Andrew Ng机器学习 三:Multi-class Classification and Neural Networks
背景:识别手写数字,给一组数据集ex3data1.mat,,每个样例都为灰度化为20*20像素,也就是每个样例的维度为400,加载这组数据后,我们会有5000*400的矩阵X(5000个样例),会有5000*1的矩阵y(表示每个样例所代表的数据)。现在让你拟合出一个模型,使得这个模型能很好的预测其它手写的数字。
(注意:我们用10代表0(矩阵y也是这样),因为Octave的矩阵没有0行)
我们随机可视化100个样例,可以看到如下图所示:
一:多类别分类(Multi-class Classification)
在这我们使用逻辑回归多类别分类去拟合数据。在这组数据,总共有10类别,我们可以将它们分成10个2元分类问题,最后我们选择一个让$h_\theta^i(x)$最大的$i$。
逻辑回归脚本ex3.m:
%% Machine Learning Online Class - Exercise | Part : One-vs-all % Instructions
% ------------
%
% This file contains code that helps you get started on the
% linear exercise. You will need to complete the following functions
% in this exericse:
%
% lrCostFunction.m (logistic regression cost function)
% oneVsAll.m
% predictOneVsAll.m
% predict.m
%
% For this exercise, you will not need to change any code in this file,
% or any other files other than those mentioned above.
% %% Initialization
clear ; close all; clc %% Setup the parameters you will use for this part of the exercise
input_layer_size = ; % 20x20 Input Images of Digits
num_labels = ; % labels, from to
% (note that we have mapped "" to label ) %% =========== Part : Loading and Visualizing Data =============
% We start the exercise by first loading and visualizing the dataset.
% You will be working with a dataset that contains handwritten digits.
% % Load Training Data
fprintf('Loading and Visualizing Data ...\n') load('ex3data1.mat'); % training data stored in arrays X, y
m = size(X, ); % Randomly select data points to display
rand_indices = randperm(m);
sel = X(rand_indices(:), :); displayData(sel); fprintf('Program paused. Press enter to continue.\n');
pause; %% ============ Part 2a: Vectorize Logistic Regression ============
% In this part of the exercise, you will reuse your logistic regression
% code from the last exercise. You task here is to make sure that your
% regularized logistic regression implementation is vectorized. After
% that, you will implement one-vs-all classification for the handwritten
% digit dataset.
% % Test case for lrCostFunction
fprintf('\nTesting lrCostFunction() with regularization'); theta_t = [-; -; ; ];
X_t = [ones(,) reshape(:,,)/];
y_t = ([;;;;] >= 0.5);
lambda_t = ;
[J grad] = lrCostFunction(theta_t, X_t, y_t, lambda_t); fprintf('\nCost: %f\n', J);
fprintf('Expected cost: 2.534819\n');
fprintf('Gradients:\n');
fprintf(' %f \n', grad);
fprintf('Expected gradients:\n');
fprintf(' 0.146561\n -0.548558\n 0.724722\n 1.398003\n'); fprintf('Program paused. Press enter to continue.\n');
pause;
%% ============ Part 2b: One-vs-All Training ============
fprintf('\nTraining One-vs-All Logistic Regression...\n') lambda = 0.1;
[all_theta] = oneVsAll(X, y, num_labels, lambda); %*,每行表示标签i的拟合参数 fprintf('Program paused. Press enter to continue.\n');
pause; %% ================ Part : Predict for One-Vs-All ================ pred = predictOneVsAll(all_theta, X); fprintf('\nTraining Set Accuracy: %f\n', mean(double(pred == y)) * );
ex3.m
1,正则化逻辑回归代价函数(忽略偏差项$\theta_0$的正则化):
$J(\theta)=-\frac{1}{m}\sum_{i=1}^{m}[y^{(i)}log(h_\theta(x^{(i)}))+(1-y^{(i)})log(1-h_{\theta}(x^{(i)}))]+\frac{\lambda }{2m}\sum_{j=1}^{n}\theta_j^{2}$
2,梯度下降:
不带学习速率(给之后fmincg作为梯度下降使用):
$\frac{\partial J(\theta)}{\partial \theta_0}=\frac{1}{m}\sum_{i=1}^{m}[(h_\theta(x^{(i)})-y^{(i)})x^{(i)}_0]$ for $j=0$
$\frac{\partial J(\theta)}{\partial \theta_j}=(\frac{1}{m}\sum_{i=1}^{m}[(h_\theta(x^{(i)})-y^{(i)})x^{(i)}_j])+\frac{\lambda }{m}\theta_j $ for $j\geq 1$
代价函数代码:
function [J, grad] = lrCostFunction(theta, X, y, lambda)
%LRCOSTFUNCTION Compute cost and gradient for logistic regression with
%regularization
% J = LRCOSTFUNCTION(theta, X, y, lambda) computes the cost of using
% theta as the parameter for regularized logistic regression and the
% gradient of the cost w.r.t. to the parameters. % Initialize some useful values
m = length(y); % number of training examples % You need to return the following variables correctly
J = ;
grad = zeros(size(theta)); % ====================== YOUR CODE HERE ======================
% Instructions: Compute the cost of a particular choice of theta.
