java深入探究14-lucene
项目代码:链接:http://pan.baidu.com/s/1qXVcfCw 密码:apw1
01 回顾索引
定义:索引是对数据库表中一列或多列的值进行排序的一种结构
目的:加快对数据库表中记录的查询
特点:以空间换取时间,提高查询速度快

02 体验百度搜索与原理图
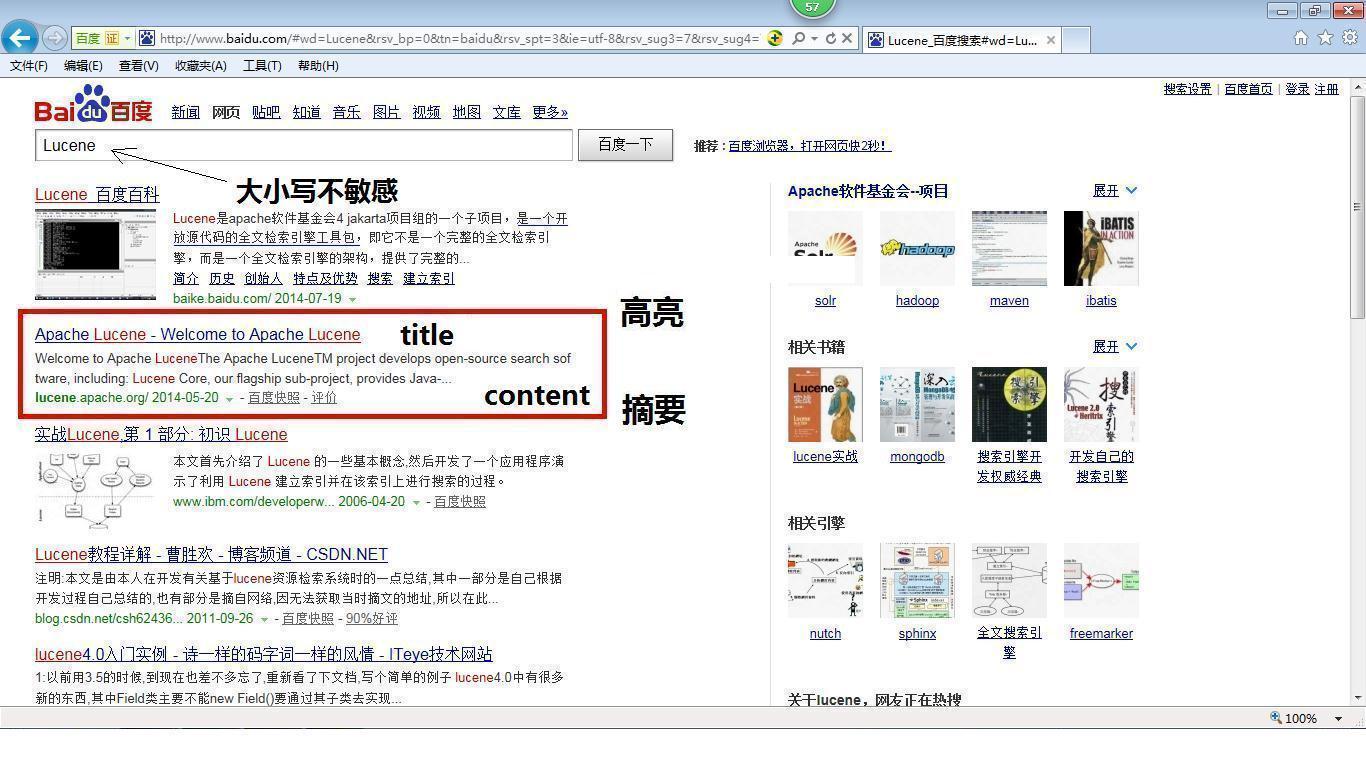
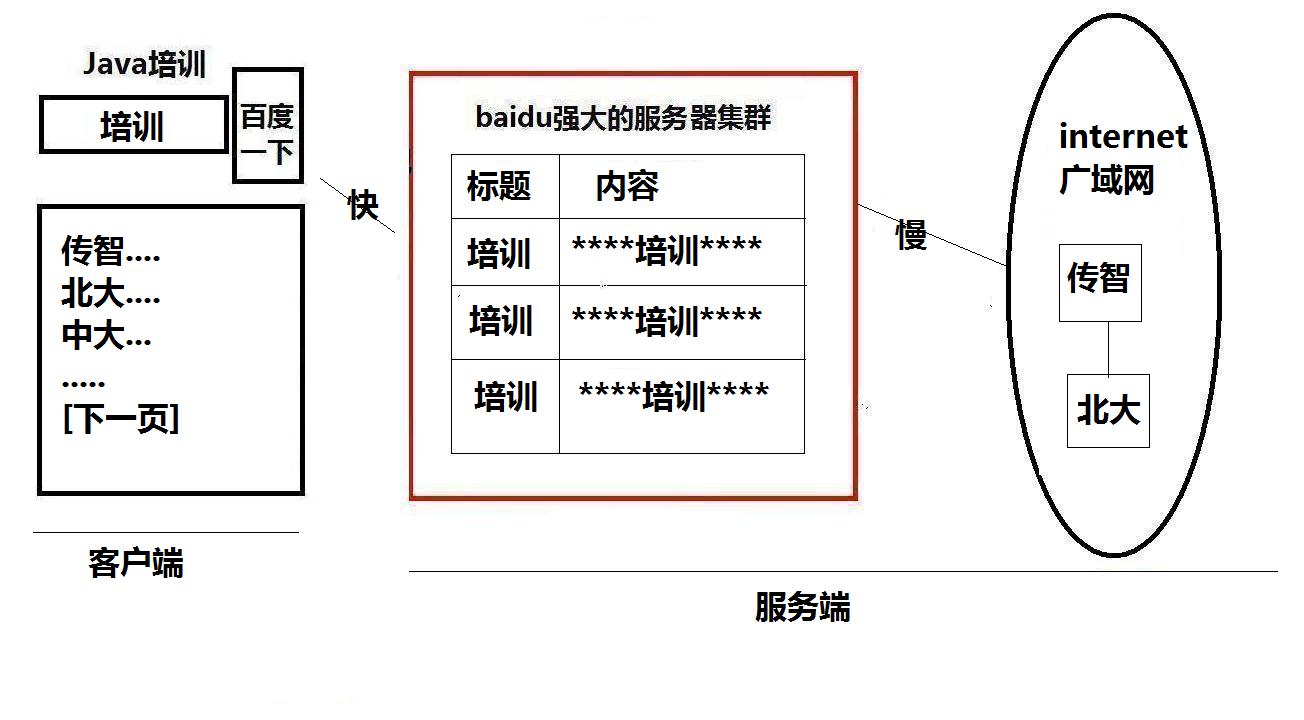

03 什么是Lucene
Lucene是apache软件基金会发布的一个开放源代码的全文检索引擎工具包,由资深全文检索专家Doug Cutting所撰写,它是一个全文检索引擎的架构,提供了完整的创建索引和查询索引,以及部分文本分析的引擎,Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎,Lucene在全文检索领域是一个经典的祖先,现在很多检索引擎都是在其基础上创建的,思想是相通的。
即:Lucene是根据关健字来搜索的文本搜索工具,只能在某个网站内部搜索文本内容,不能跨网站搜索
04 Lucene通常用在什么地方
Lucece不能用在互联网搜索(即像百度那样),只能用在网站内部的文本搜索(即只能在CRM,RAX,ERP内部使用),但思想是相通的。

05 Lucene中存的什么内容
Lucene中存的就是一系列的二进制压缩文件和一些控制文件,它们位于计算机的硬盘上,
这些内容统称为索引库,索引库有二部份组成:
(1)原始记录
存入到索引库中的原始文本,例如:小平非常的聪明
(2)词汇表
按照一定的拆分策略(即分词器)将原始记录中的每个字符拆开后,存入一个供将来搜索的表
06 为什么网站内部有些地方要用Lucene来索搜,确不全用SQL来搜索
(1)SQL只能针对数据库表搜索,不能直接针对硬盘上的文本搜索
(2)SQL没有相关度排名
(3)SQL搜索结果没有关健字高亮显示
(4)SQL需要数据库的支持,数据库本身需要内存开销较大,例如:Oracle
(5)SQL搜索有时较慢,尤其是数据库不在本地时,超慢,例如:Oracle
07 书写代码使用Lucene的流程图


创建索引库:
1) 创建JavaBean对象
2) 创建Docment对象
3) 将JavaBean对象所有的属性值,均放到Document对象中去,属性名可以和JavaBean相同或不同
4) 创建IndexWriter对象
5) 将Document对象通过IndexWriter对象写入索引库中
6) 关闭IndexWriter对象
根据关键字查询索引库中的内容:
1) 创建IndexSearcher对象
2) 创建QueryParser对象
3) 创建Query对象来封装关键字
4) 用IndexSearcher对象去索引库中查询符合条件的前100条记录,不足100条记录的以实际为准
5) 获取符合条件的编号
6) 用indexSearcher对象去索引库中查询编号对应的Document对象
7) 将Document对象中的所有属性取出,再封装回JavaBean对象中去,并加入到集合中保存,以备将之用
*****08 Lucene快速入门
步一:创建javaweb工程,取名叫lucene-day01
步二:导入Lucene相关的jar包
lucene-core-3.0.2.jar【Lucene核心】
lucene-analyzers-3.0.2.jar【分词器】
lucene-highlighter-3.0.2.jar【Lucene会将搜索出来的字,高亮显示,提示用户】
lucene-memory-3.0.2.jar【索引库优化策略】
步三:创建包结构
cn.itcast.javaee.lucene.entity
cn.itcast.javaee.lucene.firstapp
cn.itcast.javaee.lucene.secondapp
cn.itcast.javaee.lucene.crud
cn.itcast.javaee.lucene.fy
cn.itcast.javaee.lucene.utils
。。 。。 。
步四:创建JavaBean类
public class Article {
private Integer id;//标题
private String title;//标题
private String content;//内容
public Article(){}
public Article(Integer id, String title, String content) {
this.id = id;
this.title = title;
this.content = content;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
步五:创建FirstLucene.java类,编写createIndexDB()和findIndexDB()二个业务方法
@Test
public void createIndexDB() throws Exception{
Article article = new Article(,"培训","传智是一个Java培训机构");
Document document = new Document();
document.add(new Field("id",article.getId().toString(),Store.YES,Index.ANALYZED));
document.add(new Field("title",article.getTitle(),Store.YES,Index.ANALYZED));
document.add(new Field("content",article.getContent(),Store.YES,Index.ANALYZED));
Directory directory = FSDirectory.open(new File("E:/LuceneDBDBDBDBDBDBDBDBDB"));
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
MaxFieldLength maxFieldLength = MaxFieldLength.LIMITED;
IndexWriter indexWriter = new IndexWriter(directory,analyzer,maxFieldLength);
indexWriter.addDocument(document);
indexWriter.close();
}
*****09 创建LuceneUtil工具类,使用反射,封装通用的方法
public class LuceneUtil {
private static Directory directory ;
private static Analyzer analyzer ;
private static Version version;
private static MaxFieldLength maxFieldLength;
static{
try {
directory = FSDirectory.open(new File("E:/LuceneDBDBDBDBDBDBDBDBDB"));
version = Version.LUCENE_30;
analyzer = new StandardAnalyzer(version);
maxFieldLength = MaxFieldLength.LIMITED;
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public static Directory getDirectory() {
return directory;
}
public static Analyzer getAnalyzer() {
return analyzer;
}
public static Version getVersion() {
return version;
}
public static MaxFieldLength getMaxFieldLength() {
return maxFieldLength;
}
public static Document javabean2documemt(Object obj) throws Exception{
Document document = new Document();
Class clazz = obj.getClass();
java.lang.reflect.Field[] reflectFields = clazz.getDeclaredFields();
for(java.lang.reflect.Field field : reflectFields){
field.setAccessible(true);
