python3爬虫爬取猫眼电影TOP100(含详细爬取思路)
待爬取的网页地址为https://maoyan.com/board/4,本次以requests、BeautifulSoup css selector为路线进行爬取,最终目的是把影片排名、图片、名称、演员、上映时间与评分提取出来并保存到文件。
初步分析:所有网页上展示的内容后台都是通过代码来完成的,所以,不管那么多,先看源代码
F12打开chrome的调试工具,从下面的图可以看出,实际上每一个电影选项(排名、分数、名字等)都被包括在dd标签中。
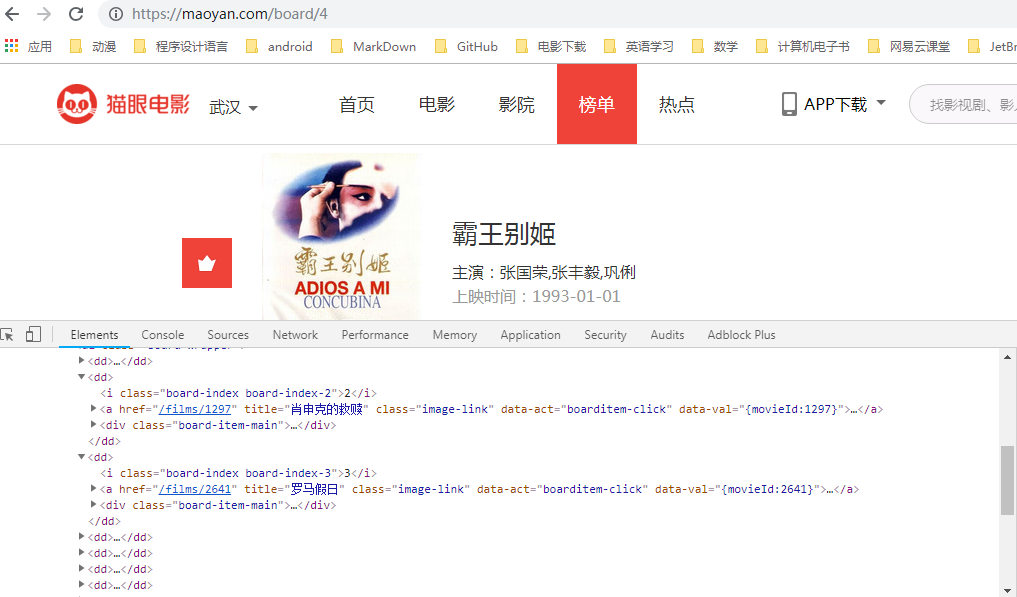
为了能把这些影片信息爬取出来,可以有以下两种思路。
思路一:把电影的每一个要素的列表先提取出来,类似如下:
titile = ['霸王别姬','肖申克的救赎'....],index = [1,2...],
最后从各个列表中选中对应的item拼接成一个个新的列表或字典类型,
类似如下:result = [{'title':'霸王别姬','index':'1'},{'title':'肖申克的救赎','index':'2'.....}
分析:因为要多次进行遍历,思路一的整体逻辑较混乱,容易出错
思路二:把每一个dd标签作为一个整体提取为一个列表,然后对列表的每一项(包含每部影片的各项信息)进行解析提取
分析:很明显,相对第一种思路,第二种思路就更加的清晰明了
下面通过代码来实现思路二的方式:
第一步:获取当前页的网页源代码
def get_current_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except RequestException:
return None
第二步:解析当前网页提取出影片信息
def parse_html(html):
soup = BeautifulSoup(html, 'lxml')
dd = soup.select('dd') #css选择器,select是选取所有符合条件的节点,select_one是选取第一个符合条件的节点
for result in dd:
#生成器的方式更省内存
yield {
'index': result.select_one('.board-index').text, #获取影片排名
'title':result.select_one('.image-link')['title'], #获取影片名字
'image':result.select_one('.poster-default')['src'], #获取影片图片链接
