大数据之路week07--day07 (Hive结构设计以及Hive语法)
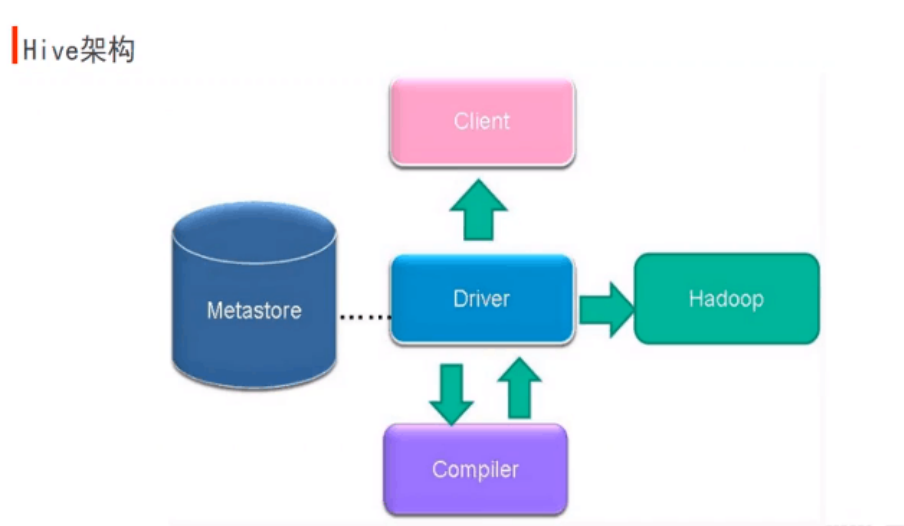
Hive架构流程(十分重要,结合图进行记忆理解)当客户端提交请求,它先提交到Driver,Driver拿到这个请求后,先把表明,字段名拿出来,去数据库进行元数据验证,也就是Metasore,如果有,返回有,Driver再返回给Complier编译器,进行HQL解析到MR任务的转化过程,执行完之后提交回给Driver一个MR任务,然后提交到Hadoop集群,交给YRAN进行接收请求并处理,产生结果,把结果再返回给Driver, Driver再把结果返回给客户端进行显示。
当写了一串非常复杂的SQL语句的时候,编译器会把这个SQL语句转化成N多个操作符,把这些操作符拼接起来之后变成MR任务
1、编译器将一个Hive SQL转化为操作符
2、操作符是Hive最小的处理单元
3、每个操作符代表HDFS的一个操作或者是一个mapreduce作业
客户端有,CLI ,Client ,WUI
========================================================================================================================================
Hive的基本数据类型
基本数据类型
整型 TINYINT — 微整型,只占用1个字节,只能存储0-255的整数。
SMALLINT– 小整型,占用2个字节,存储范围–32768 到 32767。
INT– 整型,占用4个字节,存储范围-2147483648到2147483647。
BIGINT– 长整型,占用8个字节,存储范围-2^63到2^63-1。
布尔型BOOLEAN — TRUE/FALSE
浮点型FLOAT– 单精度浮点数。
DOUBLE– 双精度浮点数。
字符串型STRING– 不设定长度。
日期类型:
1,Timestamp 格式“YYYY-MM-DD HH:MM:SS.fffffffff”(9位小数位精度)
2,Date DATE值描述特定的年/月/日,格式为YYYY-MM-DD。
复杂数据类型: Structs,Maps,Arrays
A $ B 按位与 只有当两位都是1的时候才是1
A^B 按位异或 有且只有一位是1的时候才是1
复杂数据类型:
在Hive中如何使用符合数据结构 maps,array,structs
1 Array的使用
创建数据库表,以array作为数据类型
create table person(name string,work_locations array<string>)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ',';
数据
biansutao beijing,shanghai,tianjin,hangzhou
linan changchu,chengdu,wuhan
入库数据
LOAD DATA LOCAL INPATH '/home/Hadoop/person.txt' OVERWRITE INTO TABLE person;
查询
hive> select * from person;
biansutao ["beijing","shanghai","tianjin","hangzhou"]
linan ["changchu","chengdu","wuhan"]
Time taken: 0.355 seconds
hive> select name from person;
linan
biansutao
Time taken: 12.397 seconds
hive> select work_locations[0] from person;
changchu
beijing
Time taken: 13.214 seconds
hive> select work_locations from person;
["changchu","chengdu","wuhan"]
["beijing","shanghai","tianjin","hangzhou"]
Time taken: 13.755 seconds
hive> select work_locations[3] from person;
NULL
hangzhou
Time taken: 12.722 seconds
hive> select work_locations[4] from person;
NULL
NULL
Time taken: 15.958 seconds
2 Map的使用
创建数据库表
create table score(name string, score map<string,int>)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY ':';
数据
biansutao '数学':80,'语文':89,'英语':95
jobs '语文':60,'数学':80,'英语':99
入库数据
LOAD DATA LOCAL INPATH '/home/hadoop/score.txt' OVERWRITE INTO TABLE score;
查询
hive> select * from score;
biansutao {"数学":80,"语文":89,"英语":95}
jobs {"语文":60,"数学":80,"英语":99}
Time taken: 0.665 seconds
hive> select name from score;
jobs
biansutao
Time taken: 19.778 seconds
hive> select t.score from score t;
{"语文":60,"数学":80,"英语":99}
{"数学":80,"语文":89,"英语":95}
Time taken: 19.353 seconds
hive> select t.score['语文'] from score t;
60
89
Time taken: 13.054 seconds
hive> select t.score['英语'] from score t;
99
95
Time taken: 13.769 seconds
3 Struct的使用
创建数据表
CREATE TABLE test(id int,course struct<course:string,score:int>)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ',';
数据
1 english,80
2 math,89
3 chinese,95
入库
LOAD DATA LOCAL INPATH '/home/hadoop/test.txt' OVERWRITE INTO TABLE test;
查询
hive> select * from test;
OK
1 {"course":"english","score":80}
2 {"course":"math","score":89}
3 {"course":"chinese","score":95}
Time taken: 0.275 seconds
hive> select course from test;
{"course":"english","score":80}
{"course":"math","score":89}
{"course":"chinese","score":95}
Time taken: 44.968 seconds
select t.course.course from test t;
english
math
chinese
Time taken: 15.827 seconds
