Hadoop基础入门
一、hadoop是什么?
(1)Hadoop是一个开源的框架,可编写和运行分布式应用处理大规模数据,是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。Hadoop=HDFS(文件系统,数据存储技术相关)+ Mapreduce(数据处理),Hadoop的数据来源可以是任何形式,在处理半结构化和非结构化数据上与关系型数据库相比有更好的性能,具有更灵活的处理能力,不管任何数据形式最终会转化为key/value,key/value是基本数据单元。用函数式变成Mapreduce代替SQL,SQL是查询语句,而Mapreduce则是使用脚本和代码,而对于适用于关系型数据库,习惯SQL的Hadoop有开源工具hive代替。
(2)Hadoop就是一个分布式计算的解决方案。
二、hadoop的应用场景有哪些?
- 大数据量存储:分布式存储
- 日志处理: Hadoop擅长这个
- 海量计算: 并行计算
- ETL:数据抽取到oracle、mysql、DB2、mongdb及主流数据库
- 使用HBase做数据分析: 用扩展性应对大量的写操作—Facebook构建了基于HBase的实时数据分析系统
- 机器学习: 比如Apache Mahout项目
- 搜索引擎:hadoop + lucene实现
- 数据挖掘:目前比较流行的广告推荐
- 大量地从文件中顺序读。HDFS对顺序读进行了优化,代价是对于随机的访问负载较高。
- 数据支持并且最适用于一次写入,多次读取的场景。对于已经形成的数据的更新不支持。
- 数据不进行本地缓存(文件很大,且顺序读没有局部性)
- 任何一台服务器都有可能失效,需要通过大量的数据副本使得性能不会受到大的影响。
- 用户细分特征建模
- 个性化广告推荐
- 智能仪器推荐
三、Hadoop各版本特性
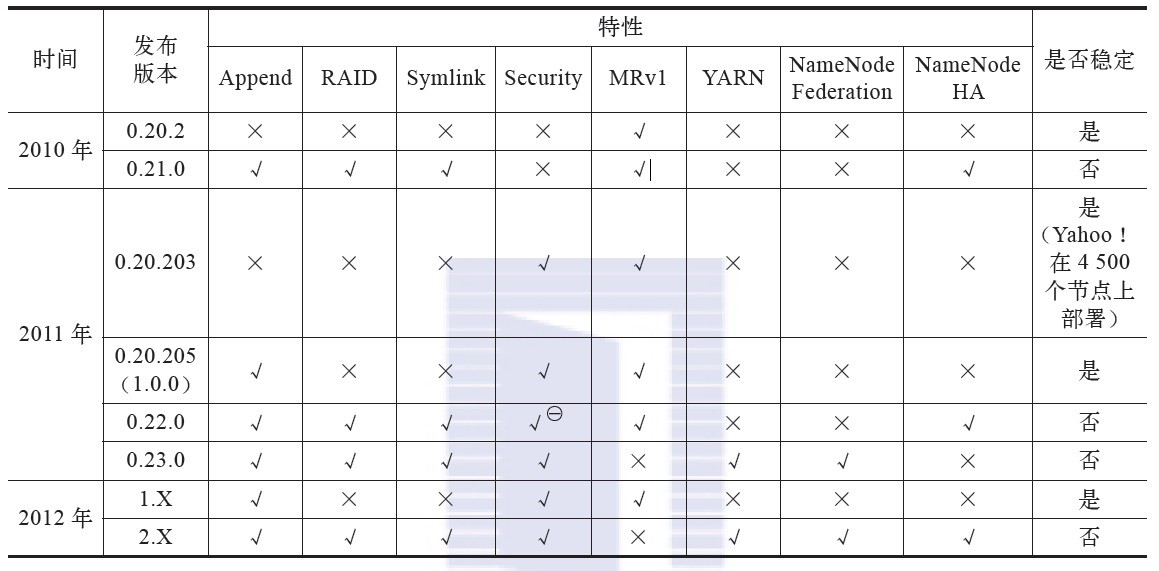
四、Hadoop存储模型
Hadoop采用hbase做数据库,但由于hbase没有类sql查询方式,所以操作和计算数据非常不方便,于是整合hive,让hive支撑在hbase数据库层面 的 hql查询.hive也即 做数据仓库。
五、Hadoop的优缺点
Hadoop 在处理非结构数据和半结构数据上具备优势,尤其适合海量数据批处理等应用需求。
Hadoop基础入门的更多相关文章
- hadoop 基础入门
启动: 格式化节点:bin/hdfs namenode -format 全部启动:sbin/start-dfs:datanode.namenode sbi ...
