[转] Cache 和 Buffer的区别
程序员开发过程中经常会遇到“缓存”、“缓冲”等相似概念,之前没有特别关注,现在停下来做一下总结,才能更好地前行。
先来下枯燥的概念:
1、Cache:缓存区,是高速缓存,是位于CPU和主内存之间的容量较小但速度很快的存储器,因为CPU的速度远远高于主内存的速度,CPU从内存中读取数据需等待很长的时间,而 Cache保存着CPU刚用过的数据或循环使用的部分数据,这时从Cache中读取数据会更快,减少了CPU等待的时间,提高了系统的性能。Cache并不是缓存文件的,而是缓存块的(块是I/O读写最小的单元);Cache一般会用在I/O请求上,如果多个进程要访问某个文件,可以把此文件读入Cache中,这样下一个进程获取CPU控制权并访问此文件直接从Cache读取,提高系统性能。
2、Buffer:缓冲区,用于存储速度不同步的设备或优先级不同的设备之间传输数据;通过buffer可以减少进程间通信需要等待的时间,当存储速度快的设备与存储速度慢的设备进行通信时,存储慢的数据先把数据存放到buffer,达到一定程度存储快的设备再读取buffer的数据,在此期间存储快的设备CPU可以干其他的事情。Buffer一般是用在写入磁盘的,例如:某个进程要求多个字段被读入,当所有要求的字段被读入之前已经读入的字段会先放到buffer中。
计算机专业性太强,一般小白看了懵懵懂懂 。
一句话解释cache和buffer
1、cache 是为了弥补高速设备和低速设备的鸿沟而引入的中间层,最终起到**加快访问速度**的作用。
2、而 buffer 的主要目的进行流量整形,把突发的大数量较小规模的 I/O 整理成平稳的小数量较大规模的 I/O,以**减少响应次数**
(比如从网上下电影,你不能下一点点数据就写一下硬盘,而是积攒一定量的数据以后一整块一起写,不然硬盘都要被你玩坏了)。
这个算是通俗易懂,引入了下电影的例子,不错哈!
继续!
假设某地发生了自然灾害(比如地震),居民缺衣少食,于是派救火车去给若干个居民点送水。
救火车到达第一个居民点,开闸放水,老百姓就拿着盆盆罐罐来接水。
假如说救火车在一个居民点停留100分钟放完了水,然后重新储水花半个小时,再开往下一个居民点。这样一个白天来来来回回的,也就是4-5个居民点。
但我们想想,救火车是何等存在,如果把水龙头完全打开,其强大的水压能轻易冲上10层楼以上, 10分钟就可以把水全部放完。但因为居民是拿盆罐接水,100%打开水龙头那就是给人洗澡了,所以只能打开一小部分(比如10%的流量)。但这样就降低了放水的效率(只有原来的10%了),10分钟变100分钟。
那么,我们是否能改进这个放水的过程,让救火车以最高效率放完水、尽快赶往下一个居民点呢?
