ubuntu之路——day8.5 学习率衰减learning rate decay
在mini-batch梯度下降法中,我们曾经说过因为分割了baby batch,所以迭代是有波动而且不能够精确收敛于最小值的
因此如果我们将学习率α逐渐变小,就可以使得在学习率α较大的时候加快模型训练速度,在α变小的时候使得模型迭代的波动逐渐减弱,最终收敛于一个较小的区域来得到较为精确的结果
首先是公式1学习率衰减的标准公式:

其中decay rate即衰减率,epoch-num指的是遍历整个训练集的次数,α0是给定的初始学习率
其次是公式2指数衰减公式:
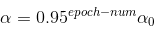
其中,0.95是一个小于1的初始值,可以指定
接下来公式3,k是一个常数:
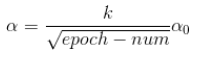
公式4,t是mini-batch的大小:
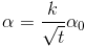
公式5:
离散下降法,每经过一定的迭代次数,指定更低的α即可
公式6:
手动下降法,适用于在小数据集上分步骤实验,可以随时指定α
ubuntu之路——day8.5 学习率衰减learning rate decay的更多相关文章
- 权重衰减(weight decay)与学习率衰减(learning rate decay)
本文链接:https://blog.csdn.net/program_developer/article/details/80867468“微信公众号” 1. 权重衰减(weight decay)L2 ...
- 跟我学算法-吴恩达老师(mini-batchsize,指数加权平均,Momentum 梯度下降法,RMS prop, Adam 优化算法, Learning rate decay)
1.mini-batch size 表示每次都只筛选一部分作为训练的样本,进行训练,遍历一次样本的次数为(样本数/单次样本数目) 当mini-batch size 的数量通常介于1,m 之间 当 ...
- pytorch learning rate decay
关于learning rate decay的问题,pytorch 0.2以上的版本已经提供了torch.optim.lr_scheduler的一些函数来解决这个问题. 我在迭代的时候使用的是下面的方法 ...
- ubuntu之路——day8.4 Adam自适应矩估计算法
基本上讲,Adam就是将day8.2提到的momentum动量梯度下降法和day8.3提到的RMSprop算法相结合的优化算法 首先初始化 SdW = 0 Sdb = 0 VdW = 0 Vdb = ...
- mxnet设置动态学习率(learning rate)
https://blog.csdn.net/xiaotao_1/article/details/78874336 如果learning rate很大,算法会在局部最优点附近来回跳动,不会收敛: 如果l ...
- ubuntu之路——day11.7 end-to-end deep learning
在传统的数据处理系统或学习系统中,有一些工作需要多个步骤进行,但是端到端的学习就是用一个神经网络来代替中间所有的过程. 举个例子,在语音识别中: X(Audio)----------MFCC----- ...
- ubuntu之路——day8.1 深度学习优化算法之mini-batch梯度下降法
所谓Mini-batch梯度下降法就是划分训练集和测试集为等分的数个子集,比如原来有500W个样本,将其划分为5000个baby batch,每个子集中有1000个样本,然后每次对一个mini-bat ...
- ubuntu之路——day8.3 RMSprop
RMSprop: 全称为root mean square prop,提及这个算法就不得不提及上篇博文中的momentum算法 首先来看看momentum动量梯度下降法的过程: 在RMSprop中: C ...
- ubuntu之路——day8.2 深度学习优化算法之指数加权平均与偏差修正,以及基于指数加权移动平均法的动量梯度下降法
首先感谢吴恩达老师的免费公开课,以下图片均来自于Andrew Ng的公开课 指数加权平均法 在统计学中被称为指数加权移动平均法,来看下面一个例子: 这是伦敦在一些天数中的气温分布图 Vt = βVt- ...
随机推荐
- MongoDB 4.2.1 安装失败,提示 verify that you have sufficient privileges to start system services 解决
官网下载地址:https://www.mongodb.com/download-center/community 问题: 解决:直接安装在根目录 测试:
- 如何在backoffice里创建Hybris image container以及分配给product
登录backoffice,在media container视图点击新建按钮: Catalog选择Product Catalog: 在Properties界面,可以选择media实例放入该contain ...
- 从零开始学虚拟DOM
此文主要翻译自:Building a Simple Virtual DOM from Scratch,看原文的同学请直达! 此文是作者在一次现场编程演讲时现场所做的,有关演讲的相关资料我们也可以在原英 ...
- AE二次开发,解决子窗体使用父窗体的AxControl控件
在子窗体写构造函数,然后再在父窗体按钮点击事件下写 public frmIDW(AxMapControl axMapControl1) { InitializeComponent(); this.ax ...
- linq 书籍推荐 博客汇总 (经典)
1.博客推荐 博客园linq专区 https://kb.cnblogs.com/zt/linq/ LINQ体验系列文章导航 https://www.cnblogs.com/lyj/archive/20 ...
- linux防火墙开放端口,针对固定ip开放端口
编辑/etc/sysconfig/iptables,添加 -A INPUT -m state --state NEW -m tcp -p tcp -s 127.0.0.1 --dport 6379 - ...
- C#入门概述
ASP.NET 则是一种技术. Main方法 代码编写规范 命名规范
- 模块之 time datetime random json pickle os sys hashlib collections
目录 1. time模块 1.1表示时间的几种方式: 1.2格式化字符串的时间格式 1.3不同格式时间的转换 2.datetim模块 3.random模块 4. json模块 4.1dumps.loa ...
- 如何使用MCUXpresso IDE创建一个Cortex-M工程
拿到Cortex-M开发板之后,就可以开始使用MCUXpresso IDE上手入门.在这个教程中,我们将详细介绍如何基于CMSIS(Cortex微控制器软件接口标准)在MCUXpresso IDE中为 ...
- java 静态代码块和spring @value等注解注入顺序
java 静态代码块和spring @value等注解注入顺序 问题所在 先上代码 java方法 @Value("${mf.cashost}") public static S ...