论文阅读笔记五十七:FCOS: Fully Convolutional One-Stage Object Detection(CVPR2019)

论文原址:https://arxiv.org/abs/1904.01355
github: tinyurl.com/FCOSv1
摘要
本文提出了一个基于全卷积的单阶段检测网络,类似于语义分割,针对每个像素进行预测。RetinaNet,SSD,YOLOv3,Faster R-CNN都依赖于预定义的anchor boxes。本文的FCOX是anchor free ,proposal free类型的检测器。将预定义的anchors进行移除,进而减少了大量的计算以及内存占用,同时,anchor中的超参对于最终的结果也有较大的影响,而本文完美的将其避开。FCOS后面接着一个NMS处理。
介绍
基于anchor-based的检测器存在以下缺点:
I. 检测性能对anchor的数量及尺寸影响较大。因此,需要仔细的调整anchor-based的参数。
II. 即使anchor的尺寸预先经过定义,但是当处理变化较大的物体,尤其是小目标时会面临困难,比如要根据新的检测任务重新设计anchor的尺寸。
III.为了得到一个较高的召回率,基于anchor的检测器需要在输入图像上密集的设置anchors,其中大部分anchor被标记为negative,加剧了训练时正负样本之间的不平衡。
IV.计算IoU时,大量的anchor box也会占用大量的计算及内存资源。
基于anchor-based的检测方法偏离全卷积预测的框架,而本文尝试类似于语义分割的像素级预测应用至目标检测任务中。因此,目标检测,语义分割,关键点检测等几种任务可以糅合到一个模型中。一些工作如Dense-Box,UnitBox曾利用基于FCN-based的框架进行目标检测。但这些方法在某一层的feature map上直接预测4D坐标及类别,如下图左侧所示,4D向量表示了边框的边距离该像素点的偏移。这些方法与语义分割的全卷积相类似,但每个位置需要回归一个连续的4D向量。为了处理不同大小的边框,DenseBox将训练图片调整为固定尺寸。DenseBox必须要在图像金字塔上进行检测,违反了全卷积对所有卷积只计算一次的思想。而且,这些方法大多应用在目标检测的特殊场景中,比如文本检测或者人脸检测。如下图右侧所示,较多的重叠框造成了模糊,无法确定重叠区域应该对哪个框进行回归。本文证明通过FPN结构可以消除这种模糊。本文发现在距离目标中心较远的位置会预测一定数量低质量的边界框。为了打压这些边框,本文设计了一个新的分支"center-ness",用于预测一个像素与对应边框中心的偏差。所得的分数用于down-weight 低质量的检测框,最后通过NMS将检测结果进行融合。

FCOS的优点如下:
I.可以将目标检测与语义分割,等基于全卷积的任务进行结合,更加简单。
II.目标检测与anchor/proposal无关,大量减少了参数量,计算量及内存。
III.FCOS也可以与RPN结合取得更好的结果。
IV.通过对模型进行小幅度改造就可以应用到其他视觉任务,比如关键点检测。
本文方法
PART I:基于全卷积的单阶段检测
 表示backbone中第i层feature map,s代表该层之前的stride。对于输入图片ground truth boxes的定义为