'star':result.select_one('.star').text.strip(), #获取演员信息
'realeasetime':result.select_one('.releasetime').text.strip(),#获取上映时间
'score':result.select_one('.integer').text+result.select_one('.fraction').text #获取影片得分
}
第三步:将结果保存到文件
def save_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f: #以追加的形式写入文件
f.write(json.dumps(content, ensure_ascii=False) + '\n')
以上实现了单页影片信息的爬取与存储,下面探索怎么实现翻页后的页面爬取
思路:既然要翻页,那就先点击下一页看看,找找规律,从下图可以看出url后面多了个?offset=10,继续翻页显示为?offset=20,最后一页显示为?offset=90,这就找到规律了,每一个url后面的url都等于页面号x10(页面号从0计数)。
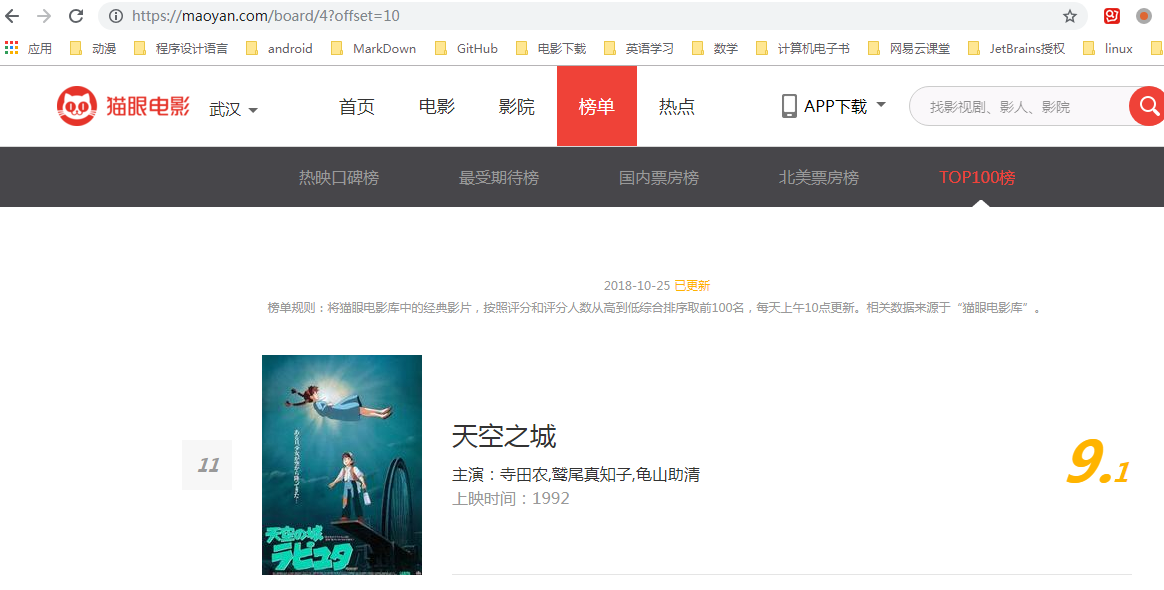
得出规律之后我们开始写主函数
第四步:写主函数
def main(offset):
url = 'https://maoyan.com/board/4?offset=' + str(offset * 10)
html = get_current_page(url)
for result in parse_html(html):
print(result)
save_to_file(result)
第五步:写函数入口
if __name__ == '__main__':
depth = 10
for i in range(depth):
main(i)
最后运行的结果:
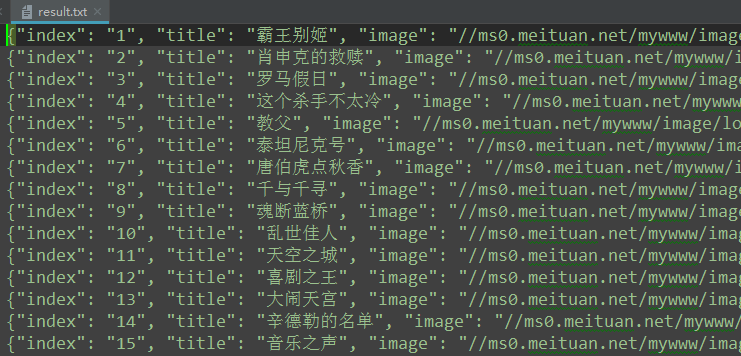
整个的爬取过程就是这样,完整代码查看可以点击这里
python3爬虫爬取猫眼电影TOP100(含详细爬取思路)的更多相关文章
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- # [爬虫Demo] pyquery+csv爬取猫眼电影top100
目录 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 代码君 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 https://maoyan.co ...
