Python学习日记(十八) 序列化模块
什么是序列?
就是每一个元素被有序的排成一列
什么是序列化?
就是将原本的列表、字典等内容转化成字符串的过程
什么时候会用到序列化?
数据存储(把数据放在文件、数据库),网络传输等
序列化的目的
1.以某种存储形式使自定义对象持久化
2.将对象从一个地方传递到另一个地方
3.使程序更具维护性
序列化:数据结构转换成字符串
反序列化:字符串转换成数据结构
三大序列化模块:
1.Json
特点:
json是一个通用的序列化格式且只有很少一部分数据(str、list、dict、tuple、数字)类型能够通过json转化成字符串
json.dumps():
方法使用序列化,将一个数据类型转化成字符串类型
import json
dic = {'k1': 2,'k2': 3 }
str_d = json.dumps(dic)
print(type(str_d),str_d) #<class 'str'> {"k1": 2, "k2": 3}
元祖的序列化:
在json这里元祖会被转成列表再去序列化
import json
tu = (1,'a',['y',2])
print(type(tu),tu) #<class 'tuple'> (1, 'a', ['y', 2])
str_t = json.dumps(tu)
print(type(str_t),str_t) #<class 'str'> [1, "a", ["y", 2]]
json.loads():
方法使用反序列化,将一个字符串类型还原成原数据类型
import json
str_d = '{"k1": 2, "k2": 3}'
dict = json.loads(str_d)
print(type(dict),dict) #<class 'dict'> {'k1': 2, 'k2': 3}
这里字符串内部的键值要""表示,否则会报错
元祖的反序列化:
结果会转成一个列表,可以用list()方法再转成元祖
json.dump():
接收文件句柄和数据类型,再将该数据类型转换成json字符串写入文件中
import json
dic = {'k1' : 1,'k2' : 2,'k3' : 3}
with open('jsonTestfile','w',encoding='utf-8') as f:
json.dump(dic,f)
程序执行前:
程序执行后:
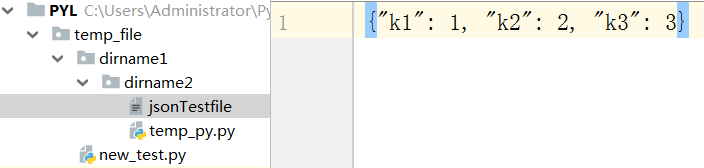
json.load():
接收一个文件句柄,将文件中json字符串转成数据结构返回
import json
with open('jsonTestfile') as f:
get_str = json.load(f)
print(get_str) #{'k1': 1, 'k2': 2, 'k3': 3}
如果这个文件有汉字等非ASCII的字符,文件会被写成一个bytes类型
import json
dic = {'k1':'中国','k2':'美国','k3':123,'k4':'abc1'}
with open('jsonTestFile','w',encoding='utf-8') as f:
json.dump(dic,f,ensure_ascii=False) #关闭ensure_ascii这样汉字就不变成乱码了
with open('jsonTestFile',encoding='utf-8') as f:
print(json.load(f)) #{'k1': '中国', 'k2': '美国', 'k3': 123, 'k4': 'abc1'}
总结:
在这里从文件写入一个json支持的数据类型或从中取出一个json字符串,这里用到的方法dumps\loads都是从内存中直接取出想要的数据,dump\load则都是从文件中取出想要的数据
前面所归纳到的方法都只能一行一行去获取数据,如果我们要多行获取:
import json
l = [{'k1':'a','k2':'b','k3':1}]
#将每一个列表中的字典迭代获取并转成json字符串并以分行格式写入文件
with open('jsonTestFile','w') as f:
for dic in l:
str_dic = json.dumps(dic)
f.write(str_dic+'\n')
#打开这个文件将里面的字符串每行去换行再存入到收集器中,最后再打印结果
with open('jsonTestFile') as f:
colletion = []
for line in f:
dic = json.loads(line.strip())
colletion.append(dic)
print(colletion) #[{'k1': 'a', 'k2': 'b', 'k3': 1}]
2.Pickle
特点:
pickle可以将所有的python中的数据类型转成字符串形式,pickle序列化的内容只有python才能够理解,且部分序列化依赖python代码
pickle.dumps()
将一个数据类型转换成二进制内容,这里dumps()的参数支持python内的所有数据类型
import pickle
dic = {'k1': 1,'k2': 2,'k3': 3}
set = {1,2,'s'}
tu = (1,2,'avb')
li = ['k',1,'s',666] pstr_d = pickle.dumps(dic)
print(type(pstr_d),pstr_d) #<class 'bytes'> b'\x80\x03}q\x00(X\x02\x00\x00\x00k1q\x01K\x01X\x02\x00\x00\x00k2q\x02K\x02X\x02\x00\x00\x00k3q\x03K\x03u.'
