datanode启动异常(Incompatible clusterIDs)
问题:
正常start-all.sh无法启动datanode进程,但是./hadoop-daemon.sh start datanode又可以启动。过一会后datanode进程又莫名消失。
原理:
多次hdfs namenode -format导致namenode生成了新的clusterID, 和datanode的不一致。
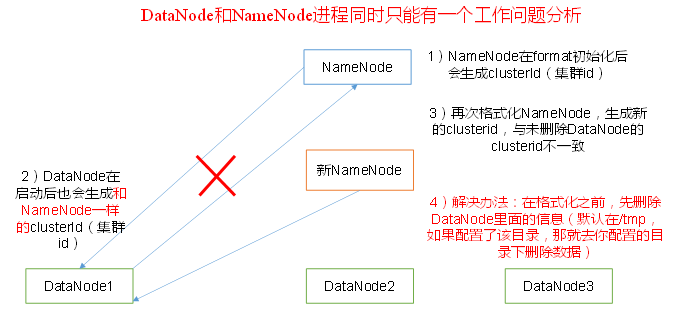
解决:
查日志,发现异常信息如下:
2019-07-22 17:46:09,856 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/home/wjy/hadoop/tmp/dfs/data
java.io.IOException: Incompatible clusterIDs in /home/wjy/hadoop-3.1.1/tmp/dfs/data: namenode clusterID = CID-8041cf56-7cbd-423e-a0b6-f782c1e1340f; datanode clusterID = CID-0d8412e3-e59b-4b1b-acdf-871b8cfa2f79
照着网上说的删除本地dfs.data.dir下的所有内容然后重启进程并没有解决我的问题。这个dfs.data.dir是在hdfs-site.xml里找的(由于我用的hadoop3.1.1,所以是dfs.datanode.data.dir):

把data下面的current文件夹删了以后再次格式化namenode,还是那个问题,不同的是namenode的clusterID发生了改变(这很正常,因为重新格式化以后又生成了新的clusterID),datanode的clusterID却一直没变。按理说datanode的clusterID应该是在data/current/VERSION里面被记录的,但是现在我根本就把这个文件夹给删掉了。。。 而且启动datanode时应该会生成一个和namenode一样的clusterID的,并没有。把namenode的VERSION给复制过去做适当的修改还是没用。
后来我发现在下图这个路径下面还有一个data文件夹,下面的VERSION文件中的clusterID正是错误信息中的那个!
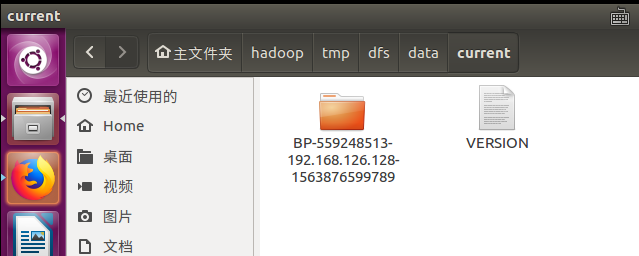
原来我之前删错了。。。 把这个current给删掉再重启一次datanode果然就好了(完全分布式记得要删除所有节点的哦,不然slave的datanode也会起不来的)。
可是很奇怪,为什么这个文件不生成在设置的dfs.datanode.name.dir的文件夹下面呢?而是在这个默认路径里面。
datanode启动异常(Incompatible clusterIDs)的更多相关文章
- hadoop2 datanode启动异常解决步骤
1.datanode起不来2016-11-25 09:46:43,685 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Invalid d ...
- hadoop异常: 到目前为止解决的最牛逼的一个异常(java.io.IOException: Incompatible clusterIDs)
(注意: 本人用的版本为hadoop2.2.0, 旧的版本和此版本的解决方法不同) 异常为: 9 (storage id DS-2102177634-172.16.102.203-50010-1384 ...
- hadoop集群启动报错: java.io.IOException: Incompatible clusterIDs
java.io.IOException: Incompatible clusterIDs in /export/hadoop-2.7.5/hadoopDatas/datanodeDatas2: nam ...