% You should set J to the cost.
% Compute the partial derivatives and set grad to the partial
% derivatives of the cost w.r.t. each parameter in theta
%
% Hint: The computation of the cost function and gradients can be
% efficiently vectorized. For example, consider the computation
%
% sigmoid(X * theta)
%
% Each row of the resulting matrix will contain the value of the
% prediction for that example. You can make use of this to vectorize
% the cost function and gradient computations.
%
% Hint: When computing the gradient of the regularized cost function,
% there're many possible vectorized solutions, but one solution
% looks like:
% grad = (unregularized gradient for logistic regression)
% temp = theta;
% temp() = ; % because we don't add anything for j = 0
% grad = grad + YOUR_CODE_HERE (using the temp variable)
%
h=sigmoid(X*theta);
theta(,)=;
J=(-(y')*log(h)-(1-y)'*log(-h))/m+lambda//m*sum(power(theta,));%代价函数
grad=(X'*(h-y))./m+(lambda/m).*theta; %不带学习速率的梯度下降 % ============================================================= grad = grad(:); end
lrCostFunction.m
拟合参数:
function [all_theta] = oneVsAll(X, y, num_labels, lambda)
%ONEVSALL trains multiple logistic regression classifiers and returns all
%the classifiers in a matrix all_theta, where the i-th row of all_theta
%corresponds to the classifier for label i
% [all_theta] = ONEVSALL(X, y, num_labels, lambda) trains num_labels
% logistic regression classifiers and returns each of these classifiers
% in a matrix all_theta, where the i-th row of all_theta corresponds
% to the classifier for label i % Some useful variables
m = size(X, ); %
n = size(X, ); % % You need to return the following variables correctly
all_theta = zeros(num_labels, n + ); %* % Add ones to the X data matrix
X = [ones(m, ) X]; %* % ====================== YOUR CODE HERE ======================
% Instructions: You should complete the following code to train num_labels
% logistic regression classifiers with regularization
% parameter lambda.
%
% Hint: theta(:) will return a column vector.
%
% Hint: You can use y == c to obtain a vector of 's and 0's that tell you
% whether the ground truth is true/false for this class.
%
% Note: For this assignment, we recommend using fmincg to optimize the cost
% function. It is okay to use a for-loop (for c = :num_labels) to
% loop over the different classes.
%
% fmincg works similarly to fminunc, but is more efficient when we
% are dealing with large number of parameters.
%
% Example Code for fmincg:
%
% % Set Initial theta
% initial_theta = zeros(n + , );
%
% % Set options for fminunc
% options = optimset('GradObj', 'on', 'MaxIter', );
%
% % Run fmincg to obtain the optimal theta
% % This function will return theta and the cost
% [theta] = ...
% fmincg (@(t)(lrCostFunction(t, X, (y == c), lambda)), ...
% initial_theta, options);
% for c=:num_labels,
initial_theta = zeros(n + , ); %*
options = optimset('GradObj', 'on', 'MaxIter', );
[theta] = ...
fmincg (@(t)(lrCostFunction(t, X, (y == c), lambda)), ...
initial_theta, options);
all_theta(c,:)=theta; %给标签c拟合参数
end; % ========================================================================= end
oneVsAll.m
3, 预测:我们根据我们拟合好的参数$\theta$去预测样例。我们可以看到我们使用逻辑回归去拟合对类别分类问题的准确率为95%。我们可以增加更多的特征,让我们的准确率更高,但因为过高的维度,最后我们可能要花费昂贵的训练代价。
function p = predictOneVsAll(all_theta, X)
%PREDICT Predict the label for a trained one-vs-all classifier. The labels
%are in the range ..K, where K = size(all_theta, ).
% p = PREDICTONEVSALL(all_theta, X) will return a vector of predictions
% for each example in the matrix X. Note that X contains the examples in
% rows. all_theta is a matrix where the i-th row is a trained logistic
% regression theta vector for the i-th class. You should set p to a vector
% of values from ..K (e.g., p = [; ; ; ] predicts classes , , ,
% for examples) m = size(X, );
num_labels = size(all_theta, ); % You need to return the following variables correctly
p = zeros(size(X, ), ); % Add ones to the X data matrix
X = [ones(m, ) X]; % ====================== YOUR CODE HERE ======================
% Instructions: Complete the following code to make predictions using
% your learned logistic regression parameters (one-vs-all).
