分布式存储-ceph
1. ceph 简介
Ceph是一种为优秀的性能、可靠性和可扩展性而设计的统一的、分布式文件系统()。ceph 的统一体现在可以提供文件系统、块存储和对象存储,分布式体现在可以动态扩展。在国内一些公司的云环境中,通常会采用 ceph 作为openstack 的唯一后端存储来提高数据转发效率。
Ceph项目最早起源于Sage就读博士期间的工作(最早的成果于2004年发表),并随后贡献给开源社区。在经过了数年的发展之后,目前已得到众多云计算厂商的支持并被广泛应用。RedHat及OpenStack都可与Ceph整合以支持虚拟机镜像的后端存储。
官网:https://ceph.com/
官方文档:http://docs.ceph.com/docs/master/#
2. Ceph特点
高性能:
1) 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。
2) 考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
3) 能够支持上千个存储节点的规模,支持TB到PB级的数据。
高可用性:
1) 副本数可以灵活控制。
2) 支持故障域分隔,数据强一致性。
3) 多种故障场景自动进行修复自愈。
4) 没有单点故障,自动管理。
高可扩展性:
1) 去中心化。
2) 扩展灵活。
3) 随着节点增加而线性增长。
特性丰富:
1) 支持三种存储接口:块存储、文件存储、对象存储。
2) 支持自定义接口,支持多种语言驱动。
3. Ceph应用场景
Ceph可以提供对象存储、块设备存储和文件系统服务,其对象存储可以对接网盘(owncloud)应用业务等;其块设备存储可以对接(IaaS),当前主流的IaaS运平台软件,如:OpenStack、CloudStack、Zstack、Eucalyptus等以及kvm等。
1> Ceph是一个高性能、可扩容的分布式存储系统,它提供三大功能:
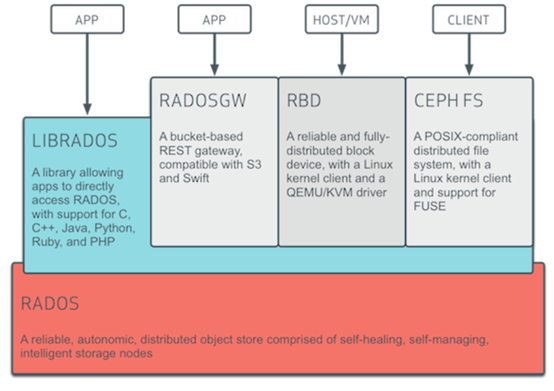
对象存储(RADOSGW):提供RESTful接口,也提供多种编程语言绑定。兼容S3、Swift;
块存储(RDB):由RBD提供,可以直接作为磁盘挂载,内置了容灾机制;
文件系统(CephFS):提供POSIX兼容的网络文件系统CephFS,专注于高性能、大容量存储;
2> 什么是块存储/对象存储/文件系统存储?
1)对象存储:
也就是通常意义的键值存储,其接口就是简单的GET、PUT、DEL 和其他扩展,代表主要有 Swift 、S3 以及 Gluster 等;
2)块存储:
这种接口通常以 QEMU Driver 或者 Kernel Module 的方式存在,这种接口需要实现 Linux 的 Block Device 的接口或者 QEMU 提供的 Block
Driver 接口,如 Sheepdog,AWS 的 EBS,青云的云硬盘和阿里云的盘古系统,还有 Ceph 的 RBD(RBD是Ceph面向块存储的接口)。在常见的存储中 DAS、SAN 提供的也是块存储;
3)文件系统存储:
通常意义是支持 POSIX 接口,它跟传统的文件系统如 Ext4 是一个类型的,但区别在于分布式存储提供了并行化的能力,如 Ceph 的 CephFS
(CephFS是Ceph面向文件存储的接口),但是有时候又会把 GlusterFS ,HDFS 这种非POSIX接口的类文件存储接口归入此类。当然 NFS、NAS也是属于文件系统存储;
4. Ceph核心组件
