CPU拓扑结构
本篇旨在认识一下以下三种CPU拓扑结构分别是什么:
- Symmetric multiprocessing (SMP)
- Non-uniform memory access (NUMA)
- Simultaneous Multi-Threading (SMT)
Symmetric multiprocessing (SMP)
对称多处理(英语:Symmetric multiprocessing,缩写为SMP),也译为均衡多处理、对称性多重处理,是一种多处理器的电脑硬件架构,在对称多处理架构下,每个处理器的地位都是平等的,对资源的使用权限相同。现代多数的多处理器系统,都采用对称多处理架构,也被称为对称多处理系统(Symmetric multiprocessing system),其组织方式如下图所示:
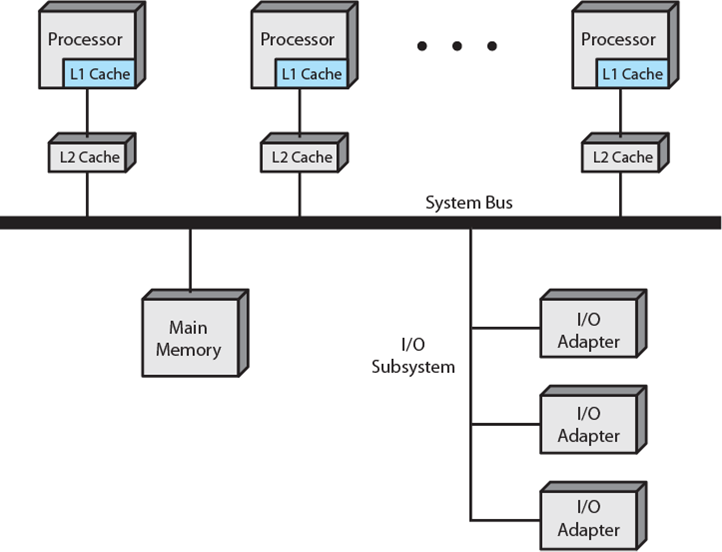
每个处理器都有自己的L1缓存,共享L2缓存,通过某种互联方式(如系统总线)共享资源如内存和IO。
Non-uniform memory access (NUMA)
是什么
非统一内存访问架构(英语:Non-uniform memory access,简称NUMA),是在许多multi-sockets系统中SMP设计的衍生品——CPU规模因摩尔定律指数级发展,而总线发展缓慢,导致多核CPU通过一条总线共享内存成为瓶颈,NUMA的出现,使得CPU平均划分为若干个Chip(不多于4个),每个Chip有自己的内存控制器及内存插槽,CPU访问自己Chip上所插的内存时速度快,而访问其他CPU所关联的内存(下文称Remote Access)的速度较慢,如下图所示:
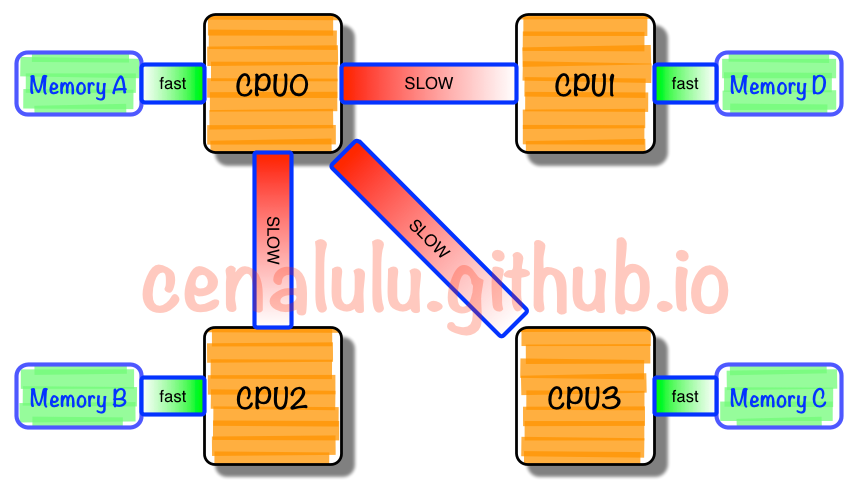
NUMA相关的几个概念有node、socket、core和thread,先来一张示意图:

- Socket是一个物理上的概念,指的是主板上的cpu插槽
- Node是一个逻辑上的概念,上图中没有提及。由于SMP体系中各个CPU访问内存只能通过单一的通道,导致内存访问成为瓶颈,cpu再多也无用。后来引入了NUMA,通过划分node,每个node有本地RAM,这样node内访问RAM速度会非常快。但跨Node的RAM访问代价会相对高一点
- Core就是一个物理cpu,一个独立的硬件执行单元,比如寄存器,计算单元等
- Thread就是超线程(HyperThreading)的概念,是一个逻辑cpu,共享core上的执行单元
下面是SMP和NUMA的对比图:

由此可以总结这样的逻辑关系(包含):Node > Socket > Core > Thread
查看CPU信息
常用的方式是lscpu和numactl:
[root@10e131e69e15 ~]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E5-2630 v3 @ 2.40GHz
Stepping: 2
CPU MHz: 1712.343
BogoMIPS: 4793.31
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 20480K
NUMA node0 CPU(s): 0-7,16-23
NUMA node1 CPU(s): 8-15,24-31