- 启动Hadoop HDFS时的“Incompatible clusterIDs”错误原因分析
"Incompatible clusterIDs"的错误原因是在执行"hdfs namenode -format"之前,没有清空DataNode节点的data目 ...
- 重新格式化namenode后,出现java.io.IOException Incompatible clusterIDs
错误: java.io.IOException: Incompatible clusterIDs in /data/dfs/data: namenode clusterID = CID-d1448b9 ...
- Hadoop问题:启动hadoop 2.6遇到的datanode启动不了
问题描述:第一次启动输入jps都有,第二次没有datanode 日志如下: 查看日志如下: -- ::, INFO org.mortbay.log: Started HttpServer2$Selec ...
- Hadoop2.6的DataNode启动不了
2016-05-04 18:14:51,990 INFO org.apache.hadoop.ipc.Server: IPC Server Responder: starting 2016-05-04 ...
- Hadoop错误:java.io.IOException: Incompatible clusterIDs
问题: 配置Hadoop集群时,一个节点的DataNode无法启动 排查: 查看hadoop-root-datanode-bigdata114.log文件,错误信息如下: java.io.IOExce ...
- 启动hadoop 2.6遇到的datanode启动不了
转自 http://blog.csdn.net/zhangt85/article/details/42078347 查看日志如下: 2014-12-22 12:08:27,264 INFO org.m ...
随机推荐
- 将zabbix服务和monitor服务在一个机器上部署
问题,两个服务的文件路径都是 /usr/local/sdata下,要让两个服务共存,至少需要讲一个服务的文件迁移到别的文件夹,同时将所有的配置项都进行修改,使能找到指定的文件路径, 方案1,先按照za ...
- 关于STM32 Flash的一些问题
注:本人感觉是STM32 Flash本身的问题. 最近做STM32的远程升级,保存到Flash里面,用于记录更新状态的信息总是无故的清理掉 最终测试发现 STM32的 Flash 擦除操作 并不一定会 ...
- 埃氏筛优化(速度堪比欧拉筛) + 洛谷 P3383 线性筛素数 题解
我们一般写的埃氏筛消耗的时间都是欧拉筛的三倍,但是欧拉筛并不好想(对于我这种蒟蒻) 虽然 -- 我 -- 也可以背过模板,但是写个不会的欧拉筛不如写个简单易懂的埃氏筛 于是就有了优化 这个优化还是比较 ...
- 洛谷P1352 没有上司的舞会题解
题目描述 某大学有N个职员,编号为1~N.他们之间有从属关系,也就是说他们的关系就像一棵以校长为根的树,父结点就是子结点的直接上司.现在有个周年庆宴会,宴会每邀请来一个职员都会增加一定的快乐指数Ri, ...
- Python研究
听说Python是种高级语言,故打算研究一下,看看高级在哪 学习资源:https://www.liaoxuefeng.com/wiki/1016959663602400 由于上面所示的网站对Pytho ...
- 【POJ3414】Pots
本题传送门 本题知识点:宽度优先搜素 + 字符串 题意很简单,如何把用两个杯子,装够到第三个杯子的水. 操作有六种,这样就可以当作是bfs的搜索方向了 // FILL(1) 把第一个杯子装满 // F ...
- Morpheus
https://software.broadinstitute.org/morpheus/
- 在Rancher中添加为中国区优化的k8s应用商店的步骤和方法
1.停用 rancher 应用商店中的“Rancher官方认证”商店和“社区贡献”商店 2.添加应用商店: 名称 地址 ...
- 组合模式( Composite Pattern)
参考文档:http://blog.csdn.net/ai92/article/details/298336 定义: 组合多个对象形成树形结构以表示“整体-部分”的结构层次. 设计动机: 这幅图片我们都 ...
- Django实现自动发布(2视图-任务接收)
上一篇服务版本的新增,是通过触发 gitlab 任务来实现的,那么如何得到任务的最终状态呢? 好在 gitlab 为我们提供了webhook,也就是消息钩子,可以发送pipeline消息到我们指定的地 ...