原创:史上对BM25模型最全面最深刻的解读以及lucene排序深入讲解
垂直搜索结果的优化包括对搜索结果的控制和排序优化两方面,其中排序又是重中之重。本文将全面深入探讨垂直搜索的排序模型的演化过程,最后推导出BM25模型的排序。然后将演示如何修改lucene的排序源代码,下一篇将深入解读目前比较火热的机器学习排序在垂直搜索中的应用。本文的结构如下:
一、VSM模型简单介绍;
二、lucene默认的评分公式介绍;
三、概率语言模型中的二元独立模型BIM介绍;
四、BM25介绍;
五、lucene中的edismax解析器介绍以及评分公式源代码介绍;
六、修改排序源代码;
七、机器学习排序:①为什么需要机器学习排序②机器学习排序相关算法介绍③关于ListNet算法的英语原版学术论文的解读④机器学习排序实施思路
写这篇文章,花费了很大的精力,一部分是对原有的经验和技术的总结,另一方面又必然会涉及到改进和新技术的探索。任何开源框架都不是最完美的,之前探索了对lucene内部boolean查询AND逻辑实现的算法的改进,作为一个优秀的开源框架,lucene有很多闪光的地方值得借鉴,比如优先级队列的设计。lucene在搜索排序方面的设计思想是最杰出的一个闪光点,因此有必要从理论层面进行全面探讨,然后看看lucene是如何进行简化的。因为在工程实际应用中,尤其是设计一款优秀的开源框架或者是企业级的应用级软件,一定会在准确度和时间复杂度上折中处理。比如,BM25排序lucene就进行了简化。目前,在业内,机器学习排序的关于listwise方法很火热,早在2007年,微软研究院就研究出了listnet方法,用神经网络构造luce概率模型,运用交叉熵构造损失函数,采用SGD作为优化方法。但是,截止到2014之前,貌似Google也没有采用机器学习排序方法。也就是说,每个公司,只有探索出适合自己的算法,才是最优化的。脱离了应用场景,算法就变得毫无意义了,即使在理论上是最优的,实际情况有可能是很拙劣的。就技术创新而言,70%以上来源于对原有技术的整合,但是整合不等同于抄袭或者简单的拼凑。比如listnet机器学习排序方法,在原有算法(pairwise)上提出改进。任何算法都不是凭空产生的,数学模型绝大部分来源于观察,总结归纳,演绎推理,迁移,改进,这种思维方法的培养,远远胜于知识量的积累,就像程序员想提升编程水平,仅仅靠代码量的堆积,是拙劣的,不可行的。本文在提出修改lucene底层排序源代码之前,也是认真研读了很多经典著作,并且详细分析了lucene源代码的实现,结合具体的业务需求,经过多次测试和改进才有所进展。冰冻三尺,非一日之寒,在程序员的道路上,只有多读经典,多实践,多思考,敢于提出自己的想法,本着大胆假设,小心求证的原则,不断试错和探索,才会取得一点儿成就。
信息论在信息检索中发挥了重要的作用,之前有人问我,如果在搜索框中输入苹果,你如何判断用户想要的是苹果手机还是苹果电脑,还是苹果水果本身?我相信,在搜索领域,应该不止一个人会提出这样的问题。很遗憾的是,如果你把它当作研究方向,我只能说你应该重修《信息论》这门课程。牛顿在年轻时曾经对永动机非常疯狂,后来认识到了是个伪命题,及时收手了。犯错误并不可怕,可怕的是认识不到这是个错误方向。按照信息论,信息检索的本质是不断减少信息不确定的过程,也就是减少信息熵的过程。苹果的信息熵很大,也就是不确定特别大,信息检索的目标是减少这个不确定性,方法是增加特征信息。在进入搜索系统之前,可以增加一些分类信息,然后在排序过程中,可以考虑增加一些有用的因素,比如pagerank,point等等。这些手段都是为了一个共同的目标:减少信息的不确定性。如果方向搞错了,即使搞出一个算法来,效果也不会太好,不会具有普适性。在第三代搜索系统的研发中,目前百度已经走在了前列,度秘机器人v3.0版本跟之前相比,有了很大的提升。以之前提出的问题为例,如果单独对度秘说出苹果,她很难知道用户的需求,但是如果你对她说:"我想要苹果"和"我想吃苹果",这下度秘就知道了用户的准确需求了。很显然,吃苹果中的苹果是水果,如果什么特征信息都没有,再智能的机器人也无法判断。也许有人会说,我可以在进入搜索系统之前,分词之后,挖掘用户(id)的历史记录,如果之前买水果的几率比较大,就判断为水果。这种方法毫无意义,无异于猜谜。第三代智能化的搜索,主要体现在个性化,能够理解部分人的意图和情感,个性化的推荐,人机智能问答等等。RNN(递归神经网络)将发挥重要作用,包括机器翻译。。。其中,消除歧义分词,语义分析是重中之重。比如吃苹果,分词结果是吃/苹果,苹果的语义标注有很多,例如水果,手机,电脑,logo等等。基于CRF和viterbi算法,可以预测出这句话中的苹果语义是水果,这样在搜索时,就可以构造出搜索词:苹果水果的分类,降低了不确定性。中文分词是nlp的基础,而信息检索又离不开NLP。在目前国内的聊天机器人中,度秘是最优秀的,小黄鸡等还差的很远。在学习RNN等深度学习技术之前,一定要把基础性的知识学好,不可好高骛远。下面进入到第一部分:
第一部分:VSM
VSM简称向量空间模型,主要用于计算文档的相似度。计算文档相似度时,需要提取重要特征。特征提取一般用最通用常规的方法:TF-IDF算法。这个方法非常简单但是却非常实用。给你一篇文章,用中文分词工具(目前最好的是opennlp社区中的开源源码包HanLP)对文档进行切分,处理成词向量(去除停词后的结果),然后计算TF-IDF,按降序排列,排在前几位的就是重要特征。这里不论述TF-IDF,因为太简单了。那么对于一个查询q来说,经过分词处理后形成查询向量T[t1,t2……],给每个t赋予权重值,假设总共查询到n个文档,把每个文档处理成向量(按t处理),计算每个t在各自文档中的TF-IDF。然后分别计算与T向量的余弦相似度,得出的分数按降序排列。


VSM的本质是:计算查询和文档内容的相似度。没有考虑到相关性。因为用户输入一个查询,最想得到的是相关度大的文档,而不只是这个文档中出现了查询词。因为某篇文档出现了查询词,也不一定是相关性的,所以需要引入概率模型。后面要讲的BIM还有BM25本质是:计算查询和用户需求的相似度。所以BM25会有很好的表现。而lucen底层默认的评分扩展了VSM。下面进入第二部分,lucent的默认评分公式:
二、lucene默认的评分公式介绍
Lucene 评分体系/机制(lucene scoring)是 Lucene 出名的一核心部分。它对用户来说隐藏了很多复杂的细节,致使用户可以简单地使用 lucene。但个人觉得:如果要根据自己的应用调节评分(或结构排序),十分有必须深入了解 lucene 的评分机制。
Lucene scoring 组合使用了 信息检索的向量空间模型 和 布尔模型 。
首先来看下 lucene 的评分公式(在 Similarity 类里的说明)
|
其中:
- tf(t in d) 关联到项频率,项频率是指 项 t 在 文档 d 中出现的次数 frequency。默认的实现是:
tf(t in d) = frequency½ - idf(t) 关联到反转文档频率,文档频率指出现 项 t 的文档数 docFreq。docFreq 越少 idf 就越高(物以稀为贵),但在同一个查询下些值是相同的。默认实现:
idf(t) = 1 + log ( numDocs ––––––––– docFreq+1 ) - 关于idf(t)应该这样认识:一个词语在文档集合中出现了n次,文档集合总数为N。idf(t)来源于信息论。那么每篇文档出现这个词语的概率为:n/N,所以这篇文档出现这个词语的信息量为:-log(n/N)。这个和信息熵有些类似(-P(x)logP(x)),在数据挖掘的过滤法进行特征选择时,需要用到互信息,其实是计算信息增益,还有决策树。把-log(n/N)变换一下,log(N/n),为了避免0的出现,进行平滑处理,就是上面的公式(就像朴素贝叶斯需要拉普拉斯平滑处理一样)。
- coord(q,d) 评分因子,是基于文档中出现查询项的个数。越多的查询项在一个文档中,说明些文档的匹配程序越高。默认是出现查询项的百分比。
- queryNorm(q)查询的标准查询,使不同查询之间可以比较。此因子不影响文档的排序,因为所有有文档 都会使用此因子。默认值:
queryNorm(q) = queryNorm(sumOfSquaredWeights) = 1 –––––––––––––– sumOfSquaredWeights½ 每个查询项权重的平分方和(sumOfSquaredWeights)由 Weight 类完成。例如 BooleanQuery 地计算:
sumOfSquaredWeights = q.getBoost() 2 · ∑ ( idf(t) · t.getBoost() ) 2 t in q - t.getBoost()查询时期的 项 t 加权(如:java^1.2),或者由程序使用 setBoost()。
