Python3爬取王者官方网站英雄数据
爬取王者官方网站英雄数据
众所周知,王者荣耀已经成为众多人们喜爱的一款休闲娱乐手游,今天就利用python3 爬虫技术爬取官方网站上的几十个英雄的资料,包括官方给出的人物定位,英雄名称,技能名称,CD,英雄克制关系以及官方给出的出装Tips等数据。如下图:
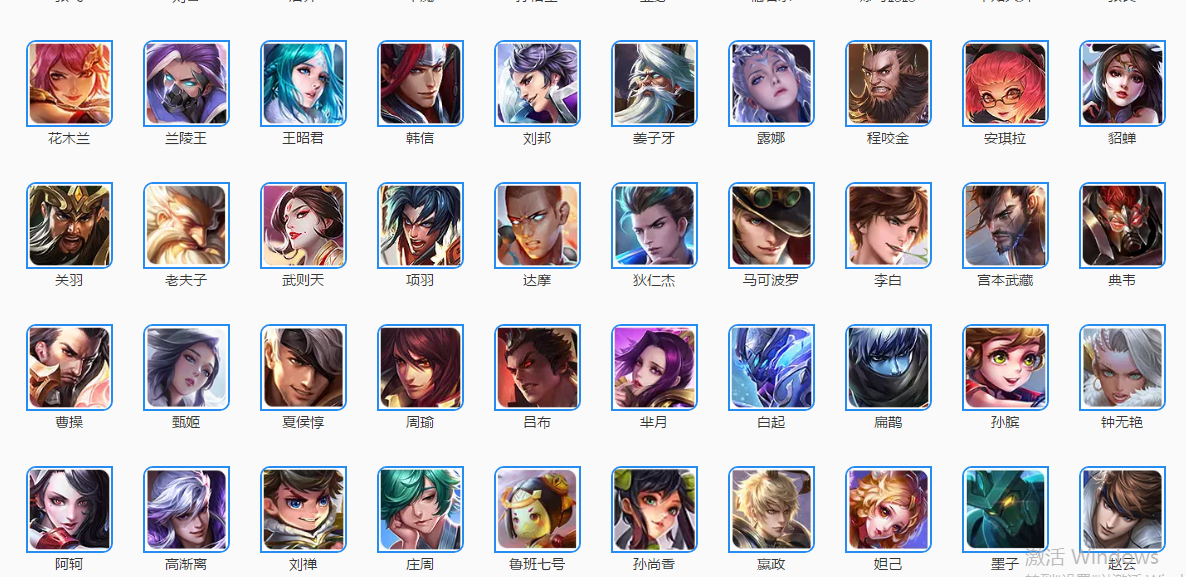
首先,对英雄列表页中的各个英雄子夜进行观察其URL的变动,发现每个英雄页面之后后面的页数会变动且呈递增规律。