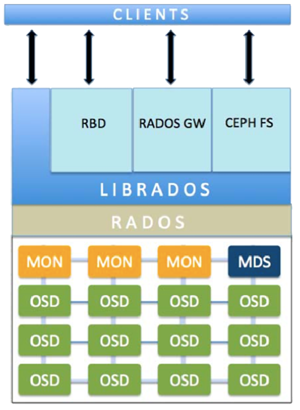
1)Monitors
监视器,维护集群状态的多种映射,同时提供认证和日志记录服务,包括有关monitor 节点端到端的信息,其中包括 Ceph 集群ID,监控主机名和IP以及端口。并且存储当前版本信息以及最新更改信息,通过
"ceph mon dump"查看 monitor map。
2)MDS(Metadata Server)
Ceph 元数据,主要保存的是Ceph文件系统的元数据。注意:ceph的块存储和ceph对象存储都不需要MDS。
3)OSD
即对象存储守护程序,但是它并非针对对象存储。是物理磁盘驱动器,将数据以对象的形式存储到集群中的每个节点的物理磁盘上。OSD负责存储数据、处理数据复制、恢复、回(Backfilling)、再平衡。完成存储数据的工作绝大多数是由 OSD daemon 进程实现。在构建 Ceph OSD的时候,建议采用SSD 磁盘以及xfs文件系统来格式化分区。此外OSD还对其它OSD进行心跳检测,检测结果汇报给Monitor。
4)RADOS
Reliable Autonomic
Distributed Object Store。RADOS是ceph存储集群的基础。在ceph中,所有数据都以对象的形式存储,并且无论什么数据类型,RADOS对象存储都将负责保存这些对象。RADOS层可以确保数据始终保持一致。
5)librados
librados库,(第三方扩展库)为应用程度提供访问接口。同时也为块存储、对象存储、文件系统提供原生的接口。
6)RADOSGW
网关接口,提供对象存储服务。它使用librgw和librados来实现允许应用程序与Ceph对象存储建立连接。并且提供S3 和 Swift 兼容的RESTful API接口。
7)RBD
块设备,它能够自动精简配置并可调整大小,而且将数据分散存储在多个OSD上。
8)CephFS
Ceph文件系统,与POSIX兼容的文件系统,基于librados封装原生接口。
5. Ceph存储系统的逻辑层次结构
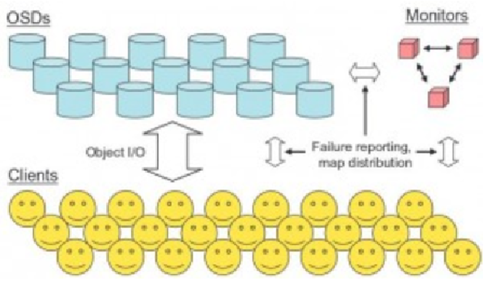
6. RADOS的系统逻辑结构
7. Ceph 数据存储过程
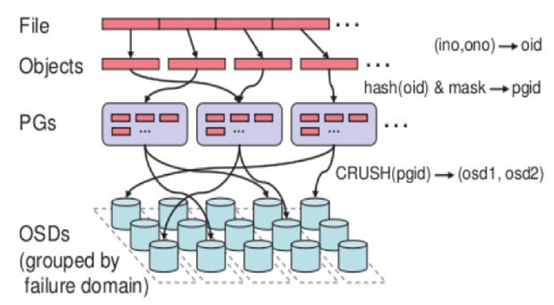
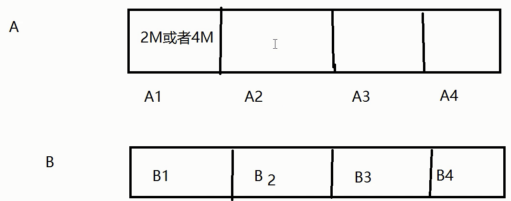
无论使用哪种存储方式(对象、块、文件系统),存储的数据都会被切分成Objects。Objects size大小可以由管理员调整,通常为2M或4M。每个对象都会有一个唯一的OID,由ino与ono生成,虽然这些名词看上去很复杂,其实相当简单。
ino:即是文件的File ID,用于在全局唯一标识每一个文件
ono:则是分片的编号
比如:一个文件FileID为A,它被切成了两个对象,一个对象编号0,另一个编号1,那么这两个文件的oid则为A0与A1。
File —— 此处的file就是用户需要存储或者访问的文件。对于一个基于Ceph开发的对象存储应用而言,这个file也就对应于应用中的“对象”,也就是用户直接操作的“对象”。
Ojbect —— 此处的object是RADOS所看到的“对象”。Object与上面提到的file的区别是,object的最大size由RADOS限定(通常为2MB或4MB),以便实现底层存储的组织管理。因此,当上层应用向RADOS存入size很大的file时,需要将file切分成统一大小的一系列object(最后一个的大小可以不同)进行存储。为避免混淆,在本文中将尽量避免使用中文的“对象”这一名词,而直接使用file或object进行说明。