可以看到,我们172.28.8.15的物理机上一共有两颗CPU(Sockets:2),每颗CPU 8核(Cores per socket:8),每一个核是双线程(Threads per core:2),所以一共2*8*2 = 32个processor。此外可以看到当前是NUMA架构,node0包含第0-7,16-23个的CPU,node1包含第8-15,24-31个CPU。我们还可以使用numactl -H或numactl --hardware查看NUMA信息:
[root@10e131e69e15 ~]# numactl -H
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 16 17 18 19 20 21 22 23
node 0 size: 32652 MB
node 0 free: 280 MB
node 1 cpus: 8 9 10 11 12 13 14 15 24 25 26 27 28 29 30 31
node 1 size: 32768 MB
node 1 free: 64 MB
node distances:
node 0 1
0: 10 21
1: 21 10
一共两个node,每个node32G内存。注意,因为我们开启了HyperThreading,所以两个node上的CPU并不是连续的,绑定时避免绑定到兄弟核上。
如果是非NUMA架构,则所有的cpu都划分到一个node中,如:
[root@f-packstack-q ~(keystone_admin)]# numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1 2 3
node 0 size: 8095 MB
node 0 free: 555 MB
node distances:
node 0
0: 10
注:在OpenStack中,SMP CPU被称为cores(核心),NUMA单元或节点被称为sockets(套接字),而SMT CPU被称为thread(线程)。例如,带有HyperThreading(超线程技术)的四sockets八cores系统将有四个sockets,每个socket八个内核,每个内核两个线程,共64个(逻辑)CPU。
Simultaneous Multi-Threading (SMT)
同步多线程(英语:Symmetric multithreading,缩写为SMT)是一种在一个CPU 的时钟周期内能够执行来自多个线程的指令的硬件多线程技术。本质上,同步多线程是一种将线程级并行处理(多CPU)转化为指令级并行处理(同一CPU)的方法。

SMT是与SMP相辅相成的设计。尽管SMP系统中的CPU共享总线和一些内存,但SMT系统中的CPU共享更多的组件。共享组件的CPU称为线程同级。所有CPU在系统上都显示为可用的CPU,并可以并行执行工作负载。但是,与NUMA一样,线程竞争共享资源。
Reference
[1].Cpu bindings (一) 理解cpu topology
[2].NUMA架构的CPU -- 你真的用好了么?
[3].NUMA体系结构详解
[4].CPU topologies - OpenStack
CPU拓扑结构的更多相关文章
- Linux CPU Hotplug CPU热插拔
http://blog.chinaunix.net/uid-15007890-id-106930.html CPU hotplug Support in Linux(tm) Kernel Linu ...
- OpenStack 企业私有云的若干需求(9): 云管理平台 CMP
本系列会介绍OpenStack 企业私有云的几个需求: 自动扩展(Auto-scaling)支持 多租户和租户隔离 (multi-tenancy and tenancy isolation) 混合云( ...
