finish...
-- ::, INFO [master/hadoop1:] master.MasterMobCompactionThread: Waiting for Region Server Mob Compaction Thread to finish...
-- ::, WARN [master/hadoop1:] zookeeper.ZKUtil: master:-0x1023619d3c30002, quorum=172.16.10.91:,172.16.10.92:,172.16.10.93:, baseZNode=/hbase Unable to get data of znode /hbase/master
org.apache.zookeeper.KeeperException$SessionExpiredException: KeeperErrorCode = Session expired for /hbase/master
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.ZooKeeper.getData(ZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper.getData(RecoverableZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.getData(ZKUtil.java:)
at org.apache.hadoop.hbase.zookeeper.MasterAddressTracker.getMasterAddress(MasterAddressTracker.java:)
at org.apache.hadoop.hbase.master.ActiveMasterManager.stop(ActiveMasterManager.java:)
at org.apache.hadoop.hbase.master.HMaster.stopServiceThreads(HMaster.java:)
at org.apache.hadoop.hbase.regionserver.HRegionServer.run(HRegionServer.java:)
at org.apache.hadoop.hbase.master.HMaster.run(HMaster.java:)
at java.lang.Thread.run(Thread.java:)
-- ::, ERROR [master/hadoop1:] zookeeper.ZKWatcher: master:-0x1023619d3c30002, quorum=172.16.10.91:,172.16.10.92:,172.16.10.93:, baseZNode=/hbase Received unexpected KeeperException, re-throwing exception
org.apache.zookeeper.KeeperException$SessionExpiredException: KeeperErrorCode = Session expired for /hbase/master
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.ZooKeeper.getData(ZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper.getData(RecoverableZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.getData(ZKUtil.java:)
at org.apache.hadoop.hbase.zookeeper.MasterAddressTracker.getMasterAddress(MasterAddressTracker.java:)
at org.apache.hadoop.hbase.master.ActiveMasterManager.stop(ActiveMasterManager.java:)
at org.apache.hadoop.hbase.master.HMaster.stopServiceThreads(HMaster.java:)
at org.apache.hadoop.hbase.regionserver.HRegionServer.run(HRegionServer.java:)
at org.apache.hadoop.hbase.master.HMaster.run(HMaster.java:)
at java.lang.Thread.run(Thread.java:)
-- ::, INFO [master/hadoop1:] assignment.AssignmentManager: Stopping assignment manager
-- ::, INFO [master/hadoop1:] procedure2.RemoteProcedureDispatcher: Stopping procedure remote dispatcher
-- ::, INFO [master/hadoop1:] procedure2.ProcedureExecutor: Stopping
-- ::, INFO [master/hadoop1:] wal.WALProcedureStore: Stopping the WAL Procedure Store, isAbort=false
-- ::, INFO [master/hadoop1:] hbase.ChoreService: Chore service for: master/hadoop1:.splitLogManager. had [] on shutdown
-- ::, INFO [master/hadoop1:] flush.MasterFlushTableProcedureManager: stop: server shutting down.
-- ::, INFO [master/hadoop1:] ipc.NettyRpcServer: Stopping server on /172.16.10.91:
-- ::, WARN [master/hadoop1:] regionserver.HRegionServer: Failed deleting my ephemeral node
org.apache.zookeeper.KeeperException$SessionExpiredException: KeeperErrorCode = Session expired for /hbase/rs/hadoop1,,
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.ZooKeeper.delete(ZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper.delete(RecoverableZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.deleteNode(ZKUtil.java:)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.deleteNode(ZKUtil.java:)
at org.apache.hadoop.hbase.regionserver.HRegionServer.deleteMyEphemeralNode(HRegionServer.java:)
at org.apache.hadoop.hbase.regionserver.HRegionServer.run(HRegionServer.java:)
at org.apache.hadoop.hbase.master.HMaster.run(HMaster.java:)
at java.lang.Thread.run(Thread.java:)
-- ::, INFO [master/hadoop1:] regionserver.HRegionServer: Exiting; stopping=hadoop1,,; zookeeper connection closed.