- norm(t,d)压缩几个索引期间的加权和长度因子:
- Document boost - 文档加权,在索引之前使用 doc.setBoost()
- Field boost - 字段加权,也在索引之前调用 field.setBoost()
- lengthNorm(field) - 由字段内的 Token 的个数来计算此值,字段越短,评分越高,在做索引的时候由 Similarity.lengthNorm 计算。
以上所有因子相乘得出 norm 值,如果文档中有相同的字段,它们的加权也会相乘:norm(t,d) = doc.getBoost() · lengthNorm(field) · ∏ f.getBoost() field f in d named as t 索引的时候,把 norm 值压缩(encode)成一个 byte 保存在索引中。搜索的时候再把索引中 norm 值解压(decode)成一个 float 值,这个 encode/decode 由 Similarity 提供。官方说:这个过程由于精度问题,以至不是可逆的,如:decode(encode(0.89)) = 0.75。
总体来说,这个评分公式仍然是基于查询与文档内容的相似度计算分数。而且,lengthNorm(field) = 1/sqrt(numTerms),即文档的索引列越长,分值越低。这个显然是不合理的,需要改进。而且这个评分公式仅仅考虑了查询词在文档向量中的TF,并没有考虑在T(查询向量)中的TF,而且,如果一篇文档越长,它的TF一般会越高,会成一定的正相关性。这对于短文档来说计算TF是不公平的。在用这个公式打分的时候,需要对文档向量归一化处理,其中的lengthNorm如何处理是个问题。举个例子,在用球拍打羽毛球的时候,球拍会有一个最佳击球和回球的区域,被成为"甜区"。在处理文档向量的长度时候,我们同样可以规定一个"甜区",比如min/max,超过这个范围的,lengthNorm设置为1。基于以上缺点,需要改进排序模型,让查询和用户的需求更加相关,所以提出了概率模型,下面进入第三部分:
三、概率语言模型中的二元独立模型BIM介绍
概率检索模型是从概率排序原理推导出来的,所以理解这一原理对于理解概率检索模型非常重要。概率排序模型的思想是:给定一个查询,返回的文档能够按照查询和用户需求的相关性得分高低排序。这是一种对用户需求相关性建模的方法。按照如下思路进行思考:首先,我们可以对查询后得到的文档进行分类:相关文档和非相关文档。这个可以按照朴素贝叶斯的生成学习模型进行考虑。如果这个文档属于相关性的概率大于非相关性的,那么它就是相关性文档,反之属于非相关性文档。所以,引入概率模型:P(R|D)是一个文档相关性的概率,P(NR|D)是一个文档非相关性的概率。如果P(R|D) > P(NR|D),说明它与查询相关,是用户想要的。按照这个思路继续,怎样才能计算这个概率呢?如果你熟悉朴素贝叶斯的话,就容易了。P(R|D) = P(D|R)P(R)/P(D),P(NR|D) = P(D|NR)P(NR)/P(D)。用概率模型计算相关性的目的就是判断一个文档是否P(R|D) > P(NR|D),即P(D|R)P(R)/P(D) > P(D|NR)P(NR)/P(D) <=> P(D|R)P(R) > P(D|NR)P(NR) <=> P(D|R)/P(D|NR) > P(NR)/P(R)。对于搜索来说,并不需要真的进行分类,只需计算P(D|R)/P(D|NR)然后按降序排列即可。于是引入二元独立模型(Binary Independent Model) 假设=>
①二元假设:在对文档向量进行数据建模时,假设特征的值属于Bernoulli分布,其值为0或者1(朴素贝叶斯就适用于特整值和分类值都属于Bernoulli分布的情况,而loggistic Regression适用于分类值为Bernoulli分布)。在文本处理领域,就是这个特征在文档中出现或者不出现,不考虑词频。
②词汇独立性假设:假设构成每个特征的词是相互独立的,不存在关联性。在机器学习领域里,进行联合似然估计或者条件似然估计时,都是假设数据遵循iid分布。事实上,词汇独立假设是非常不合理的。比如"乔布斯"和"ipad"和"苹果"是存在关联的。
有了上面的假设,就可以计算概率了。比如,有一篇文档D,查询向量由5个Term组成,在D中的分布情况如下:[1,0,1,01]。那么,P(D|R) = P1*(1-P2)*P3*(1-P4)*P5。Pi为特征在D中出现的概率,第二个和第四个词汇没有出现,所以用(1-P2)和(1-P4)。这是文档属于相关性的概率,生成模型还需要计算非相关性的概率情况。用Si表示特征在非相关性文档中出现的概率,那么P(D|NR)=S1*(1-S2)*S3*(1-S4)*S5。 =>
=>
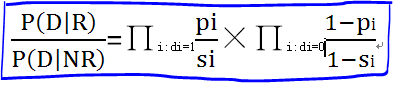 ,这个公式中第一项代表在D中出现的各个特征概率乘积,第二项表示没有在D中出现的概率乘积。进一步变换得到:
,这个公式中第一项代表在D中出现的各个特征概率乘积,第二项表示没有在D中出现的概率乘积。进一步变换得到:

这个公式里,第一部分是文档里出现的特征概率乘积,第二项是所有特征的概率乘积,是从全局计算得出。对于特定的文档,第二项对排序没有影响,计算结果都是一样的,所以去掉。于是,得出最终结果: 。为了计算方便,对这个公式取对数:
。为了计算方便,对这个公式取对数: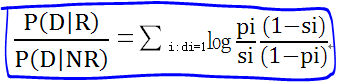 。进一步求解这个公式:
。进一步求解这个公式: ,
, 。其中,N表示文档集合总数,R表示相关文档总数,那么N-R就是非相关文档数目,ni表示包含特征di的文档数目,在这其中属于相关文档的数目是ri。于是,
。其中,N表示文档集合总数,R表示相关文档总数,那么N-R就是非相关文档数目,ni表示包含特征di的文档数目,在这其中属于相关文档的数目是ri。于是, 。当出现一个查询q和返回文档时,只需计算出现的特征的概率乘积,和朴素贝叶斯的predict原理是一样的。这个公式,在特定情况下可以转化为IDF模型。上述公式就是BM25模型的基础。下面来讲述第四部分。
。当出现一个查询q和返回文档时,只需计算出现的特征的概率乘积,和朴素贝叶斯的predict原理是一样的。这个公式,在特定情况下可以转化为IDF模型。上述公式就是BM25模型的基础。下面来讲述第四部分。
四、BM25模型
BIM模型基于二元独立假设推导出,只考虑特征是否出现,不考虑TF因素。那么,如果在这个基础之上再考虑Tf因素的话,会更加完美,于是,有人提出了BM25模型。加入了词汇再查询向量中的权值以及在文档中的权值还有一系列经验因子。公式如下:
第一项就是BIM模型推导出的公式,因为在搜索的时候,我们不知道哪些是相关的哪些不是相关的,所以把ri和R设置为0,于是,第一项退化成了
就是IDF!非常神奇! ,fi是特征在文档D中的TF权值,qfi是特征在查询向量中的TF权值。一般情况下,k1=1.2,b=0.75,k2=200.当查询向量比较短的时候,qfi通常取值为1。分析来看,当K1=0时,第二项不起作用,也就是不考虑特征在文档中的TF权值,当k2=0时,第三项也失效。从中可以看出,k1和k2值是对特征在文档或者查询向量中TF权值的惩罚因子。综合来看,BM25考虑了4个因素:IDF因子,文档长度因子,文档词频因子和查询词频因子。lucene内部的BM25要比上面公式的简单一些,个人认为并不是很好。其实lucene内部有很多的算法并不是最优的,有待提升!有了以上4个部分,相信大部分人会对lucene的评分公式有了很深入的了解,下面进入源代码解读和修改阶段,主要是为了能够满足根据时间业务场景自定义排序。进入第五部分:
,fi是特征在文档D中的TF权值,qfi是特征在查询向量中的TF权值。一般情况下,k1=1.2,b=0.75,k2=200.当查询向量比较短的时候,qfi通常取值为1。分析来看,当K1=0时,第二项不起作用,也就是不考虑特征在文档中的TF权值,当k2=0时,第三项也失效。从中可以看出,k1和k2值是对特征在文档或者查询向量中TF权值的惩罚因子。综合来看,BM25考虑了4个因素:IDF因子,文档长度因子,文档词频因子和查询词频因子。lucene内部的BM25要比上面公式的简单一些,个人认为并不是很好。其实lucene内部有很多的算法并不是最优的,有待提升!有了以上4个部分,相信大部分人会对lucene的评分公式有了很深入的了解,下面进入源代码解读和修改阶段,主要是为了能够满足根据时间业务场景自定义排序。进入第五部分:
五、edismax解析器介绍:
之所以介绍这个查询解析器,是因为特殊的业务场景需要。lucene的源码包中,两大核心包,org.apache.lucene.index和org.apache.lucene.search。其中第一个包会调用store、util和document子包,第二个会和queryParser和analysis、message子包交互。在查询中,最重要的就是queryParser。当用户输入查询字符串后,调用lucene的查询服务,要调用QueryParser类,第一步是调用analyzer(分词)形成查询向量T[t1,t2……tn],这一步是词法分析,接下来是句法分析,形成查询语法,即先形成QueryNode--->QueryTree  .t1和t2之间是逻辑与的关系,用Boolean查询。这样lucene就能理解查询语法了。为了加深理解,先看一段代码:
.t1和t2之间是逻辑与的关系,用Boolean查询。这样lucene就能理解查询语法了。为了加深理解,先看一段代码:
package com.txq.lucene.queryParser;
import java.io.IOException;
import java.io.StringReader;
import java.util.ArrayList;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.util.Version;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.PhraseQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.BooleanClause.Occur;
import org.apache.lucene.index.Term;
/**
* 自定义一个查询解析器,BooleanQuery
* @author XueQiang Tong
*
*/
public class BlankAndQueryParser extends QueryParser {
// analyzer = new IKAnalyzer(false);
public BlankAndQueryParser(Version matchVersion, String field, Analyzer analyzer) {
super(matchVersion, field, analyzer);
}
protected Query getFieldQuery(String field,String queryText,int slop) throws ParseException{
try {
TokenStream ts = this.getAnalyzer().tokenStream(field, new StringReader(queryText));
OffsetAttribute offset = (OffsetAttribute) ts.addAttribute(OffsetAttribute.class);
CharTermAttribute term = (CharTermAttribute) ts.addAttribute(CharTermAttribute.class);
TypeAttribute type = (TypeAttribute) ts.addAttribute(TypeAttribute.class);
ts.reset();
ArrayList<CharTermAttribute> v = new ArrayList<CharTermAttribute>();
while (ts.incrementToken()) {
// System.out.println(offset.startOffset() + " - "
// + offset.endOffset() + " : " + term.toString() + " | "
// + type.type());
if(term.toString() == null){
break;
}
v.add(term);
}
ts.end();
ts.close();
if(v.size() == 0){
return null;
} else if (v.size() == 1){
return new TermQuery(new Term(field,v.get(0).toString()));
} else {
PhraseQuery q = new PhraseQuery();
BooleanQuery b = new BooleanQuery();
q.setBoost(2048.0f);
b.setBoost(0.001f);
for(int i = 0;i < v.size();i++){
CharTermAttribute t = v.get(i);
//q.add(new Term(field,t.toString()));
TermQuery tmp = new TermQuery(new Term(field,t.toString()));
tmp.setBoost(0.01f);
b.add(tmp, Occur.MUST);
}
return b;
}
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
protected Query getFieldQuery(String field,String queryText) throws ParseException{
return getFieldQuery(field,queryText,0);
}
}
上面这段代码,展示了QueryParser的基本步骤,需要分词器,我用的是去年自己写的基于逆向最大匹配算法的分词器(由IK分词改造而来)。从上面能够基本了解BooleanQuery的工作原理了。去年写的两个数组取交集的算法,就是布尔查询为AND的逻辑问题抽象。短语查询精确度最高,在倒排索引项中存储有词元的位置信息,就是提供短语查询功能支持的。
现在回归到第五部分的内容,现在有一个排序业务场景:有一个电商平台,交易量非常火,点击量比较大,需要自定义一个更加合理的符合自己公司的排序需求。先提出如下需求:要求按照入住商家的时间,商家是否为VIP以及商品的点击率(point)综合考虑三者因素得出最后的评分。为了完成这样一项排序任务,先梳理以下思路:这个排序要求,按照lucene现有的score公式肯定满足不了,这是属于用户在外部自定义的排序规则,与底层的排序规则不相干。能够满足这样需求的只有solr的edismax解析器。所以按照如下思路:先了解一下edismax怎么使用(比如可以在外部定义linear函数实现规则),然后还需要解析器的内部原理(看源代码),看看它与底层的score有何种关系(不可能没有关系,所以需要深入研读源代码,看看有没有必要修改lucene底层的score源代码)。按照上面的思路开展工作,查看源代码后发现,最终得分是外部传递的评分函数与底层score的乘积,dismax解析器是相加。如果用dismax解析器的话,相加不能突出上述规则的作用,所以最好用edismax解析器。从理论上分析,如果底层使用VSM模型或者是BM25模型的话,score打分会对业务排序规则产生影响,比如有的商家是VIP,点击率很高,但是底层的score可能很低,这样一相乘的话,最后得分就不准确了,所以需要把底层的score写死,改为1,消除影响。所以,按照这个规则,评分函数,点击率高的排在前面(在point前设置比较高的权重)是比较合理的。
为了验证以上想法的正确性,可以先定义评分函数,不修改底层的score,看看排序效果,排序是混乱的 。所以,根据上面的分析,需要从基本的lucene底层的score打分源代码开始研究,然后edismax源代码。在修改lucene的score源代码的时候,最好不要用jd-gui反编译工具,最开始用的时候,得到的代码只有部分是正确的。用maven构建项目时,直接下载以来的包,包括lucene-core-4.9.0-sources.jar,修改源码包,然后重新编译打包,替换掉原来的包。这是一项繁琐的工程,包括后面的博客中介绍的机器学习排序,构建文档数据特征时,需要获取BM25信息,同样需要lucene源代码,构建训练系统和预测系统。
lucene评分流程:以BooleanQuery为例,可以参看上面写的QueryParser,BooleanQuery需要用到TermQuery,那么这个打分就由它完成。TermQuery继承了Query,所以需要实现createWeight方法,得到的是Weight的子类TermWeight。TermWeight需要实现scorer方法得到Scorer,然后调用Scorer的score方法。先看一下TermQuery的createWeight:
public Weight createWeight(IndexSearcher searcher)
throws IOException