表示backbone中第i层feature map,s代表该层之前的stride。对于输入图片ground truth boxes的定义为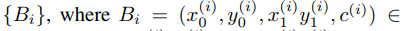
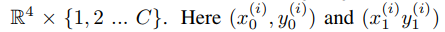 代表边框左上角,右下角的点。
代表边框左上角,右下角的点。 代表该边框所属于的类别。C代表类别总数。
代表该边框所属于的类别。C代表类别总数。
对于feature map Fi上的每个位置(x,y),将其映射回输入图片上为 ,大致为与(x,y)感受野中心的附近。基于anchor的方法是将输入图片的位置作为anchor的中心,并将边框进行回归,而FCOS直接对图片的每个位置进行目标边框的回归,换言之,本文将每个像素看作训练样本,而不是只将anchor boxes看作样本,这点与语义分割的全卷积相似。
,大致为与(x,y)感受野中心的附近。基于anchor的方法是将输入图片的位置作为anchor的中心,并将边框进行回归,而FCOS直接对图片的每个位置进行目标边框的回归,换言之,本文将每个像素看作训练样本,而不是只将anchor boxes看作样本,这点与语义分割的全卷积相似。
当某点(x,y)落入任意ground-truth 边框中,则可以将其看作是postitive 样本,其类别为ground truth边框的类别。否斥,该样本为negative 样本其类别设置为c*=0,本文用一个4D的向量 作为回归目标。
作为回归目标。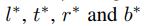 分别代表距离边框四条边的边界。如果一个位置落入多个边框中,则该位置就为模糊样本,目前,本文选择区域最小的边框作为回归目标。下文本文会通过多层次预测大幅度减少模糊样本的数量。(x,y)位置与边框Bi相关,则该位置的回归目标可以按如下方式及计算。FCOS在训练的回归时尽可能利用fore-ground样本,这也是性能优于基于anchor-based方法的可能原因。
分别代表距离边框四条边的边界。如果一个位置落入多个边框中,则该位置就为模糊样本,目前,本文选择区域最小的边框作为回归目标。下文本文会通过多层次预测大幅度减少模糊样本的数量。(x,y)位置与边框Bi相关,则该位置的回归目标可以按如下方式及计算。FCOS在训练的回归时尽可能利用fore-ground样本,这也是性能优于基于anchor-based方法的可能原因。

网络输出:网络输出一个C(类别数)D及4D的向量 ,本文的类别训练并不是基于多任务训练,而是训练C个binary 分类器。本文在backbone的feature map后分别增加了4层卷积层在分类分支及回归分支前。此外,通常,回归目标是positive,本文应用exp(x)在回归分支的顶部将任意实数映射到(0,OO)。FCOS相比基于anchor-based的方法减少了9倍的网络输出。
,本文的类别训练并不是基于多任务训练,而是训练C个binary 分类器。本文在backbone的feature map后分别增加了4层卷积层在分类分支及回归分支前。此外,通常,回归目标是positive,本文应用exp(x)在回归分支的顶部将任意实数映射到(0,OO)。FCOS相比基于anchor-based的方法减少了9倍的网络输出。
损失函数:基于Focal Loss

Inference:本文将class score px,y>0.05的看作是正样本。
PART II:FCOS基于FPN进行多层次预测