String fieldName = field.getName();
String init = fieldName.substring(,).toUpperCase();
String methodName = "get" + init + fieldName.substring();
Method method = clazz.getDeclaredMethod(methodName,null);
String returnValue = method.invoke(obj,null).toString();
document.add(new Field(fieldName,returnValue,Store.YES,Index.ANALYZED));
}
return document;
}
public static Object document2javabean(Document document,Class clazz) throws Exception{
Object obj = clazz.newInstance();
java.lang.reflect.Field[] reflectFields = clazz.getDeclaredFields();
for(java.lang.reflect.Field field : reflectFields){
field.setAccessible(true);
String fieldName = field.getName();
String fieldValue = document.get(fieldName);
BeanUtils.setProperty(obj,fieldName,fieldValue);
}
return obj;
}
}
*****10 使用LuceneUtil工具类,重构FirstLucene.java为SecondLucene.java
public class SecondLucene {
@Test
public void createIndexDB() throws Exception{
Article article = new Article(,"Java培训","传智是一个Java培训机构");
Document document = LuceneUtil.javabean2documemt(article);
IndexWriter indexWriter = new IndexWriter(LuceneUtil.getDirectory(),LuceneUtil.getAnalyzer(),LuceneUtil.getMaxFieldLength());
indexWriter.addDocument(document);
indexWriter.close();
}
@Test
public void findIndexDB() throws Exception{
List<Article> articleList = new ArrayList<Article>();
String keywords = "传";
QueryParser queryParser = new QueryParser(LuceneUtil.getVersion(),"content",LuceneUtil.getAnalyzer());
Query query = queryParser.parse(keywords);
IndexSearcher indexSearcher = new IndexSearcher(LuceneUtil.getDirectory());
TopDocs topDocs = indexSearcher.search(query,);
for(int i=;i<topDocs.scoreDocs.length;i++){
ScoreDoc scoreDoc = topDocs.scoreDocs[i];
int no = scoreDoc.doc;
Document document = indexSearcher.doc(no);
Article article = (Article) LuceneUtil.document2javabean(document,Article.class);
articleList.add(article);
}
for(Article article : articleList){
System.out.println(article.getId()+":"+article.getTitle()+":"+article.getContent());
}
}
}
*****11 使用LuceneUtil工具类,完成CURD操作
public class LuceneCURD {
@Test
public void addIndexDB() throws Exception{
Article article = new Article(,"培训","传智是一个Java培训机构");
Document document = LuceneUtil.javabean2documemt(article);
IndexWriter indexWriter = new IndexWriter(LuceneUtil.getDirectory(),LuceneUtil.getAnalyzer(),LuceneUtil.getMaxFieldLength());
indexWriter.addDocument(document);
indexWriter.close();
}
@Test
public void updateIndexDB() throws Exception{
Integer id = ;
Article article = new Article(,"培训","广州传智是一个Java培训机构");
Document document = LuceneUtil.javabean2documemt(article);
Term term = new Term("id",id.toString());
IndexWriter indexWriter = new IndexWriter(LuceneUtil.getDirectory(),LuceneUtil.getAnalyzer(),LuceneUtil.getMaxFieldLength());
indexWriter.updateDocument(term,document);
indexWriter.close();
}
@Test
public void deleteIndexDB() throws Exception{
Integer id = ;
Term term = new Term("id",id.toString());
IndexWriter indexWriter = new IndexWriter(LuceneUtil.getDirectory(),LuceneUtil.getAnalyzer(),LuceneUtil.getMaxFieldLength());
indexWriter.deleteDocuments(term);
indexWriter.close();
}
@Test
public void deleteAllIndexDB() throws Exception{
IndexWriter indexWriter = new IndexWriter(LuceneUtil.getDirectory(),LuceneUtil.getAnalyzer(),LuceneUtil.getMaxFieldLength());
indexWriter.deleteAll();
indexWriter.close();
}
@Test
public void searchIndexDB() throws Exception{
List<Article> articleList = new ArrayList<Article>();
String keywords = "传智";
QueryParser queryParser = new QueryParser(LuceneUtil.getVersion(),"content",LuceneUtil.getAnalyzer());
Query query = queryParser.parse(keywords);
IndexSearcher indexSearcher = new IndexSearcher(LuceneUtil.getDirectory());
TopDocs topDocs = indexSearcher.search(query,);
for(int i = ;i<topDocs.scoreDocs.length;i++){
ScoreDoc scoreDoc = topDocs.scoreDocs[i];
int no = scoreDoc.doc;
Document document = indexSearcher.doc(no);