{
IndexReaderContext context = searcher.getTopReaderContext();
TermContext termState;
if(perReaderTermState == null || perReaderTermState.topReaderContext != context)
termState = TermContext.build(context, term);
else
termState = perReaderTermState;
if(docFreq != -1)
termState.setDocFreq(docFreq);
return new TermWeight(searcher, termState);
}
查询文档由IndexSearcher完成,然后得到TermWeight类。再看看TermWeight的scorer:
public Scorer scorer(AtomicReaderContext context, Bits acceptDocs)
throws IOException
{
if(!$assertionsDisabled && termStates.topReaderContext != ReaderUtil.getTopLevelContext(context))
throw new AssertionError((new StringBuilder()).append("The top-reader used to create Weight (").append(termStates.topReaderContext).append(") is not the same as the current reader's top-reader (").append(ReaderUtil.getTopLevelContext(context)).toString());
TermsEnum termsEnum = getTermsEnum(context);
if(termsEnum == null)
return null;
DocsEnum docs = termsEnum.docs(acceptDocs, null);
if(!$assertionsDisabled && docs == null)
throw new AssertionError();
else
return new TermScorer(this, docs, similarity.simScorer(stats, context));
}
得到了TermScorer类。调用这个对象的score方法(调用了Similarity)
public float score()
throws IOException
{
if(!$assertionsDisabled && docID() == 2147483647)
throw new AssertionError();
else
return docScorer.score(docsEnum.docID(), docsEnum.freq());
}
private final org.apache.lucene.search.similarities.Similarity.SimScorer docScorer;//这是Similarity的内部抽象类
docScorer.score方法由很多实现者,这里用BM25Similarity extends Similarity,主要实现SimScorer的explain方法,这是最终打分的函数,通过Explain对象获取到得分。
public abstract class Similarity
{
public static abstract class SimWeight
{
public abstract float getValueForNormalization();
public abstract void normalize(float f, float f1);
public SimWeight()
{
}
}
public static abstract class SimScorer
{
public abstract float score(int i, float f);
public abstract float computeSlopFactor(int i);
public abstract float computePayloadFactor(int i, int j, int k, BytesRef bytesref);
public Explanation explain(int doc, Explanation freq)
{
Explanation result = new Explanation(score(doc, freq.getValue()), (new StringBuilder()).append("score(doc=").append(doc).append(",freq=").append(freq.getValue()).append("), with freq of:").toString());
result.addDetail(freq);
return result;
}
public SimScorer()
{
}
}
看一看BM25Similarity:
package org.apache.lucene.search.similarities;
import java.io.IOException;
import org.apache.lucene.index.*;
import org.apache.lucene.search.*;
import org.apache.lucene.util.BytesRef;
import org.apache.lucene.util.SmallFloat;
public class BM25Similarity extends Similarity
{
private static class BM25Stats extends Similarity.SimWeight
{
public float getValueForNormalization()
{
float queryWeight = idf.getValue() * queryBoost;
return queryWeight * queryWeight;
}
public void normalize(float queryNorm, float topLevelBoost)
{
this.topLevelBoost = topLevelBoost;
weight = idf.getValue() * queryBoost * topLevelBoost;
}
private final Explanation idf;
private final float avgdl;
private final float queryBoost;
private float topLevelBoost;
private float weight;
private final String field;
private final float cache[];
BM25Stats(String field, Explanation idf, float queryBoost, float avgdl, float cache[])
{
this.field = field;
this.idf = idf;
this.queryBoost = queryBoost;
this.avgdl = avgdl;
this.cache = cache;
}
}
private class BM25DocScorer extends Similarity.SimScorer
{
public float score(int doc, float freq)
{
float norm = norms != null ? cache[(byte)(int)norms.get(doc) & 255] : k1;
return (weightValue * freq) / (freq + norm);
}
public Explanation explain(int doc, Explanation freq)
{
return explainScore(doc, freq, stats, norms);//这是最终打分函数
}
public float computeSlopFactor(int distance)
{
return sloppyFreq(distance);
}