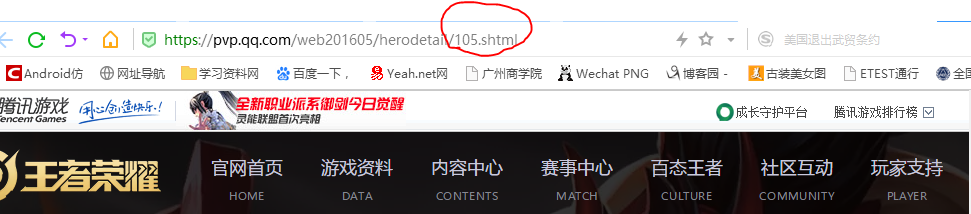
接下来审查要爬取对象的标签元素
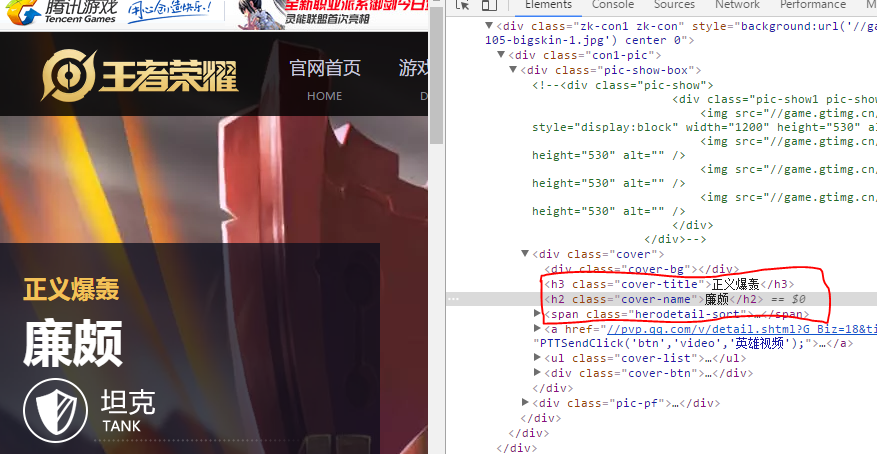
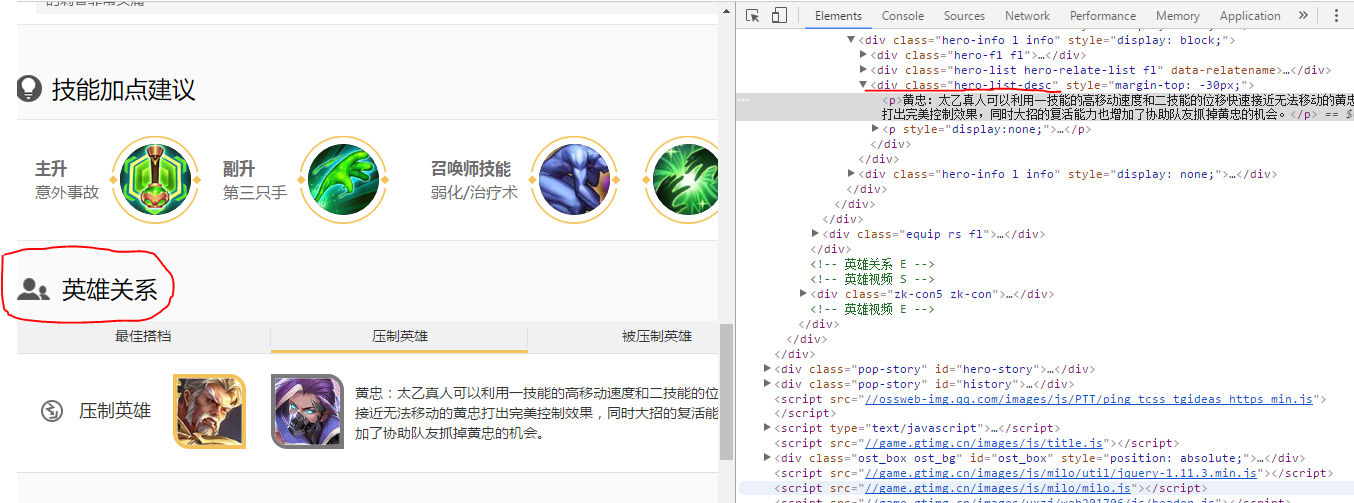
解析网站后,开始准备爬取数据
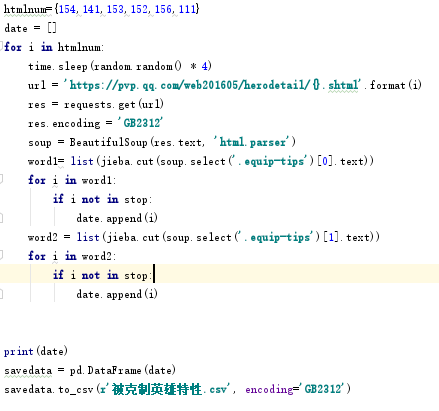
代码部分
准备要获取的所有英雄页面URL

根据页面上的标签获取数据并保存到字典

游戏部分英雄为虚构世界人物,这里还需要在jieba手动添加英雄名和部分装备名

官方某些英雄由于没有在html上标明克制与压制关系的英雄名称,只上传了照片,如下图,并未找到“吕布”、“王昭君”等关键字,为了数据的完整性,部分数据需要手动在代码添加,大部分数据还是可以自动获取。


