zz姚班天才少年鬲融凭非凸优化研究成果获得斯隆研究奖
姚班天才少年鬲融凭非凸优化研究成果获得斯隆研究奖
近日,美国艾尔弗·斯隆基金会(The Alfred P. Sloan Foundation)公布了2019年斯隆研究奖(Sloan Research Fellowships)获奖名单,华裔学者鬲融获此殊荣。
鬲融 2004 年从河北省保送至清华大学计算机系,是首届清华姚班毕业生,普林斯顿大学计算机科学系博士,曾在微软研究院新英格兰分部做博士后,2015年至今在杜克大学担任助理教授。
斯隆研究奖自1955年设立,每年颁发一次,旨在向物理学、化学和数学领域的这些“早期职业科学家和学者提供支持和认可”,后来陆续增加了神经科学、经济学、计算机科学、以及计算和进化分子生物学。2019届斯隆研究奖获奖者共126名,其中,含鬲融在内共有19位华人学者获奖。
斯隆研究奖历来有“诺奖风向标”的美誉。因为迄今为止,已有47位该奖项获奖人获得了“诺贝尔奖”。另有17位获奖人获得了“数学菲尔兹奖”,69位获奖人获得“美国国家科学奖章”,18位获得“约翰·贝茨·克拉克奖”。
鬲融求学期间有许多突出事迹,可谓是天才少年,在这篇文章中有较为详细的叙述,以及这之后在读博期间获得了 NIPS 2016 的最佳学生论文奖。下面我们着重介绍一下他近期的研究成果。
鬲融的研究领域为理论计算机科学和机器学习。他在个人主页上写道“深度学习等现代机器学习算法尝试从数据中自动学习有用的隐含表示。那么我们要如何公式化数据中的隐含结构,以及如何设计高效的算法找到它们呢?我的研究就以非凸优化和张量分解为工具,通过研究文本、图像和其他形式的数据分析中出现的问题,尝试解答这些疑问。”
鬲融的研究有三个主要课题:表示学习(Representation Learning)、非凸优化(Non-convex Optimization)以及张量分解(Tensor Decompositions)。此次获得斯隆研究奖,正是基于鬲融在非凸优化方面的研究。根据他本人介绍:“现在机器学习大多使用深度学习算法,这些算法需要通过解决一些非凸优化问题来找到最优的神经网络参数。理论上非凸优化在最坏情况下是非常困难的,但是实际上即使是非常简单的算法(比如梯度下降gradient descent)都表现很好。我最近的工作对于一些简单的非凸优化问题给出了一些分析,可以证明所有的局部最优解都是全局最优解。”
他还补充道:“科研中感觉有些问题一开始看来完全没有头绪,但是有几个特别感兴趣的问题我一般会每隔一段时间再看一下。现在理论机器学习方向发展很快,往往过了一段时间就有很多新的技术可以尝试。其实一开始研究非凸优化的问题是为了解决张量分解的问题(这个是我之前做的研究),但是开始做了之后才发现我们用的工具在很多其他问题中也非常有效。”
不仅此次获奖的研究结论“简单的非凸优化中所有的局部最优解都是全局最优解”对机器学习领域的研究人员们来说是一个令人欣慰的结论,鬲融更多关于别的课题的研究论文也发表在了NIPS、ICML、ICLR等顶级人工智能学术会议上。雷锋网 AI 科技评论下面列举一些。
Learning Two-layer Neural Networks with Symmetric Inputs,借助对称输入学习双层神经网络. ICLR 2019. https://arxiv.org/abs/1810.06793
Understanding Composition of Word Embeddings via Tensor Decomposition,通过张量分解理解词嵌入的成分. ICLR 2019. https://openreview.net/forum?id=H1eqjiCctX
Stronger generalization bounds for deep nets via a compression approach,通过压缩方式为深度神经网络赋予更强的泛化边界. ICML 2018. https://arxiv.org/abs/1802.05296
Minimizing Nonconvex Population Risk from Rough Empirical Risk,从粗糙的经验风险中最小化非凸种群风险. NeurIPS 2018. https://arxiv.org/abs/1803.09357
Beyond Log-concavity: Provable Guarantees for Sampling Multi-modal Distributions using Simulated Tempering Langevin Monte Carlo,超越对数凹面:通过仿真时序郎之万蒙特卡洛实现采样多模态分布的可证明保证. NIPS 2017 Bayesian Inference Workshop. NeurIPS 2018. https://arxiv.org/abs/1812.00793
Global Convergence of Policy Gradient Methods for Linearized Control Problems,用于线性化控制问题的策略梯度方法的全局收敛性. ICML 2018. https://arxiv.org/abs/1801.05039
Learning One-hidden-layer Neural Networks with Landscape Design,通过曲面设计学习单层隐层的神经网络. ICLR 2018. https://arxiv.org/abs/1711.00501
Generalization and Equilibrium in Generative Adversarial Nets (GANs),对抗性生成式网络的泛化性和均衡研究. ICML 2017. https://arxiv.org/abs/1703.00573
No Spurious Local Minima in Nonconvex Low Rank Problems: A Unified Geometric Analysis,低阶非凸问题中不存在虚假的局部极小值:一个统一的几何分析. ICML 2017. https://arxiv.org/abs/1704.00708
How to Escape Saddle Points Efficiently,如何高效地离开驻点. ICML 2017. https://arxiv.org/abs/1703.00887
On the Optimization Landscape of Tensor decompositions,关于张量分解的优化图像.NIPS 2016 非凸 workshop 最佳理论研究奖. https://sites.google.com/site/nonconvexnips2016/files/Paper8.pdf
Matrix Completion has No Spurious Local Minimum,矩阵期满中不存在虚假的局部极小值. NIPS 2016 最佳学生论文奖. http://arxiv.org/abs/1605.07272
Provable Algorithms for Inference in Topic Models,话题模型中可证明的推理算法. In ICML 2016. http://arxiv.org/abs/1605.08491
Efficient Algorithms for Large-scale Generalized Eigenvector Computation and Canonical Correlation Analysis,几个高效的大规模泛化特征向量计算和规范关联分析算法. ICML 2016. http://arxiv.org/abs/1604.03930
Rich Component Analysis,富成分分析. In ICML 2016. http://arxiv.org/abs/1507.03867
Intersecting Faces: Non-negative Matrix Factorization With New Guarantees,相交的截面:带有新的保证的非负矩阵乘法. ICML 2015. http://arxiv.org/abs/1507.02189
Un-regularizing: approximate proximal point and faster stochastic algorithms for empirical risk minimization,反规范化:用于经验风险最小化的逼近近似点和更快的随机算法. ICML 2015. http://arxiv.org/abs/1506.07512
此外他还有多篇论文发表在各年的 COLT(Annual Conference on Learning Theory,ACM 主办,计算学习理论顶级会议) 中。
他的个人主页见 https://users.cs.duke.edu/~rongge/。
————
编辑 ∑Pluto
来源:雷锋网
更多精彩:
☞算法立功!清华毕业教授美国被抢车,警察无能为力自己用“贪心算法”找回
☞分享 数学,常识和运气 ——投资大师詹姆斯·西蒙斯2010年在MIT的讲座
算法数学之美微信公众号欢迎赐稿
稿件涉及数学、物理、算法、计算机、编程等相关领域,经采用我们将奉上稿酬。
投稿邮箱:math_alg@163.com
Towards Theoretical Understanding of Deep Learning
Organizers: Amit Daniely (amit.daniely@mail.huji.ac.il), Rong Ge (rongge@cs.duke.edu), Tengyu Ma (tengyuma@cs.stanford.edu), Ohad Shamir (ohad.shamir@weizmann.ac.il)
Description
Deep learning has resulted in breakthroughs in many areas of artificial intelligence including computer vision, speech, natural language processing, reinforcement learning, robotics etc. However, theoretical understanding of deep learning has been scarce.
Why can simple algorithms (such as stochastic gradient descent) find high-quality solutions even though the objective function is non-convex? Why do the learned neural networks generalize to the test data even though the number of parameters is much more than the number of examples? These fundamental problems about the optimization and generalization have attracted a lot of recent attention, but we are still far from satisfying answers.
The new models and formulations in deep learning has also introduced new algorithmic challenges. For example, Generative Adversarial Nets (GANs) are very effective in generating images, but its training procedure is still very unstable. Could we design algorithms with convergence guarantees for GANs?Neural network models are often susceptible to adversarial examples. How can we find models that are robust to adversarial perturbations?
Goal
The workshop will serve as an introduction to recent developments in theoretical understanding of deep neural networks, including techniques, results, and research directions. We hope to bring together researchers in theory community, foster research discussions between theory and practice, and eventually lead to interesting results that could impact deep learning practice.
Schedule
| 08:50-09:30 am | Sanjeev Arora | Understanding the "effective capacity" of deep nets via a compression approach | Slides |
| 09:30-10:10 am | Aleksander Madry | Towards ML You Can Rely On | Slides |
| 10:10-10:25 am | Break | ||
| 10:25-11:15 am | Ohad Shamir | Is Depth Needed for Deep Learning? Circuit Complexity in Neural Networks | Slides |
| 11:15-11:45 am | Tengyu Ma | Algorithmic Regularization in Over-parameterized Matrix Recovery and Neural Networks with Quadratic Activations | Slides |
| Lunch Break | |||
| 1:00-1:50 pm | Nathan Srebo | Generalization and Implicit Regularization in Deep Learning. | |
| 1:50-2:00 pm | Break | ||
| 2:00-2:50 pm | Rong Ge | Do Deep Networks have Bad Local Minima?Brief survey on optimization landscape for neural networks | Slides |
| 2:50-3:00 pm | Break | ||
| 3:00-4:00 pm | Amit Daniely | On PAC learning and deep learning | Slides |
New Challenges in Machine Learning - Robustness and Nonconvexity
Organizers: Ilias Diakonikolas (diakonik@usc.edu), Rong Ge (rongge@cs.duke.edu), Ankur Moitra (moitra@mit.edu)
Machine learning has gone through a major transformation in the last decade. Traditional methods based on convex optimization have been replaced by highly non-convex approaches including deep learning. In the worst-case, the underlying optimization problems are NP-hard. Therefore to understand their success, we need new tools to characterize properties of natural inputs, and design algorithms that work provably in beyond-worst-case settings. In particular, robustness and nonconvexity are two of the major challenges.
Robustness: When we design provable learning algorithms, usually their performance is very brittle to the model assumptions. Can we design provably robust algorithms? How can we find outliers in high dimensions? And are there interesting theoretical questions awaiting in more modern issues in robustness, such as adversarial machine learning and generative adversarial nets?
Nonconvexity: When and why can we solve nonconvex optimization problems in high dimensions? Recent works show that it is possible to escape saddle points and get to a local minimum, and for several problems all local minima are as good as global minimum. How can we extend these results to a richer set of problems? Especially, what is deficient about the models that have been studied so far in explaining what is actually going on in deep nets?
Schedule
The workshop is on Friday June 23rd. The morning session is 9:00 - 12:00; the afternoon session is 1:00 - 4:00.
| Time | Speaker | Title | Slides |
| 9:00 - 9:30 | Ilias Diakonikolas | Efficiency versus Robustness in High-Dimensional Statistics | Slides |
| 9:40 - 10:10 | Po-Ling Loh | Robust high-dimensional linear regression: A statistical perspective | Slides |
| 10:20 - 10: 50 | Chris De Sa | Analyzing Stochastic Gradient Descent for Some Non-Convex Problems | Slides |
| 11:00 - 12:00 | Poster Session | ||
| 12:00 - 1:00 | Lunch Break | ||
| 1:00 - 1:30 | Sanjeev Arora | How to get into ML: A case study. | |
| 1:40 - 2:10 | Adam Klivans | Identifying Barriers for Learning Neural Networks | |
| 2:10 - 2:50 | Break | ||
| 2:50 - 3:20 | John Wright | Nonconvex Recovery of Low-Complexity Models | |
| 3:30 - 4:00 | Aaron Sidford | Accelerated Methods for Non-Convex Optimization | |
Call for Posters
We invite posters to be presented during the workshop. We solicit posters in all areas of machine learning, including unpublished work and recently published work outside FOCS/STOC. To submit a poster, please email stoc2017ml@gmail.comwith a link/attachment to your paper or a 2-page abstract.
Important Dates
Submission Deadline: May 27, 2017
Notification of Acceptance: June 5, 2017
Workshop Date: June 23, 2017
| Home | Research | Publications | Teaching |
 |
|
|
|
||||||
| News | ||||||
|
||||||
|
|
||||||
| My Research | ||||||
| I am broadly interested in theoretical computer science and machine learning. Modern machine learning algorithms such as deep learning try to automatically learn useful hidden representations of the data. How can we formalize hidden structures in the data, and how do we design efficient algorithms to find them? My research aims to answer these questions by studying problems that arise in analyzing text, images and other forms of data, using techniques such as non-convex optimization and tensor decompositions. See the Research page for more details.
My thesis: Provable Algorithms for Machine Learning Problems |
||||||
|
|
||||||
| Selected Publications | ||||||
|
||||||
|
|
||||||
| Workshops STOC2017, STOC2018 | ||||||
|
|
||||||
| Contact | ||||||
|
||||||



