深度学习中目标检测Object Detection的基础概念及常用方法
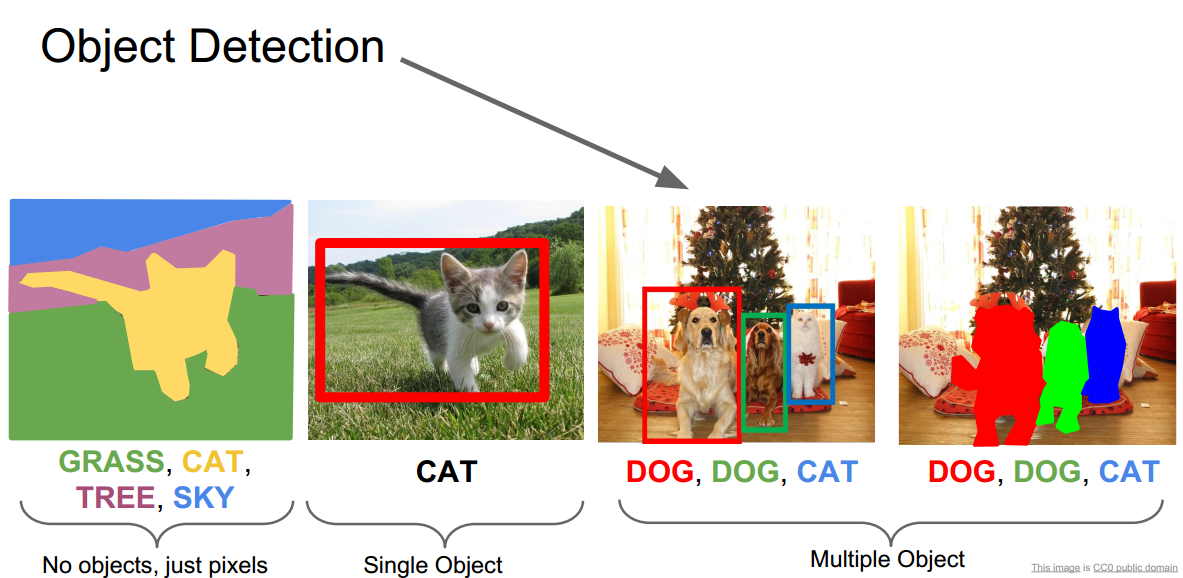
What is detection?
- detection的任务就是classification+localization
cs231n 课程截图
从左到右:语义分割semantic segmentation,图片分类classification,目标检测detection,实例分割instance segmentation
关键术语
ROI Region Of Interest 感兴趣区域,通常可以理解成图片中可能是物体的区域。 输入图片可以预先做一些标记找到候选框 proposal
- bounding box 在localization任务里的概念, 即给出物体在图片中的定位区域
- 一般表示为 (top, left, bottom, right) or (left, top, right, bottom). (left, top)为bbox左上角的坐标,(right, bottom)为右下角的坐标
IoU Intersection of Union 定义两个bbox的重叠程度 = (A交B) / (A并B) ,用于评价算法结果和人工标注(ground-truth)的差别

方法
two stage
将问题分两个阶段解决:首先从原图选出一系列候选框(object proposal)作为图中各个物体可能的bbox;然后将这些候选框输入到网络中,得出框的分类结果(多分类,是哪一类物体or背景?)和框的回归结果(坐标定位的准确值)
R-CNN
在第一阶段使用selective search这类region proposal method来得出一系列proposal;阶段二将每个region proposal分别输入到CNN网络中,提取出特征向量,然后交给SVM分类器。
因为是将proposal分别输入到网络,也就是针对各个region进行分类和回归,因此称为Region-based CNN
局限在于涉及很多重复计算(选出来的region很可能一大部分都是互相重叠的);而且selective research的效率不高
Fast R-CNN
在阶段二,针对R-CNN将每个proposal分别输入到网络带来的许多重复计算做出改进,提出直接将整张图输入到网络,只是在分类之前添加ROI pooling层,将阶段一提取出来的proposal(也就是ROI)映射到特征图中【注意阶段一提出来的proposal坐标是在原图坐标系下,因此还包括一个从原图尺度到当前特征图尺度的转换,一般是乘上缩放倍数】。
另一方面,Fast R-CNN也简化了整体的训练过程,不同于R-CNN将提取特征的网络、SVM分类、bbox回归看做三个独立的训练阶段,Fast R-CNN通过在网络中添加分类损失softmax loss和回归损失regression loss,结合两个损失(一般是加权求和),得到multi-task的loss,用其训练网络,使训练过程简化为只有一个阶段。
Faster R-CNN
Fast R-CNN提高了效率,但在阶段一仍然使用的是selective search之类的方法,阶段一和阶段二之间是分离的,这意味着训练的时候并不能做到端到端(end to end)的训练,换句话说,如果阶段一出现了错误导致阶段二表现不好,这个不好的结果无法在训练的时候回传到阶段一去使其做出调整。
因此Faster R-CNN提出了RPN(Region Proposal Network),将阶段一提取proposal的任务也用一个网络来解决,并且让阶段一和阶段二的网络共享一部分权值,从而节省了许多算力。

Faster R-CNN architecture
Faster R-CNN = RPN + Fast R-CNN
图中可以看出RPN 与 Fast R-CNN 两个网络共享了用来提取特征的卷积层,而得出特征图之后,RPN继续生成proposal,将RPN的输出与之前提取的特征图通过ROI pooling之后,作为Fast R-CNN后续部分的输入,得到分类结果与回归结果
RPN
RPN做的事情只是先粗略地提取出一堆候选框,通过网络进行分类(二分类,是物体or背景?)以及回归,得到较为准确的候选框,然后送入Fast RCNN进行更细致的分类与回归
提出概念anchor:
anchor是在原图上的
anchor以特征图上每个像素为中心,假设RPN的最后一层特征图尺寸为 f * f,原图的尺寸为 n * n,则anchor其实就是在原图 n * n上均匀地采 f * f个候选框,该候选框的面积和长宽比例是预定义的(anchor的参数)
anchor可以理解为 从特征图上的一点 s ,对应回原图的区域 S,注意这里的对应区域并不等于感受野。
