zookeeper安装搭建
一 zookeeper介绍
因为要使用kafka,但是不想用kafka自带的,而且考虑到后面别的地方需要使用,比如分布式job,觉得独立的比较好。
zookeeper目前资料一大把,但是一是我需要锻炼写blog的能力,还有就是万一有一些别人没讲到的,给大家带来惊喜,岂不美哉。
zookeeper官方介绍:一个为分布式应用提供分布式协调的服务。
设计目标(Design Goals)
简单: zookeeper 允许通过一个共享层的namespace去相互协调,这个namespace的组织结构很像一个标准的文件系统。namespace是由叫做 znodes的数据项组成。在zookeeper说法中,和文件和文件目录有相似之处。不像一个典型文件系统,被设计用来存储。Zookeeper数据被保存在memory,另一个意思就是它可以实现高的生产力。zookeeper可以被使用在一个大规模分布式系统,而且在一个单元失败还是可以保持运行,在客户端实现了复杂同步能力。
zookeeper复制(ZooKeeper is replicated)
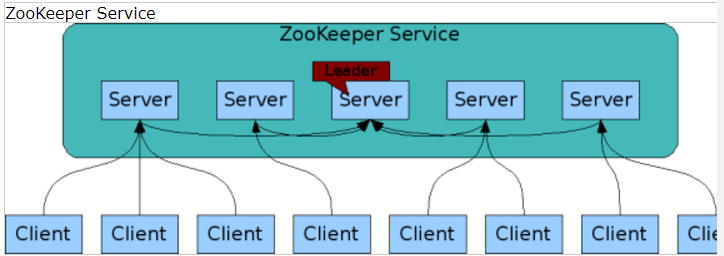
zookeeper通过一一套hosts去复制,名叫ensemble。支撑zookeeper服务的服务器,必须相互可以访问通。在一个持久存储中,他们保留一个在内存中的image状态,和一个事务日志和镜像在一起。
客户端连接一个单个zookeeper服务。客户端维护一个tcp连接,通过它发送请求,得到请求和watch events,和发送心跳包。如果一个tcp连接断掉,客户端将连接另外一个服务。
zookeeper是有秩序的(ZooKeeper is ordered)
zookeeper的每一个印记更新一个数字,反映了全部zookeeper事务的秩序。后面的操作能使用这个秩序去实现高级别的抽象,正如同步。
zookeeper是高速的(ZooKeeper is fast)
在读占优势负载中它是尤其的快。zookeeper应用运行在上千的机器上,而且它工作最好的情况下是读通常比写多,比率是大约10:1
数据模型和命名层(Data model and the hierarchical namespace)
命名空间很像一个独立的文件系统。一个名字是一个被slash(/)分割的路径元素序列。每一个节点在在zookeeper的命名空间中被标志为一个路径来使用
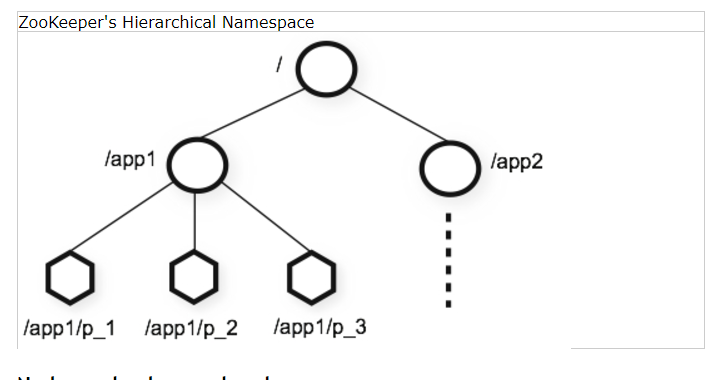
节点和临时节点(Nodes and ephemeral nodes)
不像一个标准的文件系统,每个节点在一个zookeeper命名空间中能有数据关联,这个命名空间同样有子节点。它是像一文件系统允许一个文件也可以是一个目录。(zookeeper被设计去存储协调数据:状态信息,配置,位置信息等,因此存储数据在每一个节点通常是小的,在1byte到kb的范围吧)我们使用term znode去让 我们正在讨论的 的zookeeper数据节点更清楚。
znodes维护一个状体结构,包含了版本号为每一个数据更改,ACL更改,和时间戳去允许缓存验证和协调更新。每次一个znode的数据更改,版本号自增。比如一个实例,,无论何时一个客户端检索数据,它总是接受一个版本的数据。
