DataNode 工作机制
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/qq_35641192/article/details/80303879
版权声明:本文为CSDN博主「JokerDa」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_35641192/article/details/80303879
版权声明:本文为CSDN博主「JokerDa」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_35641192/article/details/80303879
DataNode工作机制
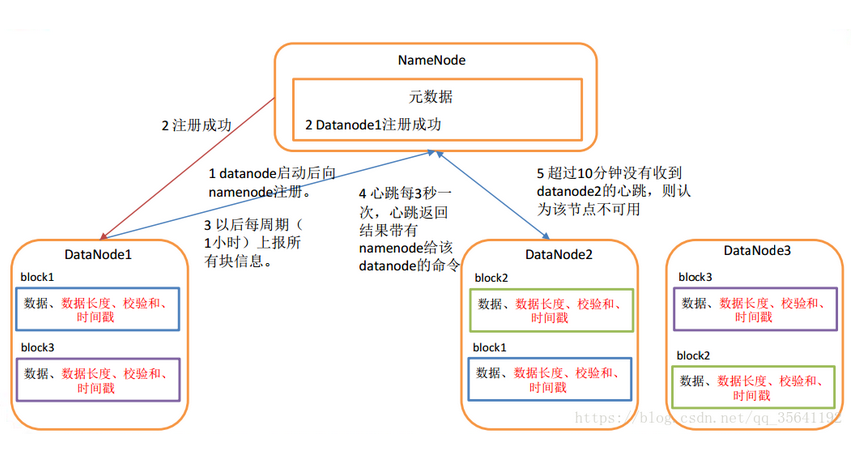
1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2)DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器。
2 数据完整性
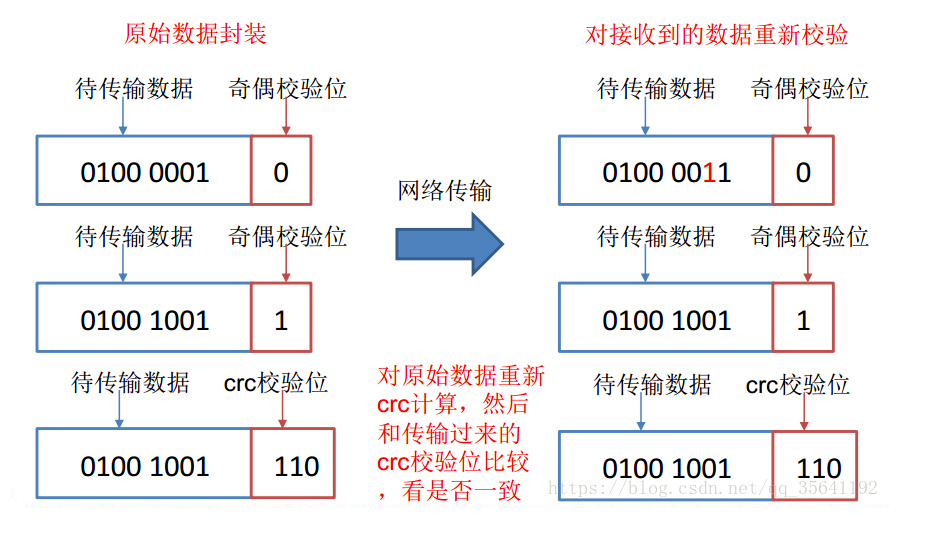
1 当 DataNode 读取 block 的时候,它会计算 checksum。
2 如果计算后的 checksum,与 block 创建时值不一样,说明 block 已经损坏。
3 client 读取其他 DataNode 上的 block。
4 datanode 在其文件创建后周期验证 checksum。
3 掉线时限参数设置
datanode 进程死亡或者网络故障造成 datanode 无法与 namenode 通信, namenode 不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。 HDFS 默认的超时时长为 10 分钟+30 秒。如果定义超时时间为 timeout,则超时时长的计算公式为:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval。
而默认的 dfs.namenode.heartbeat.recheck-interval 大小为 5 分钟,dfs.heartbeat.interval 默认为 3 秒。
需要注意的是 hdfs-site.xml 配置文件中的 heartbeat.recheck.interval 的单位为毫秒,dfs.heartbeat.interval 的单位为秒。
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name> dfs.heartbeat.interval </name>
<value>3</value>
</property>
4 DataNode 的目录结构
和 namenode 不同的是, datanode 的存储目录是初始阶段自动创建的,不需要额外格式化。
1 在/opt/module/hadoop-2.7.2/data/tmp/dfs/data/current 这个目录下查看版本号
[joker@hadoop102 current]$ cat VERSION
#Mon May 14 05:49:02 CST 2018
storageID=DS-581ac582-b391-46e3-bd0d-1faf1d7a60a4
clusterID=CID-00dee7c8-56b6-4a9f-a6ef-f596ab7d473e
cTime=0
datanodeUuid=a4cf5657-6bba-4de8-a4f0-c115fe69566c
storageType=DATA_NODE
layoutVersion=-56
2 具体解释
1) storageID: 存储 id 号
2) clusterID 集群 id, 全局唯一
3) cTime 属性标记了 datanode 存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为 0; 但是在文件系统升级之后,该值会更新到新的时间戳。
4) datanodeUuid: datanode 的唯一识别码
5) storageType: 存储类型
6) layoutVersion 是一个负整数。 通常只有 HDFS 增加新特性时才会更新这个版本号。
3)在/opt/module/hadoop-2.7.2/data/tmp/dfs/data/current/BP-97847618-192.168.10.102-1493726072779/current 这个目录下查看该数据块的版本号
[joker@hadoop102 current]$ cat VERSION
#Mon May 08 16:30:19 CST 2017
#Mon May 14 05:49:02 CST 2018
namespaceID=373601505
cTime=0
blockpoolID=BP-688790930-192.168.25.102-1525647195991
