1、HDFS 架构、启动过程
Hadoop Distributed File System
- 易于拓展的分布式文件系统
- 运行在大量普通廉价机器上,提供容错机制
- 为大量用户提供性能不错的文件存取服务
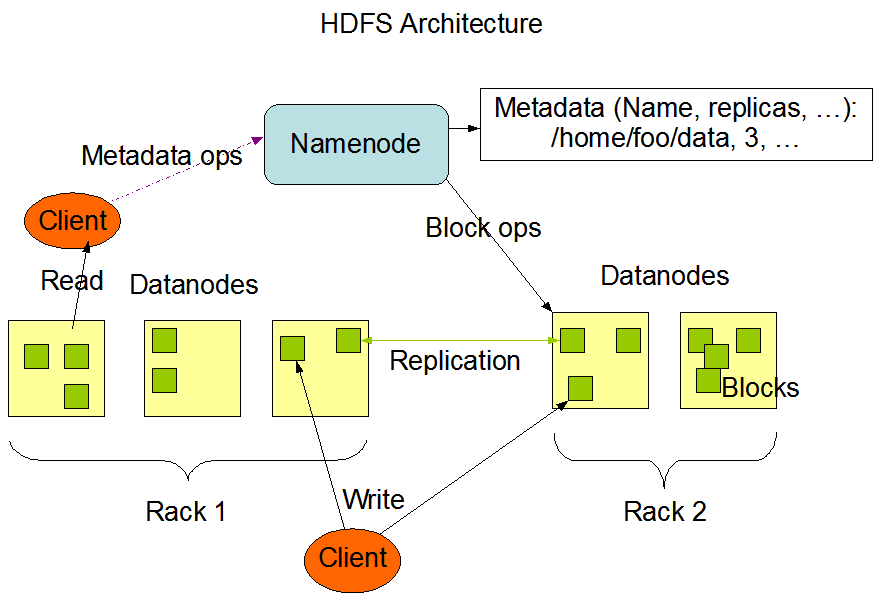
NameNode
- Namenode是一个中心服务器,==单一节点==(简化系统的设计和实现),==负责管理文件系统的名字空间(namespace)以及客户端对文件的访问==。
- 文件操作,==NameNode负责文件元数据的操作,DataNode负责处理文件内容的读写请求,跟文件内容相关的数据流不经过NameNode==,只会询问他跟哪个DataNode联系,否则NameNode会成为系统的瓶颈。
- 副本存放在那些DataNode上是由NameNode控制的,根据全局情况作出块放置决定,==读取文件时NameNode尽量让用户先读取最近的副本==,降低带块消耗和读取时延。
- ==NameNode全权管理数据块的赋值==,它周期性地从集群中的==每个DataNode接收心跳信号和块状态报告(Blockreport)==。接手到心跳信号意味着该DataNode节点工作正常。块状态报告包含了一个该==DataNode上所有数据块==的列表。
DataNode
- 一个==数据块在DataNode以文件存储在磁盘上==,包括两个文件,一个是数据本身,一个是==元数据包括数据块的长度,块数据的校验和,以及时间戳==。
- DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
- 心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令,如复制块数据到另一台机器,或者删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
- 集群运行中可以安全加入和退出一些机器。
文件
- ==文件切分成块==(默认128M),以块为单位,==每个块有多个副本存储在不同的机器上==,副本数可在文件生成时指定(默认3)。
- NameNode是主节点,==存储文件的元数据==如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的快列表以及块所在的DataNode等待。
- DataNode在本地文件==系统存储文件块数据==,以及==块数据的校验和==。
- ==可以创建、删除、移动或重命名文件,当文件创建、写入和关闭之后不能修改文件内容==。
HDFS Architecture
Data Replication
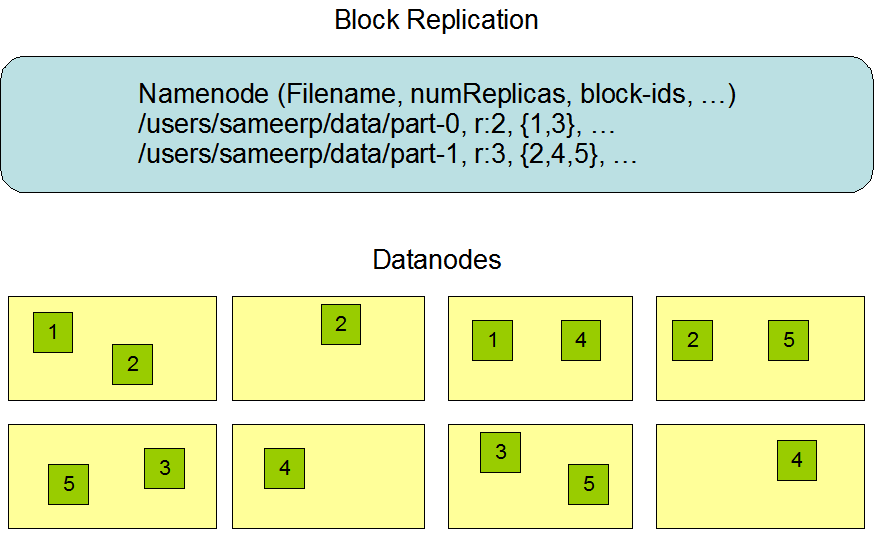
副本放置策略
For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on one node in the local rack, another on a different node in the local rack, and the last on a different node in a different rack. This policy cuts the inter-rack write traffic which generally improves write performance. The chance of rack failure is far less than that of node failure; this policy does not impact data reliability and availability guarantees. However, it does reduce the aggregate network bandwidth used when reading data since a block is placed in only two unique racks rather than three. With this policy, the replicas of a file do not evenly distribute across the racks. One third of replicas are on one node, two thirds of replicas are on one rack, and the other third are evenly distributed across the remaining racks. This policy improves write performance without compromising data reliability or read performance.