- 查看CPU/CACHE的拓扑结构
转自 http://smilejay.com/2017/12/cpu-cache-topology/ Linux上,CPU和Cache相关的拓扑结构,都可以从sysfs文件系统的目录 /sys/dev ...
- dom0的cpu hotplug【续】
上一篇说到,手动xm vcpu-pin住,在hotplug就好了. 本质上,还是因为代码有bug,导致vcpu offline的时候,信息没有清理干净,有残留,当vcpu online的时候,如果调度 ...
- STORM在线业务实践-集群空闲CPU飙高问题排查
源:http://daiwa.ninja/index.php/2015/07/18/storm-cpu-overload/ 2015-07-18AUTHORDAIWA STORM在线业务实践-集群空闲 ...
- STORM在线业务实践-集群空闲CPU飙高问题排查(转)
最近将公司的在线业务迁移到Storm集群上,上线后遇到低峰期CPU耗费严重的情况.在解决问题的过程中深入了解了storm的内部实现原理,并且解决了一个storm0.9-0.10版本一直存在的严重bug ...
- 【转载】HTTP Session 内存到内存复制的拓扑结构
http://www.oschina.net/question/129540_23215 HTTP 协议本身是“连接 - 请求 - 应答 - 关闭连接”的模式,是一种无状态协议:然而随着 web 动态 ...
- 【翻译】借助 NeoCPU 在 CPU 上进行 CNN 模型推理优化
本文翻译自 Yizhi Liu, Yao Wang, Ruofei Yu.. 的 "Optimizing CNN Model Inference on CPUs" 原文链接: h ...
- CPU/GPU/TPU/NPU...XPU都是什么意思?
CPU/GPU/TPU/NPU...XPU都是什么意思? 现在这年代,技术日新月异,物联网.人工智能.深度学习等概念遍地开花,各类芯片名词GPU, TPU, NPU,DPU层出不穷......都是什么 ...
随机推荐
- mysql复制表数据,多表数据复制到一张表
对于mysql 复制表数据可以使用 insert into select 方式 示例: $sql="insert into icarzoo.provider(providerId,provi ...
- 关于css透明度的问题
先看background和background-color background:可以设置背景颜色,背景图片,还有定位.默认background:no-repeat; background-color ...
- 轻量ORM-SqlRepoEx (三)Select语句
一.示例用数据库为Northwind数据库,可在百度网盘下载 https://pan.baidu.com/s/1er0Mm48kUfeAsYkSW6DfnA 密码:r7pm 二.如何初始化SqlRep ...
- Angularjs基础(九)
AngularJS 应用应用程序讲解 实例: <html ng-app="myNoteApp"> <head> <meat charset=" ...
- ES6 async await
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 转载:EJB到底是什么
这篇博客用通俗易懂的语言对EJB进行了介绍,写得很好,笔者在这里转载一下. 链接:https://www.cnblogs.com/strugglion/p/6027318.html
- ubuntu部署kubeadm1.13.1高可用
kubeadm的主要特性已经GA了,网上看很多人说1.13有bug在1.13.1进行的更新,具体我也没怎么看,有兴趣的朋友可以查查,不过既然有人提到了我们就不要再去踩雷了,就用现在的1.13.1来部署 ...
- linux命令之磁盘和文件系统操作
1. fdisk:磁盘分区命令 语法:fdisk [选项][参数] 命令说明:fdisk是linux系统里常用的一种磁盘管理工具,可以创建和管理系统分区 常用命令选项: -l:列出指定的并退出,没 ...
- 配置Echarts大全
由于项目中需要用到Echarts,最近研究了一个星期.网上的教程也挺多的.磕磕碰碰的,难找到合适的例子.都说的马马虎虎.不废话了.开始. 这种上下排列的... 还有这种地图的.(如下) 还有就是配置的 ...
- 三、css篇
#这里强烈推荐一本书<css世界>,css第一书. #上面的层叠顺序得记住. 1.align-items justify-content 是flex(弹性盒模型)必须要会的属性,alig ...