一切工作准备妥当之后,开始爬虫。
引入英雄名和停用词对其中部分数据进行清洗和分词

词频排序、保存为CSV文件

经过筛选,列出搭档出现频数最多,压制英雄数量最多的英雄频数,被克制最多的英雄频数三个数表如图
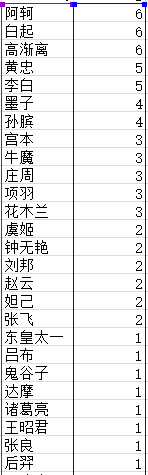
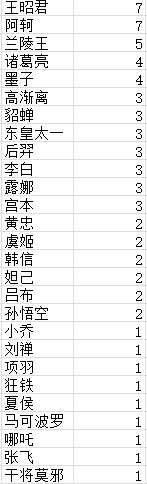
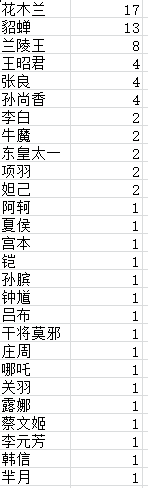
统计为树状图
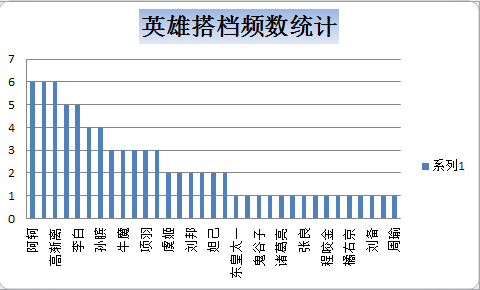
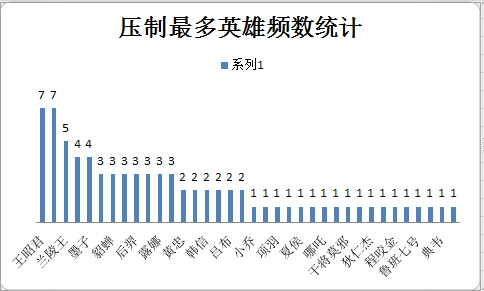
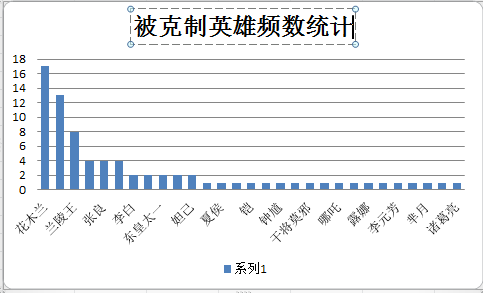
之后分析各类数据前几名英雄的官方tips词频,这里代码相同,爬取只只需改动htmlnum中的数据即可。最后输出csv文件。
在线生成词云如图



