2019-7-19 包、logging模块、hashlib(加密模块)、openpyxl模块、深浅拷贝
一、包
什么是包:
它是一系列模块文件的结合体,表示形式就是一个文件夹。该文件内部通常会有一个__init__.py文件,包的本质还是一个模块,可以被调用,调包就相当于与调用__init__.py文件。为了其他文件调用包里面的模块、函数更方便我们可以在__init__里面就写好所有的模块和函数的调用。因为调包就相当于调用__init__.py文件,在其他文件想用包里面的函数,可以直接 import 包名 ,然后 包名.函数名就可以访问到函数了。
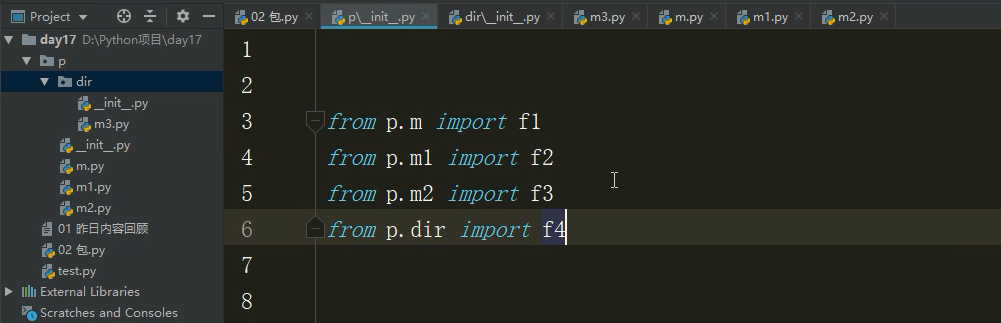
下面这个例题是在 '02包.py' 导dir文件夹下面的'm3.py' f4函数:
操作步骤:
1.在dir文件夹下面的__init__.py文件中写 from p.dir.m3 import f4 这是获取到f4函数到dir包,现在你直接调用dir包就可以直接获得f4
2.在p文件夹下面的__init__.py文件中写 from p.dir import f4 获取到dir包的f4函数到p包,直接调用p就可以得到f4
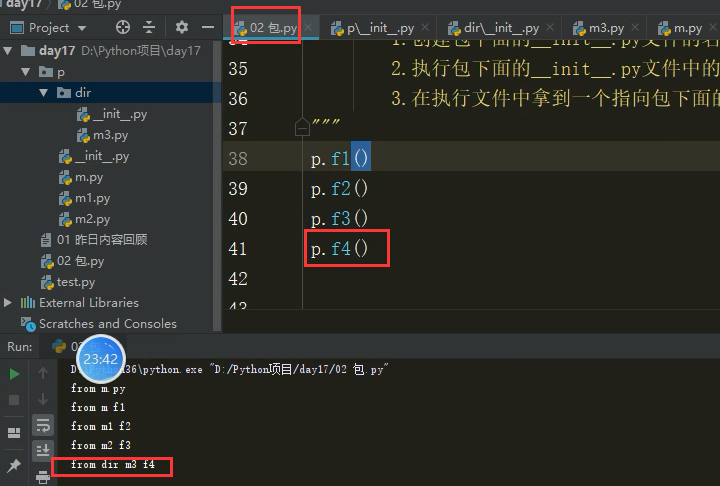
3.在 '02包.py' 中写 import p (p包的调用) p.f4() 表示可以访问到f4函数
dir/__init__.py

p/__init__.py
02包.py
首次导入包:
先产生执行文件的名称空间
1.创建包下面的__init__.py文件的名称空间
2.执行包下面的__init__.py文件中的代码 将产生的名字放入包下面的__init__.py文件的名称空间中
3.在执行文件中拿到一个指向包下面的__init__.py文件名称空间的名字
在导入语句中 .号的左边肯定是一个包(文件夹)
当你作为包的设计者来说:
1.当模块的功能特别多的情况下 应该分文件管理
2.每个模块之间为了避免后期模块改名的问题 你可以使用相对导入(包里面的文件都应该是被导入的模块)
站在包的开发者 如果使用绝对路径来管理的自己的模块 那么它只需永远以包的路径为基准依次导入模块
站在包的使用者 你必须将包所在的那个文件夹路径添加到system path中
python2如果要导入包 包下面必须要有__init__.py文件
python3如果要导入包 包下面没有__init__.py文件没有也不会报错
所以当你在删程序不必要的文件的时候 千万不要随意删掉__init__.py文件
二、logging模块 日志记录 import logging
日志记录分为四个对象:
1.logger对象:负责产生日志
2.filter对象:过滤日志(了解)
3.handler对象:控制日志输出的位置(文件或者终端)
4.formater对象:规定日志内容的格式
下面是日志生成的流程:
1.先产生日志 2.然后过滤日志(这步可以不用) 3.handler对象生成几种日志输出的位置(文件/终端) 4.formater对象生成几种日志内容的格式
5.给logger对象绑定handler对象(确定以哪种位置输出) 6.给handler对象绑定formater对象(给日志内容设置格式) 7.设置日志等级(10/20/30/40/50)五种
8.记录日志
- import logging
- # 1.logger对象:负责产生日志
- logger = logging.getLogger('转账记录')
- # 2.filter对象:过滤日志(了解)
- # 3.handler对象:控制日志输出的位置(文件/终端)
- hd1 = logging.FileHandler('a1.log',encoding='utf-8') # 输出到文件中
- hd2 = logging.FileHandler('a2.log',encoding='utf-8') # 输出到文件中
- hd3 = logging.StreamHandler() # 输出到终端
- # 4.formmater对象:规定日志内容的格式
- fm1 = logging.Formatter(
- fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
- datefmt='%Y-%m-%d %H:%M:%S %p',
- )