public float computePayloadFactor(int doc, int start, int end, BytesRef payload)
{
return scorePayload(doc, start, end, payload);
}
private final BM25Stats stats;
private final float weightValue;
private final NumericDocValues norms;
private final float cache[];
final BM25Similarity this$0;
BM25DocScorer(BM25Stats stats, NumericDocValues norms)
throws IOException
{
this$0 = BM25Similarity.this;
super();
this.stats = stats;
weightValue = stats.weight * (k1 + 1.0F);
cache = stats.cache;
this.norms = norms;
}
}
public BM25Similarity(float k1, float b)
{
discountOverlaps = true;
this.k1 = k1;
this.b = b;
}
public BM25Similarity()
{
discountOverlaps = true;
k1 = 1.2F;
b = 0.75F;
}
protected float idf(long docFreq, long numDocs)
{
return (float)Math.log(1.0D + ((double)(numDocs - docFreq) + 0.5D) / ((double)docFreq + 0.5D));
}
protected float sloppyFreq(int distance)
{
return 1.0F / (float)(distance + 1);
}
protected float scorePayload(int doc, int start, int end, BytesRef bytesref)
{
return 1.0F;
}
protected float avgFieldLength(CollectionStatistics collectionStats)
{
long sumTotalTermFreq = collectionStats.sumTotalTermFreq();
if(sumTotalTermFreq <= 0L)
return 1.0F;
else
return (float)((double)sumTotalTermFreq / (double)collectionStats.maxDoc());
}
protected byte encodeNormValue(float boost, int fieldLength)
{
return SmallFloat.floatToByte315(boost / (float)Math.sqrt(fieldLength));
}
protected float decodeNormValue(byte b)
{
return NORM_TABLE[b & 255];
}
public void setDiscountOverlaps(boolean v)
{
discountOverlaps = v;
}
public boolean getDiscountOverlaps()
{
return discountOverlaps;
}
public final long computeNorm(FieldInvertState state)
{
int numTerms = discountOverlaps ? state.getLength() - state.getNumOverlap() : state.getLength();
return (long)encodeNormValue(state.getBoost(), numTerms);
}
public Explanation idfExplain(CollectionStatistics collectionStats, TermStatistics termStats)
{
long df = termStats.docFreq();
long max = collectionStats.maxDoc();
float idf = idf(df, max);
return new Explanation(idf, (new StringBuilder()).append("idf(docFreq=").append(df).append(", maxDocs=").append(max).append(")").toString());
}
public Explanation idfExplain(CollectionStatistics collectionStats, TermStatistics termStats[])
{
long max = collectionStats.maxDoc();
float idf = 0.0F;
Explanation exp = new Explanation();
exp.setDescription("idf(), sum of:");
TermStatistics arr$[] = termStats;
int len$ = arr$.length;
for(int i$ = 0; i$ < len$; i$++)
{
TermStatistics stat = arr$[i$];
long df = stat.docFreq();
float termIdf = idf(df, max);
exp.addDetail(new Explanation(termIdf, (new StringBuilder()).append("idf(docFreq=").append(df).append(", maxDocs=").append(max).append(")").toString()));
idf += termIdf;
}
exp.setValue(idf);
return exp;
}
public final transient Similarity.SimWeight computeWeight(float queryBoost, CollectionStatistics collectionStats, TermStatistics termStats[])
{
Explanation idf = termStats.length != 1 ? idfExplain(collectionStats, termStats) : idfExplain(collectionStats, termStats[0]);
float avgdl = avgFieldLength(collectionStats);
float cache[] = new float[256];
for(int i = 0; i < cache.length; i++)
cache[i] = k1 * ((1.0F - b) + (b * decodeNormValue((byte)i)) / avgdl);
return new BM25Stats(collectionStats.field(), idf, queryBoost, avgdl, cache);
}
public final Similarity.SimScorer simScorer(Similarity.SimWeight stats, AtomicReaderContext context)
throws IOException
{
BM25Stats bm25stats = (BM25Stats)stats;
return new BM25DocScorer(bm25stats, context.reader().getNormValues(bm25stats.field));
}
private Explanation explainScore(int doc, Explanation freq, BM25Stats stats, NumericDocValues norms)
{
Explanation result = new Explanation();
result.setDescription((new StringBuilder()).append("score(doc=").append(doc).append(",freq=").append(freq).append("), product of:").toString());