Article article = (Article) LuceneUtil.document2javabean(document,Article.class);
articleList.add(article);
}
for(Article article : articleList){
System.out.println(article.getId()+":"+article.getTitle()+":"+article.getContent());
}
}
}
*****12 使用使用Jsp + Js + Servlet + Lucene完成分页一,同步分页
步一:创建ArticleDao.java类
public class ArticleDao {
public Integer getAllObjectNum(String keywords) throws Exception{
QueryParser queryParser = new QueryParser(LuceneUtil.getVersion(),"content",LuceneUtil.getAnalyzer());
Query query = queryParser.parse(keywords);
IndexSearcher indexSearcher = new IndexSearcher(LuceneUtil.getDirectory());
TopDocs topDocs = indexSearcher.search(query,);
return topDocs.totalHits;
}
public List<Article> findAllObjectWithFY(String keywords,Integer start,Integer size) throws Exception{
List<Article> articleList = new ArrayList<Article>();
QueryParser queryParser = new QueryParser(LuceneUtil.getVersion(),"content",LuceneUtil.getAnalyzer());
Query query = queryParser.parse(keywords);
IndexSearcher indexSearcher = new IndexSearcher(LuceneUtil.getDirectory());
TopDocs topDocs = indexSearcher.search(query,);
int middle = Math.min(start+size,topDocs.totalHits);
for(int i=start;i<middle;i++){
ScoreDoc scoreDoc = topDocs.scoreDocs[i];
int no = scoreDoc.doc;
Document document = indexSearcher.doc(no);
Article article = (Article) LuceneUtil.document2javabean(document,Article.class);
articleList.add(article);
}
return articleList;
}
}
步二:创建PageBean.java类
public class PageBean {
private Integer allObjectNum;
private Integer allPageNum;
private Integer currPageNum;
private Integer perPageNum = ;
private List<Article> articleList = new ArrayList<Article>();
public PageBean(){}
public Integer getAllObjectNum() {
return allObjectNum;
}
public void setAllObjectNum(Integer allObjectNum) {
this.allObjectNum = allObjectNum;
if(this.allObjectNum % this.perPageNum == ){
this.allPageNum = this.allObjectNum / this.perPageNum;
}else{
this.allPageNum = this.allObjectNum / this.perPageNum + ;
}
}
public Integer getAllPageNum() {
return allPageNum;
}
public void setAllPageNum(Integer allPageNum) {
this.allPageNum = allPageNum;
}
public Integer getCurrPageNum() {
return currPageNum;
}
public void setCurrPageNum(Integer currPageNum) {
this.currPageNum = currPageNum;
}
public Integer getPerPageNum() {
return perPageNum;
}
public void setPerPageNum(Integer perPageNum) {
this.perPageNum = perPageNum;
}
public List<Article> getArticleList() {
return articleList;
}
public void setArticleList(List<Article> articleList) {
this.articleList = articleList;
}
}
步三:创建ArticleService.java类
public class ArticleService {
private ArticleDao articleDao = new ArticleDao();
public PageBean fy(String keywords,Integer currPageNum) throws Exception{
PageBean pageBean = new PageBean();
pageBean.setCurrPageNum(currPageNum);
Integer allObjectNum = articleDao.getAllObjectNum(keywords);
pageBean.setAllObjectNum(allObjectNum);
Integer size = pageBean.getPerPageNum();
Integer start = (pageBean.getCurrPageNum()-) * size;
List<Article> articleList = articleDao.findAllObjectWithFY(keywords,start,size);
pageBean.setArticleList(articleList);
return pageBean;
}
}
步四:创建ArticleServlet.java类
public class ArticleServlet extends HttpServlet {
public void doPost(HttpServletRequest request, HttpServletResponse response)throws ServletException, IOException {
try {
request.setCharacterEncoding("UTF-8");
Integer currPageNum = Integer.parseInt(request.getParameter("currPageNum"));
String keywords = request.getParameter("keywords");
ArticleService articleService = new ArticleService();
PageBean pageBean = articleService.fy(keywords,currPageNum);
request.setAttribute("pageBean",pageBean);
request.getRequestDispatcher("/list.jsp").forward(request,response);
} catch (Exception e) {
e.printStackTrace();
}
}
}
步五:导入EasyUI相关的js包的目录

步六:在WebRoot目录下创建list.jsp
