Tarjan算法 详解+心得
Tarjan算法是由Robert Tarjan(罗伯特·塔扬,不知有几位大神读对过这个名字) 发明的求有向图中强连通分量的算法。
预备知识:有向图,强连通。
有向图:由有向边的构成的图。需要注意的是这是Tarjan算法的前提和条件。
强连通:如果两个顶点可以相互通达,则称两个顶点 强连通(strongly connected)。如果有向图G的每两个顶点都 强连通,称G是一个强连通图。非 强连通图有向图的极大强连通子图,称为强连通分量(strongly connected components)。
For example:
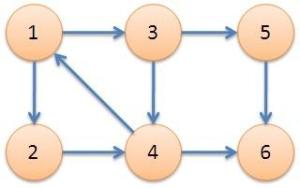
在这个有向图中1、2、3、4四个点可以互相到达,就称这四个点组成的子图为强连通分量。且这四个点两两强连通。
然后就可以开始学习神奇的Tarjan算法了!
Tarjan算法是用来求强连通分量的,它是一种基于DFS(深度优先搜索)的算法,每个强连通分量为搜索树中的一棵子树。并且运用了数据结构栈。
在介绍详细原理前,先引入两个非常重要的数组:dfn[ ] 与 low[ ]
dfn[ ]:就是一个时间戳(被搜到的次序),一旦某个点被DFS到后,这个时间戳就不再改变(且每个点只有唯一的时间戳)。所以常根据dfn的值来判断是否需要进行进一步的深搜。
low[ ]:该子树中,且仍在栈中的最小时间戳,像是确立了一个关系,low[ ]相等的点在同一强连通分量中。
注意初始化时 dfn[ ] = low[ ] = ++cnt.
算法思路:
首先这个图不一定是一个连通图,所以跑Tarjan时要枚举每个点,若dfn[ ] == 0,进行深搜。
然后对于搜到的点寻找与其有边相连的点,判断这些点是否已经被搜索过,若没有,则进行搜索。若该点已经入栈,说明形成了环,则更新low.
在不断深搜的过程中如果没有路可走了(出边遍历完了),那么就进行回溯,回溯时不断比较low[ ],去最小的low值。如果dfn[x]==low[x]则x可以看作是某一强连通分量子树的根,也说明找到了一个强连通分量,然后对栈进行弹出操作,直到x被弹出。
先来一波局部代码加深一下理解:
void tarjan(int now)
{
dfn[now]=low[now]=++cnt; //初始化
stack[++t]=now; //入栈操作
v[now]=; //v[]代表该点是否已入栈
for(int i=f[now];i!=-;i=e[i].next) //邻接表存图
if(!dfn[e[i].v]) //判断该点是否被搜索过
{
tarjan(e[i].v);
low[now]=min(low[now],low[e[i].v]); //回溯时更新low[ ],取最小值
}
else if(v[e[i].v])
low[now]=min(low[now],dfn[e[i].v]); //一旦遇到已入栈的点,就将该点作为连通量的根
//这里用dfn[e[i].v]更新的原因是:这个点可能
//已经在另一个强连通分量中了但暂时尚未出栈,所
//以now不一定能到达low[e[i].v]但一定能到达
//dfn[e[i].v].
if(dfn[now]==low[now])
{
int cur;
do
{
cur=stack[t--];
v[cur]=false; //不要忘记出栈
}while(now!=cur);
}
}
手动模拟一下过程:
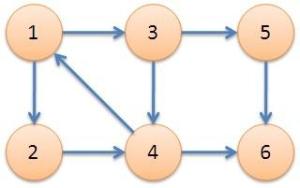
从1进入 dfn[1]= low[1]= ++cnt = 1
入栈 1
由1进入2 dfn[2]=low[2]= ++cnt = 2
入栈 1 2
之后由2进入4 dfn[4]=low[4]= ++cnt = 3
入栈 1 2 4
之后由4进入 6 dfn[6]=low[6]=++cnt = 4
入栈 1 2 4 6
6无出度,之后判断 dfn[6]==low[6]
说明6是个强连通分量的根节点:6及6以后的点出栈并输出。
回溯到4后发现4找到了一个已经在栈中的点1,更新 low [ 4 ] = min ( low [ 4 ] , dfn [ 1 ] )
于是 low [ 4 ] = 1 .
由4继续回到2 Low[2] = min ( low [ 2 ] , low [ 4 ] ).
low[2]=1;
由2继续回到1 判断 low[1] = min ( low [ 1 ] , low [ 2 ] ).
