$python正则表达式系列(2)——re模块常用函数
本文主要介绍正则re模块的常用函数。
1. 编译正则
import re
p = re.compile(r'ab*')
print '【Output】'
print type(p)
print p
print p.findall('abbc')
【Output】
<type '_sre.SRE_Pattern'>
<_sre.SRE_Pattern object at 0x7fe4783c7b58>
['abb']
正则编译的好处:速度更快。
2. re模块常用函数和方法
1. 不区分大小写匹配
p = re.compile(r'ab*',re.I)
print '【Output】'
print p.findall('AbBbc')
【Output】
['AbBb']
2. 字符串前加"r",反斜杠""就不会被作任何特殊处理
即:如果字符串前带"r",表示这是一个正则字符串,字符串里面用到的需要表示转义用途的""不用使用双重转义。
s = 'a+++'
p1 = re.compile('\++')
p2 = re.compile('\\++')
p3 = re.compile(r'\++')
# p4 = re.compile(r'\\++')
print '【Output】'
print p1.findall(s)
print p2.findall(s)
print p3.findall(s)
# print p4.findall(s)
# 用p4来匹配会报错:error: multiple repeat
【Output】
['+++']
['+++']
['+++']
3. 两个匹配函数
match():判断正则是否在字符串开始位置出现。
search():判断正则是否在字符串任何位置出现。
p = re.compile(r'aa')
print '【Output】'
print p.match('aabcd')
print p.match('bcaad')
print p.search('bcaad')
【Output】
<_sre.SRE_Match object at 0x7fe47020a098>
None
<_sre.SRE_Match object at 0x7fe47020a098>
4. 匹配查找函数
findall():找到正则匹配的所有子串,并作为列表返回。
finditer():找到正则匹配的所有子串,并作为迭代器返回。
p = re.compile(r'\d')
s = 'a1b2c3d'
print '【Output】'
print p.findall(s)
print p.finditer(s)
for ss in p.finditer(s):
print ss
print ss.group()
【Output】
['1', '2', '3']
<callable-iterator object at 0x7fe4701ecb90>
<_sre.SRE_Match object at 0x7fe47020a780>
1
<_sre.SRE_Match object at 0x7fe47020a6b0>
2
<_sre.SRE_Match object at 0x7fe47020a780>
3
5. MatchObject实例方法
p = re.compile(r'aa')
m = p.search('1aa2bb3aad')
print '【Output】'
print m.group()
print m.group(0)
#print m.group(1) # IndexError: no such group,因为当前只有一个分组
print m.start()
print m.end()
print m.span()
【Output】
aa
aa
1
3
(1, 3)
p = re.compile(r'age:(\d+),score:(\d+)')
info = 'age:15,score:98;age:20,score:100'
it = p.finditer(info)
print '【Output】'
for x in it:
print 'info=({0}),age={1},score={2}'.format(x.group(0),x.group(1),x.group(2))
【Output】
info=(age:15,score:98),age=15,score=98
info=(age:20,score:100),age=20,score=100
6. 其他re顶级函数
(1) 匹配开头
re.match(pattern,str,flags = 0)
注:这里的pattern既可以直接使用正则字符串(r'...'),又可以使用编译后的正则(p = re.compile(r'...'))