layoutVersion=-56
4 具体解释
1) namespaceID: 是 datanode 首次访问 namenode 的时候从 namenode 处获取的storageID 对每个 datanode 来说是唯一的(但对于单个 datanode 中所有存储目录来说则是相同的),namenode 可用这个属性来区分不同 datanode。
2) cTime 属性标记了 datanode 存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为 0; 但是在文件系统升级之后,该值会更新到新的时间戳。
3) blockpoolID: 一个 block pool id 标识一个 block pool,并且是跨集群的全局唯一。当一个新的 Namespace 被创建的时候(format 过程的一部分)会创建并持久化一个唯一 ID。在创建过程构建全局唯一的 BlockPoolID 比人为的配置更可靠一些。NN 将 BlockPoolID 持久化到磁盘中,在后续的启动过程中,会再次 load 并使用。
4) layoutVersion 是一个负整数。 通常只有 HDFS 增加新特性时才会更新这个版本号。
5 服役新数据节点
0 需求:
随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点。
1 环境准备
1) 克隆一台虚拟机
2)修改 ip 地址和主机名称
3)修改 xcall 和 xsync 文件, 增加新`增节点的同步 ssh
4)删除原来 HDFS 文件系统留存的文件
/opt/module/hadoop-2.7.2/data
2 服役新节点具体步骤
1)在 namenode 的/opt/module/hadoop-2.7.2/etc/hadoop 目录下创建 dfs.hosts 文件
[joker@hadoop102 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[joker@hadoop102 hadoop]$ touch dfs.hosts
[joker@hadoop102 hadoop]$ vim dfs.hosts
#添加如下主机名称(包含新服役的节点)
hadoop102
hadoop103
hadoop104
hadoop105
2)在 namenode 的 hdfs-site.xml 配置文件中增加 dfs.hosts 属性
<property>
<name>dfs.hosts</name>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts</value>
</property>
3)刷新 namenode
[joker@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
4)更新 resourcemanager 节点
[joker@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
18/05/13 14:17:11 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.25.103:8033
5)在 namenode 的 slaves 文件中增加新主机名称
[joker@hadoop102 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[joker@hadoop102 hadoop]$ vim slaves
#增加 105
hadoop102
hadoop103
hadoop104
hadoop105
#分发
[joker@hadoop102 hadoop]$ xsync hdfs-site.xml
[joker@hadoop102 hadoop]$ xsync slaves
6)单独命令启动新的数据节点和节点管理器
[joker@hadoop105 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-joker-datanode-hadoop105.out
[joker@hadoop105 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-joker-nodemanager-hadoop105.out
7)在 web 浏览器上检查是否 ok
3 如果数据不均衡,可以用命令实现集群的再平衡
[joker@hadoop102 sbin]$ ./start-balancer.sh
6 退役旧数据节点
1 在namenode的/opt/module/hadoop-2.7.2/etc/hadoop 目录下创建dfs.hosts.exclude 文件
[joker@hadoop102 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[joker@hadoop102 hadoop]$ touch dfs.hosts.exclude