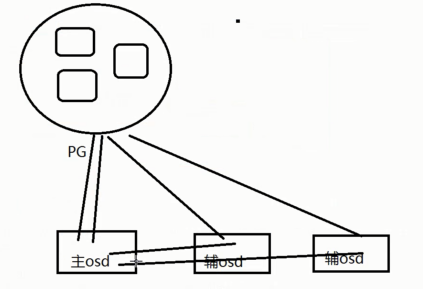
PG(Placement Group)—— 顾名思义,PG的用途是对object的存储进行组织和位置映射。具体而言,一个PG负责组织若干个object(可以为数千个甚至更多),但一个object只能被映射到一个PG中,即,PG和object之间是“一对多”映射关系。同时,一个PG会被映射到n个OSD上,而每个OSD上都会承载大量的PG,即,PG和OSD之间是“多对多”映射关系。在实践当中,n至少为2,如果用于生产环境,则至少为3。一个OSD上的PG则可达到数百个。事实上,PG数量的设置牵扯到数据分布的均匀性问题。关于这一点,下文还将有所展开。
OSD —— 即object
storage device,前文已经详细介绍,此处不再展开。唯一需要说明的是,OSD的数量事实上也关系到系统的数据分布均匀性,因此其数量不应太少。在实践当中,至少也应该是数十上百个的量级才有助于Ceph系统的设计发挥其应有的优势。
基于上述定义,便可以对寻址流程进行解释了。具体而言, Ceph中的寻址至少要经历以下三次映射:
(1)File -> object映射
(2)Object -> PG映射,hash(oid) & mask -> pgid
(3)PG -> OSD映射,CRUSH算法
CRUSH,Controlled Replication Under
Scalable Hashing,它表示数据存储的分布式选择算法, ceph 的高性能/高可用就是采用这种算法实现。CRUSH 算法取代了在元数据表中为每个客户端请求进行查找,它通过计算系统中数据应该被写入或读出的位置。CRUSH能够感知基础架构,能够理解基础设施各个部件之间的关系。并CRUSH保存数据的多个副本,这样即使一个故障域的几个组件都出现故障,数据依然可用。CRUSH 算是使得 ceph 实现了自我管理和自我修复。
RADOS 分布式存储相较于传统分布式存储的优势在于:
1)
将文件映射到object后,利用Cluster
Map 通过CRUSH 计算而不是查找表方式定位文件数据存储到存储设备的具体位置。优化了传统文件到块的映射和Block MAp的管理。
2)
RADOS充分利用OSD的智能特点,将部分任务授权给OSD,最大程度地实现可扩展
8. Ceph IO流程及数据分布
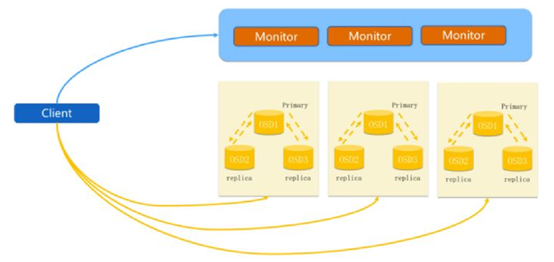
(1)正常IO流程图:
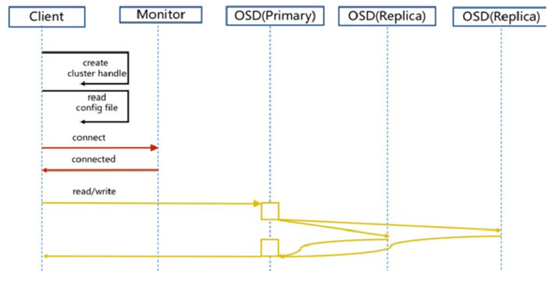
步骤:
1. client 创建cluster handler。
2. client 读取配置文件。
3. client 连接上monitor,获取集群map信息。
4. client 读写io 根据crshmap 算法请求对应的主osd数据节点。
5. 主osd数据节点同时写入另外两个副本节点数据。
6. 等待主节点以及另外两个副本节点写完数据状态。
7. 主节点及副本节点写入状态都成功后,返回给client,io写入完成。
(2)新主IO流程图
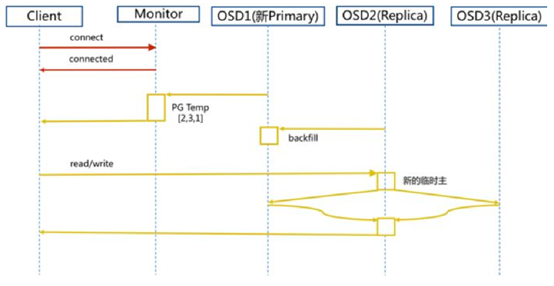
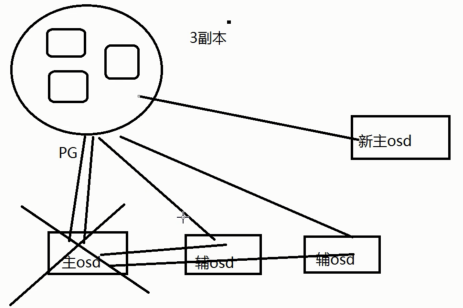
说明:如果新加入的OSD1取代了原有的 OSD4成为 Primary OSD, 由于 OSD1 上未创建 PG , 不存在数据,那么 PG 上的 I/O 无法进行,怎样工作的呢?