然后去看相应时间GC的日志:
发现在15:50分左右,出现了一次GC,耗时:63.2450700 secs。
从而可以断定,是因为GC期间服务全被堵塞了,无法响应外部请求;由于超出了zk允许的最大中断时间(40s),zk服务自动剔除该hbase节点。hbase gc后试图继续与zk连续,但得不到响应,故停止服务
--16T15::54.792+: 546.099: Total time for which application threads were stopped: 0.0001972 seconds, Stopping threads took: 0.0000609 seconds
--16T15::25.011+: 576.319: Total time for which application threads were stopped: 0.0006850 seconds, Stopping threads took: 0.0002741 seconds
--16T15::25.012+: 576.319: Total time for which application threads were stopped: 0.0003173 seconds, Stopping threads took: 0.0000438 seconds
--16T15::27.012+: 578.320: Total time for which application threads were stopped: 0.0004070 seconds, Stopping threads took: 0.0000815 seconds
--16T15::28.013+: 579.320: Total time for which application threads were stopped: 0.0004502 seconds, Stopping threads took: 0.0000730 seconds
--16T15::29.013+: 580.321: Total time for which application threads were stopped: 0.0004346 seconds, Stopping threads took: 0.0000679 seconds
--16T15::37.076+: 588.383: Total time for which application threads were stopped: 0.0053718 seconds, Stopping threads took: 0.0049407 seconds
--16T15::47.077+: 598.385: Total time for which application threads were stopped: 0.0006014 seconds, Stopping threads took: 0.0001549 seconds
--16T15::57.275+: 608.582: Total time for which application threads were stopped: 1.5978862 seconds, Stopping threads took: 0.0081536 seconds
--16T15::57.357+: 608.664: Total time for which application threads were stopped: 0.0810708 seconds, Stopping threads took: 0.0395464 seconds
--16T15::57.397+: 608.704: Total time for which application threads were stopped: 0.0400561 seconds, Stopping threads took: 0.0202738 seconds
--16T15::57.676+: 608.983: Total time for which application threads were stopped: 0.2749559 seconds, Stopping threads took: 0.0463266 seconds
--16T15::57.686+: 608.994: Total time for which application threads were stopped: 0.0102411 seconds, Stopping threads took: 0.0097304 seconds
2019-11-16T15:50:04.321+0800: 615.629: [GC (Allocation Failure) 2019-11-16T15:50:04.707+0800: 616.015: [ParNew
Desired survivor size 67108864 bytes, new threshold 15 (max 15)
- age 1: 9371352 bytes, 9371352 total
- age 2: 4838936 bytes, 14210288 total
- age 3: 6062112 bytes, 20272400 total
: 294250K->26226K(393216K), 62.8591600 secs] 294250K->26226K(3014656K), 63.2450700 secs] [Times: user=0.28 sys=0.41, real=63.23 secs]
--16T15::07.567+: 678.874: Total time for which application threads were stopped: 63.3780698 seconds, Stopping threads took: 0.0001344 seconds
--16T15::07.697+: 679.004: Total time for which application threads were stopped: 0.0767111 seconds, Stopping threads took: 0.0474820 seconds
--16T15::07.875+: 679.182: Total time for which application threads were stopped: 0.1745242 seconds, Stopping threads took: 0.1312083 seconds
--16T15::07.905+: 679.213: Total time for which application threads were stopped: 0.0298393 seconds, Stopping threads took: 0.0233279 seconds
--16T15::08.172+: 679.480: Total time for which application threads were stopped: 0.1184843 seconds, Stopping threads took: 0.0465035 seconds
--16T15::08.452+: 679.760: Total time for which application threads were stopped: 0.1325020 seconds, Stopping threads took: 0.1321667 seconds