【Deep Learning 】深度模型中的优化问题(四)之如何逃离(跳出)鞍点(Saddle Points)
局部最优和鞍点
造成神经网络难以优化的一个重要(乃至主要)原因不是高维优化问题中有很多局部极值,而是存在大量鞍点。
吴恩达视频中讲的,虽然没有理论的证明,局部最小值就是全局最小值,但是很多实际的经验告诉我们,最后,只能收敛到一个最小值,也就是说,很多现实实际问题是只有一个最小值的。但这个最小值通常是鞍点。
认识鞍点的历史
BP算法自八十年代发明以来,一直是神经网络优化的最基本的方法。神经网络普遍都是很难优化的,尤其是当中间隐含层神经元的个数较多或者隐含层层数较多的时候。长期以来,人们普遍认为,这是因为较大的神经网络中包含很多局部极小值(local minima),使得算法容易陷入到其中某些点。这种看法持续二三十年,至少数万篇论文中持有这种说法。举个例子,如著名的Ackley函数 。对于基于梯度的算法,一旦陷入到其中某一个局部极值,就很难跳出来了。
到2014年,一篇论文《Identifying and attacking the saddle point problem in high-dimensional non-convex optimization》(https://arxiv.org/pdf/1406.2572v1.pdf)。
指出高维优化问题中根本没有那么多局部极值。作者依据统计物理,随机矩阵理论和神经网络理论的分析,以及一些经验分析提出高维非凸优化问题之所以困难,是因为存在大量的鞍点(梯度为零并且Hessian矩阵特征值有正有负)而不是局部极值。
这个问题目前仍有讨论,不过大体上人们接受了这种观点,即造成神经网络难以优化的一个重要(乃至主要)原因是存在大量鞍点。造成局部极值这种误解的原因在于,人们把低维的直观认识直接推到高维的情况。在一维情况下,局部极值是仅有的造成优化困难的情形(Hessian矩阵只有一个特征值)。该如何处理这种情况,目前似乎没有特别有效的方法。
理解鞍点,以及如何有效地避开它们
大家都知道局部最小值是我们的克星,所以一个重要的问题就是如何避免局部最小值。但问题并不明显,有很多机器学习的问题没有局部最小值。即使你有局部最小值,梯度下降似乎可以轻松回避它们。神经网络如果足够大的话就会有足够的冗余,要做到这一点并不难。达到零就是全局最优解。
如果一个回路的局部最大值不是问题,它的鞍点是剩下需要解决的。
鞍点在这些体系结构中大量存在,不论是在简单的模型还是在神经网络中。它们会导致学习曲线变平。你会经常看到一个学习曲线下降很快,之后很久都是平的。这就是靠近鞍点的表现。最终你会逃离鞍点。
继续下去,你可能会碰到另一个鞍点。你会看到一个学习曲线,它这样上升和下降。某种意义上,这不是问题,如果你最终得到正确答案。但是你可能会碰到一个鞍点并在那里停滞很长一段时间,时间过久,以至于你都不知道在某个地方能找到更好的答案。特别是如果你没有那么多时间来运行你的算法。所以你可以在多维度中理解这个。
让我给你们看一张鞍点的图片。在左边我们有一个“严格”的鞍点。有一个负曲率的方向,这个负曲率是严格小于零的。在右边,它是个非严格鞍点,但第二个特征值严格为零。
如何逃离鞍点?
如果你沿着中间部分往下走,你最终会摆脱它,但这可能需要很长时间。这只是两个维度上,但如果你有上十万甚至上百万维度呢?就像现在一般的研究中一样。在这种情况下,可能只有一条出路,其他的方向都不行,所以要找到逃逸的方向可能要花很长时间。当维度越来越大的时候,就有问题了。基于梯度下降的算法可能会有麻烦。
只用一阶导数是难以区分最优点和鞍点的。但如果你有一个海森矩阵,这个问题将会消失,因为你会知道所有的方向,但你必须计算一个海森矩阵的特征向量。这两种情况都不好,因为它太复杂了也太慢。所以,梯度方法是个问题。
我们想一下,最优点和鞍点的区别不就在于其在各个维度是否都是最低点嘛~只要某个一阶导数为0的点在某个维度上是最高点而不是最低点,那它就是鞍点。而区分最高点和最低点当然就是用二阶导数(斜率从负变正的过程当然就是“下凸”,即斜率的导数大于0,即二阶导数大于0。反之则为“上凹”,二阶导数小于0)。也就是说,若某个一阶导数为0的点在至少一个方向上的二阶导数小于0,那它就是鞍点啦。
那么二阶导数大于0和小于0的概率各是多少呢?由于我们并没有先验知识,因此按照最大熵原理,我们认为二阶导数大于和小于0的概率均为0.5!
那么对于一个有n个参数的机器学习/深度学习模型,“loss曲面”即位于n+1维空间(loss值为纵轴,n个参数为n个横轴)。在这个空间里,如果我们通过梯度下降法一路下滑终于滑到了一个各方向导数均为0的点,那么它为局部最优点的概率即0.5^ n,为鞍点的概率为1-0.5^n,显然,当模型参数稍微一多,即n稍微一大,就会发现这个点为鞍点的概率会远大于局部最优点!
实际操作中避开鞍点
使用的mini-batch梯度下降法本身就是有噪声的梯度估计,哪怕我们位于梯度为0的点,也经常在某个mini-batch下的估计把它估计偏了,导致往前或者往后挪了一步摔下马鞍,也就是mini-batch的梯度下降法使得模型很容易逃离特征空间中的鞍点。
更多的,我们可以从以下方面考虑:
1)如何去设计一个尽量没有“平坦区”等危险地形的loss空间,即着手于loss函数的设计以及深度学习模型的设计;
2)尽量让模型的初始化点远离空间中的危险地带,让最优化游戏开始于简单模式,即着手于模型参数的初始化策略;
3)让最优化过程更智能一点,该加速冲时加速冲,该大胆跳跃时就大胆跳,该慢慢踱步时慢慢走,对危险地形有一定的判断力,如梯度截断策略;
4)开外挂,本来下一步要走向死亡的,结果被外挂给拽回了安全区,如batch normalization策略等。
我们知道在,优化问题中,深度学习的优化问题中,经常存在鞍点,就是这一点的导数为0,从某些维度看是极小值,从另一些维度看是极大值,比如下图所示:

深度学习的寻优过程中,鞍点所造成的困难,远比局部最小值大的多,因为:
1)在高维参数空间,鞍点存在较多。
2)大量工作表面局部最优解,对于模型而言已经足够好。
此外,正是因为深度学习中鞍点的大量存在,传统的牛顿法不适合来寻优。
因为牛顿法是通过直接寻找梯度为0的点,来寻优的,那么极有可能陷入鞍点。
(ps: 也正因为如此,牛顿法在Hessian为正定的时候,比梯度下降速度快,因为牛顿法直接找梯度为0的点,而梯度下降则是一次一次的寻找当前点的最优梯度)
那么如何逃离,跳出鞍点呢?
1)利用Hessian矩阵,判断是否为鞍点。因为Hessian在鞍点具有正负特征值,而在局部最小值点正定。
2)随机梯度,相当于给正确的梯度加了一点noise,一定程度上避免了鞍点(但是只是一定程度),达到类似于如下公式的效果 :
3)随机初始化起点,也有助于逃离鞍点,原因见here
4)增加偶尔的随机扰动,详见here
上一张各算法逃离鞍点的效果图,有一个直观的感觉:

最后,推荐大家看这两篇博客,帮助大家理解:
参考:
最优化问题之如何逃离(跳出)鞍点(Saddle Points)
你的模型真的陷入局部最优点了吗训练神经网络时如何确定batch的大小?
算法优化之道:避开鞍点
原标题:算法优化之道:避开鞍点
凸函数比较简单——它们通常只有一个局部最小值。非凸函数则更加复杂。在这篇文章中,我们将讨论不同类型的临界点( critical points) ,当你在寻找凸路径( convex path )的时候可能会遇到。特别是,基于梯度下降的简单启发式学习方法,在很多情形下会致使你在多项式时间内陷入局部最小值( local minimum ) 。
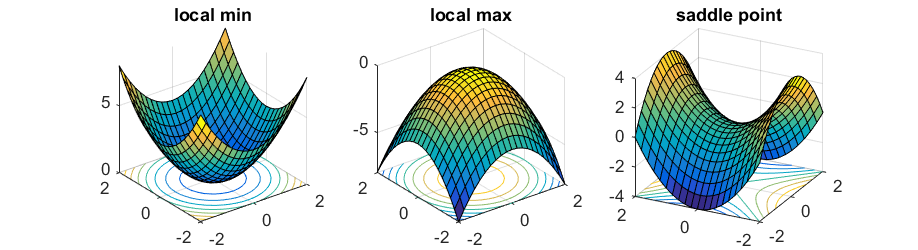
临界点类型
为了最小化函数f:Rn→R,最流行的方法就是往负梯度方向前进∇f(x)(为了简便起见,我们假定谈及的所有函数都是可微的),即:
y=x−η∇f(x),
其中η表示步长。这就是梯度下降算法(gradient descentalgorithm)。
每当梯度∇f(x)不等于零的时候,只要我们选择一个足够小的步长η,算法就可以保证目标函数向局部最优解前进。当梯度∇f(x)等零向量时,该点称为临界点( critical point),此时梯度下降算法就会陷入局部最优解。对于(强)凸函数,它只有一个临界点(critical point),也是全局最小值点(global minimum)。
然而,对于非凸函数,仅仅考虑梯度等于零向量远远不够。来看一个简单的实例:
y=x12−x22.
当x=(0,0)时,梯度为零向量,很明显此点并不是局部最小值点,因为当x=(0,ϵ)时函数值更小。在这种情况下,(0,0)点叫作该函数的鞍点(saddle point)。
为了区分这种情况,我们需要考虑二阶导数∇2f(x)——一个n×n的矩阵(通常称作Hessian矩阵),第i,j项等于
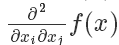
。当Hessian矩阵正定时(即对任意的u≠0,有u⊤∇2f(x)u > 0恒成立),对于任何方向向量u,通过二阶泰勒展开式
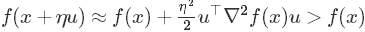
,可知x必定是一个局部最小值点。同样,当Hessian矩阵负定时,此点是一个局部最大值点;当Hessian矩阵同时具有正负特征值时,此点便是鞍点。
对于许多问题,包括 learning deep nets,几乎所有的局部最优解都有与全局最优解(global optimum)非常相似的函数值,因此能够找到一个局部最小值就足够好了。然而,寻找一个局部最小值也属于NP-hard问题(参见 Anandkumar,GE 2006中的讨论一节)。实践当中,许多流行的优化技术都是基于一阶导的优化算法:它们只观察梯度信息,并没有明确计算Hessian矩阵。这样的算法可能会陷入鞍点之中。
在文章的剩下部分,我们首先会介绍,收敛于鞍点的可能性是很大的,因为大多数自然目标函数都有指数级的鞍点。然后,我们会讨论如何对算法进行优化,让它能够尝试去避开鞍点。
对称与鞍点
许多学习问题都可以被抽象为寻找k个不同的分量(比如特征,中心…)。例如,在 聚类问题中,有n个点,我们想要寻找k个簇,使得各个点到离它们最近的簇的距离之和最小。又如在一个两层的 神经网络中,我们试图在中间层寻找一个含有k个不同神经元的网络。在我 先前的文章中谈到过张量分解(tensor decomposition),其本质上也是寻找k个不同的秩为1的分量。
解决此类问题的一种流行方法是设计一个目标函数:设x1,x2,…,xK∈Rn表示所求的中心(centers),让目标函数f(x1,…,x)来衡量函数解的可行性。当向量x1,x2,…,xK是我们需要的k的分量时,此函数值会达到最小。
这种问题在本质上是非凸的自然原因是转置对称性(permutation symmetry)。例如,如果我们将第一个和第二个分量的顺序交换,目标函数相当于:f(x1,x2,…,xk)= f(x1,x2,…,xk)。
然而,如果我们取平均值,我们需要求解的是
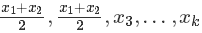
,两者是不等价的!如果原来的解是最优解,这种均值情况很可能不是最优。因此,这种目标函数不是凸函数,因为对于凸函数而言,最优解的均值仍然是最优。
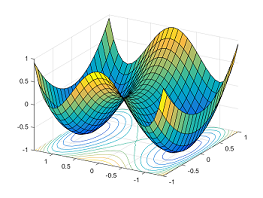
所有相似解的排列有指数级的全局最优解。鞍点自然会在连接这些孤立的局部最小值点上出现。下面的图展示了函数y = x14−2x12+ X22:在两个对称的局部最小点(−1,0)和(1,0)之间,点(0,0)是一个鞍点。
避开鞍点
为了优化这些存在许多鞍点的非凸函数,优化算法在鞍点处(或者附近)也需要向最优解前进。最简单的方法就是使用二阶泰勒展开式:
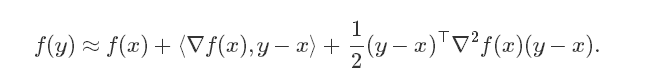
如果∇f(x)的梯度为零向量,我们仍然希望能够找到一个向量u,使得u⊤∇2f(x)u<0。在这种方式下,如果我们令y = x +ηu,函数值f(Y)就会更小。许多优化算法,诸如 trust region algorithms和 cubic regularization使用的就是这种思想,它们可以在多项式时间内避开鞍点。
严格鞍函数
通常寻找局部最小值也属于NP-hard问题,许多算法都可能陷入鞍点之中。那么避开一个鞍点需要多少步呢?这与鞍点的表现良好性密切相关。直观地说,如果存在一个方向u,使得二阶导uT∇2f(x)u明显比0小,则此鞍点x表现良好(well-behaved)——从几何上来讲,它表示存在一个陡坡方向会使函数值减小。为了量化它,在我与Furong Huang, Chi Jin and Yang Yuan合作的一篇论文中介绍了严鞍函数的概念(在 Sun et al. 2015一文中称作“ridable”函数)
对于所有的x,如果同时满足下列条件之一,则函数f(x)是严格鞍函数:
1. 梯度∇f(x)很大。
2. Hessian矩阵∇2f(x)具有负的特征值。
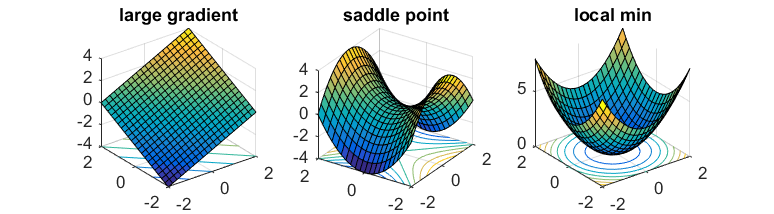
3. 点x位于局部极小值附近。从本质上讲,每个点x的局部区域看起来会与下图之一类似:
对于这种函数, trust region算法和 cubic regularization都可以有效地找到一个局部最小值点。
定理(非正式):至少存在一种多项式时间算法,它可以找到严格鞍函数的局部最小值点。什么函数是严格鞍? Ge et al. 2015表明张量分解( tensor decomposition)问题属于严格鞍。 Sun et al. 2015观察到诸如完整的 dictionary learning, phase retrieval问题也是严格鞍。
一阶方法避开鞍点
Trust region算法非常强大。然而它们需要计算目标函数的二阶导数,这在实践中往往过于费时。如果算法只计算函数梯度,是否仍有可能避开鞍点?