在一个namespace中存储在每一个节点的数据,是原子的读和写。读获取关联一个znode的全部数据,一个写替换全部数据。每个节点有一个访问控制列表(ACL)限制谁能做那些。
zookeeper也有一个临时node的概念。这些znodes与创建这些znodes的session存在一样久。如果session结束,znode就删除。
协调更新和watches(Conditional updates and watches)
zookeeper支持watches的思想。客户端能设置一个watch在一个znodes。znode更改的时候,一个watch将被triggered和移除。一个watch被激发,客户端接收一个packet,说znode已经更改。然后如果在一个服务到客户端的连接被破坏,客户端将接受一个本地通知。
Guarantees
zookeeper是一个非常快和非常简单的,自从它的目标,虽然,是计划作为一个基本为一个更复杂服务结构,正如同步。它实现一套保证。
1 时序一致,从一个客户端的更新被应用在一个先来后到的秩序上
2 原子,更新或者成功,或者失败
3 单个系统image,不管服务连接的是那个服务器,对客户端来说看到的都是相同景象。
4 可靠,一旦一个更新已经被应用,它将持续从那个时间直到一个客户端覆盖更新它。
5 及时,客户端系统的面貌被担保是在某个时间界限中是最新的。
Simple API
create 创建一个znode
delete 删除一个node
exists 测试一个node是否在一个位置存在
get 从一个node读取数据
set 写一个data去一个node
get children 检索一个node的子项的列表
sync 等待数据去被传播
实现(Implementation)
zookeeper组件展示zookeeper服务的较高层面的成分。每一个组成zookeeper服务的服务器复制它自己每一个componets的copy。
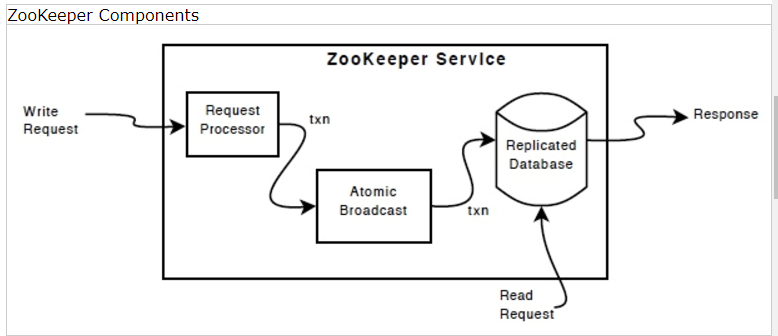
复制数据库是一个内存数据库,包含整个数据树。更新记录日志在硬盘为了恢复。然后写是序列化到硬盘,在他们应用到内存前。
每一个zookeeper服务器服务客户端。客户端准确连接到一个服务器去提交请求。读请求从每个服务器数据库的本地复制中提供服务,写请求被一个一致性协议处理,
从客户端的全部写请求一致性协议部分,被趋向一个单个的服务器,名叫leader。其余的,叫followers,从leader接受消息提议和商定传递消息。消息层处理失败替换leader和同步followers和leaders。
二 zookeeper使用
下载:http://mirrors.shu.edu.cn/apache/zookeeper/zookeeper-3.4.13/
wget http://mirrors.shu.edu.cn/apache/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz
看看目录:

首先看配置文件conf/zoo.cfg:
tickTime=
dataDir=/var/lib/zookeeper
clientPort=
- tickTime
- 微妙为基本单位,它被使用作为heartbeats和最低限度的session超时,超市将是两次ticktime。
- dataDir
- 存储内存数据库镜像,除非指定了其他,对数据库更新的事务日志
- clientPort
-
监听端口
我们创建一个cfg文件,然后将上面的配置写入,然后现在可以启动:

然后去连接:
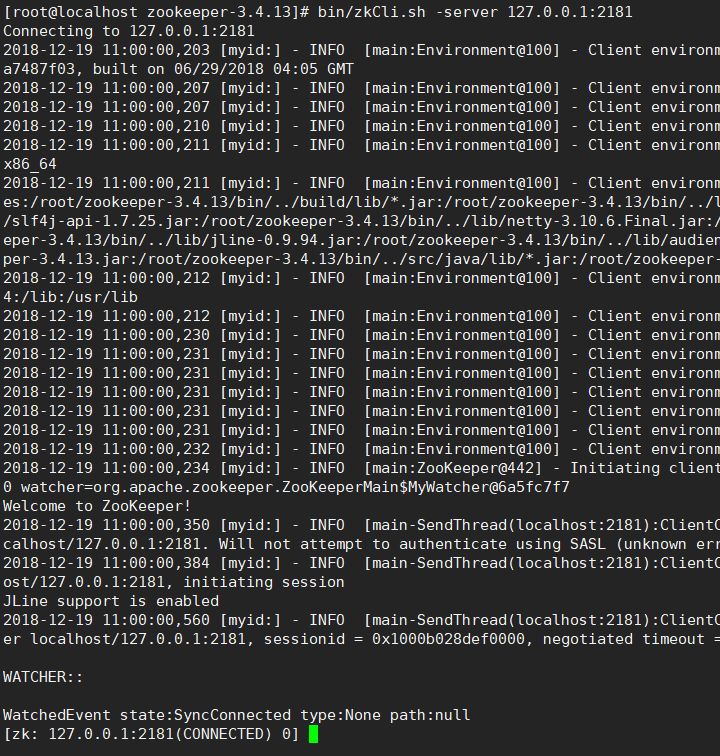
bin/zkCli.sh -server 127.0.0.1:
这样的结果证明连接成功
使用help去查询命令:
命令自己去玩吧,这个必须实践,接下来去看看zookeeper的复制
Running Replicated ZooKeeper
运行zookeeper在一个单独的模式下对于开发测试是很方便的,但是生产环境,你是运行在一个复制mode下的,一个服务器复制组在相同的应用,叫做quorum,而且再复制模式,全部服务器在quorum有相同的配置文件。
注意:对于复制模式,需要最少3个服务器,强烈推荐服务器数量是奇数。
下面是复制模式的配置:
tickTime=
dataDir=/var/lib/zookeeper
clientPort=
initLimit=
syncLimit=
server.=zoo1::
server.=zoo2::
server.=zoo3::initLimit:新的入口,是用于针对过时,zookeeper用来限制在quorum去连接一个leader的时间长度。
syncLimit:限制一个服务从一个leader多大的成都过时。
如果你指定了一个tickTime,在如上例子中,那么超时就是10秒。
而正server.x,当服务启动,它知道那个服务被查找文件myid在data目录。那个文件包含这服务的编号。
zookeeper安装搭建的更多相关文章
- CentOS安装搭建zookeeper
原文连接:https://www.cnblogs.com/rwxwsblog/p/5806075.html zookeeper集群搭建(三台) 注意关闭机器防火墙! 配置ip别名:编辑文件 # /e ...
- zookeeper安装与集群搭建
此处以centos系统下zookeeper安装为例,详细步骤可参考官网文档:zookeeper教程 一.单节点部署 1.下载zookeeper wget http://mirrors.hust.edu ...
- 3.Hadoop集群搭建之Zookeeper安装
前期准备 下载Zookeeper 3.4.5 若无特殊说明,则以下操作均在master节点上进行 1. 解压Zookeeper #直接解压Zookeeper压缩包 tar -zxvf zookeepe ...
- hadoop2.6.2+hbase+zookeeper环境搭建
1.hadoop环境搭建,版本:2.6.2,参考:http://www.cnblogs.com/bookwed/p/5251393.html 启动服务:在master机器上,进入hadoop安装目录, ...