新主IO流程步骤:
1)
client连接monitor获取集群map信息。
2)
同时新主osd1由于没有pg数据会主动上报monitor告知让osd2临时接替为主。临时主osd2会把数据全量同步给新主osd1。
3)
client IO读写直接连接临时主osd2进行读写。
4)
osd2收到读写io,同时写入另外两副本节点。
5)
等待osd2以及另外两副本写入成功。
6)
osd2三份数据都写入成功返回给client, 此时client io读写完毕。
7)
如果osd1数据同步完毕,临时主osd2会交出主角色。
9. Ceph Pool和PG分布情况
pool:是ceph存储数据时的逻辑分区,它起到namespace的作用。每个pool包含一定数量(可配置) 的PG。PG里的对象被映射到不同的Object上。pool是分布到整个集群的。 pool可以做故障隔离域,根据不同的用户场景不统一进行隔离。

10. ceph部署
1> 实验环境
四台主机192.168.16.65、.66、.68、.69,对应主机名依次为ajy5、ajy6、ajy7、ajy8、ajy9。ajy5为deploy节点,ajy6为controller节点,ajy8位compute节点,ajy9位storeage节点,将ajy6、8、9全部部署mon,同时设置成osd,ajy5运行ceph-deploy。
2> 静态域名解析,四台主机均做
[root@ajy5 ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
:: localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.16.65 ajy5
192.168.16.66 ajy6
192.168.16.68 ajy8
192.168.16.69 ajy9
3> 所有的节点都创建普通用户cent,并设置密码,我设置的是123
[root@ajy5 ~]# useradd cent && echo "" | passwd --stdin cent
Changing password for user cent.
设置每个节点cent用户都有sudo的权限
[root@ajy5 ~]# echo -e 'Defaults:cent !requiretty\ncent ALL = (root) NOPASSWD:ALL' | tee /etc/sudoers.d/ceph
[root@ajy5 ~]# chmod /etc/sudoers.d/ceph
4> 在部署节点切换为cent用户,设置无秘钥登录各节点,包括客户端节点
[root@ajy5 ~]# su - cent
[cent@ajy5 ~]$ pwd
/home/cent
[cent@ajy5 ~]$ ssh-keygen #回车回车回车
[cent@ajy5 ~]$ ssh-copy-id ajy5
[cent@ajy5 ~]$ ssh-copy-id ajy6
[cent@ajy5 ~]$ ssh-copy-id ajy8
[cent@ajy5 ~]$ ssh-copy-id ajy9
[cent@ajy5 ~]$ ssh ajy6
[cent@ajy6 ~]$ exit
logout
Connection to ajy6 closed.
[cent@ajy5 ~]$
5> 在部署节点切换为cent用户,在cent用户家目录,设置如下文件:/.ssh/config
[cent@ajy5 ~]$ ls -a
. .. .bash_logout .bash_profile .bashrc .cache .config .ssh
[cent@ajy5 ~]$ cd .ssh
[cent@ajy5 .ssh]$ ls
authorized_keys id_rsa id_rsa.pub known_hosts
[cent@ajy5 .ssh]$ vim config
Host ajy5
Hostname ajy5
User cent
Host ajy6
Hostname ajy6
User cent
Host ajy8
Hostname ajy8
User cent
Host ajy9
Hostname ajy9
User cent
修改权限
[cent@ajy5 .ssh]$ chmod ~/.ssh/config
6> 所有的节点配置ceph源
[cent@ajy5 .ssh]$ cat /etc/redhat-release
CentOS Linux release 7.6. (Core)
使用阿里源(centos7.6版本):https://mirrors.aliyun.com/centos/7.6.1810/storage/x86_64/ceph-jewel/
[root@ajy5 ~]# cd /etc/yum.repos.d/
[root@ajy5 yum.repos.d]# ls
bak local.repo.bak old
Centos7-Base-yunwei.repo Mariadb.repo.bak rdo-release-yunwei.repo
epel-yunwei.repo net.repo.bak
[root@ajy5 yum.repos.d]# vim ceph.repo
[ceph]
name=ceph
baseurl=https://mirrors.aliyun.com/centos/7.6.1810/storage/x86_64/ceph-jewel/
enable=
gpgcheck=
[root@ajy5 yum.repos.d]# yum clean all