这似乎很困难,因为在鞍点处梯度为零向量,并且没有给我们提供任何信息。然而,关键在于鞍点本身是非常不稳定的(unstable):如果我们把一个球放在鞍点处,然后轻微地抖动,球就可能会掉下去!当然,我们需要让这种直觉在更高维空间形式化,因为简单地寻找下跌方向,需要计算Hessian矩阵的最小特征向量。
为了形式化这种直觉,我们将尝试使用一个带有噪声的梯度下降法(noisy gradient descent)
y=x−η∇f(x)+ϵ.这里ϵ是均值为0的噪声向量。这种额外的噪声会提供初步的推动,使得球会顺着斜坡滚落。
事实上,计算噪声梯度通常比计算真正的梯度更加省时——这也是随机梯度法( stochastic gradient)的核心思想,大量的工作表明,噪声并不会干扰凸优化的收敛。对于非凸优化,人们直观地认为,固有的噪声有助于收敛,因为它有助于当前点远离鞍点(saddle points)。这并不是bug,而是一大特色!
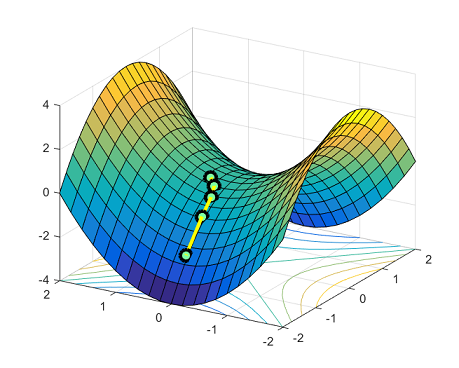
在此之前,没有良好的迭代上限(upper bound)能够确保避开鞍点并到达局部最小值点(local minimum)。在 Ge et al. 2015,我们展示了:
定理(非正式):噪声梯度下降法能够在多项式时间内找到严格鞍函数的局部最小值点。
多项式高度依赖于维度N和Hessian矩阵的最小特征值,因此不是很实用。对于严格鞍问题,找到最佳收敛率仍是一个悬而未决的问题。
最近 Lee et al.的论文表明如果初始点是随机选择的,那么即使没有添加噪声,梯度下降也不会收敛到任何严格鞍点。然而他们的结果依赖于动态系统理论(dynamical systems theory)的 稳定流形定理(Stable Manifold Theorem),其本身并不提供任何步数的上界。
复杂鞍点
通过上文的介绍,我们知道算法可以处理(简单)的鞍点。然而,非凸问题的外形更加复杂,含有退化鞍点(degeneratesaddle points)——Hessian矩阵是半正定的,有0特征值。这样的退化结构往往展示了一个更为复杂的鞍点(如 monkey saddle(猴鞍),图(a))或一系列连接的鞍点(图(b)(c))。在 Anandkumar, Ge 2016我们给出了一种算法,可以处理这些退化的鞍点。
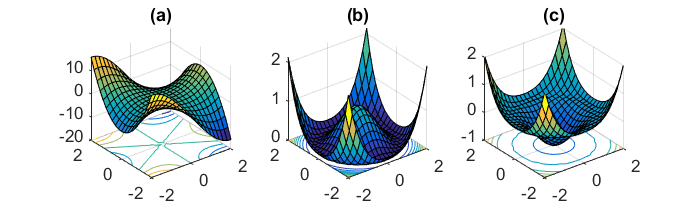
非凸函数的轮廓更加复杂,而且还存在许多公认的问题。还有什么函数是严格鞍?当存在退化鞍点,或者有伪局部最小值点时,我们又该如何使优化算法工作呢?我们希望有更多的研究者对这类问题感兴趣!
原文: Escaping from Saddle Points
译者:刘帝伟 审校:刘翔宇
责编:周建丁(投稿请联系zhoujd@csdn.net)
链接:深度学习为何起作用——关键解析和鞍点
本文为CSDN编译整理,未经允许不得转载,如需转载请联系market#csdn.net(#换成@)返回搜狐,查看更多
责任编辑:
训练神经网络时如何确定batch的大小?
当我们要训练一个已经写好的神经网络时,我们就要直面诸多的超参数啦。这些超参数一旦选不好,那么很有可能让神经网络跑的还不如感知机。因此在面对神经网络这种容量很大的model前,是很有必要深刻的理解一下各个超参数的意义及其对model的影响的。
贴心的小夕还是先带领大家简单回顾一下神经网络的一次迭代过程:
即,首先选择n个样本组成一个batch,然后将batch丢进神经网络,得到输出结果。再将输出结果与样本label丢给loss函数算出本轮的loss,而后就可以愉快的跑BP算法了(从后往前逐层计算参数之于loss的导数)。最后将每个参数的导数配合步长参数来进行参数更新。这就是训练过程的一次迭代。
由此,最直观的超参数就是batch的大小——我们可以一次性将整个数据集喂给神经网络,让神经网络利用全部样本来计算迭代时的梯度(即传统的梯度下降法),也可以一次只喂一个样本(即严格意义上的随机梯度下降法,也称在线梯度下降法,简称SGD),也可以取个折中的方案,即每次喂一部分样本让其完成本轮迭代(即batch梯度下降法)。
数学基础不太好的初学者可能在这里犯迷糊——一次性喂500个样本并迭代一次,跟一次喂1个样本迭代500次相比,有区别吗?
其实这两个做法就相当于:
第一种:
total = 旧参下计算更新值1+旧参下计算更新值2+...+旧参下计算更新值500 ;
新参数 = 旧参数 + total;
第二种:
新参数1 = 旧参数 + 旧参数下计算更新值1;
新参数2 = 新参数1 + 新参数1下计算更新值1;
新参数3 = 新参数2 + 新参数2下计算更新值1;
...
新参数500 =新参数500 + 新参数500下计算更新值1;
也就是说,第一种是将参数一次性更新500个样本的量,第二种是迭代的更新500次参数。当然是不一样的啦。
那么问题来了,哪个更好呢?
我们首先分析最简单的影响,哪种做法收敛更快呢?
我们假设每个样本相对于大自然真实分布的标准差为σ,那么根据概率统计的知识,很容易推出n个样本的标准差为(有疑问的同学快翻开概率统计的课本看一下推导过程)。
从这里可以看出,我们使用样本来估计梯度的时候,1个样本带来σ的标准差,但是使用n个样本区估计梯度并不能让标准差线性降低(也就是并不能让误差降低为原来的1/n,即无法达到σ/n),而n个样本的计算量却是线性的(每个样本都要平等的跑一遍前向算法)。
由此看出,显然在同等的计算量之下(一定的时间内),使用整个样本集的收敛速度要远慢于使用少量样本的情况。换句话说,要想收敛到同一个最优点,使用整个样本集时,虽然迭代次数少,但是每次迭代的时间长,耗费的总时间是大于使用少量样本多次迭代的情况的。
那么是不是样本越少,收敛越快呢?
理论上确实是这样的,使用单个单核cpu的情况下也确实是这样的。但是我们要与工程实际相结合呀~实际上,工程上在使用GPU训练时,跑一个样本花的时间与跑几十个样本甚至几百个样本的时间是一样的!当然得益于GPU里面超多的核,超强的并行计算能力啦。
因此,在工程实际中,从收敛速度的角度来说,小批量的样本集是最优的,也就是我们所说的mini-batch。这时的batch size往往从几十到几百不等,但一般不会超过几千(你有土豪显卡的话,当我没说)。
那么,如果我真有一个怪兽级显卡,使得一次计算10000个样本跟计算1个样本的时间相同的话,是不是设置10000就一定是最好的呢?虽然从收敛速度上来说是的,但!是!
我们知道,神经网络是个复杂的model,它的损失函数也不是省油的灯,在实际问题中,神经网络的loss曲面(以model参数为自变量,以loss值为因变量画出来的曲面)往往是非凸的,这意味着很可能有多个局部最优点,而且很可能有鞍点!
插播一下,鞍点就是loss曲面中像马鞍一样形状的地方的中心点,如下图:
(图片来自《Deep Learning》)
想象一下,在鞍点处,横着看的话,鞍点就是个极小值点,但是竖着看的话,鞍点就是极大值点(线性代数和最优化算法过关的同学应该能反应过来,鞍点处的Hessian矩阵的特征值有正有负。不理解也没关系,小夕过几天就开始写最优化的文章啦~),因此鞍点容易给优化算法一个“我已经收敛了”的假象,殊不知其旁边有一个可以跳下去的万丈深渊。。。(可怕)
回到主线上来,小夕在《机器学习入门指导(4)》中提到过,传统的最优化算法是无法自动的避开局部最优点的,对于鞍点也是理论上很头疼的东西。但是实际上,工程中却不怎么容易陷入很差劲的局部最优点或者鞍点,这是为什么呢?
暂且不说一些很高深的理论如“神经网络的loss曲面中的局部最优点与全局最优点差不太多”,我们就从最简单的角度想~
想一想,样本量少的时候会带来很大的方差,而这个大方差恰好会导致我们在梯度下降到很差的局部最优点(只是微微凸下去的最优点)和鞍点的时候不稳定,一不小心就因为一个大噪声的到来导致炸出了局部最优点,或者炸下了马(此处请保持纯洁的心态!),从而有机会去寻找更优的最优点。