- fm2 = logging.Formatter(
- fmt='%(asctime)s - %(name)s: %(message)s',
- datefmt='%Y-%m-%d',
- )
- # 5.给logger对象绑定handler对象
- logger.addHandler(hd1)
- logger.addHandler(hd2)
- logger.addHandler(hd3)
- # 6.给handler绑定formmate对象
- hd1.setFormatter(fm1)
- hd2.setFormatter(fm2)
- hd3.setFormatter(fm1)
- # 7.设置日志等级
- logger.setLevel(20)
- # 8.记录日志
- logger.debug('写了半天 好累啊 好热啊 好想释放')
logging配置字典
- import os
- import logging.config
- # 定义三种日志输出格式 开始
- standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
- '[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字
- simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
- # 定义日志输出格式 结束
- """
- 下面的两个变量对应的值 需要你手动修改
- """
- logfile_dir = os.path.dirname(__file__) # log文件的目录
- logfile_name = 'a3.log' # log文件名
- # 如果不存在定义的日志目录就创建一个
- if not os.path.isdir(logfile_dir):
- os.mkdir(logfile_dir)
- # log文件的全路径
- logfile_path = os.path.join(logfile_dir, logfile_name)
- # log配置字典
- LOGGING_DIC = {
- 'version': 1,
- 'disable_existing_loggers': False,
- 'formatters': {
- 'standard': {
- 'format': standard_format
- },
- 'simple': {
- 'format': simple_format
- },
- },
- 'filters': {}, # 过滤日志
- 'handlers': {
- #打印到终端的日志
- 'console': {
- 'level': 'DEBUG',
- 'class': 'logging.StreamHandler', # 打印到屏幕
- 'formatter': 'simple'
- },
- #打印到文件的日志,收集info及以上的日志
- 'default': {
- 'level': 'DEBUG',
- 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
- 'formatter': 'standard',
- 'filename': logfile_path, # 日志文件
- 'maxBytes': 1024*1024*5, # 日志大小 5M
- 'backupCount': 5,
- 'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
- },
- },
- 'loggers': {
- #logging.getLogger(__name__)拿到的logger配置
- '': {
- 'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
- 'level': 'DEBUG',
- 'propagate': True, # 向上(更高level的logger)传递
- }, # 当键不存在的情况下 默认都会使用该k:v配置
- },
- }
- # 使用日志字典配置
- logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置
- logger1 = logging.getLogger('asajdjdskaj')
