Scrapy 增量式爬虫
Scrapy 增量式爬虫
https://blog.csdn.net/mygodit/article/details/83931009
https://blog.csdn.net/mygodit/article/details/83896412
https://blog.csdn.net/qq_39965716/article/details/81073015
一、定义
二、原理
spider构造的第一个Request请求经由引擎交给了Scheduler,Scheduler中构造一个request对象,并将这个对象存入一个Scheduler的队列中,入队之前会生成一个对应的,唯一的指纹,下一个request对象入队之前,会先比对指纹是否已经存在,以此来达到request对象去重的目的。
Scheduler中Request对象的初始化属性,其中dont_filter表示不去重,默认是False。所以scrapy框架默认是去重的。
class Request(object_ref):
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None):
Rquest
爬虫组件Spider中,负责构造request对象是 start_requests(self) 函数。Spider构造的request对象修改了dont_filter属性。
源码如下:
def start_requests(self):
cls = self.__class__
if method_is_overridden(cls, Spider, 'make_requests_from_url'):
warnings.warn(
"Spider.make_requests_from_url method is deprecated; it "
"won't be called in future Scrapy releases. Please "
"override Spider.start_requests method instead (see %s.%s)." % (
cls.__module__, cls.__name__
),
)
for url in self.start_urls:
yield self.make_requests_from_url(url)
else:
for url in self.start_urls:
yield Request(url, dont_filter=True)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Scrapy去重的原理
Scrapy去重原理是通过sha1()加密request对象的url,method,body属性生成一个十六进制的40位随机字符串,称为指纹。将每个request对象对应的唯一指纹保存到Scheduler队列中,下次请求时,通过对比指纹,来达到request对象去重的目的。
生成指纹集合的源码如下:
def request_fingerprint(request, include_headers=None):
if include_headers:
include_headers = tuple(to_bytes(h.lower())
for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
if include_headers not in cache:
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[include_headers] = fp.hexdigest()
return cache[include_headers]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
存储在Scheduler中的reqeust队列,是放在内存上的,如果服务器关闭,或者重启,内存中的缓存就会清空,下次请求就会继续访问原来发送过的请求。
增量式爬虫的意义就是将reques队列持久化存储,以此来达到永久性的缓存。
对此需要用到scrapy_redis(需要pip install scarpy_redis),将request对象的队列和指纹集合存储的位置替换成redis。如下图所示:
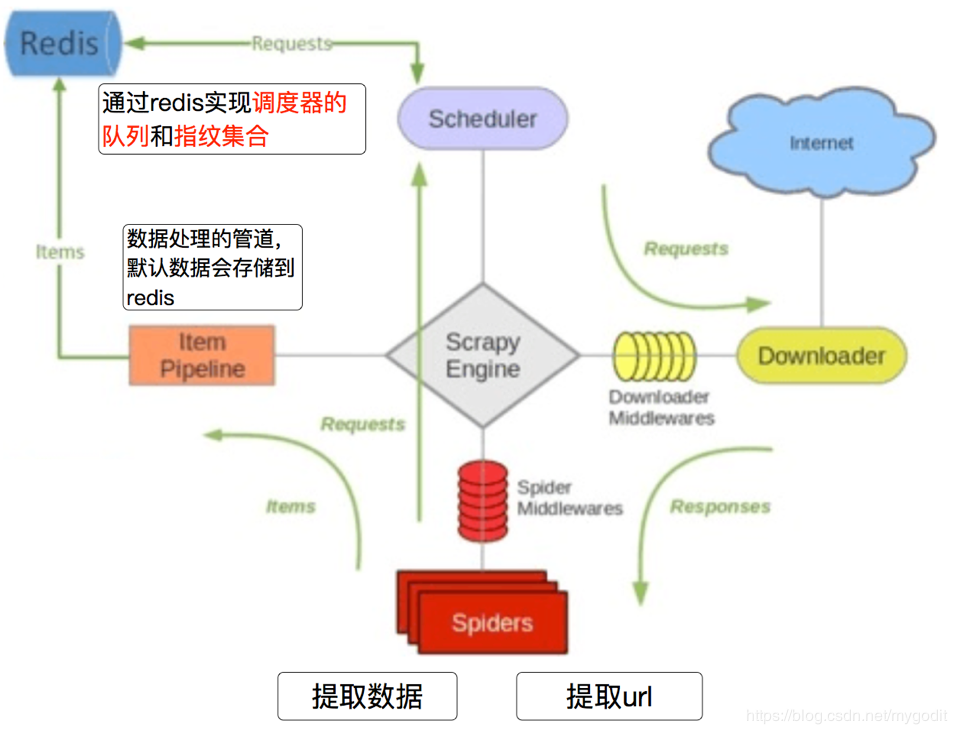
只需要在settings.py文件中添加一些配置,就能实现持久化去重的效果:
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True # 添加redis链接
REDIS_URL = "redis://127.0.0.1:6379" # 或者使用下面的方式
# REDIS_HOST = "127.0.0.1"
# REDIS_PORT = 6379 # 在pipeline中添加存储信息的scrapy_redis管道
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400,
}
Scrapy 增量式爬虫的更多相关文章
- 基于Scrapy框架的增量式爬虫
概述 概念:监测 核心技术:去重 基于 redis 的一个去重 适合使用增量式的网站: 基于深度爬取的 对爬取过的页面url进行一个记录(记录表) 基于非深度爬取的 记录表:爬取过的数据对应的数据指纹 ...
