Python爬虫--初识爬虫
Python爬虫
一、爬虫的本质是什么?
模拟浏览器打开网页,获取网页中我们想要的那部分数据
浏览器打开网页的过程:
当你在浏览器中输入地址后,经过DNS服务器找到服务器主机,向服务器发送一个请求,服务器经过解析后发送给用户浏览器结果,包括html,js,css等文件内容,浏览器解析出来最后呈现给用户在浏览器上看到的结果
所以用户看到的浏览器的结果就是由HTML代码构成的,我们爬虫就是为了获取这些内容,通过分析和过滤html代码,从中获取我们想要资源(文本,图片,视频.....)
二、爬虫的基本流程
- 发起请求:通过HTTP库向目标站点发起请求,也就是发送一个Request,请求可以包含额外的header等信息,等待服务器响应
- 获取响应内容:如果服务器能正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,类型可能是HTML,Json字符串,二进制数据(图片或者视频)等类型
- 解析内容:得到的内容可能是HTML,可以用正则表达式,页面解析库进行解析,可能是Json,可以直接转换为Json对象解析,可能是二进制数据,可以做保存或者进一步的处理
- 保存数据:保存形式多样,可以存为文本,也可以保存到数据库,或者保存特定格式的文件
三、Request、Response的分析:
浏览器发送消息给网址所在的服务器,这个过程就叫做HTPP Request,服务器收到浏览器发送的消息后,能够根据浏览器发送消息的内容,做相应的处理,然后把消息回传给浏览器,这个过程就是HTTP Response
1、Request 分析:
1.1、请求方式:
- """
- 主要有:GET/POST两种类型常用,另外还有HEAD/PUT/DELETE/OPTIONS
- GET和POST的区别就是:请求的数据GET是在url中,POST则是存放在头部
- GET:向指定的资源发出“显示”请求。使用GET方法应该只用在读取数据,而不应当被用于产生“副作用”的操作中,例如在Web Application中。其中一个原因是GET可能会被网络蜘蛛等随意访问
- POST:向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求本文中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。
- HEAD:与GET方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的本文部分。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中“关于该资源的信息”(元信息或称元数据)。
- PUT:向指定资源位置上传其最新内容。
- OPTIONS:这个方法可使服务器传回该资源所支持的所有HTTP请求方法。用'*'来代替资源名称,向Web服务器发送OPTIONS请求,可以测试服务器功能是否正常运作。
- DELETE:请求服务器删除Request-URI所标识的资源。
- """
1.2、请求的url
- """
- URL,即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
- URL的格式由三个部分组成:
- 第一部分是协议(或称为服务方式)。
- 第二部分是存有该资源的主机IP地址(有时也包括端口号)。
- 第三部分是主机资源的具体地址,如目录和文件名等。
- 爬虫爬取数据时必须要有一个目标的URL才可以获取数据,因此,它是爬虫获取数据的基本依据。
- """
1.3、请求头
百度首页请求头:
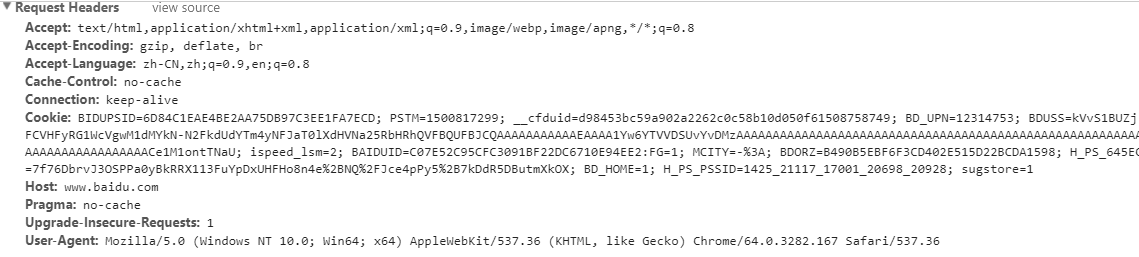