- logger1.debug('好好的 不要浮躁 努力就有收获')

三、hashlib模块 加密模块
这个加密过程是不能解密的
先用hashlib.md5 生成一个造密文的对象,用update往里面加你想变成密文的数据,但是update只接受bytes类型的数据,所以用encode编码一下变成二进制数据,最后用hex.digest获取相对应的密文。
- import hashlib # 这个加密的过程是无法解密的
- md = hashlib.md5() # 生成一个帮你造密文的对象
- md.update('hello'.encode('utf-8')) # 往对象里传明文数据 update只能接受bytes类型的数据
- md.update(b'Jason_@.') # 往对象里传明文数据 update只能接受bytes类型的数据
- print(md.hexdigest()) # 获取明文数据对应的密文
除了md5算法生成密文还有其他的算法,使用方法一致:
密文的长度越长,内部对应的算法越复杂,时间消耗越长,占用空间越大,通常情况下使用md5就可以了
传入的内容也可以分多次传入,只要传入的内容相同,密文生成也是一样的
- import hashlib
- # 传入的内容 可以分多次传入 只要传入的内容相同 那么生成的密文肯定相同
- md = hashlib.md5()
- md.update(b'areyouok?')
- md.update(b'are')
- md.update(b'you')
- md.update(b'ok?')
- print(md.hexdigest()) # 408ac8c66b1e988ee8e2862edea06cc7
- # 408ac8c66b1e988ee8e2862edea06cc7
hashlib得使用场景:1.密码的密文存储 2.校验文件内容是否一致
加盐处理:
就是在真正的内容前面加一段其他的数据也一起生成密文。
四、 openpyxl模块 操作excel表格的模块,仅支持后缀是 xlsx的excel
写文件
- from openpyxl import Workbook
- wb = Workbook() # 先生成一个工作簿
- wb1 = wb.create_sheet('index',0) # 创建一个表单页 后面可以通过数字控制位置
- wb2 = wb.create_sheet('index1')
- wb1.title = 'login' # 后期可以通过表单页对象点title修改表单页名称
- wb1['A3'] = 666 #在A3位置写666
- wb1['A4'] = 444
- wb1.cell(row=6,column=3,value=88888888)
- wb1['A5'] = '=sum(A3:A4)'
- wb2['G6'] = 999
- wb1.append(['username','age','hobby'])
- wb1.append(['jason',18,'study'])
- wb1.append(['tank',72,'吃生蚝'])
- wb1.append(['egon',84,'女教练'])
- wb1.append(['sean',23,'会所'])
- wb1.append(['nick',28,])
- wb1.append(['nick','','秃头'])
- # 保存新建的excel文件
- wb.save('test.xlsx')
读文件
- from openpyxl import load_workbook # 读文件
- wb = load_workbook('test.xlsx',read_only=True,data_only=True)
- print(wb)
- print(wb.sheetnames) # ['login', 'Sheet', 'index1']
- print(wb['login']['A3'].value)
- print(wb['login']['A4'].value)
- print(wb['login']['A5'].value) # 通过代码产生的excel表格必须经过人为操作之后才能读取出函数计算出来的结果值
- res = wb['login']
- # print(res)
- ge1 = res.rows
- for i in ge1:
- for j in i:
- print(j.value)
五、copy拷贝 copy.copy浅拷贝
修改原数据的拷贝:
浅拷贝:浅拷贝的元素是对原元素的引用,拷贝之后如果你修改原数据的不可变类型,拷贝的不会变,如果你修改原数据的可变类型,拷贝的会跟着一起改变。
深拷贝:让原数据与拷贝之后的数据没有关联,不管对方怎么修改,都不会互相影响。原理是:递归着拷贝,一层一层的拷贝原对象中每一个子对象
- from copy import copy,deepcopy
- l1 = [1,2,[3,4],{'name':'json','age':18},5,6]
- l4 = [1,2,[3,4],{'name':'json','age':18},5,6]
- #浅拷贝,只拷贝第一层(嵌套在里面的列表和字典只拷贝了地址) 修改原数据l1,如果是不可变数据类型,拷贝后l2不会变。如果是可变类型,因为指的是同一个地址,所以l1和l2都会改变
- l2 = copy(l1)
- l1[0]=2
- l1[2][0]=4 #注意:需要li[2][0]定位到列表内部,如果只是写li[2]是不会进行该表的
- print(l1)
- print(l2)
- #深拷贝
- l3 =deepcopy(l4)
- l4[0]=2
- l4[2][0]=4
- print(l4)
- print(l3)
- #结果
- [2, 2, [4, 4], {'name': 'json', 'age': 18}, 5, 6]
- [1, 2, [4, 4], {'name': 'json', 'age': 18}, 5, 6]
- [2, 2, [4, 4], {'name': 'json', 'age': 18}, 5, 6]
- [1, 2, [3, 4], {'name': 'json', 'age': 18}, 5, 6]
注意:拷贝后不管修改的是原数据还是拷贝之后的数据都适用于这个结论
修改拷贝之后的数据(也适用于上面的结论)
总结
- 对于浅拷贝和深拷贝应该在可变对象中(比如列表)中讨论这个问题,对于不可变对象,浅拷贝和深拷贝区别并不重要。
- 深拷贝和浅拷贝的本质区别在于是对地址的复制还是数据的复制的区别。
- 浅拷贝拷贝的是浅层次的数据结构(不可变元素),对象里的可变元素并没有被拷贝到新地址中,而是对原始数据的一个引用。
所以对原始数据中可变元素做修改时,拷贝之后的数据也会被修改。但是深拷贝不会这样,深拷贝是拷贝整个数据放在一个新的空间中,没有对原数据进行引用。
- import copy
- li1=[['a'],['b'],['c']]
- li2=copy.copy(li1) #浅拷贝
- li1.append()
- li1[][]=
- print(li1) #[[], ['b'], ['c'], ] #浅拷贝之后的原数据修改了不可变元素,新数据不会发生改变
- print(li2) #[[], ['b'], ['c']] #浅拷贝之后的原数据修改了可变元素,因为是引用了原数据的数据,所以新数据也会发生改变
2019-7-19 包、logging模块、hashlib(加密模块)、openpyxl模块、深浅拷贝的更多相关文章
- python基础--包、logging、hashlib、openpyxl、深浅拷贝
包:它是一系列模块文件的结合体,表现形式就是一个文件夹,该文件夹内部通常会有一个__init__.py文件,包的本质还是一个模块. 首次导入包:(在导入语句中中 . 号的左边肯定是一个包(文件夹)) ...
- logging、hashlib、collections模块
一.hashlib模块(加密模块) 1.什么叫hash:hash是一种算法(3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 , ...
- 19.包 logging 的使用
包 什么是包: ---文件夹下具有__init__.py文件就是一个包 推荐使用 from . import 包的导入; from ss.bake.api.policy import func --- ...
- 7.19 包 logging模块 hashlib模块 openpyxl模块 深浅拷贝
包 包是什么 他是一系列文件的结合体,表现形式就是文件夹 包的本质还是模块 他通常会有__init__.py文件 我们首先回顾一下模块导入的过程 import module首次导入模块(.py文件) ...