[joker@hadoop102 hadoop]$ vim dfs.hosts.exclude
添加如下主机名称(要退役的节点)
hadoop105
2 在 namenode 的 hdfs-site.xml 配置文件中增加 dfs.hosts.exclude 属性
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts.exclude</value>
</property>
3 刷新 namenode、 刷新 resourcemanager
[joker@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
[joker@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
18/05/13 14:55:56 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.25.103:8033
4 检查 web 浏览器,退役节点的状态为 decommission in progress(退役中), 说明数据节点正在复制块到其他节点。 
5 等待退役节点状态为 decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。 注意:如果副本数是 3, 服役的节点小于等于 3,是不能退役成功的,需要修改副本数后才能退役。

[joker@hadoop105 hadoop-2.7.2]$ sbin/hadoop-daemon.sh stop datanode
stopping datanode
[joker@hadoop105 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop nodemanager
stopping nodemanager
6 从 include 文件中删除退役节点,再运行刷新节点的命令
1)从 namenode 的 dfs.hosts 文件中删除退役节点 hadoop105
hadoop102
hadoop103
hadoop104
2) 刷新 namenode, 刷新 resourcemanager
[joker@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
[joker@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
7 从 namenode 的 slave 文件中删除退役节点 hadoop105
hadoop102
hadoop103
hadoop104
#同步配置文件
[joker@hadoop102 hadoop]$ xsync hdfs-site.xml
[joker@hadoop102 hadoop]$ xsync slaves
8 如果数据不均衡,可以用命令实现集群的再平衡
[joker@hadoop102 hadoop-2.7.2]$ sbin/start-balancer.sh
7 Datanode 多目录配置
1 datanode 也可以配置成多个目录, 每个目录存储的数据不一样。 即:数据不是副本。
2 具体配置如下:hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value>
</property>
6 从 include 文件中删除退役节点,再运行刷新节点的命令
1)从 namenode 的 dfs.hosts 文件中删除退役节点 hadoop105
hadoop102
hadoop103
hadoop104
2) 刷新 namenode, 刷新 resourcemanager
————————————————
版权声明:本文为CSDN博主「JokerDa」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_35641192/article/details/80303879
DataNode 工作机制的更多相关文章
- hdfs namenode/datanode工作机制
一. namenode工作机制 1. 客户端上传文件时,namenode先检查有没有同名的文件,如果有,则直接返回错误信息.如果没有,则根据要上传文件的大小以及block的大小,算出需要分成几个blo ...
- HDFS中DataNode工作机制
1.DataNode工作机制 1)一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据(包括数据块的长度,块数据的校验和,以及时间戳). 2)DataNod ...
- Hadoop_10_HDFS 的 DataNode工作机制
1.DataNode的工作机制: 1.DataNode工作职责:存储管理用户的文件块数据 定期向namenode汇报自身所持有的block信息(通过心跳信息上报) (这点很重要,因为,当集群中发生某 ...