数据损坏(corruption)处理
- 当DataNode读取block的时候,它会计算checksum
- 如果计算后的checksum,与block创建时值不一样,说明该block已经损坏。
- Client读取其他DataNode上的block
- NameNode标记该块已经损坏,然后复制block达到预期设置的文件备份数。
- DataNode在其文件创建后三周验证其checksum。
1、HDFS 架构、启动过程的更多相关文章
- HDFS Namenode启动过程
文章作者:luxianghao 文章来源:http://www.cnblogs.com/luxianghao/p/6564032.html 转载请注明,谢谢合作. 免责声明:文章内容仅代表个人观点, ...
- Tomcat架构解析(二)-----Connector、Tomcat启动过程以及Server的创建过程
Connector用于跟客户端建立连接,获取客户端的Socket,交由Container处理.需要解决的问题有监听.协议以及处理器映射等等. 一.Connector设计 Connector要实现的 ...
- HDFS启动过程概述及集群安全模式操作
1.启动过程概述 Namenode启动时,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作.一旦在内存中成功建立文件系统元数据的映像,则创建一个新的fsimage文件 ...
- 浅读tomcat架构设计和tomcat启动过程(1)
一图甚千言,这张图真的是耽搁我太多时间了: 下面的tomcat架构设计代码分析,和这张图息息相关. 使用maven搭建本次的环境,贴出pom.xml完整内容: <?xml version=&qu ...
- 大数据技术hadoop入门理论系列之二—HDFS架构简介
HDFS简单介绍 HDFS全称是Hadoop Distribute File System,是一个能运行在普通商用硬件上的分布式文件系统. 与其他分布式文件系统显著不同的特点是: HDFS是一个高容错 ...
- HDFS 架构简述
HDFS 架构简述 Hadoop分布式文件系统(HDFS)是一个分布式的文件系统,运行在廉价的硬件上.它与现有的分布式文件系统有很多相似之处.然而与其他的分布式文件系统的差异也是显着的.HDFS是高容 ...
- HDFS概述(1)————HDFS架构
概述 Hadoop分布式文件系统(HDFS)是一种分布式文件系统,用于在普通商用硬件上运行.它与现有的分布式文件系统有许多相似之处.然而,与其他分布式文件系统的区别很大.HDFS具有高度的容错能力,旨 ...
- Hadoop学习笔记一(HDFS架构)
介绍 Hadoop分布式文件系统(HDFS)设计的运行环境是商用的硬件系统.他和现存的其他分布式文件系统存在很多相似点.不过HDFS和其他分布式文件系统的区别才是他的最大亮点,HDFS具有高容错的特性 ...
- HDFS架构及原理
原文链接:HDFS架构及原理 引言 进入大数据时代,数据集的大小已经超过一台独立物理计算机的存储能力,我们需要对数据进行分区(partition)并存储到若干台单独的计算机上,也就出现了管理网络中跨多 ...
- 06_Hadoop分布式文件系统HDFS架构讲解
mr 计算框架 假如有三台机器 统领者master 01 02 03 每台机器都有过滤的应用程序 移动数据 01机== 300M >mr 移动计算 java程序传递给各个机器(mr) ...
随机推荐
- netcore 步骤
1.创建工程目录 d:\project 2.进入目录,创建解决方案 dotnet new sln 3.确定开发版本 dotnet --list-sdks //列出sdk版本 dotnet new gl ...
- C++ 工程师养成 每日一题4.5 (迭代器遍历)
首先说明,当每日一题标号不是整数时代表此题是较为简单的,我在这里整理一遍主要是我做错了(没错是我太菜各位大佬无视就好) 题目: 读入一个字符串str,输出字符串str中的连续最长的数字串 此题思路清晰 ...
- C语言中,static关键字作用
static修饰变量 1 在块中使用static修饰变量 它具有静态存储持续时间.块范围和无链接. 即作用域只能在块中,无法被块外的程序调用:变量在程序加载时创建,在程序终止时结束. 它只在编译时初始 ...
- PostgreSQL学习笔记(一)—— macOS下安装
安装命令:brew install postgresql 我的终端是zsh,所以添加环境变量到~/.zshrc vim ~/.zshrc export PATH=$PATH:/usr/local/Ce ...
- 【leetcode-97 动态规划】 交错字符串
(1过,调试很久) 给定三个字符串 s1, s2, s3, 验证 s3 是否是由 s1 和 s2 交错组成的. 示例 1: 输入: s1 = "aabcc", s2 = " ...
- docker下安装mysql数据库
因为用了.net core 所以想学习下使用docker: 项目中刚好要用到mysql数据库,所用用docker来安装一次,我使用的是5.6版本: 1.拉取官方镜像 docker pull mysql ...
- 强大的Grafana k8s 插件
原文参考: https://i4t.com/4152.html 参考:https://blog.csdn.net/mailjoin/article/details/81389700 插件链接:http ...
- python3 语法 数据类型
python3中 有6种标准数据类型 数字,字符串,列表,元祖,集合,字典
- 通过创建一个简单的骰子游戏来探究 Python
在我的这系列的第一篇文章 中, 我已经讲解如何使用 Python 创建一个简单的.基于文本的骰子游戏.这次,我将展示如何使用 Python 模块 Pygame 来创建一个图形化游戏.它将需要几篇文章才 ...
- 1+X证书学习日志——javascript基础
js javascript js的组成: ECMAscript DOM BOM js放置的位置 <script></script> <script src="路 ...