pstr_s = pickle.dumps(set)
print(type(pstr_s),pstr_s) #<class 'bytes'> b'\x80\x03cbuiltins\nset\nq\x00]q\x01(K\x01K\x02X\x01\x00\x00\x00sq\x02e\x85q\x03Rq\x04.'
pstr_t = pickle.dumps(tu)
print(type(pstr_t),pstr_t) #<class 'bytes'> b'\x80\x03K\x01K\x02X\x03\x00\x00\x00avbq\x00\x87q\x01.'
pstr_l = pickle.dumps(li)
print(type(pstr_l),pstr_l) #<class 'bytes'> b'\x80\x03]q\x00(X\x01\x00\x00\x00kq\x01K\x01X\x01\x00\x00\x00sq\x02M\x9a\x02e.'
pickle.loads()
将读取到的这一个二进制文件转换为数据类型
import pickle
pstr_d = b'\x80\x03}q\x00(X\x02\x00\x00\x00k1q\x01K\x01X\x02\x00\x00\x00k2q\x02K\x02X\x02\x00\x00\x00k3q\x03K\x03u.'
print(pickle.loads(pstr_d)) #{'k1': 1, 'k2': 2, 'k3': 3}
pstr_s = b'\x80\x03cbuiltins\nset\nq\x00]q\x01(K\x01K\x02X\x01\x00\x00\x00sq\x02e\x85q\x03Rq\x04.'
print(pickle.loads(pstr_s)) #{1, 2, 's'}
pstr_t = b'\x80\x03K\x01K\x02X\x03\x00\x00\x00avbq\x00\x87q\x01.'
print(pickle.loads(pstr_t)) #(1, 2, 'avb')
pstr_l = b'\x80\x03]q\x00(X\x01\x00\x00\x00kq\x01K\x01X\x01\x00\x00\x00sq\x02M\x9a\x02e.'
print(pickle.loads(pstr_l)) #['k', 1, 's', 666]
pickle.dump()
import pickle,time
struct_time = time.gmtime(15000000)
print(struct_time) #time.struct_time(tm_year=1970, tm_mon=6, tm_mday=23, tm_hour=14, tm_min=40, tm_sec=0, tm_wday=1, tm_yday=174, tm_isdst=0)
with open('pickleTestFile','wb') as f:
pickle.dump(struct_time,f)
pickle.load()
import pickle,time
struct_time = time.gmtime(15000000)
with open('pickleTestFile','rb') as f:
print(pickle.load(f))#time.struct_time(tm_year=1970, tm_mon=6, tm_mday=23, tm_hour=14, tm_min=40, tm_sec=0, tm_wday=1, tm_yday=174, tm_isdst=0)
3.Shelve
特点:
shelve可以序列化句柄,可以使用句柄直接操作非常方便
直接创建一个shelve对象
import shelve
f = shelve.open('shelveFile')
f['key'] = {'int': 10,'float': 15.6,'string' :'abc123'}
f.close()
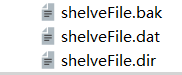
固定生成三个shelve专属的文件
取出存入DB中的数据
import shelve
f = shelve.open('shelveFile')
getData = f['key']
f.close()
print(getData) #{'int': 10, 'float': 15.6, 'string': 'abc123'}
由于shelve在默认情况下是不会记录待持久化对象的任何修改的,所以我们在shelve.open()时候需要修改参数,否则对象的修改不会保存
关于shelve的学习链接:https://www.cnblogs.com/sui776265233/p/9225164.html#_label2
Python学习日记(十八) 序列化模块的更多相关文章
- Python学习日记(十六) time模块和random模块
time模块 python表示时间的三种方式:时间戳.元祖(struct_time).格式化时间字符串 三种格式之间的转换: 1.时间戳 就是从1970年1月1日0点0分0秒开始按秒计算的偏移量,时间 ...
