poj2002 hash+邻接表优化Squares
| Time Limit: 3500MS | Memory Limit: 65536K | |
| Total Submissions: 17487 | Accepted: 6643 |
Description
So we all know what a square looks like, but can we find all
possible squares that can be formed from a set of stars in a night sky?
To make the problem easier, we will assume that the night sky is a
2-dimensional plane, and each star is specified by its x and y
coordinates.
Input
input consists of a number of test cases. Each test case starts with the
integer n (1 <= n <= 1000) indicating the number of points to
follow. Each of the next n lines specify the x and y coordinates (two
integers) of each point. You may assume that the points are distinct and
the magnitudes of the coordinates are less than 20000. The input is
terminated when n = 0.
Output
Sample Input
4
1 0
0 1
1 1
0 0
9
0 0
1 0
2 0
0 2
1 2
2 2
0 1
1 1
2 1
4
-2 5
3 7
0 0
5 2
0
Sample Output
1
6
1
Source
大致题意:
有一堆平面散点集,任取四个点,求能组成正方形的不同组合方式有多少。
相同的四个点,不同顺序构成的正方形视为同一正方形。
解题思路:
做本题数学功底要很强= =
直接四个点四个点地枚举肯定超时的,不可取。
普遍的做法是:先枚举两个点,通过数学公式得到另外2个点,使得这四个点能够成正方形。然后检查散点集中是否存在计算出来的那两个点,若存在,说明有一个正方形。
但这种做法会使同一个正方形按照不同的顺序被枚举了四次,因此最后的结果要除以4.
已知: (x1,y1) (x2,y2)
则: x3=x1+(y1-y2) y3= y1-(x1-x2)
x4=x2+(y1-y2) y4= y2-(x1-x2)
或
x3=x1-(y1-y2) y3= y1+(x1-x2)
x4=x2-(y1-y2) y4= y2+(x1-x2)
据说是利用全等三角形可以求得上面的公式
有兴趣的同学可以证明下。。。
再来就是利用hash[]标记散点集了
我个人推荐key值使用 平方求余法
即标记点x y时,key = (x^2+y^2)%prime
此时key值的范围为[0, prime-1]
由于我个人的标记需求,我把公式更改为key = (x^2+y^2)%prime+1
使得key取值范围为[1, prime],则hash[]大小为 hash[prime]
其中prime为 小于 最大区域长度(就是散点个数)n的k倍的最大素数,
即小于k*n 的最大素数 (k∈N*)
为了尽量达到key与地址的一一映射,k值至少为1,
当为k==1时,空间利用率最高,但地址冲突也相对较多,由于经常要为解决冲突开放寻址,使得寻找key值耗时O(1)的情况较少
当n太大时,空间利用率很低,但由于key分布很离散,地址冲突也相对较少,使得寻找键值耗时基本为O(1)的情况
提供一组不同k值的测试数据
K==1, prime=997 1704ms
K==2, prime=1999 1438ms
K==8, prime=7993 1110ms
K==10, prime=9973 1063ms
K==30, prime=29989 1000ms
K==50, prime=49999 1016ms
K==100, prime=99991 1000ms

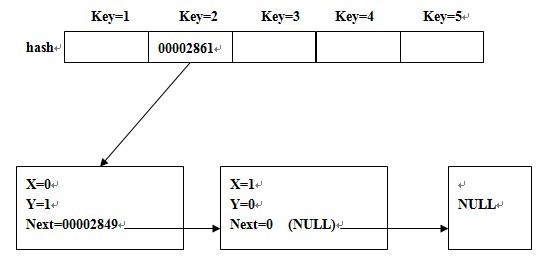
最后解决的地址冲突的方法,这是hash的难点。我使用了 链地址法
typedef class HashTable
{
public:
int x,y; //标记key值对应的x,y
HashTable* next; //当出现地址冲突时,开放寻址
HashTable() //Initial
{
next=0;
}
}Hashtable;
Hashtable* hash[prime]; //注意hash[]是指针数组,存放地址
//hash[]初始化为NULL (C++初始化为0)
先解释所谓的“冲突”
本题对于一组(x,y),通过一个函数hash(x,y),其实就是上面提到的key的计算公式
key = (x^2+y^2)%prime+1
于是我们得到了一个关于x,y的key值,但是我们不能保证key与每一组的(x,y)都一一对应,即可能存在 hash(x1,y1) = hash(x2,y2) = key
处理方法:
(1) 当读入(x1, y1)时,若hash[key]为NULL,我们直接申请一个临时结点Hashtable* temp,记录x1,y1的信息,然后把结点temp的地址存放到hash[key]中
此后我们就可以利用key访问temp的地址,继而得到x1,y1的信息
(2) 当读入(x2, y2)时,由于hash(x1,y1) = hash(x2,y2) = key,即(x2, y2)的信息同样要存入hash[key],但hash[key]已存有一个地址,怎么办?