- s14 第5天 时间模块 随机模块 String模块 shutil模块(文件操作) 文件压缩(zipfile和tarfile)shelve模块 XML模块 ConfigParser配置文件操作模块 hashlib散列模块 Subprocess模块(调用shell) logging模块 正则表达式模块 r字符串和转译
时间模块 time datatime time.clock(2.7) time.process_time(3.3) 测量处理器运算时间,不包括sleep时间 time.altzone 返回与UTC时间 ...
- Python全栈之路----常用模块----hashlib加密模块
加密算法介绍 HASH Python全栈之路----hash函数 Hash,一般翻译做“散列”,也有直接音译为”哈希”的,就是把任意长度的输入(又叫做预映射,pre-image),通过散列 ...
- day17_7.19包与logging模块,深浅拷贝
一.包 在模块的定义里,模块就是方法的集合,可以将一些常用的方法封装到一个py文件中,通过调用使用,而且,其中的表现形式也有以包的形式导入. 其实,包就是一系列模块的结合体,表示形式就是一个文件夹,在 ...
- 包、logging模块、hashlib模块、openpyxl模块、深浅拷贝
包.logging模块.hashlib模块.openpyxl模块.深浅拷贝 一.包 1.模块与包 模块的三种来源: 1.内置的 2.第三方的 3.自定义的 模块的四种表现形式: 1.py文件 2.共享 ...
- hashlib加密模块和logging模块,购物车项目
hashlib加密模块 简介 hashlib模块是一个提供了字符串加密功能的模块,包含MD5和SHA的加密算法.具体的加密支持有: MD5,sha1,sha224,sha256, sha384, sh ...
随机推荐
- java的多线程之入门
一.java多线程基本概念 调用run():在主线程调用子线程的run()方法会中断主线程等到子线程执行完毕之后再执行主线程. 调用start():在主线程中执行子线程的start()后会与主线程同步 ...
- Vue项目预渲染机制
我们知道SPA有很多优点,不过一个缺点就是对(不是Google的)愚蠢的搜索引擎的SEO不友好,为了照顾这些引擎,目前主要有两个方案:服务端渲染(Server Side Rendering).预渲染( ...
- R语言中查询帮助
可以尝试下面的几种方式 help(lapply,package=,....)?lapply??lapplyhelp.search('lapply')apropos('norm') #函数名记不全时用? ...
- C# using 的使用方法
1. using :对命名空间的引用 比如 using System; 这样的命名空间,在加入了dll 包之后,也要对包进行引用 对不同命名空间同一方法别名的区分即:定义别名 using Syste ...
- [Gamma]Scrum Meeting#1
github 本次会议项目由PM召开,时间为5月26日晚上10点30分 时长25分钟 任务表格 人员 昨日工作 下一步工作 木鬼 撰写博客,组织例会 swoip 前端显示屏幕,翻译坐标 bhlt 后端 ...
- Java编程思想之七复用类
复用代码是Java众多引人注目的功能之一.但要想成为极具革命性的语言,仅仅能够复制代码并对之加以改变是不够的,它还必须做更多的事情. 使用类而不破坏程序代码: 在新类中产生现有对象.由于新的类是由现有 ...
- 在线生成安卓APP图标
移动应用图标/启动图生成工具,一键生成所有尺寸的应用图标/启动图 在线生成安卓APP图标生成 图标在 线 在线图标 安卓图标 生成图标 https://icon.wuruihong.com/ 在线pn ...
- portaudio使用笔记《转》
原文链接:https://blog.csdn.net/gg_simida/article/details/77185755 介绍 PortAudio是一个免费.跨平台.开源的音频I/O库.看到I/O可 ...
- 字符串反转(java和js)
写在前面 关于字符串反转的奇技淫巧很多, 会一种就行了, 但是解锁更多姿势可谓艺多不压身啊~~ 正文 java https://www.cnblogs.com/binye-typing/p/92609 ...
- 通过 UNSAFE 来实现一个 Atomic 的 CAS 辅助类【原创】
public abstract class AbstractUnSafeCas<T> { @SuppressWarnings("unused") private vol ...