hive> select t.course.score from test t;
80
89
95
Time taken: 13.235 seconds
4 数据组合(不支持组合的复杂数据类型)
LOAD DATA LOCAL INPATH '/home/hadoop/test.txt' OVERWRITE INTO TABLE test;
create table test1(id int,a MAP<STRING,ARRAY<STRING>>)
row format delimited fields terminated by '\t'
collection items terminated by ','
MAP KEYS TERMINATED BY ':';
1 english:80,90,70
2 math:89,78,86
3 chinese:99,100,82
LOAD DATA LOCAL INPATH '/home/hadoop/test1.txt' OVERWRITE INTO TABLE test1;
=============================================================================================================
DDL编程:
创建数据库 create database xxxxx;
查看数据库 show databases;
删除数据库 drop database tmp;
强制删除数据库:drop database tmp cascade;
查看表:SHOW TABLES;
查看表的元信息:
desc test_table;
describe extended test_table;
describe formatted test_table;(使用这个居多,因为这个查看是最详细的)
查看建表语句:show create table table_XXX
重命名表: alter table test_table rename to new_table;
修改列数据类型:alter table lv_test change column colxx string;
增加、删除分区:
alter table test_table add partition (pt=xxxx)
alter table test_table drop if exists partition(...);
===========================================================================================================================
Hive去加载数据的时候不会去校验格式,只有在查询的时候去校验。
Hive中默认是没有事务的非常弱化,可以当作没有,一边进行写数据,一边读数据,
将HDFS上的数据加载到Hive中去(注意这里是移动,加载过去后,原来HDFS的路径下的文件没有了)
load data inpath '/usr/test/dianxin_data' into table dianxin_1 partition(province='zhejiang');
也可以从本地进行加载,(注意,从本地加载是复制)
load data local inpath '/usr/local/soft/data/shujia006_hive/dianxin_data' into table dianxin_1 partition(province='nanjing');
表对表进行加载数据(注意,这里是复制,查询到的结果进行生成一张表)
方式一:create table dianxin_test1 as select * from danxin_1 limit 10;
方式二:insert [overwrite] into table dianxin_test2 select * from dianxin_test;
===========================================================================================================================
外部表和内部表的区别
删除表后,内部表数据文件和表信息都删除。
外部表仅删除表信息
CREATE EXTERNAL TABLE IF NOT EXISTS dianxin_like LIKE dianxin_503;
加了EXTERNAL就是外部表,没加就是内部表
create [EXTERNAL] table vv_stat_fact
(
userid string,
stat_date string,
tryvv int,
sucvv int,
ptime float
)
PARTITIONED BY ( 非必选;创建分区表dt string)
clustered by (userid) into 3000 buckets // 非必选;分桶子
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' // 必选;指定列之间的分隔符
STORED AS rcfile // 非必选;指定文件的读取格式,默认textfile格式
location '/testdata/'; //非必选;指定文件在hdfs上的存储路径,如果已经有文件,会自动加载 ,默认在hive的warehouse下
====================================================================
建表1:
create table user_bh
(
phone string,
jw string,
city_id string,
area_id string,
stay_time string,
start_time string,
end_time string,
date_time string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
注意:默认数据存储位置在 /user/hive/warehouse/
====================================================================
建表2:
create table user_bh_rc
(
phone string,
jw string,
city_id string,
area_id string,
stay_time string,
start_time string,
end_time string,
date_time string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS rcfile
文件存储格式是rcfile,不能直接加载文本数据。一般是从其他表加载数据。
====================================================================
建表3:
create table user_bh_loc
(
phone string,
jw string,
city_id string,
area_id string,
stay_time string,
start_time string,
end_time string,
date_time string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
location '/testdata/';
hive表会加载在存储目录下所有可以加载的数据。要求hive对应的hdfs目录下所有的文件格式、字段个数、分隔符要完全一致。