--16T15::08.884+: 680.191: Total time for which application threads were stopped: 0.0991417 seconds, Stopping threads took: 0.0448200 seconds
--16T15::09.028+: 680.336: Total time for which application threads were stopped: 0.0449934 seconds, Stopping threads took: 0.0447280 seconds
--16T15::10.410+: 681.718: Total time for which application threads were stopped: 1.0410454 seconds, Stopping threads took: 1.0110414 seconds
--16T15::11.644+: 682.951: Total time for which application threads were stopped: 0.1198907 seconds, Stopping threads took: 0.1193440 seconds
--16T15::11.751+: 683.058: Total time for which application threads were stopped: 0.0030797 seconds, Stopping threads took: 0.0026453 seconds
--16T15::11.769+: 683.077: Total time for which application threads were stopped: 0.0057162 seconds, Stopping threads took: 0.0043807 seconds
--16T15::11.779+: 683.087: Total time for which application threads were stopped: 0.0097116 seconds, Stopping threads took: 0.0094623 seconds
--16T15::11.862+: 683.169: Total time for which application threads were stopped: 0.0410152 seconds, Stopping threads took: 0.0281023 seconds
--16T15::12.074+: 683.381: Total time for which application threads were stopped: 0.2106658 seconds, Stopping threads took: 0.2104016 seconds
--16T15::12.422+: 683.729: Total time for which application threads were stopped: 0.0109280 seconds, Stopping threads took: 0.0104571 seconds
--16T15::12.431+: 683.738: Total time for which application threads were stopped: 0.0089406 seconds, Stopping threads took: 0.0086042 seconds
--16T15::13.305+: 684.613: Total time for which application threads were stopped: 0.0034802 seconds, Stopping threads took: 0.0030049 seconds
注:gc日志输出的路径和文件名,要在bin/hbase-env.sh文件的HBASE_OPTS中设置
问题2:查看RegionServer节点的日志,出现一些GC和异常信息:
-- ::, INFO [regionserver/hadoop1:.Chore.] hbase.ScheduledChore: Chore: MemstoreFlusherChore missed its start time
-- ::, INFO [regionserver/hadoop1:.Chore.] hbase.ScheduledChore: Chore: CompactionChecker missed its start time
2019-11-16 17:36:35,527 WARN [JvmPauseMonitor] util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 40315ms
GC pool 'ParNew' had collection(s): count=1 time=39859ms
-- ::, WARN [RpcServer.default.FPBQ.Fifo.handler=,queue=,port=] ipc.RpcServer: (responseTooSlow): {"call":"Multi(org.apache.hadoop.hbase.shaded.protobuf.generated.ClientProtos$MultiRequest)","starttimems":,"responsesize":,"method":"Multi","param":"region= TERMINAL_DETAIL_DATA,2,1573617342390.91c77640ad1b2f43b5fe347f41d835b8., for 1 actions and 1st row key=29223370463942606807463901012100","processingtimems":,"client":"172.16.99.2:2210","queuetimems":,"class":"HRegionServer"}
-- ::, WARN [RpcServer.default.FPBQ.Fifo.handler=,queue=,port=] ipc.RpcServer: (responseTooSlow): {"call":"Multi(org.apache.hadoop.hbase.shaded.protobuf.generated.ClientProtos$MultiRequest)","starttimems":,"responsesize":,"method":"Multi","param":"region= TERMINAL_DETAIL_DATA,2,1573617342390.91c77640ad1b2f43b5fe347f41d835b8., for 1 actions and 1st row key=29223370463942598807001514010400","processingtimems":,"client":"172.16.99.2:2210","queuetimems":,"class":"HRegionServer"}
-- ::, WARN [RpcServer.default.FPBQ.Fifo.handler=,queue=,port=] ipc.RpcServer: (responseTooSlow): {"call":"Multi(org.apache.hadoop.hbase.shaded.protobuf.generated.ClientProtos$MultiRequest)","starttimems":,"responsesize":,"method":"Multi","param":"region= TERMINAL_DETAIL_DATA,5,1573617342390.18ad8bf75167740d2ba58df4fe71f189., for 1 actions and 1st row key=59223370463950389807568502012100","processingtimems":,"client":"172.16.99.2:2210","queuetimems":,"class":"HRegionServer"}
