检查hdfs块的块-fsck
hadoop集群运行过程中,上下节点是常有的事情,如果下架节点,hdfs存储的块肯定会受到影响。
如何查看当前的hdfs的块的状态
hadoop1.x时候的命令,hadoop2.x也可使用:
hadoop fsck /
在hadoop2.0之后,可以使用新命令:
hdfs fsck /
返回结果截图如下:
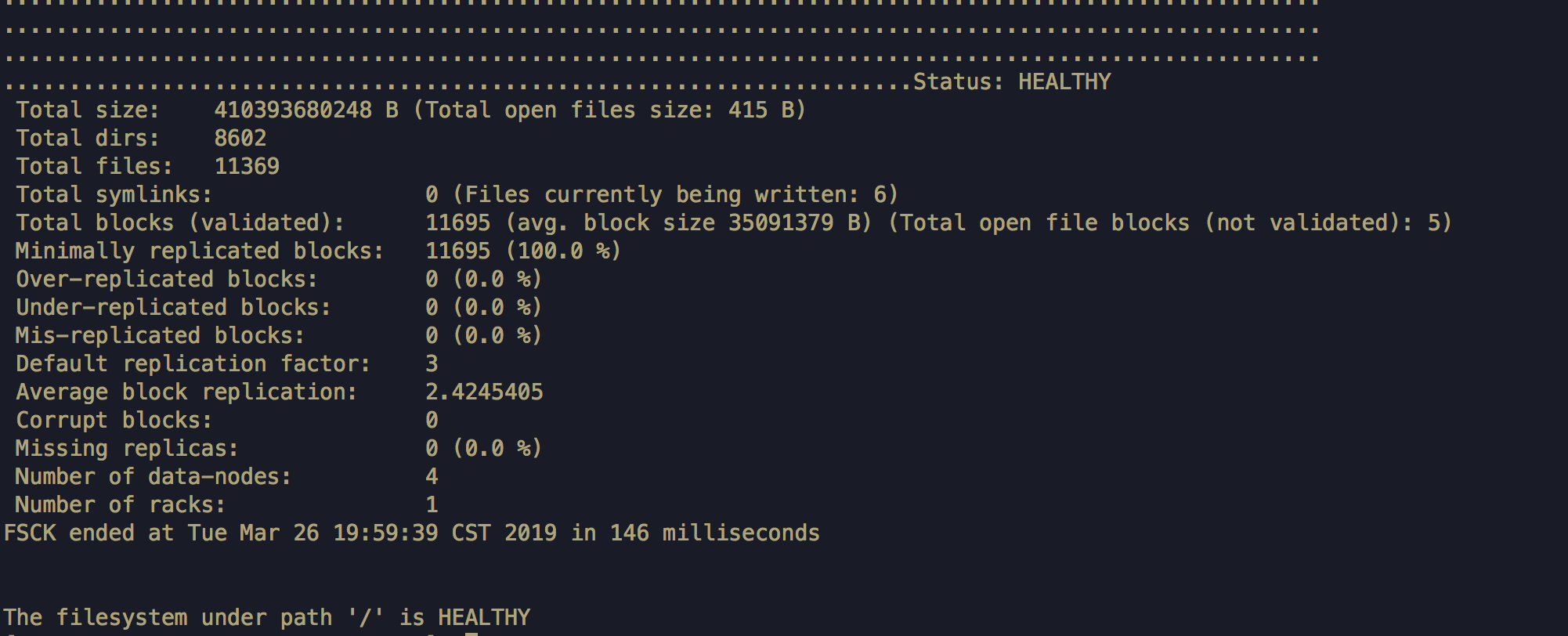
参数说明:
Total size : hdfs集群存储大小,不包括复本大小。如:75423236058649 B (字节)。(字节->KB->m->G->TB,75423236058649/1024/1024/1024/1024=68.59703358591014TB)
Total blocks (validated) : 总共的块数量,不包括复本。(5363690 (avg. block size 14061818 B) (Total open file blocks (not validated): 148),计算: 14061818 *5363690=75423232588420 集群的容量大小,不包括复本的)
Number of data-nodes : datanode的节点数量
Number of racks : 机架数量
Default replication factor : 默认的复制因子
Average block replication : 当前块的平均复制数,如果小 default replication factor,则有块丢失
Under-replicated blocks : 正在复制块数量,可采用 hadoop fsck -blocks 解决问题
Mis-replicated blocks : 正复制的缺少复制块的数量
Missing replicas : 缺少复制块的数量,通常情况下Under-replicated blocks\Mis-replicated blocks\Missing replicas 都为0,则集群健康,如果不为0,则缺失块了
Corrupt blocks : 坏块的数量,这个值不为0,则说明当前集群有不可恢复的块,即数据有丢失了
当下架节点时Under-replicated blocks\Mis-replicated blocks\Missing replicas,这三个参数会显示当前,需要补的块的数量,集群会自动补全,当三个参数都为0时,则集群块的复制块完全了。
检查hdfs块的块-fsck的更多相关文章
- HDFS读写数据块--${dfs.data.dir}选择策略
最近工作需要,看了HDFS读写数据块这部分.不过可能跟网上大部分帖子不一样,本文主要写了${dfs.data.dir}的选择策略,也就是block在DataNode上的放置策略.我主要是从我们工作需要 ...