low[1]还是 1
然后更新3的过程省略,大家可以自己手动模拟一下。
。。。。。。。。。
省略了1->3的更新过程之后,1的所有出边就跑完了
于是判断:low [ 1 ] == dfn [ 1 ] 说明以1为根节点的强连通分量已经找完了。
将栈中1以及1之后进栈的所有点,都出栈并输出。
End
完整代码如下:
#include<iostream> //输出所有强连通分量
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std; int n,m,x,y,top=,cnt=,t,col;
int ans1=-,ans2=-,ans3=-;
int d[];
int a[];
int c[];
int f[];
int dfn[];
int low[];
int stack[]; bool v[]; struct edge{
int u;
int v;
int w;
int next;
}e[]; void Add(int u,int v,int w)
{
++top;
e[top].u=u;
e[top].v=v;
e[top].w=w;
e[top].next=f[u];
f[u]=top;
} int read()
{
int x=;
int k=;
char c=getchar();
while(c>''||c<'')
{
if(c=='-') k=-;
c=getchar();
}
while(c>=''&&c<='')
x=x*+c-'',
c=getchar();
return x*k;
} void tarjan(int now)
{
dfn[now]=low[now]=++cnt;
stack[++t]=now;
v[now]=;
for(int i=f[now];i!=-;i=e[i].next)
if(!dfn[e[i].v])
{
tarjan(e[i].v);
low[now]=min(low[now],low[e[i].v]);
}
else if(v[e[i].v])
low[now]=min(low[now],dfn[e[i].v]);
int cur;
if(dfn[now]==low[now])
{
do
{
cur=stack[t--];
v[cur]=false;
printf("%d ",cur);
}while(now!=cur);
printf("\n");
}
} int main()
{
n=read();
m=read();
memset(f,-,sizeof f);
for(int i=;i<=n;++i)
a[i]=read();
for(int i=;i<=m;++i)
{
x=read();
y=read();
Add(x,y,);
}
for(int i=;i<=n;++i)
if(!dfn[i]) tarjan(i);
return ;
}
Tarjan算法 详解+心得的更多相关文章
- Tarjan算法详解
Tarjan算法详解 今天偶然发现了这个算法,看了好久,终于明白了一些表层的知识....在这里和大家分享一下... Tarjan算法是一个求解极大强联通子图的算法,相信这些东西大家都在网络上百度过了, ...
- Tarjan 算法详解
一个神奇的算法,求最大连通分量用O(n)的时间复杂度,真实令人不可思议. 废话少说,先上题目 题目描述: 给出一个有向图G,求G连通分量的个数和最大连通分量. 输入: n,m,表示G有n个点,m条边 ...
- Tarjan算法详解理解集合
[功能] Tarjan算法的用途之一是,求一个有向图G=(V,E)里极大强连通分量.强连通分量是指有向图G里顶点间能互相到达的子图.而如果一个强连通分量已经没有被其它强通分量完全包含的话,那么这个强连 ...
- ACM(图论)——tarjan算法详解
---恢复内容开始--- tarjan算法介绍: 一种由Robert Tarjan提出的求解有向图强连通分量的线性时间的算法.通过变形,其亦可以求解无向图问题 桥: 割点: 连通分量: 适用问题: 求 ...
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- kmp算法详解
转自:http://blog.csdn.net/ddupd/article/details/19899263 KMP算法详解 KMP算法简介: KMP算法是一种高效的字符串匹配算法,关于字符串匹配最简 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- [转] KMP算法详解
转载自:http://www.matrix67.com/blog/archives/115 KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的K ...
- 【转】AC算法详解
原文转自:http://blog.csdn.net/joylnwang/article/details/6793192 AC算法是Alfred V.Aho(<编译原理>(龙书)的作者),和 ...
随机推荐
- hyperledger fabric 1.0.5 分布式部署 (八)
gdb debug peer 程序 在开始我们从 github 上download 下来的源码包,实际上已经包含了可执行的 peer 程序,但是该程序是使用 release 方式编译的,并不支持gdb ...
- jquery jtemplates.js模板渲染引擎的详细用法第二篇
jquery jtemplates.js模板渲染引擎的详细用法第二篇 关于jtemplates.js的用法在第一篇中已经讲过了,这里就直接上代码,不同之处是绑定模板的方式,这里讲模板的数据专门写一个t ...
- [题解](prufer)明明的烦恼
https://www.cnblogs.com/noip/archive/2013/03/10/2952520.html 以及高精(抄 #include<iostream> #includ ...
- python进阶12 Redis
python进阶12 Redis 一.概念 #redis是一种nosql(not only sql)数据库,他的数据是保存在内存中,同时redis可以定时把内存数据同步到磁盘,即可以将数据持久化,还提 ...
- hadoop分布式存储(1)-hadoop基础概念
hadoop是一种用于海量数据存储.管理.分析的分布式系统.需要hadoop需要储备一定的基础知识:1.掌握一定的linux操作命令 2.会java编程.因此hadoop必须安装在有jdk的linux ...
- Jmeter4.0----cookie(8)
1.说明 在脚本编写的过程中,我们常常会遇到用户登录的情况,并且将部分重要信息保存在用户的cookie中,所以,来说一下,对用户登录产生cookie的操作情况. 2.步骤 第一步:添加HTTP Coo ...
- Datagridview强制结束编辑状态
DirectCast(dgvTab1.CurrentRow.DataBoundItem, DataRowView).EndEdit() dgvTab1.CommitEdit(DataGridViewD ...
- Java8中的新特性Optional
Optional 类是一个可以为null的容器对象.如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象.Optional 是个容器:它可以保存类型T的值,或者仅仅保存 ...
- java join 方法的使用
在很多情况下,主线程创建并启动子线程,如果子线程中要进行大量的耗时运算,主线程往往将早于子线程结束之前结束.这时,如果主线程想等待子线程执行完成之后再结束,比如子线程处理一个数据,主线程要取得这个数据 ...
- Get和Post的初步探究
Get请求和Post请求这两种基本请求类型,大部分开发者心里大概都有所谓的"标准答案",但博主最近用Postman测试接口的时候,遇到传参的问题:用post请求,参数放在reque ...