请求头字段释义:
- """
- Accept 设置接受的内容类型
- Accept-Charset 设置接受的字符编码
- Accept-Encoding 设置接受的编码格式
- Accept-Datetime 设置接受的版本时间
- Accept-Language 设置接受的语言
- Authorization 设置HTTP身份验证的凭证
- Cache-Control 设置请求响应链上所有的缓存机制必须遵守的指令
- Connection 设置当前连接和hop-by-hop协议请求字段列表的控制选项
- Content-Length 设置请求体的字节长度
- Content-MD5 设置基于MD5算法对请求体内容进行Base64二进制编码
- Content-Type 设置请求体的MIME类型(适用POST和PUT请求)
- Cookie 设置服务器使用Set-Cookie发送的http cookie
- Date 设置消息发送的日期和时间
- Expect 标识客户端需要的特殊浏览器行为
- Forwarded 披露客户端通过http代理连接web服务的源信息
- From 设置发送请求的用户的email地址
- Host 设置服务器域名和TCP端口号,如果使用的是服务请求标准端口号,端口号可以省略
- """
1.4、请求体
请求是携带的数据,如提交表单数据时候的表单数据(POST)
2、Response 分析:
2.1、响应状态:
有多种响应状态,如:200代表成功,301跳转,404找不到页面,502服务器错误
- 1xx消息——请求已被服务器接收,继续处理
- 2xx成功——请求已成功被服务器接收、理解、并接受
- 3xx重定向——需要后续操作才能完成这一请求
- 4xx请求错误——请求含有词法错误或者无法被执行
- 5xx服务器错误——服务器在处理某个正确请求时发生错误 常见代码: 200 OK 请求成功 400 Bad Request 客户端请求有语法错误,不能被服务器所理解 401 Unauthorized 请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用 403 Forbidden 服务器收到请求,但是拒绝提供服务 404 Not Found 请求资源不存在,eg:输入了错误的URL 500 Internal Server Error 服务器发生不可预期的错误 503 Server Unavailable 服务器当前不能处理客户端的请求,一段时间后可能恢复正常 301 目标永久性转移 302 目标暂时性转移
2.2、相应头:
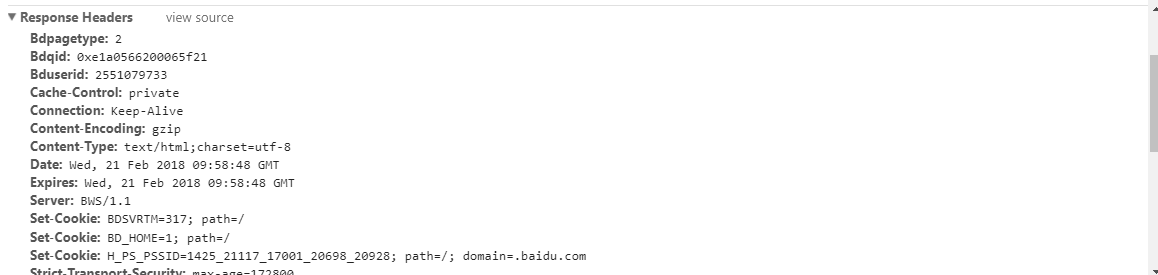
2.3、响应体:
包含请求资源的内容,如网页HTMl,图片,二进制数据等
四、爬取数据的解析与储存
1、解析方式:
- 直接处理
- Json解析
- 正则表达式处理
- BeautifulSoup解析处理
- PyQuery解析处理
- XPath解析处理
2、储存方式:
- 文本:纯文本,Json,Xml等
- 关系型数据库:如mysql,oracle,sql server等结构化数据库
- 非关系型数据库:MongoDB,Redis等key-value形式存储
Python爬虫--初识爬虫的更多相关文章
- 孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块
孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块 (完整学习过程屏幕记录视频地址在文末) 从今天起开始正式学习Python的爬虫. 今天已经初步了解了两个主要的模块: ...