- 【Hadoop】HDFS冗余数据块的自动删除
HDFS冗余数据块的自动删除 在日常维护hadoop集群的过程中发现这样一种情况: 某个节点由于网络故障或者DataNode进程死亡,被NameNode判定为死亡, HDFS马上自动开始数据块的容错拷 ...
- HDFS冗余数据块的自动删除
HDFS冗余数据块的自动删除 在日常维护hadoop集群的过程中发现这样一种情况: 某个节点由于网络故障或者DataNode进程死亡,被NameNode判定为死亡,HDFS马上自动开始数据块的容错拷贝 ...
- Hdfs block数据块大小的设置规则
1.概述 hadoop集群中文件的存储都是以块的形式存储在hdfs中. 2.默认值 从2.7.3版本开始block size的默认大小为128M,之前版本的默认值是64M. 3.如何修改block块的 ...
- HDFS 上文件块的副本数设置
一.使用 setrep 命令来设置 # 设置 /javafx-src.zip 的文件块只存三份 hadoop fs -setrep /javafx-src.zip 二.文件块在磁盘上的路径 # 设置的 ...
- access_ok | 检查用户空间内存块是否可用
access_ok() 函数是用来代替老版本的 verify_area() 函数的.它的作用也是检查用户空间指针是否可用. 函数原型:access_ok (type, addr, size); 变量说 ...
- Hadoop架构: HDFS中数据块的状态及其切换过程,GS与BGS
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 首先,我们要提出HDFS存储特点: 1.高容错 2.一个文件被切成块(新版本默认128MB一个块)在不 ...
- 关于HDFS默认block块大小
这是有疑惑的一个问题,因为在董西成的<Hadoop技术内幕--深入解析MapReduce架构设计与实现原理>中提到这个值是64M,而<Hadoop权威指南>中却说是128M,到 ...
- oracle--dump 块与块分析 (dump 深入实践二)
一,建立测试环境 01,一个oracle数据库环境 02,具体数据库实验环境配置 SQL> create user test1 identified by kingle; User create ...
随机推荐
- yii2.0的学习之旅(二)
前言:上一次我们简单认识了一下yii2.0安装,模型基本(增,删,改,查)操作 一.前后台数据交互 *如果你觉得默认的top样式太丑,可以这样关掉* *底部也可以这样关掉* (1)mvc合作操作数据 ...
- 单独KafkaConsumer实例and多worker线程。
1.单独KafkaConsumer实例and多worker线程.将获取的消息和消息的处理解耦,将消息的处理放入单独的工作者线程中,即工作线程中,同时维护一个或者若各干consumer实例执行消息获取任 ...
- WPF 动态资源 DataContext="{DynamicResource studentListKey}" DisplayMemberPath="Name"
public class StudentList:ObservableCollection<Student> { public List<Student> studentLis ...
- SQL Server like 字段
参考资料:Cannot resolve the collation conflict between "Chinese_PRC_CI_AS" and "SQL_L及由于排 ...
- Python - 条件控制、循环语句 - 第十二天
Python 条件控制.循环语句 end 关键字 关键字end可以用于将结果输出到同一行,或者在输出的末尾添加不同的字符,实例如下: Python 条件语句是通过一条或多条语句的执行结果(True 或 ...
- Java学习——泛型
Java学习——泛型 摘要:本文主要介绍了什么是泛型,为什么要用泛型,以及如何使用泛型. 部分内容来自以下博客: https://www.cnblogs.com/lwbqqyumidi/p/38376 ...
- JVM指令手册
JVM指令大全 常量入栈指令 指令码 操作码(助记符) 操作数 描述(栈指操作数栈) 0x01 aconst_null null值入栈. 0x02 iconst_m1 -1(int)值入栈. 0x03 ...
- To B产品,业务方全程蒙蔽怎么搞?
这是发生在很久前的事,那会我还是产品实习生. 今天和业务部门进行需求审核,对的是公司内部SAAS系统的采购模块.怎么说呢?就是觉得不专业吧 辛辛苦苦把原 ...
- Java并行程序基础。
并发,就是用多个执行器(线程)来完成一个任务(大任务)来处理业务(提高效率)的方法.而在这个过程中,会涉及到一些问题,所以学的就是解决这些问题的方法. 线程的基本操作: 1.创建线程:只需要new一个 ...
- 其他综合-VMware 从模板机快速克隆多台
VMware 从模板机快速克隆多台 1.实验描述 通过 CentOS 7.6 的模板机快速克隆,为实现搭建其他项目而提供干净的实验平台. [基于此文章的环境]点我快速打开文章 2.实验环境 使用软件的 ...