(2) 匹配所有位置
re.search(pattern,str,flags = 0)
re.search()函数和re.match()函数的不同用法举例:
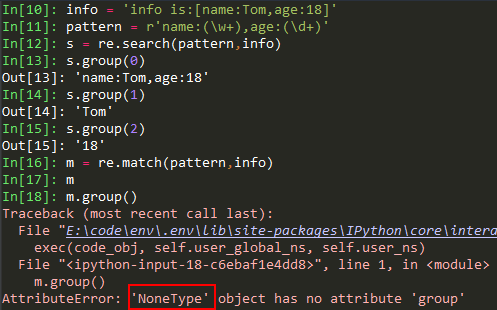
(3) 替换子串
re.sub(pattern,repl,str,count = 0,flags = 0)
print '【Output】'
print re.sub(r'a.b','xxx','acb,ayb,acd,aub,dd',2)
# re.sub()是产生一个新的字符串,使用re.sub()函数替换后,并不会对原字符串产生影响
【Output】
xxx,xxx,acd,aub,dd
替换子串与后项引用的结合使用举例:
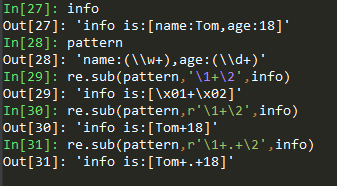
可以看出re.sub()函数的第二个参数支持对前面的正则分组的后向引用,值得注意的是,第二个参数如果需要进行后向引用,那么必须写成raw字符串('r'开头的字符串),且字符串中的正则元字符(如'.'、'+'等)会被当成普通字符出现在结果中。
注:正则后向引用相关用法参见博文:python正则表达式系列(4)——分组和后向引用
(4) 替换子串
re.subn(pattern,repl,str,count = 0,flags = 0),作用同re.sub()函数,只不过subn()函数返回一个二元组,包含了替换后的字符串和替换次数。
print '【Output】'
print re.subn(r'a.b','xxx','acb,ayb,acd,aub,dd')
【Output】
('xxx,xxx,acd,xxx,dd', 3)
(5) 字符串分割函数
re.split(pattern, string, maxsplit=0, flags=0)
p = re.compile(r'[+\-*/]')
print '【Output】'
print re.split(p,'1+2-3*4/5')
【Output】
['1', '2', '3', '4', '5']
(6) 子串查找函数
re.findall(pattern, string, flags=0)
print '【Output】'
print re.findall(r'a+','abbaaccaaa')
【Output】
['a', 'aa', 'aaa']
# 分组查找:
print '【Output】'
print re.findall(r'age=(\d+)','age=1,age=21')
【Output】
['1', '21']随机推荐
- Python tkinter 用键盘移动没反映修改代码
from tkinter import * def movetriangle(event): if event.keysym == 'Up': canvas.move(a1 ...
- plsql programming 11 记录类型
记录类型非常类似数据库表中的行. 记录作为一个整体本身并没有值, 不过每个单独成员或字段都有值, 记录提供了一种把这些值当做一组进行操作的方法. 例如: 1: -- create a table 2: ...
- MFC中改变控件的大小和位置(zz)
用CWnd类的函数MoveWindow()或SetWindowPos()能够改变控件的大小和位置. void MoveWindow(int x,int y,int nWidth,int nHeight ...
- iframe详解
如何查看是否为iframe *使用FireFox组件firebug->firepath 1.Top Window:可直接定位 2.iframe#i:根据id定位 定位方法: switch_to. ...
- MySQL运算符总结
注解:常常用于where条件判断中
- (翻译) TFS源码控制的未来 (TFSVC vs. Git)
博主: 翻译自微软Visual Studio ALM产品组老大Brian Harry 的博客文章 The future of Team Foundation Server Version contro ...
- win10 IoT开发 SerialDevice 返回 null
树莓派3,win10 Iot,串口开发,抄例子,串口获取返回老是null,例子却可以,代码一样,上网查询结果如下: https://stackoverflow.com/questions/341603 ...
- 【BZOJ4066】简单题 KDtree
[BZOJ4066]简单题 Description 你有一个N*N的棋盘,每个格子内有一个整数,初始时的时候全部为0,现在需要维护两种操作: 命令 参数限制 内容 1 x y A 1<=x,y& ...
- 《从零开始学Swift》学习笔记(Day 45)——重写方法
原创文章,欢迎转载.转载请注明:关东升的博客 重写实例方法 在子类中重写从父类继承来的实例方法和静态方法.先介绍实例方法的重写. 下面看一个示例: class Person { var name: S ...
- 【转】Gacutil.exe(全局程序集缓存工具)
全局程序集缓存工具使您可以查看和操作全局程序集缓存和下载缓存的内容. 安装 Visual Studio 和 Windows SDK 时会自动安装此工具. 要运行工具,我们建议您使用 Visual St ...