同一个中心点,可以有多种形状\面积的anchor,代表着不同形状/面积的区域。
判断anchor是否属于物体,其实就是看在原图的区域里是否包含有物体,如果只有一部分的物体,则可能说明anchor取的面积比较小
换句话说,anchor其实就是对ground-truth bbox的一个encode。一张原图上分布有多个anchor,如果某一区域有ground-truth的bbox,它的类别标签是c,则与这个区域交叠的anchor,其分类目标应该为类别c,其回归目标应该为与ground-truth bbox的offset。
one stage
直接在整张图片上采样一系列的候选框
二者的区别,两阶段的方法中,对于稀疏的候选框集进行分类;单阶段则是将分类器应用到对原图进行常规地、稠密地采样得到的候选框集。
- 什么叫单阶段是常规地采样?因为两阶段的方法中,有一些可能会使用learning的方法进行采样,而单阶段则可能直接根据预先定义好的anchor数量尺寸等参数 在原图均匀地采样
共同存在问题
多尺度
不同物体有不同种尺寸,有的网络可能比较倾向于检测出大尺寸的物体(在图像中占面积比较大),而难以应对小物体
image pyramid
将同一张输入图像resize为多种尺寸,然后分别输入到网络中,将检测结果综合起来
feature pyramid
只用一张输入图像,但使用网络中来自不同层的特征图(不同层则意味着特征图尺寸不同),分别进行分类和回归,将结果综合起来
平移不变性
样本不均衡
各个步骤可能出现的问题
输入:
输入图片可能是多尺度的
- 输入的图片可能是同一张图的不同缩放版本,有的早期网络只能接受固定尺寸的输入,因而需要对图片进行剪裁、拉伸、压缩等操作来满足尺寸要求
由于一张图片中可能有多个物体,因此大多数方法都可以理解成,将一张图片切分成多张子图,分别输入到网络中
网络:
正负样本不均衡 class imbalance between positve and negtive
训练时,正样本(物体)远少于负样本(背景)的个数,这在one-stage的方法中非常常见,因为one stage是进行稠密地采样得到候选框
解决方法:
hard negative mining,计算分类损失的时候,只用正样本和一部分的负样本来算loss,这些被选取的负样本 分类到背景的置信度较低(也就是分类正确的置信度较低),称为“难负样本”
- focal loss,认为应该让所有样本都参与到分类损失的计算中,根据分到正确类别的置信度来调整权重,也就是说,那些 易分的样本(分到正确类别的置信度较高)权重则相应调低,难分的样本(分到正确类别的置信度较低) 权重则相应调高。
...
ROI pooling,两个作用:
将ROI从原图映射到feature map上,从而只需将一整张原图输入到网络,而不是将原图中不同的ROI分别输入网络;
将不同的ROI都pooling成固定的尺寸,也就是使得不同大小的ROI通过池化输出固定尺寸的特征向量,便于后续的分类与回归
anchor
- 某类方法会使用,预先定义好候选框的尺寸和比例,训练时需要encode ground-truth bbox为anchor的形式,regression分支的target是offset between anchor and ground-truth bbox,对于输出需要decode anchor为最终预测的bbox位置(其实就是加上offset)
输出:
NMS 非极大值抑制
- 可能一个物体的实际bbox,周围有好几个候选框都被检测出来,也就是对应着好几个检测结果,这时需要根据 confidence (理解为分类得分) 抑制那些非最大值,只保留confidence高的检测结果
评判标准
TP,FP计算precision 和 recall
mAP, mean average precision,VOC的11-point方法,取不同的threshold,计算precision和recall,画出P-R curve
参考资料
2D 总结 https://zhuanlan.zhihu.com/p/34142321
https://zhuanlan.zhihu.com/p/34179420 模型的评测与训练技巧
https://blog.csdn.net/JNingWei/article/details/80039079 他人总结的 框架图的形式解释各个类别
深度学习中目标检测Object Detection的基础概念及常用方法的更多相关文章
- 基于深度学习的目标检测(object detection)—— rcnn、fast-rcnn、faster-rcnn
模型和方法: 在深度学习求解目标检测问题之前的主流 detection 方法是,DPM(Deformable parts models), 度量与评价: mAP:mean Average Precis ...