PS:以上仅为官网数据,不代表个人观点
Python3爬取王者官方网站英雄数据的更多相关文章
- 1、使用Python3爬取美女图片-网站中的每日更新一栏
此代码是根据网络上其他人的代码优化而成的, 环境准备: pip install lxml pip install bs4 pip install urllib #!/usr/bin/env pytho ...
- 2、使用Python3爬取美女图片-网站中的妹子自拍一栏
代码还有待优化,不过目的已经达到了 1.先执行如下代码: #!/usr/bin/env python #-*- coding: utf-8 -*- import urllib import reque ...
- Python 爬取 "王者荣耀.英雄壁纸" 过程中的矛和盾
1. 前言 学习爬虫,最好的方式就是自己编写爬虫程序. 爬取目标网站上的数据,理论上讲是简单的,无非就是分析页面中的资源链接.然后下载.最后保存. 但是在实施过程却会遇到一些阻碍. 很多网站为了阻止爬 ...
- 用python的requests第三方模块抓取王者荣耀所有英雄的皮肤
本文使用python的第三方模块requests爬取王者荣耀所有英雄的图片,并将图片按每个英雄为一个目录存入文件夹中,方便用作桌面壁纸 下面时具体的代码,已通过python3.6测试,可以成功运行: ...
- 20行Python代码爬取王者荣耀全英雄皮肤
引言王者荣耀大家都玩过吧,没玩过的也应该听说过,作为时下最火的手机MOBA游戏,咳咳,好像跑题了.我们今天的重点是爬取王者荣耀所有英雄的所有皮肤,而且仅仅使用20行Python代码即可完成. 准备工作 ...
- python 爬取王者荣耀英雄皮肤代码
import os, time, requests, json, re, sys from retrying import retry from urllib import parse "& ...
- Python爬取 | 王者荣耀英雄皮肤海报
这里只展示代码,具体介绍请点击下方链接. Python爬取 | 王者荣耀英雄皮肤海报 import requests import re import os import time import wi ...
- Python开发爬虫之BeautifulSoup解析网页篇:爬取安居客网站上北京二手房数据
目标:爬取安居客网站上前10页北京二手房的数据,包括二手房源的名称.价格.几室几厅.大小.建造年份.联系人.地址.标签等. 网址为:https://beijing.anjuke.com/sale/ B ...
- Scrapy实战篇(七)之爬取爱基金网站基金业绩数据
本篇我们以scrapy+selelum的方式来爬取爱基金网站(http://fund.10jqka.com.cn/datacenter/jz/)的基金业绩数据. 思路:我们以http://fund.1 ...
随机推荐
- Caffeine用法
Caffeine是使用Java8对Guava缓存的重写版本,在Spring Boot 2.0中将取代Guava.如果出现Caffeine,CaffeineCacheManager将会自动配置.使用sp ...
- IntelliJ IDEA快速自动生成Junit测试类
1.背景 测试是保证代码必不可少的环节,自己构建测试方法太慢,并且命名也不规范,idea中提供了,一键构建测试结构的功能...废话不多说,直接写步骤 2.步骤 1.在需要做测试的类的当前窗口,直接按快 ...
- day 21 作业
定义MySQL类 对象有id.host.port三个属性 定义工具create_id,在实例化时为每个对象随机生成id,保证id唯一 提供两种实例化方式,方式一:用户传入host和port 方式二:从 ...
- Oracle数据库插入过程中特殊符号
-- 问题描述:(插入数据中有特殊符号)数据插入后乱码. -- 背景:客户提供部分Excel表格数据要求导入数据库.由于考虑到数据量不大所以粗略在Excel中进行了sql处理(在数据前后添加sql及对 ...
- Linux实验:hdfs shell基本命令操作(二)
[实验目的] 1)熟练hdfs shell命令操作 2)理解hdfs shell和linux shell命令[实验原理] 安装好hadoop环境之后,可以执行hdfs shell命令 ...
- OpenStack核心组件-horizon web 界面管理
1. horizon 介绍 Horizon: Horizon 为 Openstack 提供一个 WEB 前端的管理界面 (UI 服务 )通过 Horizone 所提供的 DashBoard 服务 , ...
- HTML+Css+JavaScript知识点汇总
HTML 部分 HTML基础知识 1. HTML简介 HTML(Hypertext Markup Language),超文本标记语言,HTML利用各种标记来标识文档的结构以及标识超链接的信息.它是从S ...
- nginx: [error] invalid PID number "" in "/run/nginx.pid"
在重启云主机(系统)之后,执行 nginx -t 是OK的,然而在执行 nginx -s reload 的时候报错 nginx: [error] invalid PID number “” in “/ ...
- docker学习4-docker安装mysql环境
前言 docker安装mysql环境非常方便,简单的几步操作就可以了 拉取mysql镜像 先拉取mysql的镜像,可以在docker的镜像仓库找到不同TAG标签的版本https://hub.docke ...
- Tomcat项目内存参数调优
一.常见的Java内存溢出有以下三种: 1. Java.lang.OutOfMemoryError: Java heap space 即JVM Heap溢出 解释说明:JVM在启动的时候会自动设置JV ...