[root@ajy5 yum.repos.d]# yum makecaceh
由于下载ceph-deploy会跳到外网下载,导致下载失败,一次先将ceph的安装包在本地准备好,然后在本地安装
[root@ajy5 yum.repos.d]# cd
[root@ajy5 ~]# wget http://download2.yunwei.edu/shell/ceph-j.tar.gz
[root@ajy5 ~]# ls
anaconda-ks.cfg ceph-j.tar.gz yum-repo.sh
[root@ajy5 ~]# tar xzf ceph-j.tar.gz
[root@ajy5 ~]# ls
anaconda-ks.cfg cephjrpm ceph-j.tar.gz yum-repo.sh
[root@ajy5 ~]# cd cephjrpm
[root@ajy5 cephjrpm]# ls
ceph-10.2.-.el7.x86_64.rpm
ceph-base-10.2.-.el7.x86_64.rpm
ceph-common-10.2.-.el7.x86_64.rpm
ceph-deploy-1.5.-.noarch.rpm
ceph-devel-compat-10.2.-.el7.x86_64.rpm
cephfs-java-10.2.-.el7.x86_64.rpm
ceph-fuse-10.2.-.el7.x86_64.rpm
ceph-libs-compat-10.2.-.el7.x86_64.rpm
ceph-mds-10.2.-.el7.x86_64.rpm
ceph-mon-10.2.-.el7.x86_64.rpm
ceph-osd-10.2.-.el7.x86_64.rpm
ceph-radosgw-10.2.-.el7.x86_64.rpm
ceph-resource-agents-10.2.-.el7.x86_64.rpm
ceph-selinux-10.2.-.el7.x86_64.rpm
ceph-test-10.2.-.el7.x86_64.rpm
libcephfs1-10.2.-.el7.x86_64.rpm
libcephfs1-devel-10.2.-.el7.x86_64.rpm
libcephfs_jni1-10.2.-.el7.x86_64.rpm
libcephfs_jni1-devel-10.2.-.el7.x86_64.rpm
librados2-10.2.-.el7.x86_64.rpm
librados2-devel-10.2.-.el7.x86_64.rpm
libradosstriper1-10.2.-.el7.x86_64.rpm
libradosstriper1-devel-10.2.-.el7.x86_64.rpm
librbd1-10.2.-.el7.x86_64.rpm
librbd1-devel-10.2.-.el7.x86_64.rpm
librgw2-10.2.-.el7.x86_64.rpm
librgw2-devel-10.2.-.el7.x86_64.rpm
python-ceph-compat-10.2.-.el7.x86_64.rpm
python-cephfs-10.2.-.el7.x86_64.rpm
python-rados-10.2.-.el7.x86_64.rpm
python-rbd-10.2.-.el7.x86_64.rpm
rbd-fuse-10.2.-.el7.x86_64.rpm
rbd-mirror-10.2.-.el7.x86_64.rpm
rbd-nbd-10.2.-.el7.x86_64.rpm
7> 在部署节点先安装ceph-deploy
[root@ajy5 cephjrpm]# yum localinstall ceph-deploy-1.5.-.noarch.rpm -y
Error: Package: ceph-deploy-1.5.-.noarch (/ceph-deploy-1.5.-.noarch)
Requires: python-distribute
Available: python-setuptools-0.9.-.el7.noarch (base)
python-distribute = 0.9.-.el7
配置源有问题,修改rdo的源
[root@ajy5 yum.repos.d]# ls
bak epel-yunwei.repo net.repo.bak
Centos7-Base-yunwei.repo local.repo.bak old
ceph.repo Mariadb.repo.bak rdo-release-yunwei.repo
[root@ajy5 yum.repos.d]# mv rdo-release-yunwei.repo bak
[root@ajy5 yum.repos.d]# ls
bak ceph.repo local.repo.bak net.repo.bak
Centos7-Base-yunwei.repo epel-yunwei.repo Mariadb.repo.bak old
[root@ajy5 yum.repos.d]# cd -
/root/cephjrpm
[root@ajy5 cephjrpm]# yum localinstall ceph-deploy-1.5.-.noarch.rpm -y
验证是否安装成功,用ceph自己的命令查看ceph版本
[root@ajy5 cephjrpm]# ceph-deploy --version
1.5.