% You should set p to a vector of predictions (from to
% num_labels).
%
% Hint: This code can be done all vectorized using the max function.
% In particular, the max function can also return the index of the
% max element, for more information see 'help max'. If your examples
% are in rows, then, you can use max(A, [], ) to obtain the max
% for each row.
% temp = X*all_theta'; %(5000,401)*(401*10)
[maxx, p] = max(temp,[],); %返回每行的最大值 % ========================================================================= end
predictOneVsAll.m
二:神经网络(Neural Networks)
这里已经拟合好三层网络的参数$\Theta1$和$\Theta2$,只需加载ex3weights.mat就可以了。
中间层(hidden layer)$\Theta1$的size为25x401,输出层( output layer)$\Theta2$的size为10x26。
根据前向传播算法(Feedforward Propagation)来去预测数据,
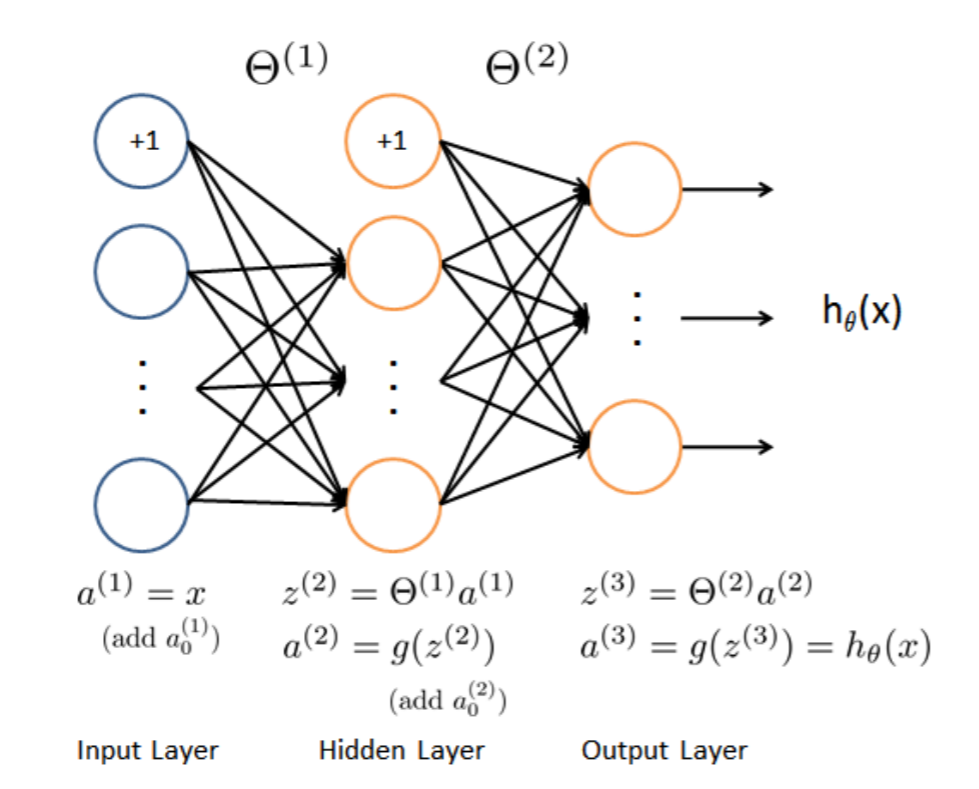
$z^{(2)}=\Theta^{(1)}x$
$a^{(2)}=g(z^{(2)})$
$z^{(3)}=\Theta^{(2)}a^{(2)}$
$a^{(3)}=g(z^{(3)})=h_\theta(x)$
function p = predict(Theta1, Theta2, X)
%PREDICT Predict the label of an input given a trained neural network
% p = PREDICT(Theta1, Theta2, X) outputs the predicted label of X given the
% trained weights of a neural network (Theta1, Theta2) % Useful values
m = size(X, );
num_labels = size(Theta2, ); % You need to return the following variables correctly
p = zeros(size(X, ), ); % ====================== YOUR CODE HERE ======================
% Instructions: Complete the following code to make predictions using
% your learned neural network. You should set p to a
% vector containing labels between to num_labels.
%
% Hint: The max function might come in useful. In particular, the max
% function can also return the index of the max element, for more
% information see 'help max'. If your examples are in rows, then, you
% can use max(A, [], ) to obtain the max for each row.