-- ::, INFO [AsyncFSWAL-] wal.AbstractFSWAL: Slow sync cost: ms, current pipeline: [DatanodeInfoWithStorage[172.16.10.91:,DS-9402e3dd-982e-4f18-be39-3a7dfc0d2672,DISK], DatanodeInfoWithStorage[172.16.10.93:,DS-b843ad5a-97c2-42f5-ac4f-619acca6219c,DISK]]
-- ::, INFO [AsyncFSWAL-] wal.AbstractFSWAL: Slow sync cost: ms, current pipeline: [DatanodeInfoWithStorage[172.16.10.91:,DS-9402e3dd-982e-4f18-be39-3a7dfc0d2672,DISK], DatanodeInfoWithStorage[172.16.10.93:,DS-b843ad5a-97c2-42f5-ac4f-619acca6219c,DISK]]
-- ::, INFO [main-SendThread(172.16.10.93:)] zookeeper.ClientCnxn: Opening socket connection to server 172.16.10.93/172.16.10.93:. Will not attempt to authenticate using SASL (unknown error)
-- ::, WARN [main-SendThread(172.16.10.93:)] zookeeper.ClientCnxn: Session 0x2042fa555aa0251 for server null, unexpected error, closing socket connection and attempting reconnect
java.net.ConnectException: Connection refused
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:)
at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:)
-- ::, INFO [main-SendThread(172.16.10.92:)] zookeeper.ClientCnxn: Opening socket connection to server 172.16.10.92/172.16.10.92:. Will not attempt to authenticate using SASL (unknown error)
-- ::, INFO [main-SendThread(172.16.10.92:)] zookeeper.ClientCnxn: Socket connection established to 172.16.10.92/172.16.10.92:, initiating session
-- ::, WARN [main-SendThread(172.16.10.92:)] zookeeper.ClientCnxn: Unable to reconnect to ZooKeeper service, session 0x2042fa555aa0251 has expired
-- ::, INFO [main-SendThread(172.16.10.92:)] zookeeper.ClientCnxn: Unable to reconnect to ZooKeeper service, session 0x2042fa555aa0251 has expired, closing socket connection
-- ::, WARN [regionserver/hadoop1:] zookeeper.ZKUtil: regionserver:-0x2042fa555aa0251, quorum=172.16.10.91:,172.16.10.92:,172.16.10.93:, baseZNode=/hbase Unable to get data of znode /hbase/master
org.apache.zookeeper.KeeperException$SessionExpiredException: KeeperErrorCode = Session expired for /hbase/master
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.ZooKeeper.getData(ZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper.getData(RecoverableZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.getDataInternal(ZKUtil.java:)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.getDataAndWatch(ZKUtil.java:)
at org.apache.hadoop.hbase.zookeeper.ZKNodeTracker.getData(ZKNodeTracker.java:)
at org.apache.hadoop.hbase.zookeeper.MasterAddressTracker.getMasterAddress(MasterAddressTracker.java:)
at org.apache.hadoop.hbase.regionserver.HRegionServer.createRegionServerStatusStub(HRegionServer.java:)
at org.apache.hadoop.hbase.regionserver.HRegionServer.tryRegionServerReport(HRegionServer.java:)
at org.apache.hadoop.hbase.regionserver.HRegionServer.run(HRegionServer.java:)
at java.lang.Thread.run(Thread.java:)
-- ::, ERROR [regionserver/hadoop1:] zookeeper.ZKWatcher: regionserver:-0x2042fa555aa0251, quorum=172.16.10.91:,172.16.10.92:,172.16.10.93:, baseZNode=/hbase Received unexpected KeeperException, re-throwing exception
org.apache.zookeeper.KeeperException$SessionExpiredException: KeeperErrorCode = Session expired for /hbase/master