方法就是:在居民点建蓄水池。
救火车把水放到蓄水池里,因为是以100%的效率放水,10分钟结束然后走人。居民再从蓄水池里一点一点的接水。
我们分析一下这个例子,就可以知道Cache的含义了。
救火车要给居民送水,居民要从救火车接水,就是说居民和救火车之间有交互,有联系。
但救火车是“高速设备”,居民是“低速设备”,低速的居民跟不上高速的救火车,所以救火车被迫降低了放水速度以适应居民。
为了避免这种情况,在救火车和居民之间多了一层“蓄水池(也就是Cache)”,它一方面以100%的高效和救火车打交道,另一方面以10%的低效和居民打交道,这就解放了救火车,让其以最高的效率运行,而不被低速的居民拖后腿,于是救火车只需要在一个居民点停留10分钟就可以了。
所以说,蓄水池是“活雷锋”,把高效留给别人,把低效留给自己。把10分钟留给救火车,把100分钟留给自己。
从以上例子可以看出,所谓Cache,就是“为了弥补高速设备和低速设备之间的矛盾”而设立的一个中间层。因为在现实里经常出现高速设备要和低速设备打交道,结果被低速设备拖后腿的情况。
以PC为例。CPU速度很快,但CPU执行的指令是从内存取出的,计算的结果也要写回内存,但内存的响应速度跟不上CPU。
CPU跟内存说:你把某某地址的指令发给我。内存听到了,但因为速度慢,迟迟不见指令返回,这段时间,CPU只能无所事事的等待了。这样一来,再快的CPU也发挥不了效率。
怎么办呢?在CPU和内存之间加一块“蓄水池”,也就是Cache(片上缓存),这个Cache速度比内存快,从Cache取指令不需要等待。
当CPU要读内存的指令的时候先读Cache再读内存,但一开始Cache是空着的,只能从内存取,这时候的确是很慢,CPU需要等待。
但从内存取回的不仅仅是CPU所需要的指令,还有其它的、当前不需要的指令,然后把这些指令存在Cache里备用。
CPU再取指令的时候还是先读Cache,看看里面有没有所需指令,如果碰巧有就直接从Cache取,不用等待即可返回(命中),这就解放了CPU,提高了效率。(当然不会是100%命中,因为Cache的容量比内存小)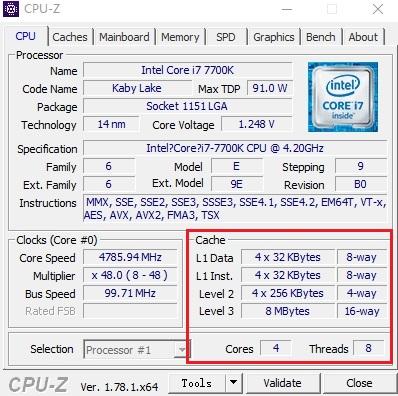
CPU的Cache,可以有好几层,而且还分数据Cache和指令Cache
磁盘缓存也是一样,刚才说内存是慢速设备,所以需要片上缓存,但这个“慢”是相对于CPU而言的,相对于机械硬盘HDD,内存的速度可快多了。
对于磁盘的读写操作,在很久以前,读写过程需要CPU参与,后来出现了“DMA/直接内存访问"就不再需要CPU了,但即使如此,高负荷、长时间的磁盘读写也非常的耗时,因为磁盘是机械旋转部件,其读写速度相比CPU和内存条的二进制电压变化速度,那就是蒸汽机和火箭速度的差别。
为了加快数据的读写速度,在磁盘和内存之间也插入一层Cache(Windows在内存里划分出一块区域作为Cache,硬盘也有板载Cache。)
写入数据的时候先写入到Cache里;因为Cache很快,所以数据很快就写入。
比方说,1G的数据,如果直接写入硬盘需要10秒,但写入Cache(也就是系统内存)只需要1秒。
这样一来用户就有了系统速度很快的“幻觉”。但这只是障眼法,数据暂存在Cache里并没有被真正写入磁盘,等系统空闲的时候再慢慢写入。
同理,在读数据的时候,除了所需的数据,还有一堆目前不需要的数据也都被读出来放到内存的Cache里。下次再读的时候,如果恰巧Cache里有所需的数据就可直接读入(命中),这就避免了从慢速的HDD读数据的尴尬。用户的体验同样也是速度很快。(同样不会100%命中,因为RAM的容量远小于硬盘容量)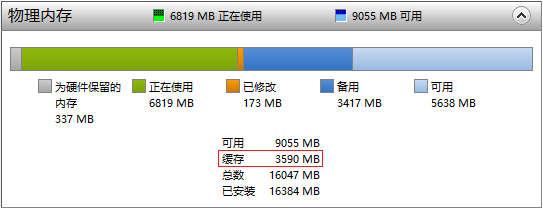
PC有16G的内存,磁盘Cahce占用了3.59G,这是动态的,会自动调整大小

硬盘也内置了Cache。某品牌硬盘的广告强调了大缓存的优势
以上举了3个栗子:蓄水池、CPU的Cache、磁盘的Cache
Cache的存在是为了解决什么问题?速度太慢了,要加快速度!