hive是读时模式,就是当读取查询的时候才会校验文件格式。存储的时候不会校验。当格式不统一,比如字段个数不一致,分隔符不一致,查选的
时候会有异常,出现null。
====================================================================
建表4:
create table t1 as select * from user_bh;
create table t2 like user_bh;(只是复制表结构,不复制数据)
外部表和内部表的区别:
1 删除表,内部表(普通表)会将元信息以及数据目录删除。外部表仅仅删除元信息,不删除原始数据
2 一般使用外部表,可以避免误删
3 可以作为临时表(hdfs上的数据是已经存在的,但是数据很重要)
====================================================================
(创建一个外部表 external)
create EXTERNAL table user_bh_ext
(
phone string,
jw string,
city_id string,
area_id string,
stay_time string,
start_time string,
end_time string,
date_time string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
====================================================================
分区表:实际上是就是在原表的基础上,增加一个分区字段,用于区分数据。放到不同的子目录中。
create table dianxin_1
(
phone string,
jw string,
city_id string,
area_id string,
stay_time string,
start_time string,
end_time string,
date_time string
)partitioned by (province string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
增加一个分区:表必须在建表的时候定义它是一个分区表,并且指定分区字段。
alter table user_bh_part add partition(provience="shandong");
====================================================================
公司中最常用的分区是按照日期进行分区。partitioned by (dt string)
可以创建多级分区:一般最多两级分区,分区太多,影响查询效率
create table dianxin_3
(
phone string,
jw string,
city_id string,
area_id string,
stay_time string,
start_time string,
end_time string,
date_time string
)partitioned by (province string,dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
alter table user_bh_part2 add partition(provience="anhui",dt="20191220");
====================================================================
分区特点:建表的时候要定义好,避免全表扫描,提高查询效率。
用法:通过分区字段去过滤,或者裁剪数据。
分区字段在sql中用起来和普通字段一样。
开启动态分区支持
hive>set hive.exec.dynamic.partition=true;
hive>set hive.exec.dynamic.partition.mode=nostrict;
hive>set hive.exec.max.dynamic.partitions.pernode=1000;
加大动态分区数
操作语句 insert into table anhui_air partition (dt) select part,pm25,date_time from anhui_air2;
开启后,查询的语句中最后的对应的字段作为动态分区的字段,会按照这个字段进行分区,相同的值会放到同一个分区
动态分区:适用于将原始非分区表数据,进行动态自动分区到指定的分区表。
create table user_bh_city
(
phone string,
jw string,
city_id string,
area_id string,
stay_time string,
start_time string,
end_time string,
date_time string
)partitioned by (city string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
insert into user_bh_city partition(city) select phone,jw,city_id,area_id,stay_time,start_time,end_time,date_time,city_id from user_bh_loc;
====================================================================
去重
select distinct ename from emp limit 10;
连接
concat_ws()
====================================================================
创建结构化的
create table t(id struct<id1:int,id2:int,id3:int>,name array<string>,xx map<int,string>)
row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n'
文本数据准备:
1,2,3 1,2,3,4,5 05:李智恩,06:王友虎
注意:
ROW FORMAT DELIMITED 必须在其它分隔设置之前,也就是分隔符设置语句的最前
LINES TERMINATED BY必须在其它分隔设置之后,也就是分隔符设置语句的最后,否则会报错
(下面的写法回报错)
hive> create table t (id struct<id1:int,id2:int,id3:int>,name array<string>,xx map<int,string>)
> row format delimited
> fields terminated by '\t'
> lines terminated by '\n'
> collection items terminated by ','
> map keys terminated by ':';
FAILED: ParseException line 5:0 missing EOF at 'collection' near ''\n''
大数据之路week07--day07 (Hive结构设计以及Hive语法)的更多相关文章
- 胖子哥的大数据之路(10)- 基于Hive构建数据仓库实例
一.引言 基于Hive+Hadoop模式构建数据仓库,是大数据时代的一个不错的选择,本文以郑商所每日交易行情数据为案例,探讨数据Hive数据导入的操作实例. 二.源数据-每日行情数据 三.建表脚本 C ...