因此,与之相反的,当样本量很多时,方差很小(咦?最开始的时候好像在说标准差来着,反正方差与标准差就差个根号,没影响的哈~),对梯度的估计要准确和稳定的多,因此反而在差劲的局部最优点和鞍点时反而容易自信的呆着不走了,从而导致神经网络收敛到很差的点上,跟出了bug一样的差劲。
小总结一下,batch的size设置的不能太大也不能太小,因此实际工程中最常用的就是mini-batch,一般size设置为几十或者几百。但是!
好像这篇文章的转折有点多了诶( ̄∇ ̄)
细心的读者可能注意到了,这之前我们的讨论是基于梯度下降的,而且默认是一阶的(即没有利用二阶导数信息,仅仅使用一阶导数去优化)。因此对于SGD(随机梯度下降)及其改良的一阶优化算法如Adagrad、Adam等是没问题的,但是对于强大的二阶优化算法如共轭梯度法、L-BFGS来说,如果估计不好一阶导数,那么对二阶导数的估计会有更大的误差,这对于这些靠二阶导数吃饭的算法来说是致命的。
因此,对于二阶优化算法,减小batch换来的收敛速度提升远不如引入大量噪声导致的性能下降,因此在使用二阶优化算法时,往往要采用大batch哦。此时往往batch设置成几千甚至一两万才能发挥出最佳性能(比如小夕曾经试验过,做信息抽取中的关系分类分类时,batch设置的2048配合L-BFGS取得了比SGD好得多的效果,无论是收敛速度还是最终的准确率)。
另外,听说GPU对2的幂次的batch可以发挥更佳的性能,因此设置成16、32、64、128...时往往要比设置为整10、整100的倍数时表现更优(不过小夕没有验证过,有兴趣的同学可以试验一下~
你的模型真的陷入局部最优点了吗?
小夕曾经收到过一个提问:“小夕,我的模型总是在前几次迭代后很快收敛了,陷入到了一个局部最优点,怎么也跳不出来,怎么办?”
本文不是单纯对这个问题的回答,不是罗列工程tricks,而是希望从理论层面上对产生类似疑问的人有所启发。
真的结束于最优点吗?
我们知道,在局部最优点附近,各个维度的导数都接近0,而我们训练模型最常用的梯度下降法又是基于导数与步长的乘积去更新模型参数的,因此一旦陷入了局部最优点,就像掉进了一口井,你是无法直着跳出去的,你只有连续不间断的依托四周的井壁努力向上爬才有可能爬出去。更何况梯度下降法的每一步对梯度正确的估计都在试图让你坠入井底,因此势必要对梯度“估计错很多次”才可能侥幸逃出去。那么从数学上看,什么才是局部最优点呢?
这个问题看似很白痴,很多人会说“局部最优点不就是在loss曲面上某个一阶导数为0的点嘛”。这就不准确啦,比如下面这个马鞍形状的中间的那个点:
(图片来自《deep learning》)
显然这个点也是(一阶)导数为0,但是肯定不是最优点。事实上,这个点就是我们常说的鞍点。
显然,只用一阶导数是难以区分最优点和鞍点的。
我们想一下,最优点和鞍点的区别不就在于其在各个维度是否都是最低点嘛~只要某个一阶导数为0的点在某个维度上是最高点而不是最低点,那它就是鞍点。而区分最高点和最低点当然就是用二阶导数(斜率从负变正的过程当然就是“下凸”,即斜率的导数大于0,即二阶导数大于0。反之则为“上凹”,二阶导数小于0)。也就是说,若某个一阶导数为0的点在至少一个方向上的二阶导数小于0,那它就是鞍点啦。
那么二阶导数大于0和小于0的概率各是多少呢?由于我们并没有先验知识,因此按照最大熵原理,我们认为二阶导数大于和小于0的概率均为0.5!
那么对于一个有n个参数的机器学习/深度学习模型,“loss曲面”即位于n+1维空间(loss值为纵轴,n个参数为n个横轴)。在这个空间里,如果我们通过梯度下降法一路下滑终于滑到了一个各方向导数均为0的点,那么它为局部最优点的概率即,为鞍点的概率为
,显然,当模型参数稍微一多,即n稍微一大,就会发现这个点为鞍点的概率会远大于局部最优点!
好吧我再啰嗦的举个栗子,已经反应过来的同学可以跳过这个栗子:
假设我们的模型有100个参数(实际深度学习模型中一般会远大于100),那么某一阶导数为0的点为局部最优点的概率为约为,而为鞍点的概率则为
。就算我们的模型在训练时使用了特别厉害的“超级梯度下降法”,它可以每走一步都恰好踩在一个一阶导数为0的点上,那么从数学期望上来看,我们需要走
步才行。而实际的projects中,哪怕数据集规模为千万级,我们分了100万个batches,然后要迭代100次,那也仅仅是走了
步,你真的觉得运气可以辣么好的走到局部最优点上去吗?所以实际中,当我们的深度学习模型收敛时,几乎没有必要认为它收敛到了一个局部最优点,这完全等同于杞人忧天。
也就是说,如果最后模型确实在梯度下降法的指引下收敛到了一个导数为0的点,那这个点几乎可以肯定就是一个鞍点。
如果我们的模型真的收敛到鞍点上了,会很可怕吗?
这就又回到了文章开头的那副马鞍状的图。
显然,站在马鞍中央的时候,虽然很难翻过两边的山坡,但是往前或者往后随便走一步就能摔下马鞍!而在文章《batch size》中小夕讲过,我们默认使用的mini-batch梯度下降法本身就是有噪声的梯度估计,哪怕我们位于梯度为0的点,也经常在某个mini-batch下的估计把它估计偏了,导致往前或者往后挪了一步摔下马鞍,也就是mini-batch的梯度下降法使得模型很容易逃离特征空间中的鞍点。
那么问题来了,既然局部最优点很难踩到,鞍点也很容易逃离出去,那么为什么我们的模型看起来是收敛了呢?
初学者可能会说 “诶诶,会不会是学习率太大了,导致在“鞍点”附近震荡?” 首先,鞍点不像最优点那样容易震荡,而且哪怕你不断的减小学习率继续让模型收敛,你这时计算output层或者后几层的梯度向量的长度时会发现它依然离0很遥远!(这句话是有实验支撑的,不过那篇论文我找不到惹,也忘了名字了。热心的观众帮忙补充一下哦)
难道,踩到的鞍点太多,最后恰好收敛到一个跳不下去的鞍点身上了?
虽然高维空间中的鞍点数量远远大于最优点,但是鞍点的数量在整个空间中又是微不足道的:按前面的假设,假设在某个维度上随机一跳有10%的概率踩到导数为0的点,那么我们在101维的空间中的一步恰好踩到这个点上的概率为,也就是说在101维空间里随机乱跳的时候,有
的可能性踩到鞍点身上。因此,即使有难以逃离的鞍点,那么被我们正好踩到的概率也是非常小的。
所以更令人信服的是,在高维空间里(深度学习问题上)真正可怕的不是局部最优也不是鞍点问题,而是一些特殊地形。比如大面积的平坦区域:
(图片来自《deep learning》)
在平坦区域,虽然导数不为0但是却不大。虽然是在不断下降但是路程却非常长。对于优化算法来说,它需要走很多很多步才有可能走过这一片平坦区域。甚至在这段地形的二阶导数过于特殊的情况下,一阶优化算法走无穷多步也走不出去(设想一下,如果终点在一米外,但是你第一次走0.5米,后续每一步都是前一步的一半长度,那么你永远也走不到面前的一米终点处)。
所以相比于栽到最优点和鞍点上,优化算法更有可能载到这种类似平坦区的地形中(如果这个平坦区又是“高原地带”,即loss值很高的地带,那么恭喜你悲剧了)。更糟糕的是,由于高维地形难以可视化,还有很多更复杂的未知地形会导致假收敛,一旦陷入到这些危险地形中,几乎是无解的。
所以说,在深度学习中,与其担忧模型陷入局部最优点怎么跳出来,更不如去好好考虑:
如何去设计一个尽量没有“平坦区”等危险地形的loss空间,即着手于loss函数的设计以及深度学习模型的设计;
尽量让模型的初始化点远离空间中的危险地带,让最优化游戏开始于简单模式,即着手于模型参数的初始化策略;
让最优化过程更智能一点,该加速冲时加速冲,该大胆跳跃时就大胆跳,该慢慢踱步时慢慢走,对危险地形有一定的判断力,如梯度截断策略;
开外挂,本来下一步要走向死亡的,结果被外挂给拽回了安全区,如batch normalization策略等。
算法优化之道:避开鞍点
凸函数比较简单——它们通常只有一个局部最小值。非凸函数则更加复杂。在这篇文章中,我们将讨论不同类型的临界点( critical points) ,当你在寻找凸路径( convex path )的时候可能会遇到。特别是,基于梯度下降的简单启发式学习方法,在很多情形下会致使你在多项式时间内陷入局部最小值( local minimum ) 。
临界点类型