<%@ page language="java" pageEncoding="UTF-8"%>
<%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<link rel="stylesheet" href="themes/default/easyui.css" type="text/css"></link>
<link rel="stylesheet" href="themes/icon.css" type="text/css"></link>
<script type="text/javascript" src="js/jquery.min.js"></script>
<script type="text/javascript" src="js/jquery.easyui.min.js"></script>
<script type="text/javascript" src="locale/easyui-lang-zh_CN.js"></script>
</head>
<body> <!-- 输入区 -->
<form action="${pageContext.request.contextPath}/ArticleServlet?currPageNum=1" method="POST">
输入关健字:<input type="text" name="keywords" value="传智" maxlength=""/>
<input type="button" value="提交"/>
</form> <!-- 显示区 -->
<table border="" align="center" width="70%">
<tr>
<th>编号</th>
<th>标题</th>
<th>内容</th>
</tr>
<c:forEach var="article" items="${pageBean.articleList}">
<tr>
<td>${article.id}</td>
<td>${article.title}</td>
<td>${article.content}</td>
</tr>
</c:forEach>
</table> <!-- 分页组件区 -->
<center>
<div id="pp" style="background:#efefef;border:1px solid #ccc;width:600px"></div>
</center>
<script type="text/javascript">
$("#pp").pagination({
total:${pageBean.allObjectNum},
pageSize:${pageBean.perPageNum},
showPageList:false,
showRefresh:false,
pageNumber:${pageBean.currPageNum}
});
$("#pp").pagination({
onSelectPage:function(pageNumber){
$("form").attr("action","${pageContext.request.contextPath}/ArticleServlet?currPageNum="+pageNumber);
$("form").submit();
}
});
</script>
<script type="text/javascript">
$(":button").click(function(){
$("form").submit();
});
</script>
</body>
</html>
步六:在WebRoot目录下创建list2.jsp
<%@ page language="java" pageEncoding="UTF-8"%>
<%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<title>根据关键字分页查询所有信息</title>
</head>
<body> <!-- 输入区 -->
<form action="${pageContext.request.contextPath}/ArticleServlet" method="POST">
<input id="currPageNOID" type="hidden" name="currPageNO" value="">
<table border="" align="center">
<tr>
<th>输入关键字:</th>
<th><input type="text" name="keywords" maxlength="" value="${requestScope.keywords}"/></th>
<th><input type="submit" value="站内搜索"/></th>
</tr>
</table>
</form> <!-- 输出区 -->
<table border="" align="center" width="60%">
<tr>
<th>编号</th>
<th>标题</th>
<th>内容</th>
</tr>
<c:forEach var="article" items="${requestScope.pageBean.articleList}">
<tr>
<td>${article.id}</td>
<td>${article.title}</td>
<td>${article.content}</td>
</tr>
</c:forEach>
<!-- 分页条 -->
<tr>
<td colspan="" align="center">
<a onclick="fy(1)" style="text-decoration:none;cursor:hand">
【首页】
</a>
<c:choose>
<c:when test="${requestScope.pageBean.currPageNO+1<=requestScope.pageBean.allPageNO}">
<a onclick="fy(${requestScope.pageBean.currPageNO+1})" style="text-decoration:none;cursor:hand">
【下一页】
</a>
</c:when>
<c:otherwise>
下一页
</c:otherwise>
</c:choose>
<c:choose>
<c:when test="${requestScope.pageBean.currPageNO-1>0}">
<a onclick="fy(${requestScope.pageBean.currPageNO-1})" style="text-decoration:none;cursor:hand">
【上一页】
</a>
</c:when>
<c:otherwise>
上一页
</c:otherwise>
</c:choose>
<a onclick="fy(${requestScope.pageBean.allPageNO})" style="text-decoration:none;cursor:hand">
【未页】
</a>
</td>
</tr>
</table> <script type="text/javascript">
function fy(currPageNO){
document.getElementById("currPageNOID").value = currPageNO;
document.forms[].submit();
}
</script> </body>
</html>


-------------------------------------------------------------------------------------------------------
13 索引库优化
1)什么是索引库
索引库是Lucene的重要的存储结构,它包括二部份:原始记录表,词汇表
原始记录表:存放的是原始记录信息,Lucene为存入的内容分配一个唯一的编号
词汇表:存放的是经过分词器拆分出来的词汇和该词汇在原始记录表中的编号
2)为什么要将索引库进行优化
在默认情况下,向索引库中增加一个Document对象时,索引库自动会添加一个扩展名叫*.cfs的二进制压缩文件,如果向索引库中存Document对象过多,那么*.cfs也会不断增加,同时索引库的容量也会不断增加,影响索引库的大小。
3)索引库优化方案
1.合并cfs文件,合并后的cfs文件是二进制压缩字符,能解决是的文件大小和数量的问题
indexWriter.addDocument(document);indexWriter.optimize(); indexWriter.close();
2设定合并因子,自动合并cfs文件,默认10个cfs文件合并成一个cfs文件