- 大数据Hadoop基础入门到精通
1.hadoop前世今生: 1) 搜索引擎:网络爬虫+索引服务器(生成索引+检索) 2) Doung Cutting 3) Nutch a.分布式存储 b.分布式计算 4)GFS论文 doung c ...
- Hadoop学习笔记—2.不怕故障的海量存储:HDFS基础入门
一.HDFS出现的背景 随着社会的进步,需要处理数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是却不方便管理和维护—>因此,迫切需要一种系统来管理多 ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- 【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell
Spark 基础入门,集群搭建以及Spark Shell 主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践. Spark 安装部署 理论已经了解的差不多了,接下来是实际动手实 ...
- Cloudera Manager、CDH零基础入门、线路指导 http://www.aboutyun.com/thread-9219-1-1.html (出处: about云开发)
Cloudera Manager.CDH零基础入门.线路指导http://www.aboutyun.com/thread-9219-1-1.html(出处: about云开发) 问题导读:1.什么是c ...
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- hadoop基础----hadoop理论(四)-----hadoop分布式并行计算模型MapReduce具体解释
我们在前一章已经学习了HDFS: hadoop基础----hadoop理论(三)-----hadoop分布式文件系统HDFS详细解释 我们已经知道Hadoop=HDFS(文件系统,数据存储技术相关)+ ...
- 1.2 Hadoop快速入门
1.2 Hadoop快速入门 1.Hadoop简介 Hadoop是一个开源的分布式计算平台. 提供功能:利用服务器集群,根据用户定义的业务逻辑,对海量数据的存储(HDFS)和分析计算(MapReduc ...
随机推荐
- 3.Hive中查看数据来源文件和具体位置方法
虚拟列 -- 当 hive 产生了非预期的或 null 的时候,可以通过虚拟列进行诊断,判断哪行数据出现问题 INPUT__FILE__NAME (输入文件名)map任务读入File的全路径 ...
- Part5核心初始化_lesson4---关闭mmu
1.ARM存储体系 2.cache 3.虚拟地址 那么谁来完成把虚拟地址转换成物理地址呢? 4.这个工作就由MMU来转换!! 5.关闭MMU和cache 他们都是通过cp15协处理器来控制的!应该在A ...
- Entity Framework 6.0 Tutorials(4):Database Command Logging
Database Command Logging: In this section, you will learn how to log commands & queries sent to ...
- hdu4643 GSM
#include<stdio.h> #include<math.h> #define Max 55 #define eps 1e-8 int n,m; struct Point ...
- springboot-条件化注解
在项目中,有时会遇到我们的Configuration.Bean.Service等等的bean组件需要依条件按需加载的情况.那么Spring Boot怎么做的呢?它为此定义了许多有趣的条件,当我们将它们 ...
- 常用Linux命令:mount/umount/blkid
一.mount:挂载命令 1.命令格式 mount [参数] [设备名称] [挂载点] 2.常用参数 -a :安装在/etc/fstab文件中列出的所有文件系统 -f :伪装mount,做出检 ...
- EBS取Web字段SQL操作文档
1) 安全性—>责任-à定义 在这个路径下,输入责任名称,可以查询这个责任的请求组的名称 2) organization_id 和 org_id的功能 3) 查找网页上的字段 Naviga ...
- HTML5移动开发即学即用(双色) 王志刚 pdf扫描版
HTML5已经广泛应用于各智能移动终端设备上,而且绝大部分技术已经被各种最新版本的测览器所支持:逐一剖析HTML5标准中包含的最新技术,详细介绍了HTML5新标准中提供的各种API,各种各样的应用实例 ...
- Timer(定时器)
默认情况下,在每个采样器之前没有任何延时,这样不能很好的模拟现实生活中人们访问网页,因为现实生活中人们点击一个请求后,会有一定的时间,然后再点击下一个请求,JMeter提供了定时器来模拟这种行为. 定 ...
- day1学python Hello Python
Hello Python 本人使用的是Pycharm编译器 ----------------------------------------------- 1.输出 2.赋值 3.‘’‘/“”“ 多行 ...