为了最小化函数f:Rn→R,最流行的方法就是往负梯度方向前进∇f(x)(为了简便起见,我们假定谈及的所有函数都是可微的),即:
y=x−η∇f(x),
其中η表示步长。这就是梯度下降算法(gradient descentalgorithm)。
每当梯度∇f(x)不等于零的时候,只要我们选择一个足够小的步长η,算法就可以保证目标函数向局部最优解前进。当梯度∇f(x)等零向量时,该点称为临界点(critical point),此时梯度下降算法就会陷入局部最优解。对于(强)凸函数,它只有一个临界点(critical point),也是全局最小值点(global minimum)。
然而,对于非凸函数,仅仅考虑梯度等于零向量远远不够。来看一个简单的实例:
y=x12−x22.
当x=(0,0)时,梯度为零向量,很明显此点并不是局部最小值点,因为当x=(0,ϵ)时函数值更小。在这种情况下,(0,0)点叫作该函数的鞍点(saddle point)。
为了区分这种情况,我们需要考虑二阶导数∇2f(x)——一个n×n的矩阵(通常称作Hessian矩阵),第i,j项等于

。当Hessian矩阵正定时(即对任意的u≠0,有u⊤∇2f(x)u > 0恒成立),对于任何方向向量u,通过二阶泰勒展开式

,可知x必定是一个局部最小值点。同样,当Hessian矩阵负定时,此点是一个局部最大值点;当Hessian矩阵同时具有正负特征值时,此点便是鞍点。
对于许多问题,包括 learning deep nets,几乎所有的局部最优解都有与全局最优解(global optimum)非常相似的函数值,因此能够找到一个局部最小值就足够好了。然而,寻找一个局部最小值也属于NP-hard问题(参见 Anandkumar,GE 2006中的讨论一节)。实践当中,许多流行的优化技术都是基于一阶导的优化算法:它们只观察梯度信息,并没有明确计算Hessian矩阵。这样的算法可能会陷入鞍点之中。
在文章的剩下部分,我们首先会介绍,收敛于鞍点的可能性是很大的,因为大多数自然目标函数都有指数级的鞍点。然后,我们会讨论如何对算法进行优化,让它能够尝试去避开鞍点。
对称与鞍点
许多学习问题都可以被抽象为寻找k个不同的分量(比如特征,中心…)。例如,在 聚类问题中,有n个点,我们想要寻找k个簇,使得各个点到离它们最近的簇的距离之和最小。又如在一个两层的 神经网络中,我们试图在中间层寻找一个含有k个不同神经元的网络。在我 先前的文章中谈到过张量分解(tensor decomposition),其本质上也是寻找k个不同的秩为1的分量。
解决此类问题的一种流行方法是设计一个目标函数:设x1,x2,…,xK∈Rn表示所求的中心(centers),让目标函数f(x1,…,x)来衡量函数解的可行性。当向量x1,x2,…,xK是我们需要的k的分量时,此函数值会达到最小。
这种问题在本质上是非凸的自然原因是转置对称性(permutation symmetry)。例如,如果我们将第一个和第二个分量的顺序交换,目标函数相当于:f(x1,x2,…,xk)= f(x1,x2,…,xk)。
然而,如果我们取平均值,我们需要求解的是

,两者是不等价的!如果原来的解是最优解,这种均值情况很可能不是最优。因此,这种目标函数不是凸函数,因为对于凸函数而言,最优解的均值仍然是最优。

所有相似解的排列有指数级的全局最优解。鞍点自然会在连接这些孤立的局部最小值点上出现。下面的图展示了函数y = x14−2x12 + X22:在两个对称的局部最小点(−1,0)和(1,0)之间,点(0,0)是一个鞍点。

避开鞍点
为了优化这些存在许多鞍点的非凸函数,优化算法在鞍点处(或者附近)也需要向最优解前进。最简单的方法就是使用二阶泰勒展开式:

如果∇f(x)的梯度为零向量,我们仍然希望能够找到一个向量u,使得u⊤∇2f(x)u<0。在这种方式下,如果我们令y = x +ηu,函数值f(Y)就会更小。许多优化算法,诸如 trust region algorithms和 cubic regularization使用的就是这种思想,它们可以在多项式时间内避开鞍点。
严格鞍函数
通常寻找局部最小值也属于NP-hard问题,许多算法都可能陷入鞍点之中。那么避开一个鞍点需要多少步呢?这与鞍点的表现良好性密切相关。直观地说,如果存在一个方向u,使得二阶导uT∇2f(x)u明显比0小,则此鞍点x表现良好(well-behaved)——从几何上来讲,它表示存在一个陡坡方向会使函数值减小。为了量化它,在我 与Furong Huang, Chi Jin and Yang Yuan合作的一篇论文中介绍了严鞍函数的概念(在 Sun et al. 2015一文中称作“ridable”函数)
对于所有的x,如果同时满足下列条件之一,则函数f(x)是严格鞍函数: 1. 梯度∇f(x)很大。 2. Hessian矩阵∇2f(x)具有负的特征值。 3. 点x位于局部极小值附近。
从本质上讲,每个点x的局部区域看起来会与下图之一类似:

对于这种函数, trust region算法和 cubic regularization都可以有效地找到一个局部最小值点。
定理(非正式):至少存在一种多项式时间算法,它可以找到严格鞍函数的局部最小值点。
什么函数是严格鞍? Ge et al. 2015表明张量分解( tensor decomposition)问题属于严格鞍。 Sun et al. 2015观察到诸如完整的 dictionary learning, phase retrieval问题也是严格鞍。
一阶方法避开鞍点
Trust region算法非常强大。然而它们需要计算目标函数的二阶导数,这在实践中往往过于费时。如果算法只计算函数梯度,是否仍有可能避开鞍点?
这似乎很困难,因为在鞍点处梯度为零向量,并且没有给我们提供任何信息。然而,关键在于鞍点本身是非常不稳定的(unstable):如果我们把一个球放在鞍点处,然后轻微地抖动,球就可能会掉下去!当然,我们需要让这种直觉在更高维空间形式化,因为简单地寻找下跌方向,需要计算Hessian矩阵的最小特征向量。
为了形式化这种直觉,我们将尝试使用一个带有噪声的梯度下降法(noisy gradient descent)
y=x−η∇f(x)+ϵ.
这里ϵ是均值为0的噪声向量。这种额外的噪声会提供初步的推动,使得球会顺着斜坡滚落。
事实上,计算噪声梯度通常比计算真正的梯度更加省时——这也是随机梯度法( stochastic gradient)的核心思想,大量的工作表明,噪声并不会干扰凸优化的收敛。对于非凸优化,人们直观地认为,固有的噪声有助于收敛,因为它有助于当前点远离鞍点(saddle points)。这并不是bug,而是一大特色!

在此之前,没有良好的迭代上限(upper bound)能够确保避开鞍点并到达局部最小值点(local minimum)。在 Ge et al. 2015,我们展示了:
定理(非正式):噪声梯度下降法能够在多项式时间内找到严格鞍函数的局部最小值点。
多项式高度依赖于维度N和Hessian矩阵的最小特征值,因此不是很实用。对于严格鞍问题,找到最佳收敛率仍是一个悬而未决的问题。
最近 Lee et al.的论文表明如果初始点是随机选择的,那么即使没有添加噪声,梯度下降也不会收敛到任何严格鞍点。然而他们的结果依赖于动态系统理论(dynamical systems theory)的 稳定流形定理(Stable Manifold Theorem),其本身并不提供任何步数的上界。
复杂鞍点
通过上文的介绍,我们知道算法可以处理(简单)的鞍点。然而,非凸问题的外形更加复杂,含有退化鞍点(degeneratesaddle points)——Hessian矩阵是半正定的,有0特征值。这样的退化结构往往展示了一个更为复杂的鞍点(如 monkey saddle(猴鞍),图(a))或一系列连接的鞍点(图(b)(c))。在 Anandkumar, Ge 2016我们给出了一种算法,可以处理这些退化的鞍点。

非凸函数的轮廓更加复杂,而且还存在许多公认的问题。还有什么函数是严格鞍?当存在退化鞍点,或者有伪局部最小值点时,我们又该如何使优化算法工作呢?我们希望有更多的研究者对这类问题感兴趣!
原文: Escaping from Saddle Points(http://www.offconvex.org/2016/03/22/saddlepoints/)
译者:刘帝伟 审校:刘翔宇
责编:周建丁(投稿请联系zhoujd@csdn.net)
最优化内点算法
相关内容


机器学习中的最优化算法总结
对于几乎所有机器学习算法,无论是有监督学习、无监督学习,还是强化学习,最后一般都归结为求解最优化问题。 因此,最优化方法在机器学习算法的推导与实现中占据中心地位。 在这篇文章中,sigai将对机器学习中所使用的优化算法做一个全面的总结,并理清它们直接的脉络关系,帮你从全局的高度来理解这一部分知识...
算法优化之道:避开鞍点
避开鞍点为了优化这些存在许多鞍点的非凸函数,优化算法在鞍点处(或者附近)也需要向最优解前进。 最简单的方法就是使用二阶泰勒展开式:? 如果f(x)的...这就是梯度下降算法(gradient descentalgorithm)。 每当梯度f(x)不等于零的时候,只要我们选择一个足够小的步长η,算法就可以保证目标函数向局部最优...

深度学习最常用的学习算法:Adam优化算法
听说你了解深度学习最常用的学习算法:adam优化算法? -深度学习世界。 深度学习常常需要大量的时间和机算资源进行训练,这也是困扰深度学习算法开发的重大原因。 虽然我们可以采用分布式并行训练加速模型的学习,但所需的计算资源并没有丝毫减少。 而唯有需要资源更少、令模型收敛更快的最优化算法,才能从根本上...
优化算法之萤火虫算法
目前研究比较多的有两种算法:蚁群算法(aco)和粒子群算法(pso)。 有研究结果表明,仿生群智能优化算法为许多应用领域提供了新思路和新方法。 2005年,印度学者k.n.krishnanand和d.ghose在ieee群体智能会议上提出了一种新的群智能优化算法,人工萤火虫群优化(glowworm swarm optimization, gso)算法。 2009年...

机器学习 学习笔记(10)序列最小最优化算法
smo算法是一种启发式算法,基本思路是:如果所有边的解都满足此优化问题的kkt条件,那么这个最优化问题的解就得到了,因为kkt条件就是该最优化问题的充分必要条件。 否则,选择两个变量,固定其他变量,针对这两个变量构建一个二次规划问题。 这个二次规划问题关于这两个变量的解应该更接近原始二次规划问题的解...

梯度下降优化算法概述
非凸的损失函数优化过程存在大量的局部最优解或鞍点; 参数更新采用相同的学习率。 针对上述挑战,接下来为大家列举一些优化算法。 如果我们把梯度下降法...那么优化器的作用就是指引初始值 a 点走向最低点 b 点,那么如何让这个过程执行的更加迅速呢? 梯度下降了解一下! 位于三维空间里的任意一个点都可以找到...

教程 | 听说你了解深度学习最常用的学习算法:Adam优化算法?
选自arxiv机器之心编译参与:蒋思源 深度学习常常需要大量的时间和机算资源进行训练,这也是困扰深度学习算法开发的重大原因。 虽然我们可以采用分布式并行训练加速模型的学习,但所需的计算资源并没有丝毫减少。 而唯有需要资源更少、令模型收敛更快的最优化算法,才能从根本上加速机器的学习速度和效果,adam 算法...
优化算法——模拟退火算法
模拟退火算法原理模拟退火算法模拟退火算法过程模拟退火算法流程模拟退火算法的java实现java代码最后的结果模拟退火算法原理爬山法是一种贪婪的方法,对于一个优化问题,其大致图像(图像地址)如下图所示: ? 其目标是要找到函数的最大值,若初始化时,初始点的位置在cc处,则会寻找到附近的局部最大值aa点处,由于aa...

优化算法——模拟退火算法
模拟退火算法原理爬山法是一种贪婪的方法,对于一个优化问题,其大致图像(图像地址)如下图所示: ? 其目标是要找到函数的最大值,若初始化时,初始点的位置在cc处,则会寻找到附近的局部最大值aa点处,由于aa点出是一个局部最大值点,故对于爬山法来讲,该算法无法跳出局部最大值点。 若初始点选择在dd处,根据爬山法...
入门 | 目标函数的经典优化算法介绍
幸运的是,在参数空间的维数非常高的情况下,阻碍目标函数充分优化的局部最小值并不经常出现,因为这意味着对象函数相对于每个参数在训练过程的早期都是凹的。 但这并非常态,通常我们得到的是许多鞍点,而不是真正的最小值。? 找到生成最小值的一组参数的算法被称为优化算法。 我们发现随着算法复杂度的增加,则算法...

优化算法——梯度下降法
一、优化算法概述 优化算法所要求解的是一个问题的最优解或者近似最优解。 现实生活中有很多的最优化问题,如最短路径问题,如组合优化问题等等,同样,也存在很多求解这些优化问题的方法和思路,如梯度下降方法。 机器学习在近年来得到了迅速的发展,越来越多的机器学习算法被提出,同样越来越多的问题利用机器学习...