indexWriter.addDocument(document);indexWriter.setMergeFactor(3);indexWriter.close();
3.使用RAMDirectory,类似于内存索引库,能解决是的读取索引库文件的速度问题,它能以空换时,提高速度快,但不能持久保存,因此启动时加载硬盘中的索引库到内存中的索引库,退出时将内存中的索引库保存到硬盘中的索引库,且内容不能重复。
Article article = new Article(1,"培训","传智是一家Java培训机构");
Document document = LuceneUtil.javabean2document(article); Directory fsDirectory = FSDirectory.open(new File("E:/indexDBDBDBDBDBDBDBDB"));
Directory ramDirectory = new RAMDirectory(fsDirectory); IndexWriter fsIndexWriter = new IndexWriter(fsDirectory,LuceneUtil.getAnalyzer(),true,LuceneUtil.getMaxFieldLength());
IndexWriter ramIndexWriter = new IndexWriter(ramDirectory,LuceneUtil.getAnalyzer(),LuceneUtil.getMaxFieldLength()); ramIndexWriter.addDocument(document);
ramIndexWriter.close(); fsIndexWriter.addIndexesNoOptimize(ramDirectory);
fsIndexWriter.close();
14 分词器
1)什么是分词器
采用一种算法,将中英文本中的字符拆分开来,形成词汇,以待用户输入关健字后搜索
2)为什么要分词器
因为用户输入的搜索的内容是一段文本中的一个关健字,和原始表中的内容有差别,
但作为搜索引擎来讲,又得将相关的内容搜索出来,此时就得采用分词器来最大限度
匹配原始表中的内容
3)分词器工作流程
按分词器拆分出词汇-》去除停用词和禁用词-》如果有英文,把英文字母转为小写,即搜索不分大小写
4)演示分词测试
private static void testAnalyzer(Analyzer analyzer, String text) throws Exception {
System.out.println("当前使用的分词器:" + analyzer.getClass());
TokenStream tokenStream = analyzer.tokenStream("content",new StringReader(text));
tokenStream.addAttribute(TermAttribute.class);
while (tokenStream.incrementToken()) {
TermAttribute termAttribute = tokenStream.getAttribute(TermAttribute.class);
System.out.println(termAttribute.term());
}
}
5)使用第三方IKAnalyzer分词器--------中文首选
需求:过滤掉上面例子中的“说”,“的”,“呀”,且将“传智播客”看成一个整体 关健字
步一:导入IKAnalyzer分词器核心jar包,IKAnalyzer3.2.0Stable.jar
步二:将IKAnalyzer.cfg.xml和stopword.dic和xxx.dic文件复制到MyEclipse的src目录下,
再进行配置,在配置时,首行需要一个空行
15 搜索结果高亮
什么是搜索结果高亮
在搜索结果中,将与关健字相同的字符用红色显示
String keywords = "培训";
List<Article> articleList = new ArrayList<Article>();
QueryParser queryParser = new QueryParser(LuceneUtil.getVersion(),"content",LuceneUtil.getAnalyzer());
Query query = queryParser.parse(keywords);
IndexSearcher indexSearcher = new IndexSearcher(LuceneUtil.getDirectory());
TopDocs topDocs = indexSearcher.search(query,1000000); Formatter formatter = new SimpleHTMLFormatter("<font color='red'>","</font>");
Scorer scorer = new QueryScorer(query);
Highlighter highlighter = new Highlighter(formatter,scorer); for(int i=0;i<topDocs.scoreDocs.length;i++){
ScoreDoc scoreDoc = topDocs.scoreDocs[i];
int no = scoreDoc.doc;
Document document = indexSearcher.doc(no); String highlighterContent = highlighter.getBestFragment(LuceneUtil.getAnalyzer(),"content",document.get("content"));
document.getField("content").setValue(highlighterContent); Article article = (Article) LuceneUtil.document2javabean(document,Article.class);
articleList.add(article);
}
for(Article article : articleList){
System.out.println(article);
}
}
16 搜索结果摘要
1)什么是搜索结果搞要
如果搜索结果内容太多,我们只想显示前几个字符, 必须与高亮一起使用
String keywords = "培训";
List<Article> articleList = new ArrayList<Article>();
QueryParser queryParser = new QueryParser(LuceneUtil.getVersion(),"content",LuceneUtil.getAnalyzer());
Query query = queryParser.parse(keywords);
IndexSearcher indexSearcher = new IndexSearcher(LuceneUtil.getDirectory());
TopDocs topDocs = indexSearcher.search(query,1000000); Formatter formatter = new SimpleHTMLFormatter("<font color='red'>","</font>");
Scorer scorer = new QueryScorer(query);
Highlighter highlighter = new Highlighter(formatter,scorer); Fragmenter fragmenter = new SimpleFragmenter(4);
highlighter.setTextFragmenter(fragmenter); for(int i=0;i<topDocs.scoreDocs.length;i++){
ScoreDoc scoreDoc = topDocs.scoreDocs[i];
int no = scoreDoc.doc;
Document document = indexSearcher.doc(no); String highlighterContent = highlighter.getBestFragment(LuceneUtil.getAnalyzer(),"content",document.get("content"));
document.getField("content").setValue(highlighterContent); Article article = (Article) LuceneUtil.document2javabean(document,Article.class);
articleList.add(article);
}