- ZooKeeper学习第二期--ZooKeeper安装配置
一.Zookeeper的搭建方式 Zookeeper安装方式有三种,单机模式和集群模式以及伪集群模式. ■ 单机模式:Zookeeper只运行在一台服务器上,适合测试环境:■ 伪集群模式:就是在一台物 ...
- 真分布式SolrCloud+Zookeeper+tomcat搭建、索引Mysql数据库、IK中文分词器配置以及web项目中solr的应用(1)
版权声明:本文为博主原创文章,转载请注明本文地址.http://www.cnblogs.com/o0Iris0o/p/5813856.html 内容介绍: 真分布式SolrCloud+Zookeepe ...
- zookeeper环境搭建及使用
本文只讲解搭建步骤,先不讲原理相关知识 一.zookeeper下载地址 本文使用版本为zookeeper-3.4.10.tar.gz 地址:http://mirrors.shuosc.org/apac ...
- zookeeper安装以及遇到的一些坑
最近项目中用到了storm,然后storm中用到了zookeeper,然后今天抽空整理一下zookeeper的安装使用,原来后期再慢慢学习. 本篇文档,操作部分是摘自其他博客,里边的问题分析是自己在实 ...
- Zookeeper系列一:Zookeeper介绍、Zookeeper安装配置、ZK Shell的使用
https://www.cnblogs.com/leeSmall/p/9563547.html 一.Zookeeper介绍 1. 介绍Zookeeper之前先来介绍一下分布式 1.1 分布式主要是下面 ...
随机推荐
- Nginx反向代理+负载均衡简单实现
一.基础环境: 负 载 机:A机器: 192.168.71.223后端机器1:B机器:192.168.71.224后端机器2:C机器:192.168.71.226 需求: 1)访问A机器的808 ...
- iOS 设置 延迟执行 与 取消延迟执行 方法 以及对 run loop 初步认识
之前开发过程中经常会有需求会使用 NSObject中的"performSelector:withObject:afterDelay:"做方法延迟执行的处理, 但是 还没有什么地方需 ...
- hostname -f 失败解决办法
$ hostname fzk $ uname -n fzk 当 hostname -f 时报错:未搜索到主机名 产生这个原因时因为 /etc/hosts和/etc/sysconfig/network ...
- linux中安装软件的集中方法
一.rpm包安装方式步骤: 引用:1.找到相应的软件包,比如soft.version.rpm,下载到本机某个目录:2.打开一个终端,su -成root用户:3.cd soft.version.rpm所 ...
- mybatis collection 一对多关联查询,单边分页的问题总结!
若想直接通过sql实现多级关联查询表结构得有2 个必不可少的字段:id ,parentId,levelId id:主键id, parentId:父id levelId:表示第几级(表本身关联查询的时候 ...
- debian内核代码执行流程(三)
接续<debian内核代码执行流程(二)>未完成部分 下面这行输出信息是启动udevd进程产生的输出信息: [ ]: starting version 175是udevd的版本号. 根据& ...
- [Android]开源中国源码分析之一---启动界面
开源中国android端版本号:2.4 启动界面: 在AndroidManifest.xml中找到程序的入口, <activity android:name=".AppStart&qu ...
- poj 1330 【最近公共祖先问题+fa[]数组+ 节点层次搜索标记】
题目地址:http://poj.org/problem?id=1330 Sample Input 2 16 1 14 8 5 10 16 5 9 4 6 8 4 4 10 1 13 6 15 10 1 ...
- Luogu-3346 [ZJOI2015]诸神眷顾的幻想乡
\(trie\)树建广义后缀自动机: \(dfs\)遍历\(trie\)树,将树上的一个节点插入\(sam\)时,将他的\(fa\)在\(sam\)上所在的节点作为\(last\) #include& ...
- vue-cli入门之项目结构分析
一个vue-cli的项目结构如下,其中src文件夹是需要掌握的,所以本文也重点讲解其中的文件,至于其他相关文件,了解一下即可. 文件结构细分 1.build——[webpack配置] build文件主 ...