注意到hash[key]所存放的temp中还有一个成员next,且next==0,由此,我们可以申请一个新结点存放x2,y2的信息,用next指向这个结点
此后我们利用key访问temp的地址时,先检查temp->x和temp->y是否为我们所需求的信息,若不是,检查next是否非空,若next非空,则检查下一结点,直至 next==0
当检查完所有next后仍然找不到所要的信息,说明信息原本就不存在
就是说hash[key]只保存第一个值为key的结点的地址,以后若出现相同key值的结点,则用前一个结点的next保存新结点的地址,其实就是一个链表
简单的图示为:
#include<stdio.h>
#include<string.h>
#include<iostream>
#include<algorithm>
using namespace std;
const int maxn=;
const int mod=;
int ptx[maxn],pty[maxn];
int cur,ans;
int first[maxn];
struct node{
int x,y;
int next;
}que[]; void insert(int x,int y){
int h=(x*x+y*y)%mod;
que[cur].x=x;
que[cur].y=y;
que[cur].next=first[h];
first[h]=cur;
cur++;
} bool find(int tx,int ty){
int h=(tx*tx+ty*ty)%mod;
int next=first[h];
while(next!=-){
if(que[next].x==tx&&que[next].y==ty)
return true;
next=que[next].next;
}
return false; } int main(){
int n;
while(scanf("%d",&n)!=EOF){
if(n==)
break;
cur=,ans=;
memset(ptx,,sizeof(ptx));
memset(pty,,sizeof(pty));
memset(first, -,sizeof(first));
for(int i=;i<n;i++){
scanf("%d%d",&ptx[i],&pty[i]);
insert(ptx[i],pty[i]);
}
for (int i = ; i < n; ++i){
for (int j = i + ; j < n; ++j){
int x1 = ptx[i] - (pty[i] - pty[j]);
int y1 = pty[i] + (ptx[i] - ptx[j]);
int x2 = ptx[j] - (pty[i] - pty[j]);
int y2 = pty[j] + (ptx[i] - ptx[j]);
if (find(x1, y1) && find(x2, y2))
++ans;
}
}
for (int i = ; i < n; ++i){
for (int j = i + ; j < n; ++j){
int x1 = ptx[i] + (pty[i] - pty[j]);
int y1 = pty[i] - (ptx[i] - ptx[j]);
int x2 = ptx[j] + (pty[i] - pty[j]);
int y2 = pty[j] - (ptx[i] - ptx[j]);
if (find(x1, y1) && find(x2, y2))
++ans;
}
}
ans=ans/;
printf("%d\n",ans);
}
return ;
}
poj2002 hash+邻接表优化Squares的更多相关文章
- topo排序 + 用邻接表优化后的
输入数据: 4 61 21 32 33 42 44 2 4 61 21 32 33 42 41 2 topo排序为偏序: #include<stdio.h> #include<que ...
- nyoj--138--找球号(二)(hash+邻接表)
找球号(二) 时间限制:1000 ms | 内存限制:65535 KB 难度:5 描述 在某一国度里流行着一种游戏.游戏规则为:现有一堆球中,每个球上都有一个整数编号i(0<=i<=1 ...
- POJ 1511 Invitation Cards(Dijkstra(优先队列)+SPFA(邻接表优化))
题目链接:http://poj.org/problem?id=1511 题目大意:给你n个点,m条边(1<=n<=m<=1e6),每条边长度不超过1e9.问你从起点到各个点以及从各个 ...