for(Article article : articleList){
System.out.println(article);
}
}
*****17 搜索结果
1)什么是搜索结果排序
搜索结果是按某个或某些字段高低排序来显示的结果
2)影响网站排名的先后的有多种
head/meta/;网页的标签整洁;网页执行速度; 采用div+css。。。。。。
3)Lucene中的显示结果次序与相关度得分有关:ScoreDoc.score;
默认情况下,Lucene是按相关度得分排序的,得分高排在前,得分低排在后如果相关度得分相同,按插入索引库的先后次序排序
4)Lucene中的设置相关度得分
IndexWriter indexWriter = new IndexWriter(LuceneUtil.getDirectory(),LuceneUtil.getAnalyzer(),LuceneUtil.getMaxFieldLength());
document.setBoost(20F);
indexWriter.addDocument(document);
indexWriter.close();
5)Lucene中按单个字段排序
Sort sort = new Sort(new SortField("id",SortField.INT,true));
TopDocs topDocs = indexSearcher.search(query,null,1000000,sort);
6)Lucene中按多个字段排序
Sort sort = new Sort(new SortField("count",SortField.INT,true),new SortField("id",SortField.INT,true));
TopDocs topDocs = indexSearcher.search(query,null,1000000,sort);
在多字段排序中,只有第一个字段排序结果相同时,第二个字段排序才有作用 提倡用数值型排序
*****18 条件搜索
1)什么是条件搜索
用关健字与指定的单列或多例进行匹配的搜索
2)单字段条件搜索
QueryParser queryParser = new QueryParser(LuceneUtil.getVersion(),"content",LuceneUtil.getAnalyzer());
3)多字段条件搜索,项目中提倡多字段搜索
QueryParser queryParser = new MultiFieldQueryParser(LuceneUtil.getVersion(),new String[]{"content","title"},LuceneUtil.getAnalyzer());
*****19 用第三方工具类,将Map<String,Object>转成JSON文本
导入第三方jar包:
》commons-beanutils-1.7.0.jar
》commons-collections-3.1.jar
》commons-lang-2.5.jar
》commons-logging-1.1.1.jar
》ezmorph-1.0.3.jar
》json-lib-2.1-jdk15.jar
(1)JavaBean->JSON
》JSONArray jsonArray = JSONArray.fromObject(city);
》String jsonJAVA = jsonArray.toString();
(2)List<JavaBean>->JSON
》JSONArray jsonArray = JSONArray.fromObject(cityList);
》String jsonJAVA = jsonArray.toString();
(3)List<String>->JSON
》JSONArray jsonArray = JSONArray.fromObject(stringList);
》String jsonJAVA = jsonArray.toString();
(4)Map<String,Object>->JSON【重点】
List<User> userList = new ArrayList<User>();
userList.add(new User(100,"哈哈",1000));
userList.add(new User(200,"呵呵",2000));
userList.add(new User(300,"嘻嘻",3000)); Map<String,Object> map = new LinkedHashMap<String,Object>();
map.put("total",userList.size());
map.put("rows",userList); JSONArray jsonArray = JSONArray.fromObject(map);
String jsonJAVA = jsonArray.toString();
System.out.println(jsonJAVA); jsonJAVA = jsonJAVA.substring(1,jsonJAVA.length()-1);
System.out.println(jsonJAVA);
*****20 用JSON文本动态创建DataGrid
<table id="dg"></table>
$('#dg').datagrid({
url : 'data/datagrid_data.json',
columns:[[
{field:'code',title:'编号',width:100},
{field:'name',title:'姓名',width:100},
{field:'price',title:'薪水',width:100}
]]
});
*****21 用Servlet返回JSON文本动态创建DataGrid
<table id="dg"></table>
$('#dg').datagrid({
url : '/lucene-day02/JsonServlet',
columns:[[
{field:'code',title:'编号',width:100},
{field:'name',title:'姓名',width:100},
{field:'price',title:'薪水',width:100}
]]
});
Servlet:
public void doPost(HttpServletRequest request, HttpServletResponse response)
request.setCharacterEncoding("UTF-8"); Integer currPageNO = null;
try {
//DateGrid会向服务端传入page参数,表示第几页
currPageNO = Integer.parseInt(request.getParameter("page"));
} catch (Exception e) {
currPageNO = 1;
}
//DateGrid会向服务端传入rows参数,表示几条记录
//Integer rows = Integer.parseInt(request.getParameter("rows"));
//System.out.println(currPageNO+":"+rows); UserService userService = new UserService();
PageBean pageBean = userService.fy(currPageNO); Map<String,Object> map = new LinkedHashMap<String,Object>();
map.put("total",pageBean.getAllRecordNO());
map.put("rows",pageBean.getUserList()); JSONArray jsonArray = JSONArray.fromObject(map);
String jsonJAVA = jsonArray.toString();
jsonJAVA = jsonJAVA.substring(1,jsonJAVA.length()-1); System.out.println(jsonJAVA);
response.setContentType("text/html;charset=UTF-8");
response.getWriter().write(jsonJAVA);
response.getWriter().flush();
response.getWriter().close(); }
*****22 使用Jsp + Jquery + EasyUI+ Servlet + Lucene,完成分页二,异步分页
步一:创建ArticleDao.java类
public class ArticleDao {
public Integer getAllObjectNum(String keywords) throws Exception{