- 增量式爬虫 Scrapy-Rredis 详解及案例
1.创建scrapy项目命令 scrapy startproject myproject 2.在项目中创建一个新的spider文件命令: scrapy genspider mydomain mydom ...
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
- 爬虫---scrapy分布式和增量式
分布式 概念: 需要搭建一个分布式的机群, 然后在每一台电脑中执行同一组程序, 让其对某一网站的数据进行联合分布爬取. 原生的scrapy框架不能实现分布式的原因 调度器不能被共享, 管道也不能被共享 ...
- 爬虫 crawlSpider 分布式 增量式 提高效率
crawlSpider 作用:为了方便提取页面整个链接url,不必使用创参寻找url,通过拉链提取器,将start_urls的全部符合规则的URL地址全部取出 使用:创建文件scrapy startp ...
- python爬虫---CrawlSpider实现的全站数据的爬取,分布式,增量式,所有的反爬机制
CrawlSpider实现的全站数据的爬取 新建一个工程 cd 工程 创建爬虫文件:scrapy genspider -t crawl spiderName www.xxx.com 连接提取器Link ...
- Scrapy 框架 增量式
增量式: 用来检测网站中数据的更新情况 from scrapy.linkextractors import LinkExtractor from scrapy.spiders import Crawl ...
- [开源 .NET 跨平台 数据采集 爬虫框架: DotnetSpider] [三] 配置式爬虫
[DotnetSpider 系列目录] 一.初衷与架构设计 二.基本使用 三.配置式爬虫 四.JSON数据解析与配置系统 上一篇介绍的基本的使用方式,虽然自由度很高,但是编写的代码相对还是挺多.于是框 ...
- 增量式PID计算公式4个疑问与理解
一开始见到PID计算公式时总是疑问为什么是那样子?为了理解那几道公式,当时将其未简化前的公式“活生生”地算了一遍,现在想来,这样的演算过程固然有助于理解,但假如一开始就带着对疑问的答案已有一定看法后再 ...
随机推荐
- hibernate缓存机制详细介绍
hibernate的缓存机制,包括一级缓存(session级别).二级缓存(sessionFactory级别). 一:hibernate的 N+1问题 list()获得对象: 如果通过list()方法 ...
- 一种js异步处理方式
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- SQL Server专题
SQL Server 2005/2008 一.连接异常 在C#代码中调用Open()方法打开数据库连接时(账户为sa),出现异常:异常信息如下: 在与 SQL Server 建立连接时出现与网络相关的 ...
- javascript原型继承中的两种方法对比
在实际的项目中,我们通常都是用构造函数来创建一个对象,再将一些常用的方法添加到其原型对象上.最后要么直接实例化该对象,要么将它作为父类,再申明一个对象,继承该父类. 而在继承的时候有两种常用方式,今天 ...
- 场景中,并没有灯源的存在,但是cube却会有灯光照射的反应,这就是Light Probe Group的作用。
http://blog.csdn.net/qq617119142/article/details/41674755
- java代码优化29个点
通过java代码规范来优化程序,优化内存使用情况,防止内存泄露 可供程序利用的资源(内存.CPU时间.网络带宽等)是有限的,优化的目的就是让程序用尽可能少的资源完成预定的任务.优化通常包含两方面的内容 ...
- AOP基本概念、AOP底层实现原理、AOP经典应用【事务管理、异常日志处理、方法审计】
1 什么是AOP AOP为Aspect Oriented Programming的缩写,意为:面向切面编程,通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术.AOP是OOP的延续,是软件 ...
- 409. Longest Palindrome 最长对称串
[抄题]: Given a string which consists of lowercase or uppercase letters, find the length of the longes ...
- coordinatewise 是什么意思?
As far as I remember, in the context of optimization, "coordinate wise" means that you are ...
- Luogu 2403 [SDOI2010]所驼门王的宝藏
BZOJ 1924 内存要算准,我MLE了两次. 建立$n + r + c$个点,对于一个点$i$的坐标为$(x, y)$,连边$(n + x, i)$和$(n + r + y, i)$,代表这一列和 ...