Explanation boostExpl = new Explanation(stats.queryBoost * stats.topLevelBoost, "boost");
if(boostExpl.getValue() != 1.0F)
result.addDetail(boostExpl);
result.addDetail(stats.idf);
Explanation tfNormExpl = new Explanation();
tfNormExpl.setDescription("tfNorm, computed from:");
tfNormExpl.addDetail(freq);
tfNormExpl.addDetail(new Explanation(k1, "parameter k1"));
if(norms == null)
{
tfNormExpl.addDetail(new Explanation(0.0F, "parameter b (norms omitted for field)"));
tfNormExpl.setValue((freq.getValue() * (k1 + 1.0F)) / (freq.getValue() + k1));
} else
{
float doclen = decodeNormValue((byte)(int)norms.get(doc));
tfNormExpl.addDetail(new Explanation(b, "parameter b"));
tfNormExpl.addDetail(new Explanation(stats.avgdl, "avgFieldLength"));
tfNormExpl.addDetail(new Explanation(doclen, "fieldLength"));
tfNormExpl.setValue((freq.getValue() * (k1 + 1.0F)) / (freq.getValue() + k1 * ((1.0F - b) + (b * doclen) / stats.avgdl)));
}
result.addDetail(tfNormExpl);
result.setValue(boostExpl.getValue() * stats.idf.getValue() * tfNormExpl.getValue());
return result;
}
public String toString()
{
return (new StringBuilder()).append("BM25(k1=").append(k1).append(",b=").append(b).append(")").toString();
}
public float getK1()
{
return k1;
}
public float getB()
{
return b;
}
private final float k1;
private final float b;
protected boolean discountOverlaps;
private static final float NORM_TABLE[];
static
{
NORM_TABLE = new float[256];
for(int i = 0; i < 256; i++)
{
float f = SmallFloat.byte315ToFloat((byte)i);
NORM_TABLE[i] = 1.0F / (f * f);
}
}
}
从上面的代码可以看出,要修改的话,就修改explainScore方法,把影响因素全部改为1就行了,因为获取评分是通过Explain对象。
以上就是lucene底层的评分流程:BooleanQuery----->TermQuery----->createWeight----->TermWeight.scorer()------>TermScorer----TermScorer.score()------->(Similarity内部抽象类)SimScorer.explain()------->BM25Similarity的explainScore方法。最后看一下edismax解析器的源代码:
六、为机器学习排序做准备:
下面进一步深入思考,加入由如下示例的查询:
String[] fields = {"name","content"};
QueryParser queryParser = new MultiFieldQueryParser(matchVersion, fields,analyzer);
Query query = queryParser.parse(queryString);
BooleanQuery bq = new BooleanQuery();
bq.add(query, Occur.MUST);
IndexSearcher indexSearcher = new IndexSearcher((IndexReader)DirectoryReader.open(FSDirectory.open(new File("/Users/ChinaMWorld/Desktop/index/"))));
Filter filter = null;
//查询前10000条记录
TopDocs topDocs = indexSearcher.search(bq,filter,10000);
现在我要求不用lucene以及solr的所有的评分,用机器学习排序,先构建训练系统,然后预测,最后排序。问题的关键是在lucene返回排序的文档之前截取结果(ScoreDocs),截取到的这些文档具有BM25信息,但是还没有排序,我们把它先截取下来,然后构建文档向量,开始数据建模(训练时需要样本的评分,可以在点击图中转化,把点击率转化为评分),然后进入机器学习系统训练评分函数。训练时可以这样,获取一段时间内用户的搜索图和点击图,得到文档及对应的评分。然后再模拟用户的搜索词,获取到相同的文档,这个时候用我们改造过的代码,截取到未排序前的ScoreDoc。然后开始数据建模,训练。当用户再搜索时,仍然截取到上述文档,把这些文档转到predict系统中,最后加入到自定义的PriorityQueue(区别于JDK的)排序,得到最终结果。有了思路后,就开始实施,在实施的过程中其实是有一定难度的。先从最外部的代码一步步抽丝剥茧,找到答案。上面的示例代码是有问题的,在正式的生产环境中,IndexSearch()构造器中一定要传递CompletionService,满足多线程的要求。从indexSearcher.search(bq,filter,10000)开始进入源代码内部,我们的任务是找到未排序前的代码,截取下来进行改造。------>
public TopDocs search(Query query, Filter filter, int n)throws IOException
{
return search(createNormalizedWeight(wrapFilter(query, filter)), ((ScoreDoc) (null)), n);
}//这个query是我们制定的BooleanQuery,createNormalizedWeight方法产生Weight的子类BooleanWeight,里面的评分方法需要的Similarity由我们在配置文件中指定:<similarity class="org.apache.lucene.search.similarities.BM25Similarity"/>,运行原理跟前面的一样了,都是Bm25Similarity评分。接着继续看serach方法:
protected TopDocs search(Weight weight, ScoreDoc after, int nDocs)
throws IOException
{
int limit = reader.maxDoc();
if(limit == 0)
limit = 1;
if(after != null && after.doc >= limit)
throw new IllegalArgumentException((new StringBuilder()).append("after.doc exceeds the number of documents in the reader: after.doc=").append(after.doc).append(" limit=").append(limit).toString());
nDocs = Math.min(nDocs, limit);
if(executor == null)