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.KeeperException.create(KeeperException.java:)
at org.apache.zookeeper.ZooKeeper.getData(ZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper.getData(RecoverableZooKeeper.java:)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.getDataInternal(ZKUtil.java:)
at org.apache.hadoop.hbase.zookeeper.ZKUtil.getDataAndWatch(ZKUtil.java:)
at org.apache.hadoop.hbase.zookeeper.ZKNodeTracker.getData(ZKNodeTracker.java:)
at org.apache.hadoop.hbase.zookeeper.MasterAddressTracker.getMasterAddress(MasterAddressTracker.java:)
at org.apache.hadoop.hbase.regionserver.HRegionServer.createRegionServerStatusStub(HRegionServer.java:)
at org.apache.hadoop.hbase.regionserver.HRegionServer.tryRegionServerReport(HRegionServer.java:)
at org.apache.hadoop.hbase.regionserver.HRegionServer.run(HRegionServer.java:)
at java.lang.Thread.run(Thread.java:)
-- ::, INFO [regionserver/hadoop1:.Chore.] regionserver.HRegionServer: MemstoreFlusherChore requesting flush of TERMINAL_DETAIL_DATA,,.91c77640ad1b2f43b5fe347f41d835b8. because F1 has an old edit so flush to free WALs after random delay 264353ms
-- ::, INFO [regionserver/hadoop1:.Chore.] regionserver.HRegionServer: MemstoreFlusherChore requesting flush of TERMINAL_DETAIL_DATA,,.622d87ccf68b5944f0e09db363f9cc5e. because F1 has an old edit so flush to free WALs after random delay 7288ms
-- ::, INFO [regionserver/hadoop1:.Chore.] regionserver.HRegionServer: MemstoreFlusherChore requesting flush of TERMINAL_DETAIL_DATA,,.fbb4d1d0d473e3db06c71a54404ca479. because F1 has an old edit so flush to free WALs after random delay 63104ms
-- ::, INFO [regionserver/hadoop1:.Chore.] regionserver.HRegionServer: MemstoreFlusherChore requesting flush of TERMINAL_DETAIL_DATA,,.18ad8bf75167740d2ba58df4fe71f189. because F1 has an old edit so flush to free WALs after random delay 220784ms
-- ::, INFO [AsyncFSWAL-] wal.AbstractFSWAL: Slow sync cost: ms, current pipeline: [DatanodeInfoWithStorage[172.16.10.91:,DS-9402e3dd-982e-4f18-be39-3a7dfc0d2672,DISK], DatanodeInfoWithStorage[172.16.10.93:,DS-b843ad5a-97c2-42f5-ac4f-619acca6219c,DISK]]
-- ::, INFO [JvmPauseMonitor] util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 1554ms
No GCs detected
解决方案
1、把hbase与zk的timeout时间加长为5分钟,但这并不能很好的解决问题
进入hbase安装主目录,vi conf/hbase-site.xml
<property>
<name>zookeeper.session.timeout</name>
<value></value>
<!--默认: 180000 :zookeeper 会话超时时间,单位是毫秒 -->
</property>
注:这个时间还依赖于zookeeper自身的超时时间,如果太短也需要设置一下,在zookeeper的配置文件中配置:minSessionTimeout,maxSessionTimeout。
2、避免gc的影响,加大hbase的堆内存
进入hbase安装主目录,vi bin/hbase-env.sh
调整HBASE_REGIONSERVER_OPTS值:
export HBASE_OPTS="$HBASE_OPTS -Xmx8g -Xms8g -Xmn512m -Xss256k -XX:MaxPermSize=256m -XX:SurvivorRatio=2 -XX:MaxTenuringThreshold=15 -XX:CMSInitiatingOccupancyFraction=65 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:+UseCMSInitiatingOccupancyOnly -XX:-DisableExplicitGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintTenuringDistribution -Xloggc:$HBASE_HOME/logs/gc-$(hostname)-hbase.log"
3、重启HBase集群
HBase管理与监控——HMaster或HRegionServer自动停止挂掉的更多相关文章
- HBase管理与监控——WebUI
一.Region Server栏信息 Requests Per Second,每秒读或写请求次数,可以用来监控HBase请求是否均匀.如果不均匀需排查是否为建表的region划分不合理造成. Num. ...
- HBase管理与监控——内存调优
HMaster 没有处理过重的负载,并且实际的数据服务不经过 HMaster,它的主要任务有2个:一.管理Hbase Table的 DDL操作, 二.region的分配工作,任务不是很艰巨. 但是如果 ...