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN,Faster R-CNN
基于深度学习的目标检测技术演进:R-CNN.Fast R-CNN,Faster R-CNN object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别.obj ...
- #Deep Learning回顾#之基于深度学习的目标检测(阅读小结)
原文链接:https://www.52ml.net/20287.html 这篇博文主要讲了深度学习在目标检测中的发展. 博文首先介绍了传统的目标检测算法过程: 传统的目标检测一般使用滑动窗口的框架,主 ...
- 关于目标检测(Object Detection)的文献整理
本文对CV中目标检测子方向的研究,整理了如下的相关笔记(持续更新中): 1. Cascade R-CNN: Delving into High Quality Object Detection 年份: ...
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别.object detection要解决的问题就是物体在哪里,是什么这整个流程的问题.然而,这个问题 ...
- (转)基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别.object detection要解决的问题就是物体在哪里,是什么这整个流程的问题.然而,这个问题 ...
- 关于目标检测 Object detection
NO1.目标检测 (分类+定位) 目标检测(Object Detection)是图像分类的延伸,除了分类任务,还要给定多个检测目标的坐标位置. NO2.目标检测的发展 R-CNN是最早基于C ...
- 【深度学习】目标检测算法总结(R-CNN、Fast R-CNN、Faster R-CNN、FPN、YOLO、SSD、RetinaNet)
目标检测是很多计算机视觉任务的基础,不论我们需要实现图像与文字的交互还是需要识别精细类别,它都提供了可靠的信息.本文对目标检测进行了整体回顾,第一部分从RCNN开始介绍基于候选区域的目标检测器,包括F ...
- 利用更快的r-cnn深度学习进行目标检测
此示例演示如何使用名为“更快r-cnn(具有卷积神经网络的区域)”的深度学习技术来训练对象探测器. 概述 此示例演示如何训练用于检测车辆的更快r-cnn对象探测器.更快的r-nnn [1]是r-cnn ...
随机推荐
- Windows文件夹共享和Unity的PersisterdataPath
在共享机上存放unity开发的pc版本游戏,在其它机器双击就可以运行,但会遇到问题,比如: 游戏是需要下载资源的,默认情况下unity下载的资源是存放在persisterdataPath目录的,对于w ...
- MD文件图片base64自动编码
看工具链接请直接将文章拉到最后.. 概述 不知道你在使用markdown写文章的时候有没有遇到过这样的烦恼, 文件写完了, 想将写完的文章粘贴到博客的时候, 你满心欢喜的复制粘贴, 但是发现图片根本复 ...
- MongoDB介绍(一)
MongoDB是一个基于分布式文件存储的数据库.由C++语言编写.旨在为WEB应用提供可扩展的高性能数据存储解决方案. MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功 ...
- java自定义词典使用Hanlp
一开始按照网上的方法在配置文件加入自定义的词典不行,不知道是什么问题,这里给出链接,有兴趣的自己尝试:https://my.oschina.net/u/3793864/blog/3073171 说一下 ...
- 高性能MySQL count(1)与count(*)的差别
-------------------------------------------------------------------------------------------------第一篇 ...
- 纯CSS打造BiliBili样式博客主题
前言 一直以来,我都在思考如何减少不必要的JS代码,仅通过CSS来实现博客园主题美化.CSS有很多魔法代码,例如:before,iconfont,order,等等,利用好这些技巧,也能实现很好美化效果 ...
- Java 未来行情到底如何,来看看各界人士是怎么说的
这是黄小斜的第102篇文章 作者 l 黄小斜 来源 l 公众号[程序员黄小斜](ID:AntCoder) 转载请联系作者(wx_ID:john_josh) Java从出生到现在已经走过了 20 多个年 ...
- ubutnu 挂载磁盘
1. 查看已挂载的磁盘 df -h 2. 查看可挂载的磁盘 fdisk -l 3. 创建挂载点 mkdir /media/HDD 注意: /media/HDD 必须为空文件夹 4. 挂载 sudo m ...
- Linux和windows下修改tomcat内存
原文地址:https://www.cnblogs.com/wdpnodecodes/p/8036333.html 由于服务器上放的tomcat太多,造成内存溢出. 常见的内存溢出有以下两种: java ...
- 【LOJ#3145】[APIO2019]桥梁(分块,并查集)
[LOJ#3145][APIO2019]桥梁(分块,并查集) 题面 LOJ 题解 因为某个\(\text{subtask}\)没判\(n=1\)的情况导致我自闭了很久的题目... 如果没有修改操作,可 ...