- Hadoop框架:DataNode工作机制详解
本文源码:GitHub·点这里 || GitEE·点这里 一.工作机制 1.基础描述 DataNode上数据块以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是数据块元数据包括长度.校验.时 ...
- Hadoop(五)—— HDFS NameNode、DataNode工作机制
一.NN与2NN工作机制 NameNode(NN) 1.当HDFS启动时,会加载日志(edits)和镜像文件(fsImage)到内存中. 2-4.当元数据的增删改查请求进来时,NameNode会先将操 ...
- 大数据学习之HDFS的工作机制07
1:namenode+secondaryNameNode工作机制 2:datanode工作机制 3:HDFS中的通信(代理对象RPC) 下面用代码来实现基本的原理 1:服务端代码 package it ...
- Hadoop的namenode的管理机制,工作机制和datanode的工作原理
HDFS前言: 1) 设计思想 分而治之:将大文件.大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析: 2)在大数据系统中作用: 为各类分布式运算框架(如:mapr ...
- DataNode的工作机制
DataNode的工作机制 一个数据块在DataNode以文件的形式在磁盘上保存,分为两个文件,一个是数据本身, 一个是元数据信息(包括数据的长度,校验和,时间戳) 1.DataNode启动后,向Na ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
随机推荐
- html5滚动页面简单写法
html5滚动页面简单写法纵向滚动比较简单 直接在外面加个高度 然后overflow-y: auto; 横向比较复杂了外面写两层 最外面一层写个宽度 overflow-x: auto;第二层 写wid ...
- 实现一个特殊的栈,要求push,poll , getMin方法时间复杂度都是O(N)
借助两个栈来实现 public class GetMinStack { private Stack<Integer> stackData; private Stack<Integer ...
- 最新修改Oracle10gscott用户
1.以system登录及输入自己设置口令; 2.更换sysdba身份: conn system/orcl as sysdba; 3.解锁scott用户(因装好默认是锁定的): alter user s ...
- Python将背景图片的颜色去掉
一.问题 在使用图片的时候有时候我们希望把背景变成透明的,这样就只关注于图片本身.比如在连连看中就只有图片,而没有背景,其实我个人感觉有背景好看一点. 二.解决 我们需要使用RGBA(Red,Gr ...
- 【题解】Sonya and Matrix Beauty [Codeforces1080E]
[题解]Sonya and Matrix Beauty [Codeforces1080E] 传送门:\(Sonya\) \(and\) \(Matrix\) \(Beauty\) \([CF1080E ...
- Linux学习笔记之Centos7 自定义systemctl服务脚本
0x00 概述 之前工作环境一直使用Centos6版本,脚本一直在使用/etc/init.d/xxx:系统升级到Cento7后,虽然之前的启动脚本也可以使用,但一直没有使用systemctl 的自定义 ...
- springboot初体验-不知道怎么创建spring-boot项目?
https://spring.io/projects/spring-boot/ 在以上地址找到 Quick start Bootstrap your application with Spring I ...
- 开源串口 Ymodem 上位机软件
概述 上位机使用Qt开发,计划整合多个工具为一体,用作以后的调试工具. 当前完成功能: 1.串口调试 支持hex和ascii 码发送,接受. 支持自动添加回车换行. 支持定时发送,最短间隔100ms, ...
- 2019 荔枝java面试笔试题 (含面试题解析)
本人5年开发经验.18年年底开始跑路找工作,在互联网寒冬下成功拿到阿里巴巴.今日头条.荔枝等公司offer,岗位是Java后端开发,因为发展原因最终选择去了荔枝,入职一年时间了,也成为了面试官,之 ...
- Vue学习之路由vue-router传参及嵌套小结(十)
一.路由传递参数: 1.使用query传值: <!DOCTYPE html> <html lang="en"> <head> <meta ...