- Python学习日记(八)—— 模块一(sys、os、hashlib、random、time、RE)
模块,用一砣代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能需要多个函数才 ...
- Python学习日记(十五) collections模块
在内置函数(dict.list.set.tuple)的基础上,collections模块还提供了几个其他的数据类型:Counter.deque.defaultdict.namedtuple和Order ...
- Python学习(十) —— 常用模块
一.collections模块 在内置数据类型(dict.list.set.tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter.deque.defaultdic ...
- python学习(十二)模块
怎么一下子就来学了模块? 其实学了判断.循环.函数等知识就可以开始下水写程序了,不用在意其他的细节,等你用到的时候再回过头去看,此所谓囫囵吞枣学习法. 为啥学模块? 有点用的.或者有点规模的程序都是要 ...
- Python学习日记(十九) 模块导入
模块导入 当文件夹中有这样一个自定义的command模块 在它的内部写下下列代码: print('这个py文件被调用!') def fuc(): print('这个函数被调用!') 然后我们在comm ...
- Python学习日记(十四) 正则表达式和re模块
正则表达式: 它是字符串的一种匹配模式,用来处理字符串,可以极大地减轻处理一些复杂字符串的代码量 字符组:它是在同一位置可能出现的各种字符组成了一个字符组,用[]表示,但是它的结果只能是一个数字或者一 ...
- Python学习二十八周(vue.js)
一.指令 1.一个例子简单实用vue: 下载vue.js(这里实用1.0.21版本) 编写html代码: <!DOCTYPE html> <html lang="en&qu ...
- Python学习第十八篇——低耦合函数设计思想
import json 2 def greet_user(filename): 3 try: 4 with open(filename) as f_obj: 5 username = json.loa ...
随机推荐
- 【嵌入式硬件Esp32】MQTT链接测试工具
1.Eclipse Paho MQTT Utility GUI测试工具 下载地址: 链接:https://pan.baidu.com/s/1ivxk3DWJkod-jBsowlcoBA 提取码:0lp ...
- swoole实战1-初识swoole
原文地址:https://www.jianshu.com/p/008d5702d01f 安装swoole 以mac操作系统为例,如果你是mac新手,推荐阅读 程序员如何优雅使用mac 环境要求:php ...
- React+antd+less框架搭建步骤,看吧,整的明白儿的
1.node版本 首先你要先看下你的node版本,如果小于10,建议升级到10及以上,因为低版本的 node 在自动创建 react框架时,有配置文件跟10及以上的有比较大的差异,而且需要增加.修改的 ...
- Oracle Spatial图层元数据坐标范围影响R-TREE索引的ROOT MBR吗?
Oracle Spatial的空间索引R-TREE,其实现原理为一级级的MBR(最小定界矩形).我突然想到一个问题,它的ROOT MBR是怎么确定的?是根据元数据表user_sdo_geom_meta ...
- saltstack配置文件详解
软件依赖 Python版本大于2.6或版本小于3.0: 对Python版本要求 msgpack-python: SalStack消息交换库 YAML: SaltStack配置解析定义语法 Jinja2 ...
- PyCharm的安装方法及设置中文界面
pycharm官网下载安装包:https://www.jetbrains.com/pycharm/download/#section=windows 下载中文语言包:https://github.co ...
- 关于su下bash:xxx :command not found
今天在新建组的时候出了问题: $ su Password: # groupadd prj bash: groupadd :command not found 我就纳闷,明明是在su权限下,怎么还不能使 ...
- [转帖]首颗国产DRAM芯片的技术与专利,合肥长鑫存储的全面深度剖析
首颗国产DRAM芯片的技术与专利,合肥长鑫存储的全面深度剖析 https://mp.weixin.qq.com/s/g_gnr804q8ix4b9d81CZ1Q 2019.11 存储芯片已经成为全球珍 ...
- gitlab升级备份
一.备份有关备份和恢复的操作,详见我的另一篇博客:Gitlab的备份与恢复在开始升级之前,一定要做好备份工作,并记录好版本号.1.查看当前Gitlab的版本号 [root@gitlab ~]# cat ...
- Fiddler如何切换hosts以及切换hosts的另一个神器SwithcHosts