那么buffer呢? 请允许我再次举起栗子。
比如说吐鲁番的葡萄熟了,要用大卡车装葡萄运出去卖
果园的姑娘采摘葡萄,当然不是前手把葡萄摘下来,后手就放到卡车上,而是需要一个中间过程“箩筐”:摘葡萄→放到箩筐里→把箩筐里的葡萄倒入卡车。
也就是说,虽然最终目的是“把葡萄倒入卡车”,但中间必须要经过“箩筐”的转手,这里的箩筐就是Buffer。是“暂时存放物品的空间”。
注意2个关键词:暂时,空间
再换句话说,为了完成最终目标:把葡萄放入卡车的空间,需要暂时把葡萄放入箩筐的空间。
以BT为例,BT下载需要长时间的挂机,电脑就有可能24小时连轴转,但BT下载的数据是碎片化的,体现在硬盘写入上也是碎片化的,因为硬盘是机械寻址器件,这种碎片化的写入会造成硬盘长时间高负荷的机械运动,造成硬盘过早老化损坏,当年有大量的硬盘因为BT下载而损坏。
于是新出的BT软件在内存里开辟了Buffer,数据暂时写入Buffer,攒到一定的大小(比如512M)再一次性写入硬盘,这种“化零为整”的写入方式大大降低了硬盘的负荷。
这就是:为了完成最终目标:把数据写入硬盘空间,需要暂时写入Buffer的空间。
再以编程为例,假设要实现一个功能:接受用户键入的字符串,并赋值给一个字符串变量
其过程如下:
1:在内存中开辟一个”键盘缓冲区“接受用户键入的字符串
2:把缓冲区中的字符串copy到程序中定义的字符串变量指向的内存空间(也就是赋值过程)
也就是说,为了完成最终目标:把字符串放入字符串变量指向的空间,需要暂时把字符串放入“键盘缓冲区”的空间。
以上举的3个栗子:箩筐、BT的Buffer,键盘缓冲区的Buffer
Buffer的存在是为了解决什么问题?找个临时的存储空间!
总结:
Cache和Buffer的相同点:都是2个层面之间的中间层,都是内存。
Cache和Buffer的不同点:Cache解决的是时间问题,Buffer解决的是空间问题。
为了提高速度,引入了Cache这个中间层。
为了给信息找到一个暂存空间,引入了Buffer这个中间层。
为了解决2个不同维度的问题(时间、空间),恰巧取了同一种解决方法:加入一个中间层,先把数据写到中间层上,然后再写入目标。
这个中间层就是内存“RAM”,既然是存储器就有2个参数:写入的速度有多块(速度),能装多少东西(容量)
Cache利用的是RAM提供的高读写速度,Buffer利用的是RAM提供的存储容量(空间)。
大佬的观点
2、Cache(缓存)则是系统两端处理速度不匹配时的一种折衷策略。因为CPU和memory之间的速度差异越来越大,所以人们充分利用数据的局部性(locality)特征,通过使用存储系统分级(memory hierarchy)的策略来减小这种差异带来的影响。
3、假定以后存储器访问变得跟CPU做计算一样快,cache就可以消失,但是buffer依然存在。比如从网络上下载东西,瞬时速率可能会有较大变化,但从长期来看却是稳定的,这样就能通过引入一个buffer使得OS接收数据的速率更稳定,进一步减少对磁盘的伤害。
4、TLB(Translation Lookaside Buffer,翻译后备缓冲器)名字起错了,其实它是一个cache。
[转] Cache 和 Buffer的区别的更多相关文章
- cache 和 buffer的区别
cache 和 buffer的区别: Cache:高速缓存,是位于CPU与主内存间的一种容量较小但速度很高的存储器.由于CPU的速度远高于主内存, CPU直接从内存中存取数据要等待一定时间周期,Cac ...
- Linux Free命令每个数字的含义 和 cache 、buffer的区别
Linux Free命令每个数字的含义 和 cache .buffer的区别 我们按照图中来一细细研读(数字编号和图对应)1,total:物理内存实际总量2,used:这块千万注意,这里可不是实际已经 ...
- Cache和Buffer的区别
一.研究数据库的人这样理解:http://wenku.baidu.com/view/32b8b13e376baf1ffc4fad7e.html Cache和Buffer是两个不同的概念,简单的说,Ca ...