ceph-deploy安装完成后将ceph-deploy的安装移除,然后在各节点安装其他所有的安装包,即ceph-deploy只有部署节点ajy5上面安装,其他节点不需要安装
[root@ajy5 cephjrpm]# mv ceph-deploy-1.5.-.noarch.rpm ../ #移到上层目录
[root@ajy5 cephjrpm]# yum localinstall ./* -y
[root@ajy6 cephjrpm]# yum localinstall ./* -y
[root@ajy8 cephjrpm]# yum localinstall ./* -y
[root@ajy9 cephjrpm]# yum localinstall ./* -y
8> 部署节点创建ceph的工作目录,配置新集群
[root@ajy5 ~]# su - cent
[cent@ajy5 ~]$ mkdir ceph
[cent@ajy5 ~]$ cd ceph/
[cent@ajy5 ceph]$ pwd
/home/cent/ceph
[cent@ajy5 ceph]$ ceph-deploy new ajy6 ajy8 ajy9 #配置集群,包含三个节点
[cent@ajy5 ceph]$ ls
ceph.conf ceph-deploy-ceph.log ceph.mon.keyring #生成三个文件
[cent@ajy5 ceph]$ vim ceph.conf #编辑主配置文件
[global]
fsid = a5611bfb-b339-43be-b65b-6de3745b86fc #ceph集群id
mon_initial_members = ajy6, ajy8, ajy9 #监控节点成员
mon_host = 192.168.16.66,192.168.16.68,192.168.16.69 #监控成员ip
auth_cluster_required = cephx #ceph认证的参数
auth_service_required = cephx
auth_client_required = cephx
osd_pool_default_size = #ceph集群默认保存的副本数,实验环境较差,一个即可
mon_clock_drift_allowed = #至少两个mon正常的情况下ceph集群是正常的
mon_clock_drift_warn_backoff = #每3秒执行一次ceph集群的健康检查
:wq
可选的调优参数有:
public_network = 192.168.254.0/
cluster_network = 172.16.254.0/
osd_pool_default_size =
osd_pool_default_min_size =
osd_pool_default_pg_num =
osd_pool_default_pgp_num =
osd_crush_chooseleaf_type = [mon]
mon_clock_drift_allowed = 0.5 [osd]
osd_mkfs_type = xfs
osd_mkfs_options_xfs = -f
filestore_max_sync_interval =
filestore_min_sync_interval = 0.1
filestore_fd_cache_size =
filestore_omap_header_cache_size =
filestore_fd_cache_random = true
osd op threads =
osd disk threads =
filestore op threads =
max_open_files =
9> 在部署节点cent用户下,使用ceph命令安装ceph软件
注意 :若安装失败可尝试移除源 rdo 再进行安装
[cent@ajy5 ceph]$ pwd
/home/cent/ceph
[cent@ajy5 ceph]$ ceph-deploy install ajy5 #可以一次性安装所有节点,也可以将各节点分开安装
[ajy5][DEBUG ] Nothing to do #第7>步已经提前安装完了所有所需的软件包,这个安装过程会跳到外网安装,由于网络原因肯定会安装失败,因此提前将这些包安装。
[cent@ajy5 ceph]$ ceph-deploy install ajy6
[cent@ajy5 ceph]$ ceph-deploy install ajy8
[cent@ajy5 ceph]$ ceph-deploy install ajy9
安装完成后初始化集群,在部署节点的cent用户下执行
[cent@ajy5 ceph]$ ceph-deploy mon create-initial
10> 每个节点将第二块硬盘(sdb)做分区,并格式化为xfs文件系统挂载到/data。
由于节点ajy6作为OpenStack控制节点内存需求较高,我将sdb硬盘做了swap缓存分区,所以给ajy6节点添加另一块硬盘sdc
列示节点的磁盘信息
[cent@ajy5 ceph]$ ceph-deploy disk list ajy6
.....
[ajy6][INFO ] Running command: sudo /usr/sbin/ceph-disk list
[ajy6][DEBUG ] /dev/dm- other, xfs, mounted on /
[ajy6][DEBUG ] /dev/dm- swap, swap
[ajy6][DEBUG ] /dev/sda :
[ajy6][DEBUG ] /dev/sda2 other, LVM2_member
[ajy6][DEBUG ] /dev/sda1 other, xfs, mounted on /boot
[ajy6][DEBUG ] /dev/sdb :
[ajy6][DEBUG ] /dev/sdb1 swap, swap
[ajy6][DEBUG ] /dev/sdc other, unknown
[ajy6][DEBUG ] /dev/sr0 other, iso9660
......
若想格式化某个磁盘,可以擦净节点磁盘:ceph-deploy disk zap ajy6:/dev/vdb1
准备osd:
在各节点先进行磁盘的文件分区
[root@ajy6 ~]# lsblk
[root@ajy6 ~]# fdisk /dev/sdc
....
Command (m for help): n
Select (default p):
Using default response p
Partition number (-, default ):
First sector (-, default ):
Using default value
Last sector, +sectors or +size{K,M,G} (-, default ):
Using default value
Partition of type Linux and of size GiB is set
Command (m for help): p
Disk /dev/sdc: 17.2 GB, bytes, sectors
Units = sectors of * = bytes
Sector size (logical/physical): bytes / bytes
I/O size (minimum/optimal): bytes / bytes
Disk label type: dos
Disk identifier: 0x8146f214
Device Boot Start End Blocks Id System
/dev/sdc1 Linux
Command (m for help): w
The partition table has been altered!
[root@ajy6 ~]# lsblk
......
sdc : 16G disk
└─sdc1 : 16G part
......