- python爬虫从入门到放弃(一)之初识爬虫
整理这个文档的初衷是自己开始学习的时候没有找到好的教程和文本资料,自己整理一份这样的资料希望能对小伙伴有帮助 什么是爬虫? 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页 ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
- Python 开发轻量级爬虫08
Python 开发轻量级爬虫 (imooc总结08--爬虫实例--分析目标) 怎么开发一个爬虫?开发一个爬虫包含哪些步骤呢? 1.确定要抓取得目标,即抓取哪些网站的哪些网页的哪部分数据. 本实例确定抓 ...
- Python 开发轻量级爬虫07
Python 开发轻量级爬虫 (imooc总结07--网页解析器BeautifulSoup) BeautifulSoup下载和安装 使用pip install 安装:在命令行cmd之后输入,pip i ...
- Python 开发轻量级爬虫06
Python 开发轻量级爬虫 (imooc总结06--网页解析器) 介绍网页解析器 将互联网的网页获取到本地以后,我们需要对它们进行解析才能够提取出我们需要的内容. 也就是说网页解析器是从网页中提取有 ...
- Python 开发轻量级爬虫05
Python 开发轻量级爬虫 (imooc总结05--网页下载器) 介绍网页下载器 网页下载器是将互联网上url对应的网页下载到本地的工具.因为将网页下载到本地才能进行后续的分析处理,可以说网页下载器 ...
- Python 开发轻量级爬虫04
Python 开发轻量级爬虫 (imooc总结04--url管理器) 介绍抓取URL管理器 url管理器用来管理待抓取url集合和已抓取url集合. 这里有一个问题,遇到一个url,我们就抓取它的内容 ...
- Python 开发轻量级爬虫03
Python 开发轻量级爬虫 (imooc总结03--简单的爬虫架构) 现在来看一下一个简单的爬虫架构. 要实现一个简单的爬虫,有哪些方面需要考虑呢? 首先需要一个爬虫调度端,来启动爬虫.停止爬虫.监 ...
随机推荐
- 如何在CentOS 7上安装Nginx
第一步 - 添加Nginx存储库要添加CentOS 7 EPEL仓库,请打开终端并使用以下命令: sudo yum install epel-release第二步 - 安装Nginx现在Nginx存储 ...
- mysql控制台入门级--简单的创建表,字段。。。(用于网站测试)
一:在Mysql控制台创建数据表 [sql] use ceshi; create table student ( stuid int primary key auto_incremen ...
- Eclipse 最常用的 10 组快捷键,个个牛逼!
虽然栈长我现在不怎么用 Eclipse 了,但 Eclipse 的快捷键还是忘不了的,可以说 Eclipse 的快捷键很方便,恰到好处. 今天,我大概整理了 10 组 Eclipse 我觉得比较常用的 ...
- my -> mysql on duplicate key update使用总结
CREATE TABLE `t_duplicate` ( `a` int(11) NOT NULL, `b` int(255) DEFAULT NULL, `c` int(255) DEFAULT N ...
- php根据日期时间生成随机编码
订单.申请单之类的需要一个编码,通过下面方法可得 代码如下: $PNUM="PG" . date("YmdHis").rand(1000,9999);
- CentOS下iptables 配置详解
如果你的IPTABLES基础知识还不了解,建议先去看看. 开始配置 我们来配置一个filter表的防火墙. (1)查看本机关于IPTABLES的设置情况 [root@tp ~]# iptables - ...
- PowerDesigner16 安装包及破解文件
一.准备工作 PowerDesigner16 安装包:http://pan.baidu.com/s/11Qv9H 或http://cloud.suning.com/cloud-web/share/li ...
- iframe中,重新加载页面
比如在iframe中的页面,设置一个onclick事件的触发函数flush function flush(){ window.location.reload(); }
- jquery Table基础操作
鼠标移动行变色 $("#table1 tr").hover(function(){ $(this).children("td").ad ...
- Html5 播放Hls格式视频
二群号为766718184 ,博主提供Ffmpeg.GB28181视频教程 播放地址: http://www.iqiyi.com/u/1426749687 移动端Html5支持Hls格式视频播放,创 ...