- POJ 1511 - Invitation Cards 邻接表 Dijkstra堆优化
昨天的题太水了,堆优化跑的不爽,今天换了一个题,1000000个点,1000000条边= = 试一试邻接表 写的过程中遇到了一些问题,由于习惯于把数据结构封装在 struct 里,结果 int [10 ...
- 【邻接表字符串Hash】【HDU1800】Flying to the Mars
题意: 给你N个数字,带前导0,问出现最多的数字个数 思路: 读入,清楚前导0,Hash. 用邻接表字符串Hash有一下几点注意 string,不要memset,否则地址也没了,涉及到stl的东西,少 ...
- 图论——最小生成树prim+邻接表+堆优化
今天学长对比了最小生成树最快速的求法不管是稠密图还是稀疏图,prim+邻接表+堆优化都能得到一个很不错的速度,所以参考学长的代码打出了下列代码,make_pair还不是很会,大体理解的意思是可以同时绑 ...
- Dijkstra堆优化+邻接表
Dijkstra算法是个不错的算法,但是在优化前时间复杂度太高了,为O(nm). 在经过堆优化后(具体实现用的c++ STL的priority_queue),时间复杂度为O((m+n) log n), ...
- bfs 邻接表(需要优化 可能会RE *【模板】)
//---基于邻接表的bfs #include <stdio.h> #include <string.h> #include <iostream> #include ...
- poj3013 邻接表+优先队列+Dij
把我坑到死的题 开始开题以为是全图连通是的最小值 ,以为是最小生成树,然后敲了发现不是,看了下别人的题意,然后懂了: 然后发现数据大,要用邻接表就去学了一下邻接表,然后又去学了下优先队列优化的dij: ...
随机推荐
- JS中的toString()和valueOf()方法
1.toString()方法:主要用于Array.Boolean.Date.Error.Function.Number等对象转化为字符串形式.日期类的toString()方法返回一个可读的日期和字符串 ...
- codeforces 599D Spongebob and Squares
很容易得到n × m的方块数是 然后就是个求和的问题了,枚举两者中小的那个n ≤ m. 然后就是转化成a*m + c = x了.a,m≥0,x ≥ c.最坏是n^3 ≤ x,至于中间会不会爆,测下1e ...
- PAT (Advanced Level) Practise - 1092. To Buy or Not to Buy (20)
http://www.patest.cn/contests/pat-a-practise/1092 Eva would like to make a string of beads with her ...
- java编程基础——二叉树的镜像
题目描述 操作给定的二叉树,将其变换为源二叉树的镜像. 题目代码 /** * @program: JavaCode * @description: 操作给定的二叉树,将其变换为源二叉树的镜像. * 二 ...
- 初尝微信小程序3-移动设备的分辨率与rpx
屏幕尺寸就是实际的物理尺寸. 分辨率(pt),是逻辑分辨率,pt的大小只和屏幕尺寸有关,简单可以理解为长度和视觉单位. 分辨率(px),是物理分辨率,单位是像素点,和屏幕尺寸没有关系. 微信开发者工具 ...
- 解决MySQL安装到最后一步未响应的三种方法
这种情况一般是你以前安装过MySQL数据库服务项被占用了.解决方法: 方法一:安装MySQL的时候在这一步时它默认的服务名是“MySQL” 只需要把这个名字改了就可以了.可以把默认的服务器的名称手动改 ...
- node基础
javascript window gulp ---- 前端工程构建工具 webpack ---- 前端工程构建工具 java Python php:后台 本地电脑,服务器 node 本地或服务端运行 ...
- bootstrap validation submit
表单提交校验功能 前端样式用bootstrap,依赖jquery,应用jquery自带的validation插件. 其实校验是一个小功能,做了还几天主要是因为碰到了两个问题,一个是对于提示信息样式添加 ...
- Mysql数据库的权限、索引基本操作
数据库的关闭方法: .优雅的关闭数据库的方法: mysqladmin -uroot -p123456 shutdown .脚本关闭: /etc/init.d/mysqld stop .使用kill信号 ...
- PHP switch问题
$a = 0; switch($a){ case $a > 7: echo 234; break; case $a > 2: echo 4556; break; default: echo ...