QueryParser queryParser = new QueryParser(LuceneUtil.getVersion(),"content",LuceneUtil.getAnalyzer());
Query query = queryParser.parse(keywords);
IndexSearcher indexSearcher = new IndexSearcher(LuceneUtil.getDirectory());
TopDocs topDocs = indexSearcher.search(query,3);
return topDocs.totalHits;
}
public List<Article> findAllObjectWithFY(String keywords,Integer start,Integer size) throws Exception{
List<Article> articleList = new ArrayList<Article>();
QueryParser queryParser = new QueryParser(LuceneUtil.getVersion(),"content",LuceneUtil.getAnalyzer());
Query query = queryParser.parse(keywords);
IndexSearcher indexSearcher = new IndexSearcher(LuceneUtil.getDirectory());
TopDocs topDocs = indexSearcher.search(query,100000000);
int middle = Math.min(start+size,topDocs.totalHits);
for(int i=start;i<middle;i++){
ScoreDoc scoreDoc = topDocs.scoreDocs[i];
int no = scoreDoc.doc;
Document document = indexSearcher.doc(no);
Article article = (Article) LuceneUtil.document2javabean(document,Article.class);
articleList.add(article);
}
return articleList;
}
}
步二:创建PageBean.java类
public class PageBean {
private Integer allObjectNum;
private Integer allPageNum;
private Integer currPageNum;
private Integer perPageNum = 2;
private List<Article> articleList = new ArrayList<Article>();
public PageBean(){}
public Integer getAllObjectNum() {
return allObjectNum;
}
public void setAllObjectNum(Integer allObjectNum) {
this.allObjectNum = allObjectNum;
if(this.allObjectNum % this.perPageNum == 0){
this.allPageNum = this.allObjectNum / this.perPageNum;
}else{
this.allPageNum = this.allObjectNum / this.perPageNum + 1;
}
}
public Integer getAllPageNum() {
return allPageNum;
}
public void setAllPageNum(Integer allPageNum) {
this.allPageNum = allPageNum;
}
public Integer getCurrPageNum() {
return currPageNum;
}
public void setCurrPageNum(Integer currPageNum) {
this.currPageNum = currPageNum;
}
public Integer getPerPageNum() {
return perPageNum;
}
public void setPerPageNum(Integer perPageNum) {
this.perPageNum = perPageNum;
}
public List<Article> getArticleList() {
return articleList;
}
public void setArticleList(List<Article> articleList) {
this.articleList = articleList;
}
}
步三:创建ArticleService.java类
public class ArticleService {
private ArticleDao articleDao = new ArticleDao();
public PageBean fy(String keywords,Integer currPageNum) throws Exception{
PageBean pageBean = new PageBean();
pageBean.setCurrPageNum(currPageNum);
Integer allObjectNum = articleDao.getAllObjectNum(keywords);
pageBean.setAllObjectNum(allObjectNum);
Integer size = pageBean.getPerPageNum();
Integer start = (pageBean.getCurrPageNum()-1) * size;
List<Article> articleList = articleDao.findAllObjectWithFY(keywords,start,size);
pageBean.setArticleList(articleList);
return pageBean;
}
}
步四:创建ArticleServlet.java类
public class UserServlet extends HttpServlet {
public void doPost(HttpServletRequest request, HttpServletResponse response)throws ServletException, IOException {
try {
//获取当前页号,默认1
String strCurrPageNO = request.getParameter("page");
if(strCurrPageNO == null){
strCurrPageNO = "1";
}
Integer currPageNO = Integer.parseInt(strCurrPageNO);
//获取关健字
String keywords = request.getParameter("keywords");
//创建业务对象
UserService userService = new UserService();
//调用业务层
PageBean pageBean = userService.fy(keywords,currPageNO);
//以下代码生成DateGrid需要的JSON文本
Map<String,Object> map = new LinkedHashMap<String,Object>();
//总记录数
map.put("total",pageBean.getAllRecordNO());
//该页显示的内容
map.put("rows",pageBean.getUserList());
JSONArray jsonArray = JSONArray.fromObject(map);
String jsonJAVA = jsonArray.toString();
jsonJAVA = jsonJAVA.substring(1,jsonJAVA.length()-1);
//以下代码是将json文本输出到浏览器给DateGrid组件
response.setContentType("text/html;charset=UTF-8");
response.getWriter().write(jsonJAVA);
response.getWriter().flush();
response.getWriter().close();
} catch (Exception e) {
}
}
