Tair分布式缓存
淘宝缓存架构
开源地址
Tair简介
Tair总体结构


Tair 的负载均衡算法
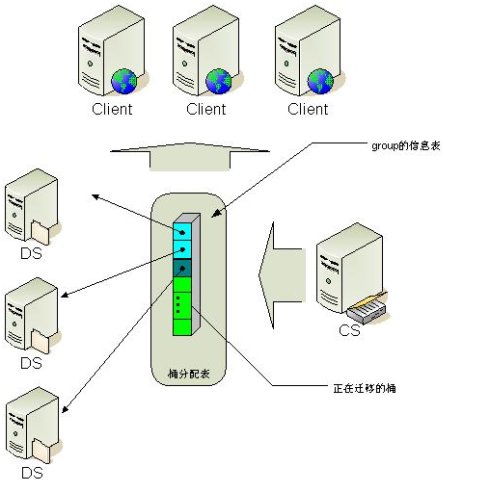
增加或者减少data server的时候会发生什么
发生迁移的时候data server如何对外提供服务
桶在data server上分布时候的策略
Tair 的一致性和可靠性问题
参考博客
Tair分布式缓存的更多相关文章
- Tair分布式key/value存储
[http://www.lvtao.net/database/tair.html](特别详细) tair 是淘宝自己开发的一个分布式 key/value 存储引擎. tair 分为持久化和非持久化 ...
- Tair 分布式K-V存储方案
tair 是淘宝的一个开源项目,它是一个分布式的key/value结构数据的解决方案. 作为一个分布式系统,Tair由一个中心控制节点(config server)和一系列的服务节点(data ser ...
- 阿里云分布式缓存OCS与DB之间的数据一致性
[分布式系统的数据一致性问题] OCS概要介绍 据AlertSite网络分析公司表示,Facebook的响应时间在2010年平均为1秒钟,到2011年中期已提高到了0.73秒.对比来看,响应时间占 ...
- .net 分布式架构之分布式缓存中间件
开源git地址: http://git.oschina.net/chejiangyi/XXF.BaseService.DistributedCache 分布式缓存中间件 方便实现缓存的分布式,集群, ...
- CRL快速开发框架系列教程六(分布式缓存解决方案)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
- 一个技术汪的开源梦 —— 公共组件缓存之分布式缓存 Redis 实现篇
Redis 安装 & 配置 本测试环境将在 CentOS 7 x64 上安装最新版本的 Redis. 1. 运行以下命令安装 Redis $ wget http://download.redi ...
- ASP.Net MVC4+Memcached+CodeFirst实现分布式缓存
ASP.Net MVC4+Memcached+CodeFirst实现分布式缓存 part 1:给我点时间,允许我感慨一下2016年 正好有时间,总结一下最近使用的一些技术,也算是为2016年画上一个完 ...
- CYQ.Data V5 分布式缓存Redis应用开发及实现算法原理介绍
前言: 自从CYQ.Data框架出了数据库读写分离.分布式缓存MemCache.自动缓存等大功能之后,就进入了频繁的细节打磨优化阶段. 从以下的更新列表就可以看出来了,3个月更新了100条次功能: 3 ...
- CYQ.Data V5 分布式缓存MemCached应用开发介绍
前言 今天大伙还在热议关于.NET Core的东西,我只想说一句:在.NET 跨平台叫了这么多年间,其实人们期待的是一个知名的跨平台案例,而不是一堆能跨平台的消息. 好,回头说说框架: 在框架完成数据 ...
随机推荐
- 【转】虚拟 IO 服务器(VIOS)和 IBM i
Power 主机上的虚拟化应用,简单阐述虚拟 IO 服务器的功能,用途,优点,以及虚拟 IO 服务器在高级虚拟化技术的作用.举例说明虚拟 IO 服务器与 IBM i 分区直接互联特性. 引言 随着信息 ...
- How To Surf The Internet In Right Ways
本文偏指导性质,具体实现自行探索~~ 科普 如何***既然想学点东西,就不能被网络束缚住.国内的网络环境,对于外面世界探索还是挺限制的. 什么是墙GFW(great firewall) 中国特有的.就 ...
- random模块一些常用的东西
import random#一.随机小数# (1)大于0且小于1之间的小数print(random.random())# (2)大于1且小于9之间的小数print(random.uniform(0,9 ...
- 前端框架之jQuery
一 iQuery是什么 jQuery由美国人John Resig创建,至今已吸引了来自世界各地的众多 javascript高手加入其team jQuery是继prototype之后又一个优秀的Java ...
- Spring学习笔记5—为Spring添加REST功能
1 关于REST 我的理解,REST就是将资源以最合适的形式在服务端和客户端之间传递. 系统中资源采用URL进行标识(可以理解为URL路径中带参数) 使用HTTP方法进行资源的管理(GET,PUT,P ...
- BADI:LE_SHP_DELIVERY_PROC-增强在交货处理中
1.所得方法清单: CHANGE_FCODE_ATTRIBUTES Control Activation of Function CodesCHANGE_FIELD_ATTRIBUTES Contro ...
- 剑指offer 面试10题
面试10题: 题目:大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项.n<=39 n=0时,f(n)=0 n=1时,f(n)=1 n>1时,f(n)=f(n-1 ...
- 剑指offer 面试33题
面试33题:题:二叉搜索树的后序遍历序列 题目:输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果.如果是则输出Yes,否则输出No.假设输入的数组的任意两个数字都互不相同. 解题思路:递 ...
- XML和解析
XML和解析 1.什么是XML?Extensible Markup Language,可扩展标记语言.一般也叫XML文档.和JSON一样,也是常用的一种用于交互的数据格式. 2.XML语法1)一个常见 ...
- MySQL数据库(2)_MySQL数据库和数据库表操作语句
一.关于数据库操作的sql语句 -- .创建数据库(在磁盘上创建一个对应的文件夹) create database [if not exists] db_name [character set xxx ...