准备osd
[cent@ajy5 ceph]$ ceph-deploy osd prepare ajy6:/dev/sdc1
[cent@ajy5 ceph]$ ceph-deploy osd prepare ajy8:/dev/sdb1
[cent@ajy5 ceph]$ ceph-deploy osd prepare ajy9:/dev/sdb1
激活osd(Object Storage Daemon)
[cent@ajy5 ceph]$ ceph-deploy osd activate ajy6:/dev/sdc1 ajy8:/dev/sdb1 ajy9:/dev/sdb1 #也可以分开写
11> 在部署节点将配置文件发送给每个节点
[cent@ajy5 ceph]$ ceph-deploy admin ajy5 ajy6 ajy8 ajy9
在每个节点修改配置文件权限
[root@ajy6 ~]# sudo chmod /etc/ceph/ceph.client.admin.keyring
[root@ajy8~]# sudo chmod /etc/ceph/ceph.client.admin.keyring
[root@ajy9]# sudo chmod /etc/ceph/ceph.client.admin.keyring
12>在集群中的任意节点进行检测
[root@ajy8 ~]# ceph -s
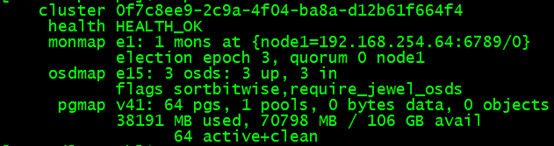
查看osd的分布
[cent@ajy5 ceph]$ ceph osd tree
11. ceph集群的使用
如果计算机条件允许,可以在单独创建一台机器用作客户端。
1> 客户端配置cent用户
创建cent用户
useradd cent && echo "" | passwd --stdin cent 赋予sudo权限
echo-e 'Defaults:cent !requiretty\ncent ALL = (root) NOPASSWD:ALL' | tee /etc/sudoers.d/ceph 更改权限
chmod440 /etc/sudoers.d/ceph
2> 在部署端ajy5安装车屁股客户端并进行设置。controller表示新添加的客户端节点。
控制节点安装
ceph-deploy install controller 给客户端传配置文件
ceph-deploy admin controller
3> 在客户端修改权限
sudo chmod /etc/ceph/ceph.client.admin.keyring
由于本人的物理机配置极低,因此使用几点ajy8作为客户端,不在重新创建客户端节点。
4> 在客户端配置rbd块设备
创建rbd:
rbd create disk01 --size 10G --image-feature layering 列示rbd,创建完rbd后在任何集群节点都可以看到rbd配置信息,因为rbd块设备使用的是集群的osd提供的空间
rbd ls -l 映射rbd的image map:
sudo rbd map disk01 显示map:
rbd showmapped 格式化disk01文件系统xfs:
sudo mkfs.xfs /dev/rbd0 挂载硬盘:
sudo mount /dev/rbd0 /mnt 验证是否挂着成功:
df -hT 挂载完成后就可以使用fdisk命令操作块设备了,也可以直接使用mkfs .xfs等命令对块设备进行操作。
将块设备映射后就相当于一块硬盘,使用方法也与硬盘相同,若不想使用该硬盘,去除该硬盘操作如下:
1) 取消挂载,使用umount命令;
2) 格式化分区,清洗掉元数据;
3) 取消映射:sudo rbd unmap disk01;
4) 删除块设备:rbd rm disk01。
5> 文件系统(File System)配置
在部署节点ajy5选择一个节点ajy创建mds的元数据服务
ceph-deploy mds create node1
在节点上修改权限
sudo chmod /etc/ceph/ceph.client.admin.keyring
在ceph集群创建存储池(pool)
ceph osd pool create cephfs_data #128指的是pg的数量
ceph osd pool create cephfs_metadata
开启pool
ceph fs new cephfs cephfs_metadata cephfs_data
显示ceph fs
ceph fs ls
ceph mds stat
若客户端想挂载文件系统需要安装ceph-fuse客户端
yum -y install ceph-fuse
然后再获取认证
sshcent@node1"sudo ceph-authtool -p /etc/ceph/ceph.client.admin.keyring" > admin.key chmod600 admin.key
之后再挂载,服务器的名字可以指定ceph节点的任意一个节点
mount-t ceph ajy6::/ /mnt -o name=admin,secretfile=admin.key #挂载在本地,名字为admin,认证为admin.key
df-hT
1) 若不想使用mds,需要如下操作:
2) 停止mds:systemctl stop ceph-mds@node1;
3) 设置mds状态为0:ceph mds fail 0;
4) 删除cephfs中的pool:ceph fs rm cephfs --yes-i-really-mean-it
a) 显示pool:ceph osd lspools;
b) 删除pool:ceph osd pool rm cephfs_metadata cephfs_metadata --yes-i-really-really-mean-it
6> 删除环境
若不想使用ceph,可以将其环境删除。在部署几点切换为cent用户,执行:
1) 删除节点:ceph-deploy purge ajy5 ajy6 ajy8 ajy9;
2) 删除节点数据:ceph-deploy purgedata ajy5 ajy6 ajy8 ajy9;
3) 忘记验证信息:ceph-deploy forgetkeys;
4) 删除所有的ceph文件:rm -rf ceph*。
分布式存储-ceph的更多相关文章
- 高可用OpenStack(Queen版)集群-13.分布式存储Ceph
参考文档: Install-guide:https://docs.openstack.org/install-guide/ OpenStack High Availability Guide:http ...