}
步五:导入EasyUI相关的js包的目录

步六:在WebRoot目录下创建list.jsp
<%@ page language="java" pageEncoding="UTF-8"%>
<%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<link rel="stylesheet" href="themes/default/easyui.css" type="text/css"></link>
<link rel="stylesheet" href="themes/icon.css" type="text/css"></link>
<script type="text/javascript" src="js/jquery.min.js"></script>
<script type="text/javascript" src="js/jquery.easyui.min.js"></script>
<script type="text/javascript" src="locale/easyui-lang-zh_CN.js"></script>
</head> <body> 输入姓名关健字:
<input type="text" size="4px" id="name"/>
<input type="button" value="搜索" id="find"/> <table id="dg" style="width:500px"></table> <script type="text/javascript">
//定位"搜索"按钮,同时添加单击事件
$("#find").click(function(){
//获取用户名
var name = $("#name").val();
//去二边的空格
name = $.trim(name);
//加载最新数据
$("#dg").datagrid("load",{
"keywords" : name
});
});
</script> <script type="text/javascript">
//动态创建表格
$("#dg").datagrid({
url:'${pageContext.request.contextPath}/UserServlet?id=' + new Date().getTime(),
fitColumns : true,
singleSelect : true,
columns:[[
{field:'id',title:'编号',width:100,align:'center'},
{field:'name',title:'姓名',width:100,align:'center'},
{field:'sal',title:'薪水',width:100,align:'center'}
]],
pagination : true,
pageNumber : 1,
pageSize : 2,
pageList:[2]
});
</script> </body> </html>
-------------------------------------------------------------------------------------------------------
|
QueryParser queryParser = new |
java深入探究14-lucene的更多相关文章
- 2018面向对象程序设计(Java)第14周学习指导及要求
2018面向对象程序设计(Java)第14周学习指导及要求(2018.11.29-2018.12.2) 学习目标 (1) 掌握GUI布局管理器用法: (2) 掌握各类Java Swing组件用途及 ...
- Java 集合系列14之 Map总结(HashMap, Hashtable, TreeMap, WeakHashMap等使用场景)
概要 学完了Map的全部内容,我们再回头开开Map的框架图. 本章内容包括:第1部分 Map概括第2部分 HashMap和Hashtable异同第3部分 HashMap和WeakHashMap异同 转 ...
- Java 集合系列 14 hashCode
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Apache Solr采用Java开发、基于Lucene的全文搜索服务器
http://docs.spring.io/spring-data/solr/ 首先介绍一下solr: Apache Solr (读音: SOLer) 是一个开源.高性能.采用Java开发.基于Luc ...
- Java数据库设计14个技巧
Java数据库设计14个技巧 1. 原始单据与实体之间的关系 可以是一对一.一对多.多对多的关系.在一般情况下,它们是一对一的关系:即一张原始单据对应且只对应一个实体.在特殊情况下,它们可能是一对 ...
- JAVA自学笔记14
JAVA自学笔记14 1.正则表达式 1)是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串.其实就是一种规则.有自己的特殊应用 2)组成规则: 规则字符在java.util.rege ...
- 【Java】-NO.14.Java.4.Java.1.001-【Java JUnit 5 】-
1.0.0 Summary Tittle:[Java]-NO.14.Java.4.Java.1.001-[Java JUnit 5 ]- Style:Java Series:JUnit Since:2 ...
- Java设计模式(14)责任链模式(Chain of Responsibility模式)
Chain of Responsibility定义:Chain of Responsibility(CoR) 是用一系列类(classes)试图处理一个请求request,这些类之间是一个松散的耦合, ...
- 面向对象程序设计(JAVA) 第14周学习指导及要求
2019面向对象程序设计(Java)第14周学习指导及要求 (2019.11.29-2019.12.2) 学习目标 (1)掌握GUI布局管理器用法: (2)掌握Java Swing文本输入组件用途 ...
随机推荐
- Map Hashtable Hashmap 集合四
Map是通过键值对来唯一标识的,所以不能重复 存相同键值对 Hashtable存的是键值对 Hashtable<key,value> key,value 都不能为null 方法get(); ...
- java解析xml字符串为实体(dom4j解析)
package com.smsServer.Dhst; import java.util.HashMap; import java.util.Iterator; import java.util.Ma ...
- Android WebView-应用内嵌入浏览器
移动应用开发,web app.Native app的讨论已经很久了,纯粹的web app还很少,多少能见到Native + web混合的app,混合的app是在Native app中写一个浏览器加载 ...
- 巨蟒django之权限10,内容梳理&&权限组件应用
1.CRM项目内容梳理: 2.权限分配 3.权限组件的应用
- Linux 装JDK
1.查看当前系统有没有装jdk java -version 2.看看有没有安装包 rpm -qa | grep java 3.卸载OpenJDK $>rpm -e --nodeps tzdata ...
- /proc/kcore
[root@b proc]# ls -lh /proc/kcore-r-------- 1 root root 128T Sep 29 09:39 /proc/kcore[root@b proc]# ...
- 如何使用模板生成 sqlite3 sql 创建语句?
template<typename T,typename... Args> std::string createTable(T tableName,Args&&... ar ...
- 常用代码块:创建httpclient
HttpGet httpGet = new HttpGet(url); SSLContext sslcontext = SSLContexts.custom() .loadTrustMaterial( ...
- python函数补充
一 作用域 作用域介绍 python中的作用域分4种情况: L:local,局部作用域,即函数中定义的变量: E:enclosing,嵌套的父级函数的局部作用域,即包含此函数的上级函数的局 ...
- Kafka高可用的保证
zookeeper作为去中心化的集群模式,消费者需要知道现在那些生产者(对于消费者而言,kafka就是生产者)是可用的. 如果没有zookeeper每次消费者在消费之前都去尝试连接生产者测试下是 ...