% X=[ones(m,) X]; %而外增加一列偏差单位
item=sigmoid(X*Theta1'); %计算a^{(2)}
item=[ones(m,) item];
item=sigmoid(item*Theta2');
[a,p]=max(item,[],); %每行最大值 % ========================================================================= end
predict.m
最后我们可以看到,预测的准确率为97.5%。
我的便签:做个有情怀的程序员。
Andrew Ng机器学习 三:Multi-class Classification and Neural Networks的更多相关文章
- Andrew Ng机器学习编程作业:Multi-class Classification and Neural Networks
作业文件 machine-learning-ex3 1. 多类分类(Multi-class Classification) 在这一部分练习,我们将会使用逻辑回归和神经网络两种方法来识别手写体数字0到9 ...
- Andrew Ng机器学习课程笔记(三)之正则化
Andrew Ng机器学习课程笔记(三)之正则化 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7365475.html 前言 ...
- Andrew Ng机器学习课程笔记(四)之神经网络
Andrew Ng机器学习课程笔记(四)之神经网络 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7365730.html 前言 ...
- Andrew Ng机器学习课程笔记(二)之逻辑回归
Andrew Ng机器学习课程笔记(二)之逻辑回归 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7364636.html 前言 ...
- Andrew Ng机器学习课程9-补充
Andrew Ng机器学习课程9-补充 首先要说的还是这个bias-variance trade off,一个hypothesis的generalization error是指的它在样本上的期望误差, ...
- Andrew Ng机器学习课程14(补)
Andrew Ng机器学习课程14(补) 声明:引用请注明出处http://blog.csdn.net/lg1259156776/ 利用EM对factor analysis进行的推导还是要参看我的上一 ...
- Andrew Ng机器学习课程笔记(五)之应用机器学习的建议
Andrew Ng机器学习课程笔记(五)之 应用机器学习的建议 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7368472.h ...
- Andrew Ng机器学习课程笔记--week1(机器学习介绍及线性回归)
title: Andrew Ng机器学习课程笔记--week1(机器学习介绍及线性回归) tags: 机器学习, 学习笔记 grammar_cjkRuby: true --- 之前看过一遍,但是总是模 ...
- Andrew Ng机器学习课程笔记--汇总
笔记总结,各章节主要内容已总结在标题之中 Andrew Ng机器学习课程笔记–week1(机器学习简介&线性回归模型) Andrew Ng机器学习课程笔记--week2(多元线性回归& ...
随机推荐
- SpringBoot系列教程web篇之Freemaker环境搭建
现在的开发现状比较流行前后端分离,使用springboot搭建一个提供rest接口的后端服务特别简单,引入spring-boot-starter-web依赖即可.那么在不分离的场景下,比如要开发一个后 ...
- Influx Sql系列教程二:retention policy 保存策略
retention policy这个东西相比较于传统的关系型数据库(比如mysql)而言,是一个比较新的东西,在将表之前,有必要来看一下保存策略有什么用,以及可以怎么用 I. 基本操作 1. 创建re ...
- 第07组 Beta冲刺(2/4)
队名:秃头小队 组长博客 作业博客 组长徐俊杰 过去两天完成的任务:学习了很多东西 Github签入记录 接下来的计划:继续学习 还剩下哪些任务:后端部分 燃尽图 遇到的困难:自己太菜了 收获和疑问: ...
- 自动化运维工具之SaltStack简介与安装
1.SaltStack简介 官方网址:http://www.saltstack.com官方文档:http://docs.saltstack.comGitHub:https:github.com/sal ...
- MySQL8.0.16 单机 Linux安装以及使用
安装 先去下载 https://dev.mysql.com/downloads/mysql/ 然后上传到Linux 进入存放目录,解压到指定目录[我这里是/soft/mysql8] [root@loc ...
- [转帖]关于一个 websocket 多节点分布式问题的头条前端面试题
关于一个 websocket 多节点分布式问题的头条前端面试题 https://juejin.im/post/5dcb5372518825352f524614 你来说说 websocket 有什么用? ...
- [转帖]抢先AMD一步,英特尔推出新处理器,支持LPDDR5!
抢先AMD一步,英特尔推出新处理器,支持LPDDR5! http://www.eetop.cn/cpu_soc/6946240.html 2019.10 intel的最新技术发展. 近日,知名硬件爆料 ...
- 使用guava cache在本地缓存热点数据
某些热点数据在短时间内可能会被成千上万次访问,所以除了放在redis之外,还可以放在本地内存,也就是JVM的内存中. 我们可以使用google的guava cache组件实现本地缓存,之所以选择gua ...
- flask报错 KeyError: <flask.cli.ScriptInfo object at 0x000001638AC164E0>
(flask_venv) D:\DjangoProject\flask_test>flask db init Traceback (most recent call last): File &q ...
- 通过Anaconda安装的jupyter notebook,打开时,未能启动默认浏览器
问题:通过Anaconda安装的jupyter notebook,通过开始菜单的快捷方式打开时,未能启动网页,需要复制url,粘贴到浏览器中才会出现工作面板. 解决方法: 修改jupyter_note ...