- cache与buffer的区别
Cache vs Buffer 高速缓存和缓冲区 缓存区cache和缓冲区buffer都是临时存储区,但它们在许多方面有所不同.缓冲区buffer主要存在于RAM中,作为CPU暂时存储数据的区域,例如 ...
- Cache 和 Buffer 的区别在哪里
Cache和Buffer是两个不同的概念,简单的说,Cache是加速“读”,而buffer是缓冲“写”,前者解决读的问题,保存从磁盘上读出的数据,后者是解决写的问题,保存即将要写入到磁盘上的数据.在很 ...
- Cache、Buffer的区别
什么是Cache?什么是Buffer?二者的区别是什么? Buffer和Cache的区别 buffer与cache操作的对象就不一样. 1.buffer(缓冲)是为了提高内存和硬盘(或其他I/O设备) ...
- Cache和Buffer的区别(转载)
1. Cache:缓存区,是高速缓存,是位于CPU和主内存之间的容量较小但速度很快的存储器,因为CPU的速度远远高于主内存的速度,CPU从内存中读取数据需等待很长的时间,而 Cache保存着CPU刚 ...
- 【linux】Cache和Buffer的区别
- cache和buffer区别探讨
一. 1.Buffer(缓冲区)是系统两端处理速度平衡(从长时间尺度上看)时使用的.它的引入是为了减小短期内突发I/O的影响,起到流量整形的作用.比如生产者——消费者问题,他们产生和消耗资源的速度大体 ...
随机推荐
- ORA-00923: FROM keyword not found where expected
网上搜索这类错误还是挺多的,只提供我遇到的一种情景. 本地数据库环境:Oracle10g 导入别人的项目后,有一段SQL查询总是报如下错误信息: Cause: java.sql.SQLExceptio ...
- node开发遇到类似:Error: ENOENT: no such file or directory, scandir 'D:\work\taro-components- ....... _node-sass@4.12.0@node-sass\vendor
唯一的有参考价值的文章,https://www.cnblogs.com/milo-wjh/p/9175138.html 我可以负责任的说,以下的方法, npm rebuild node-sass 80 ...
- 管理node.js的nvm
我们坑同时在运行2个项目.而2个不同的项目所使用的node版本又不一样,或者是要用更新的node版本进行试验或学习.这种情况下,对于维护多个版本的node将会是一键非常麻烦的事情,而nvm就是为了解决 ...
- requests.session()会话保持
可能大家对session已经比较熟悉了,也大概了解了session的机制和原理,但是我们在做爬虫时如何会运用到session呢,就是接下来要讲到的会话保持. 首先说一下,为什么要进行会话保持的操作? ...
- Spring Boot 2.2.2 发布,新增 2 个新特性!
Spring Boot 2.2.2 发布咯! Spring Boot 2.2.1 发布,一个有点坑的版本! 2.2.1 发布没过一个月,2.2.2 就来了. Maven依赖给大家奉上: <dep ...
- 怎么删除iOS模拟器上的应用程序?
怎么删除iOS模拟器上的应用程序: 和手机上一样,鼠标长按,点击删除 xcode 卸载模拟器 Simulator:删除目录/Library/Developer/CoreSimulator/Profil ...
- elasticsearch 基于 rollover 管理按时间递增的索引 合并 删除
https://www.elastic.co/cn/blog/managing-time-based-indices-efficiently Anybody who uses Elasticsearc ...
- SVN版本管理系统使用教程
1.下载SVN安装包 https://tortoisesvn.net/downloads.html 2.下载SVN汉化包 网页下翻到下载处 3.下载服务端 https://www.visualsvn. ...
- this指北 (一篇读懂)
this 关键字 涵义 this关键字是一个非常重要的语法点.毫不夸张地说,不理解它的含义,大部分开发任务都无法完成. 前一章已经提到,this可以用在构造函数之中,表示实例对象.除此之外,this还 ...
- 关于Linux TCP "SACK PANIC" 远程拒绝服务漏洞的修复
Linux 内核被曝存在TCP "SACK PANIC" 远程拒绝服务漏洞(漏洞编号:CVE-2019-11477,CVE-2019-11478,CVE-2019-11479),攻 ...