- 大数据之路week07--day05 (一个基于Hadoop的数据仓库建模工具之一 HIve)
什么是Hive? 我来一个短而精悍的总结(面试常问) 1:hive是基于hadoop的数据仓库建模工具之一(后面还有TEZ,Spark). 2:hive可以使用类sql方言,对存储在hdfs上的数据进 ...
- 大数据之路week07--day05 (Hive的搭建部署)
在之前博客中我有记录安装JDK和Hadoop和Mysql的过程,如果还没有安装,请先进行安装配置好,对应的随笔我也提供了百度云下载连接. 安装JDK: https://www.cnblogs.co ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据技术生态圈形象比喻(Hadoop、Hive、Spark 关系)
[摘要] 知乎上一篇很不错的科普文章,介绍大数据技术生态圈(Hadoop.Hive.Spark )的关系. 链接地址:https://www.zhihu.com/question/27974418 [ ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
- 大数据之路week07--day06 (Sqoop 将关系数据库(oracle、mysql、postgresql等)数据与hadoop数据进行转换的工具)
为了方便后面的学习,在学习Hive的过程中先学习一个工具,那就是Sqoop,你会往后机会发现sqoop是我们在学习大数据框架的最简单的框架了. Sqoop是一个用来将Hadoop和关系型数据库中的数据 ...
- 大数据之路week06--day07(Hadoop生态圈的介绍)
Hadoop 基本概念 一.Hadoop出现的前提环境 随着数据量的增大带来了以下的问题 (1)如何存储大量的数据? (2)怎么处理这些数据? (3)怎样的高效的分析这些数据? (4)在数据增长的情况 ...
- 大数据之路week04--day06(I/O流阶段一 之异常)
从这节开始,进入对I/O流的系统学习,I/O流在往后大数据的学习道路上尤为重要!!!极为重要,必须要提起重视,它与集合,多线程,网络编程,可以说在往后学习或者是工作上,起到一个基石的作用,没了地基,房 ...
- C#码农的大数据之路 - 使用C#编写MR作业
系列目录 写在前面 从Hadoop出现至今,大数据几乎就是Java平台专属一般.虽然Hadoop或Spark也提供了接口可以与其他语言一起使用,但作为基于JVM运行的框架,Java系语言有着天生优势. ...
随机推荐
- Appium 环境配置(sdk)
1,jdk环境配置 参见jdk环境配置:https://www.cnblogs.com/changpuyi/p/8659545.html 2,sdk环境的配置 前提已经下载,解压adt-bundle- ...
- 01.在Java中如何创建PDF文件
1.简介 在这篇快速文章中,我们将重点介绍基于流行的iText和PdfBox库从头开始创建 PDF 文档. 2. Maven 依赖 <dependency> <groupId> ...
- spring整合mybatis报.UnsatisfiedDependencyException错误
tomcat启动报org.springframework.beans.factory.UnsatisfiedDependencyException:错误 org.springframework.bea ...
- JS Web API 拖拽对话框案例
<style> .login-header { width: 100%; text-align: right; height: 30px; font-size: 24px; line-he ...
- IIS err_connection_timed_out(响应时间过长)
场景:我在服务器的IIS上部署了一个网站,服务器上可以正常打开,然后我用自己的电脑访问,出现如下错误: 原因:服务器的防火墙对入站规则进行了一些限制. 解决方法:1.打开服务器的防火墙-----> ...
- Go defer 会有性能损耗,尽量不要用?
上个月在 @polaris @轩脉刃 的全栈技术群里看到一个小伙伴问 “说 defer 在栈退出时执行,会有性能损耗,尽量不要用,这个怎么解?”. 恰好前段时间写了一篇 <深入理解 Go def ...
- tf.reduce_max的运用
a=np.array([[[[1],[2],[3]],[[4],[25],[6]]],[[[27],[8],[99]],[[10],[11],[12]]],[[[13],[14],[15]],[[16 ...
- 最全的 pip 使用指南,50% 你可能没用过
所有的 Python 开发者都清楚,Python 之所以如此受欢迎,能够在众多高级语言中,脱颖而出,除了语法简单,上手容易之外,更多还要归功于 Python 生态的完备,有数以万计的 Python 爱 ...
- Mybatis中使用association进行关联的几种方式
这里以一对一单向关联为例.对使用或不使用association的配置进行举例. 实体类: @Data @ToString @NoArgsConstructor public class IdCard ...
- Python进阶----数据库引擎(InnoDB),表的创建,mysql的数据类型,mysql表的约束
Python进阶----数据库引擎(InnoDB),表的创建,mysql的数据类型,mysql表的约束 一丶MySQL的存储引擎 什么是存储引擎: MySQL中的数据用各种不同的技术存储在文件( ...