- 分布式存储ceph——(6)ceph 讲解
一.Ceph简介: Ceph是一种为优秀的性能.可靠性和可扩展性而设计的统一的.分布式文件系统.ceph 的统一体现在可以提供文件系统.块存储和对象存储,分布式体现在可以动态扩展.在国内一些公司的云环 ...
- 分布式存储ceph理论
一.ceph简介 Ceph是一种具有优秀性能,可靠性和可扩展性,统一的分布式文件系统.ceph 的统一体现在可以提供文件系统.块存储和对象存储,分布式体现在可以动态扩展.在国内一些公司的云环境中,通常 ...
- 分布式存储ceph介绍(1)
一.Ceph简介: Ceph是一种为优秀的性能.可靠性和可扩展性而设计的统一的.分布式文件系统.ceph 的统一体现在可以提供文件系统.块存储和对象存储,分布式体现在可以动态扩展.在国内一些公司的云环 ...
- 全能成熟稳定开源分布式存储Ceph破冰之旅-上
@ 目录 概述 定义 传统存储方式及问题 优势 生产遇到问题 架构 总体架构 组成部分 CRUSH算法 数据读写过程 CLUSTER MAP 部署 部署建议 部署版本 部署方式 Cephadm部署 前 ...
- 分布式存储Ceph的几种安装方法,源码,apt-get,deploy工具,Ubuntu CentOS
最近搞了下分布式PB级别的存储CEPH 尝试了几种不同的安装,使用 期间遇到很多问题,和大家一起分享. 一.源码安装 说明:源码安装可以了解到系统各个组件, 但是安装过程也是很费劲的,主要是依赖包太 ...
- 分布式存储ceph——(5)ceph osd故障硬盘更换
正常状态:
- 分布式存储ceph——(4)ceph 添加/删除osd
一.添加osd: 当前ceph集群中有如下osd,现在准备新添加osd:
- 分布式存储ceph——(3)ceph常用命令
1.查看ceph集群配置信息 1 ceph daemon /var/run/ceph/ceph-mon.$(hostname -s).asok config show 2.在部署节点修改了ceph ...
随机推荐
- [ ceph ] CEPH 部署完整版(CentOS 7 + luminous)
1. 前言 拜读了 胖哥的(el7+jewel)完整部署 受益匪浅,目前 CEPH 已经更新到 M 版本,配置方面或多或少都有了变动,本博文就做一个 ceph luminous 版本完整的配置安装. ...
- idea修改maven项目名
1.修改pom.xml中相关 <artifactId>seal-hn</artifactId><name>seal-hn</name><descr ...
- 负载均衡Nginx和F5的区别
今早上看书,看到为了保证Zuul的高可用性,在Zuul的前端可以使用Nginx或F5再次进行负载转发 使用过Nginx,那F5是什么,他们有什么区别吗? (1)F5 F5负载均衡器是应用交付网络的全球 ...
- EF的 NoTracking 的一些记录
NoTracking官方解释 跟踪与非跟踪查询 跟踪行为可控制 Entity Framework Core 是否将有关实体实例的信息保留在其更改跟踪器中. 如果已跟踪某个实体,则该实体中检测到的任何更 ...
- c#中特性Attribute
接上篇: 特性介绍: 特性是一个类,需要间接或者直接继承Attribute父类,在标记特性时以中括号包裹,可以标记在元素之前.AttributeTargets.Class设置标记的元素,需要明确指定标 ...
- 虚拟机centos与主机互相Ping通
在虚拟机(Vmware Workstation)下,安装了CentOS7,现在想通过SSH工具连接虚拟机中的CentOS7 1. 首先,要确保CentOS7安装了 openssh-server,在 ...
- 【剑指offer】链表中的倒数第k个结点
输入一个链表,输出该链表中倒数第k个结点. 分析: 定义两个结点p1和p2都指向头节点,p1先走k-1步,然后p1和p2一起走,当p1走到链表尾部时,p2指向的结点就是倒数第k个结点 遍历一遍链表即可 ...
- [转帖]Proof Of Work 工作量证明
Proof Of Work 工作量证明 https://www.cnblogs.com/zhang-qc/p/10451817.html 借鉴了 哈希现金(Hashcash)-1997年 英国密码学专 ...
- BJFU-216-基于链式存储结构的图书信息表的修改
#include<stdio.h> #include<stdlib.h> #define MAX 100 typedef struct Book{ double no; cha ...
- 【SpringBoot】SpingBoot整合AOP
https://blog.csdn.net/lmb55/article/details/82470388 [SpringBoot]SpingBoot整合AOPhttps://blog.csdn.net ...