- Python爬虫项目--爬取猫眼电影Top100榜
本次抓取猫眼电影Top100榜所用到的知识点: 1. python requests库 2. 正则表达式 3. csv模块 4. 多进程 正文 目标站点分析 通过对目标站点的分析, 来确定网页结构, ...
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- 50 行代码教你爬取猫眼电影 TOP100 榜所有信息
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天,恋习Python的手把手系列,手把手教你入门Python爬虫,爬取猫眼电影TOP100榜信息,将涉及到基础爬虫 ...
- 用requests库爬取猫眼电影Top100
这里需要注意一下,在爬取猫眼电影Top100时,网站设置了反爬虫机制,因此需要在requests库的get方法中添加headers,伪装成浏览器进行爬取 import requests from re ...
- Python爬虫之requests+正则表达式抓取猫眼电影top100以及瓜子二手网二手车信息(四)
requests+正则表达式抓取猫眼电影top100 一.首先我们先分析下网页结构 可以看到第一页的URL和第二页的URL的区别在于offset的值,第一页为0,第二页为10,以此类推. 二.< ...
- Python Spider 抓取猫眼电影TOP100
""" 抓取猫眼电影TOP100 """ import re import time import requests from bs4 im ...
随机推荐
- hbase(0.94) get、scan源码分析
简介 本文是需要用到hbase timestamp性质时研究源码所写.内容有一定侧重.且个人理解不算深入,如有错误请不吝指出. 如何看源码 hbase依赖很重,没有独立的client包.所以目前如果在 ...
- 机器学习模型-支持向量机(SVM)
二.代码实现 import numpy as np from sklearn import datasets from sklearn.model_selection import train_tes ...
- hdu1281(棋盘游戏,车的放置)
Problem Description 给定一个n * m的棋盘,在棋盘里放尽量多的国际象棋中的车,使他们不能相互攻击 已知有些格子不能放置,问最多能放置多少个车 并计算出必须棋盘上的必须点. Inp ...
- cookie中的path与domain属性详解
1.domain表示的是cookie所在的域,默认为请求的地址,如网址为www.jb51.net/test/test.aspx,那么domain默认为www.jb51.net.而跨域访问,如域A为t1 ...
- 湖南大学第十四届ACM程序设计新生杯 Dandan's lunch
Dandan's lunch Description: As everyone knows, there are now n people participating in the competiti ...
- region xx not deployed on any region server
ERROR: Region { meta => month_hotstatic,860010-2288000000_201405_5_exit_00000047486,1400144486405 ...
- 数据结构之(HDU2051 Bitset)
Problem Description Give you a number on base ten,you should output it on base two.(0 < n < 10 ...
- c++ 公有继承的赋值兼容规则
赋值兼容规则是指在需要基类对象的任何地方都可以使用公有派生类的对象来替代.通过公有继承,派生类得到了基类中除构造函数.析构函数之外的所有成员,而且所有成员的访问控制属性也和基类完全相同.这样,公有派生 ...
- 转:强化学习(Reinforcement Learning)
机器学习算法大致可以分为三种: 1. 监督学习(如回归,分类) 2. 非监督学习(如聚类,降维) 3. 增强学习 什么是增强学习呢? 增强学习(reinforcementlearning, RL)又叫 ...
- DotNETCore 学习笔记 依赖注入和多环境
Dependency Injection ------------------------------------------------------------------------ ASP.NE ...