return search(leafContexts, weight, after, nDocs);-------------①
HitQueue hq = new HitQueue(nDocs, false);
Lock lock = new ReentrantLock();
ExecutionHelper runner = new ExecutionHelper(executor);------------②
for(int i = 0; i < leafSlices.length; i++)
runner.submit(new SearcherCallableNoSort(lock, this, leafSlices[i], weight, after, nDocs, hq));---------------------③
int totalHits = 0;
float maxScore = (-1.0F / 0.0F);
Iterator i$ = runner.iterator();
do
{
if(!i$.hasNext())
break;
TopDocs topDocs = (TopDocs)i$.next();
if(topDocs.totalHits != 0)
{
totalHits += topDocs.totalHits;
maxScore = Math.max(maxScore, topDocs.getMaxScore());
}
} while(true);
ScoreDoc scoreDocs[] = new ScoreDoc[hq.size()];
for(int i = hq.size() - 1; i >= 0; i--)
scoreDocs[i] = (ScoreDoc)hq.pop();//排序--------------④
return new TopDocs(totalHits, scoreDocs, maxScore);
}
标出了4个序号:第①出直接越过去了,第②处的ExecutionHelper对象封装了CompletionService,如果对jdk1.7及以后版本的多线程,还有lunece内部的PriorityQueue的设计思想以及CAS,ReentrantLock这些都不了解的话,自己补一补。把代码贴出来:
private static final class ExecutionHelper
implements Iterator, Iterable
{
public boolean hasNext()
{
return numTasks > 0;
}
public void submit(Callable task)
{
service.submit(task);
numTasks++;
}
public Object next()
{
if(!hasNext())
throw new NoSuchElementException("next() is called but hasNext() returned false");
Object obj;
try
{
obj = service.take().get();
}
catch(InterruptedException e)
{
throw new ThreadInterruptedException(e);
}
catch(ExecutionException e)
{
throw new RuntimeException(e);
}
numTasks--;
return obj;
Exception exception;
exception;
numTasks--;
throw exception;
}
public void remove()
{
throw new UnsupportedOperationException();
}
public Iterator iterator()
{
return this;
}
private final CompletionService service;
private int numTasks;
ExecutionHelper(Executor executor)
{
service = new ExecutorCompletionService(executor);
}
}
第③处是我们要改造的地方,是submit()方法里面的东东:new SearcherCallableNoSort(lock, this, leafSlices[i], weight, after, nDocs, hq),从名字上就能看出来,是非排序的查询结果集。submit方法调用的是Callabel,所以看一下SearcherCallableNoSort的call()方法---------------->
private static final class SearcherCallableNoSort
implements Callable
{
public TopDocs call()
throws IOException
{
TopDocs docs;
ScoreDoc scoreDocs[];
docs = searcher.search(Arrays.asList(slice.leaves), weight, after, nDocs);//这里就不往下追踪了,跟前面讲的BM25Similarity排序是一样的
scoreDocs = docs.scoreDocs;
lock.lock();
int j = 0;
do
{
if(j >= scoreDocs.length)
break;
ScoreDoc scoreDoc = scoreDocs[j];
//问题的关键在这里,得到scoreDoc后,由于已经获取了BM25参数,接下来把ScoreDoc处理成向量,开始
//数据建模,然后进入机器学习训练系统,学习评分函数,后面的代码可以用在predict后获得每个文档的
//分数,然后加入到优先级队列中排序
if(scoreDoc == hq.insertWithOverflow(scoreDoc))
break;
j++;
} while(true);
lock.unlock();
break MISSING_BLOCK_LABEL_106;
Exception exception;
exception;
lock.unlock();
throw exception;
return docs;
}
public volatile Object call()
throws Exception
{
return call();
}
private final Lock lock;
private final IndexSearcher searcher;
private final Weight weight;
private final ScoreDoc after;
private final int nDocs;
private final HitQueue hq;
private final LeafSlice slice;
public SearcherCallableNoSort(Lock lock, IndexSearcher searcher, LeafSlice slice, Weight weight, ScoreDoc after, int nDocs, HitQueue hq)
{
this.lock = lock;
this.searcher = searcher;
this.weight = weight;
this.after = after;
this.nDocs = nDocs;
this.hq = hq;
this.slice = slice;
}
}
需要把代码改造成训练系统和predict系统两个版本。到此为止,这篇博客算是写完了,还差edismax解析器的源代码解读,单独写一篇文章吧,下一篇博客将开始研究ListNet算法(机器学习排序的一种)……
另外,关于RNN的理解和应用,可以参考一些一线专家从实践中总结出来的心得,在结合一下理论效果会比较好。在微信公众号中搜索深度学习大讲堂 公众号,中科视拓的公众号,很不错的,包括tensorflow的源码解析,很系统。学习这些技术,没有捷径,必须多实践,多动手,多编程,多思考。上帝是公平的,付出多了,会有回报的。
佟氏出品,必属精品!坚持独立思考,大胆假设,小心求证,技术进步永无止境………………………………
原创:史上对BM25模型最全面最深刻的解读以及lucene排序深入讲解的更多相关文章
- 【原创+史上最全】Nginx+ffmpeg实现流媒体直播点播系统
#centos6.6安装搭建nginx+ffmpeg流媒体服务器 #此系统实现了视频文件的直播及缓存点播,并支持移动端播放(支持Apple和Android端) #系统需要自行安装,流媒体服务器配置完成 ...