- HBase管理与监控——强制删除表
在用phoenix创建Hbase表时,有时会提示创建失败,发现Hbase中又已创建成功, 但这些表在进行enable.disable.drop都无效,也无法删除: hbase(main)::> ...
- HBase管理与监控——HBase region is not online
发现有些regison程序操作失败,其他region 都是正常的,重启regionserver 后依然报同样的错误. 首先进入hbase的bin目录,执行下面命令检查表是否有存储一致性问题: hbas ...
- HBase管理与监控——统计表行数
背景 HBase统计 RowCount 的方法有好几种,并且执行效率差别巨大,以下3种方法效率依次提高. 一.hbase-shell的count命令 这是最简单直接的操作,但是执行效率非常低,适用 ...
- HBase管理与监控——Dead Region Servers
[问题描述] 在持续批量写入HBase的情况下,出现了Dead Region Servers的情况.集群会把dead掉节点上的region自动分发到另外2个节点上,集群还能继续运行,只是少了1个节点. ...
- HBase管理与监控——彻底删除HBase数据
1.hadoop的bin目录下,执行命令以下命令清除Hbase数据 hadoop fs -rm -r /hbase 2.连接ZK,执行以下命令清除Hbase数据 rmr /hbase 3.重启ZK.重 ...
- 【HBase】知识小结+HMaster选举、故障恢复、读写流程
1:什么是HBase HBase是一个高可靠性,高性能,面向列,可伸缩的分布式数据库,提供海量数据存储功能,一个结构化的分布式存储系统,不同于一般的关系型数据库,它适合半结构化和非结构化数据存储. 2 ...
- HBase 集群监控系统构建
HBase 集群监控系统构建 标签(空格分隔): Hbase 一, 集群为什么需要监控系统 总的来说是为了保证系统的稳定性,可靠性,可运维性.具体来说我认为有以下几点: 掌控集群的核心性能指标,了解集 ...
随机推荐
- 算法之暴力破解和kmp算法 判断A字符串是否包含B字符串
我们都知道java中有封装好的方法,用来比较A字符串是否包含B字符串 如下代码,contains,用法是 str1.contains(str2), 这个布尔型返回,存在返回true,不存在返回fals ...
- XPath 爬虫解析库
XPath XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言.最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的 ...
- 解决 分布式事务中HRESULT:0x8004D025 错误
最近在开发分布式事务的过程中,碰到 该伙伴事务管理器已经禁止了它对远程/网络事务的支持. (异常来自 HRESULT:0x8004D025)的错误. 后来检查到,原来是数据库服务器的MSDTC 没有设 ...
- Java常用数学类和BigDecimal
笔记: Math类 * java.lang.Math提供了一系列静态方法用于科学计算:其方法的参数和返回值类型一般为double型. * abs 绝对值 * acos,asin,atan,cos,si ...
- 获取mysql一组数据中的第N大的值
create table tb(name varchar(10),val int,memo varchar(20)) insert into tb values('a', 2, 'a2') inser ...
- HDU 3824/ BZOJ 3963 [WF2011]MachineWorks (斜率优化DP+CDQ分治维护凸包)
题面 BZOJ传送门(中文题面但是权限题) HDU传送门(英文题面) 分析 定义f[i]f[i]f[i]表示在iii时间(离散化之后)卖出手上的机器的最大收益.转移方程式比较好写f[i]=max{f[ ...
- Nginx:Nginx概要
简介 nginx是俄罗斯开源的HTTP和代理服务,也可以作邮件服务器. 核心功能: 1.正向代理:客户机的请求先到达nginx,再由nginx代理访问互联网资源 2.反向代理:客户机请求互联网,到达n ...
- E:only-child
E:only-child 语法: E:only-child { sRules } 说明: 匹配父元素仅有的一个子元素E.大理石机械构件维修 要使该属性生效,E元素必须是某个元素的子元素,E的父元素最高 ...
- border-width
border-width 语法: border-width:<line-width>{1,4} <line-width> = <length> | thin | m ...
- mysql 常见ALTER TABLE操作
删除列 alter table table-name drop col-name; 增加列(单列) alter table table-name add col-name col-type comme ...