最优化问题综述
含有不等式约束的优化问题:主要通过kkt条件(karush-kuhn-tucker condition)将其转化成无约束优化问题求解。 3 求解算法3.1 无约束优化算法3. 1...共轭梯度法不仅是解决大型线性方程组最有用的方法之一,也是解大型非线性最优化最有效的算法之一。 在各种优化算法中,共轭梯度法是非常重要的一种。 其...
机器学习优化算法(一)
式中rn(x)是函数f(x)在任意点x与x0处的误差。 这样就得出了函数f(x)的泰勒公式,即与f(x)无限接近的p(x)函数。 2.利用牛顿法求解最优化问题思路: 已知函数待求解最优化问题可以转化为求函数f(x)的极值,求f(x)的极值可以转化为求f(x)的导数 φ′(x)=0的解。 即: 求解得: 于是,随机选择一个初始点x0,然后即可利用...

学界 | 机遇与挑战:用强化学习自动搜索优化算法
另一方面,如果算法空间代表了所有可能的程序,其中必然包含了最佳算法,但这种情况缺乏有效的搜索,因为枚举时间将呈指数级增长。 连续优化(continuous optimization)算法是机器学习最为常见的算法之一,其中包含一系列已知流行的算法,包括梯度下降、动量法、adagrad 和 adam 方法。 我们考虑过自动设计这些优化...

【收藏版】深度学习中的各种优化算法
优化算法里最常见的两个超参数? 都在这里了,前者控制一阶动量,后者控制二阶动量。 3.4nadam最后是nadam。 我们说adam是集大成者,但它居然遗漏了nesterov,这还能忍? 必须给它加上,按照nag的步骤1:? 就是nesterov + adam = nadam了。 说到这里,大概可以理解为什么j经常有人说 adam nadam 目前最主流、最好用的...
数据+进化算法=数据驱动的进化优化?进化算法PK数学优化
对优化问题本身的性质要求是非常低的,不会像数学优化算法往往依赖于一大堆的条件,例如是否为凸优化,目标函数是否可微,目标函数导数是否lipschitz continuity等等。 本人还曾经研究过带有偏微分方程约束的优化问题,很多时候你根本就不知道那个目标函数凸不凸,可导不可导。 这一点是进化算法相对数学优化算法来说...
神经网络突变自动选择AI优化算法,速度提升50000倍!
大明【新智元导读】为特定任务寻找最合适的优化机器学习算法是一件耗时费力的工作,因为没有一种算法能适用于所有任务。 ibm的研究人员提出“神经突变”...选择速度提升了50000倍,错误率仅上升0.6%. 机器学习系统并非是“生而平等”的。 没有一种算法能应对所有的机器学习任务,这就让寻找最优的机器学习算法...

【干货】2018值得尝试的无参数全局优化新算法,所有测试取得最优结果
基于此,作者提出了maxlipo和置信域方法混合使用的优化方法,在所有测试中,都取得了最优结果,而且不需要任何参数。 你还在手动调参? 不如试一下更好的方法。 有一个常见的问题:你想使用某个机器学习算法,但它总有一些难搞的超参数。 例如权重衰减大小,高斯核宽度等等。 算法不会设置这些参数,而是需要你去决定...

【优化算法】遗传算法(Genetic Algorithm) (附代码及注释)
如下所示:1.2-3.2-5.3-7.2-1.4-9.7浮点数编码方法有下面几个优点:1) 适用于在遗传算法中表示范围较大的数。 2) 适用于精度要求较高的遗传算法。 3) 便于较大空间的遗传搜索。 4) 改善了遗传算法的计算复杂性,提高了运算交率。 5) 便于遗传算法与经典优化方法的混合使用。 6) 便于设计针对问题的专门知识的知识型...

MATLAB算法の爬山算法
是的,以上的开场白也说明了爬山算法的优缺点,爬山算法可以很好地求解局域(当地)极大或极小值,但并不能求解全局(全世界)最大或最小值。 爬山算法是一种采用启发式搜索方式来完成局域优化的智能算法。 爬山算法描述如下:对于目标函数f(x),随意选择定义域范围内的一个节点作为起始节点,计算当前的节点与周围的近邻...
返回顶部
zz姚班天才少年鬲融凭非凸优化研究成果获得斯隆研究奖的更多相关文章
- paper 110:凸优化和非凸优化
数学中最优化问题的一般表述是求取,使,其中是n维向量,是的可行域,是上的实值函数.凸优化问题是指是闭合的凸集且是上的凸函数的最优化问题,这两个条件任一不满足则该问题即为非凸的最优化问题. 其中,是 凸 ...
- 凸优化&非凸优化问题
转载知乎大神的回答:Robin Shen 参考:https://www.zhihu.com/question/20343349
- 200万年薪请不到!清华姚班到底有多牛X?
前几天,清华大学自动化系2020年大一新生的C++作业因为太难而上了热搜,该话题在知乎上的热度一度高达 1300+ 万.  在该帖子下方,有很多关于这件事的讨论,其中很多不禁赞叹"清华太牛 ...
- [一起面试AI]NO.9 如何判断函数凸或非凸
首先定义凸集,如果x,y属于某个集合M,并且所有的θx+(1-θ)f(y)也属于M,那么M为一个凸集.如果函数f的定义域是凸集,并且满足 f(θx+(1-θ)y)≤θf(x)+(1-θ)f(y) 则该 ...
- 旷视6号员工范浩强:高二开始实习,“兼职”读姚班,25岁在CVPR斩获第四个世界第一...
初来乍到,这个人说话容易让人觉得"狂". "我们将比赛结果提交上去,果不其然,是第一名的成绩."当他说出这句话的时候,表情没有一丝波澜,仿佛一切顺理成章. 他说 ...
- 中国 AI 天才养成计划:清华姚班和 100 个「张小龙」
https://daily.zhihu.com/story/9653612?from=timeline&isappinstalled=0 AI财经社,专注未来,以及更好的生活 真正的 AI ...
- 【XSY2849】陈姚班 平面图网络流 最短路 DP
题目描述 有一个\(n\)行\(m\)列的网格图. \(S\)到第一行的每一个点都有一条单向边,容量为\(\infty\). 最后一行的每个点到\(T\)都有一条单向边,容量为\(\infty\). ...
- 潭州课堂25班:Ph201805201 并发(非阻塞,epoll) 第十课 (课堂笔记)
# -*- coding: utf-8 -*- # 斌彬电脑 # @Time : 2018/7/12 0012 20:29 import socket server = socket.socket() ...
- 省队集训 Day3 陈姚班
[题目大意] 给一张网格图,上往下有流量限制,下往上没有,左往右有流量限制. $n * m \leq 2.5 * 10^6$ [题解] 考场直接上最大流,50分.竟然傻逼没看出狼抓兔子. 平面图转对偶 ...
随机推荐
- Linux学习笔记-第16天 这些个配置参数好饶阿
原理是懂了,但是配置参数好多阿,难道这些都要记么...呃
- VBS实现UTC时间和本地时间互转
本地时间转UTC时间 dim SWDT, datetime, utcTime Set SWDT = CreateObject("WbemScripting.SWbemDateTime&quo ...
- ORB-SLAM2初步(Tracking.cpp)
今天主要是分析一下Tracking.cpp这个文件,它是实现跟踪过程的主要文件,这里主要针对单目,并且只是截取了部分代码片段. 一.跟踪过程分析 首先构造函数中使用初始化列表对跟踪状态mState(N ...
- Asp.Net Core 工作单元 UnitOfWork UOW
Asp.Net Core 工作单元示例 来自 ABP UOW 去除所有无用特性 代码下载 : 去除所有无用特性版本,原生AspNetCore实现 差不多 2278 行代码: 链接:https://pa ...
- react、less、antd-mobile 报错Inline JavaScript is not enabled. Is it set in your options?
增加less-loader里面的配置.如图或者降级less到2.x版本
- jdk自带监控程序jvisualvm的使用
监控小程序的配置 生产环境tomcat的配置 编辑应用所在的tomcat服务器下的bin目录下的catalina.sh文件,修改如下: 配置如下内容: export JAVA_OPTS="- ...
- pixijs shader教程
pixijs 写shader 底层都封装好了 只要改改片段着色器就行了 pxijs一定刚要设置支持透明 不然 颜色不支持透明度了 const app = new PIXI.Application({ ...
- JeeSite | 访问控制权限
在各种后台系统中都会涉及到权限的管控,从功能权限的管控,到数据权限的管控,都是为了让系统的在使用的过程中更加的安全.功能权限管控是对针对不同的角色可以进行不同的功能操作,而数据权限管控是针对不同的角色 ...
- 阿里云CentOS7.x安装nodejs及pm2
对之前文章的修订 您将了解 CentOS下如何安装nodejs CentOS下如何安装NVM CentOS下如何安装git CentOS下如何安装pm2 适用对象 本文档介绍如何在阿里云CentOS系 ...
- cmake打印shell
cmake链接库失败时,可通过打印路径下对应的lib来定位问题 execute_process(COMMAND ls -lt ${CMAKE_CURRENT_SOURCE_DIR}/lib #执行sh ...