- 史上最全的maven pom.xml文件教程详解
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/20 ...
- GitHub上史上最全的Android开源项目分类汇总 (转)
GitHub上史上最全的Android开源项目分类汇总 标签: github android 开源 | 发表时间:2014-11-23 23:00 | 作者:u013149325 分享到: 出处:ht ...
- 移动端IM开发者必读(二):史上最全移动弱网络优化方法总结
1.前言 本文接上篇<移动端IM开发者必读(一):通俗易懂,理解移动网络的“弱”和“慢”>,关于移动网络的主要特性,在上篇中已进行过详细地阐述,本文将针对上篇中提到的特性,结合我们的实践经 ...
- 史上最全的spark面试题——持续更新中
史上最全的spark面试题——持续更新中 2018年09月09日 16:34:10 为了九亿少女的期待 阅读数 13696更多 分类专栏: Spark 面试题 版权声明:本文为博主原创文章,遵循C ...
- 【腾讯Bugly干货分享】OCS——史上最疯狂的iOS动态化方案
本文来自于腾讯Bugly公众号(weixinBugly),未经作者同意,请勿转载,原文地址:https://mp.weixin.qq.com/s/zctwM2Wf8c6_sxT_0yZvXg 导语 在 ...
- 史上最详细“截图”搭建Hexo博客并部署到Github
http://jingyan.baidu.com/article/d8072ac47aca0fec95cefd2d.html 大家也搭建过博客,很多时候,按着教程来做就可以了,但是我当时为了搭建Hex ...
- 史上最详细Windows版本搭建安装React Native环境配置 转载,比官网的靠谱亲测可用
史上最详细Windows版本搭建安装React Native环境配置 2016/01/29 | React Native技术文章 | Sky丶清| 95条评论 | 33530 views ...
- .Net魔法堂:史上最全的ActiveX开发教程——ActiveX与JS间交互篇
一.前言 经过上几篇的学习,现在我们已经掌握了ActiveX的整个开发过程,但要发挥ActiveX的真正威力,必须依靠JS.下面一起来学习吧! 二.JS调用ActiveX方法 只需在UserContr ...
随机推荐
- NEST dynamic 和 alias
/// <summary> /// Dynamic = false无法搜索 /// </summary> public void Dynamicmapping() { var ...
- 缓冲区溢出漏洞 ms04011
DSScan使用 扫描目标主机是否存在ms04011漏洞 getos使用 获取操作系统类型 > getos.exe 192.168.1.101 ------------------------- ...
- 如何在SAP gateway系统配置路由到后台系统的OData服务路径
看这张架构图,SAP Gateway系统也叫frontend系统,通过RFC远程调用SAP后台系统的OData服务实现. 以SAP CRM Fiori应用My Opportunity为例,使用事务码/ ...
- vue.js 样式绑定
简单用法 <div v-bind:height="bindStyle"> 复杂用法 <div v-bind:style="bindStyle" ...
- day 03作业
目录 作业 简述执行Python程序的两种方式以及他们的优缺点: 简述Python垃圾回收机制: 对于下述代码: 10的引用计数为多少? x对应的变量值257的引用计数为多少? 简述Python小整数 ...
- 03-JavaScript语法介绍
本篇主要关于原生JavaScript的介绍,其中包括其嵌入HTML页面方式,JavaScript的语法结构,以及贪吃蛇案例: 一.绪论 JavaScript是运行在浏览器端的脚步语言,JavaScri ...
- 【转】Vsftpd-3.0.2服务器arm-linux移植—mini2440开发板
Vsftpd-3.0.2服务器arm-linux移植—mini2440开发板 开发板:mini2440(2011.04.21)环境:ubuntu9.10 为方便的将文件上传到开发板,采用vsftpd, ...
- FreeBSD设置开机同步时间
没有设置开机同步时间的话,重启之后时间不对. 如果装机时没正确设置时区,先设置时区:# tzsetup 用date命令手工设置时间一方面不方便,另一方面也依赖于本地管理员的时钟的正确性,那么网络上不同 ...
- Linux命令——jobs、bg、fg、nohup
参考:Bash基础——工作管理(Job control) jobs -l :除了列出 job number 与命令串之外,同时列出 PID 的号码: -r :仅列出正在背景 run 的工作:-s :仅 ...
- web程序防止攻击的一些资料——整理
地址:https://docs.microsoft.com/en-us/previous-versions/aspnet/a2a4yykt(v=vs.100)?redirectedfrom=MSDN ...