FCOS上的存在的两个问题及解决:
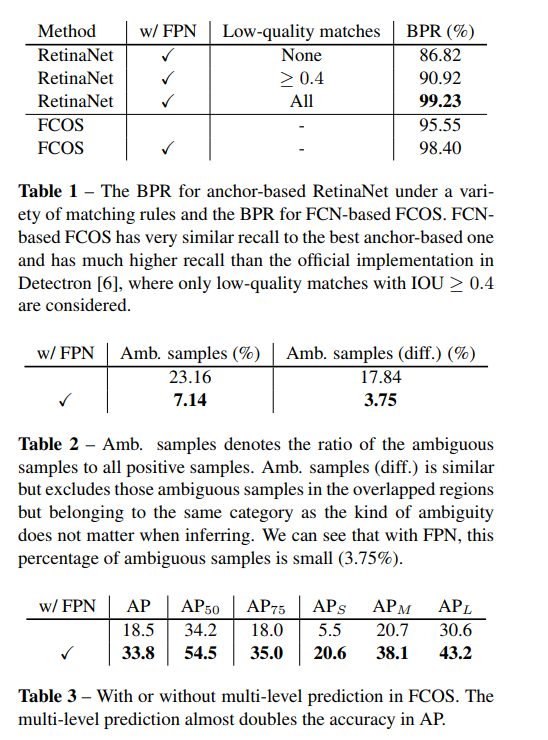
I.CNN中经过加大的stride得到的feature map可能会产生较低的最可能召回率(BPR)。对于基于anchor的方法,可以通过调整IoU的阈值来补偿较大stride导致的较低召回率,对于FCOS来说,由于较大stride后的feature map上没有位置编码信息,因此,FCOS得到的BPR可能会更低,然而,通过FCN仍可以得到较满意的BPR。因此,BPR对于FCOS来说并不是一个问题。此外,通过much-level FPN预测,BPR可以得到进一步的提高可以达到RetinaNet最好的高度。
II.训练时,与ground truth boxes的重叠可能会产生难以理解的模糊情况,会拉低基于FCN检测器的检测能。本文通过多层次预测解决上述问题。
与FPN相似,本文在不同层次的feature map上进行不同尺寸的目标检测。利用feature map的五个层次 P3,P4,P5由backbone 的C3,C4,C5后接1x1的卷积得到。 如下图所示,P6,P7在分别在P5,P6上设置stride 为2并增加卷积层得到。最终,P3,P4,P5,P6,P7的stride分别为8,16,32,64,128。
P3,P4,P5由backbone 的C3,C4,C5后接1x1的卷积得到。 如下图所示,P6,P7在分别在P5,P6上设置stride 为2并增加卷积层得到。最终,P3,P4,P5,P6,P7的stride分别为8,16,32,64,128。
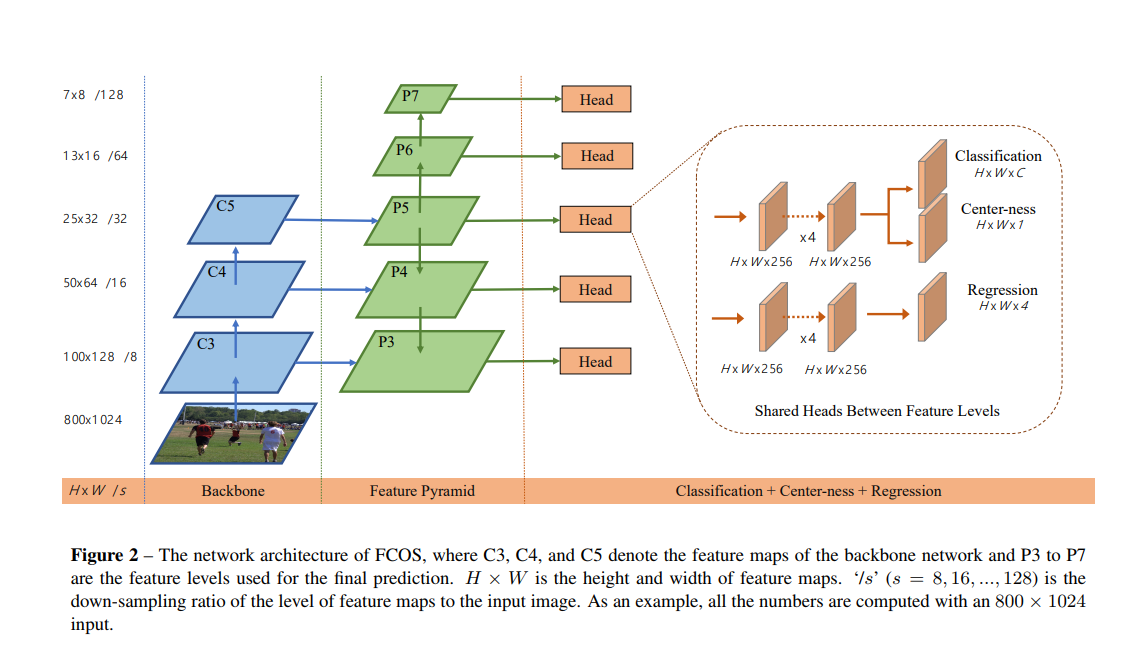
不同于基于anchor的检测器,在不同层的feature map上应用不同尺寸的anchor,本文直接限制边界框回归的范围。首先计算出所有层上每个位置对应的回归目标,l*,t*,r*,b*,若一个位置满足下列两个条件则将其认定为负样本,也没有进行回归的意义了。max(l*,t*,r*,b*)>mi或者max(l*,t*,r*,b*)<mi-1。mi代表feature level i需要回归的最大距离。本文,m2,m3,m4,m5,m6,m7分别设置为0,64,128,256,512及OO.由于不同的目标放置在不同的feature level中,而且,大部分重叠发生在相似大小的目标之间,因此通过多层次预测可以有效移除模糊样本,进而提高基于FCN检测器的心梗你。本文将不同层的feature levels进行共享,不仅使参数有效,而且提高了检测心梗。然而,不同层的feature level需要回归指定大小的回归框。如P3的范围为[0,63],P4的为[64,128].因此,对于不同的feature level使用相同的head这是不合理的。因此,本文并不使用标准的exp(x),而是增加了一个训练参数si,基于exp(si x)根据Pi进行自动调整。
PART III: Center-ness for FCOS
在进行多层次预测后,FCOS仍与基于anchor的检测器的性能存在一定差距。这是由于距离目标中心较远的位置预测出大量低质量的边框造成的。本文在不引进参数的情况下来抑制低质量的边框。平行于分类分支增加了一个分支, 用于预测位位置的"center-ness"如该位置到目标物中心位置的距离。如上图所示,给定一个回归目标,t*,l*,r*,b*,center-ness的回归定义如下所示
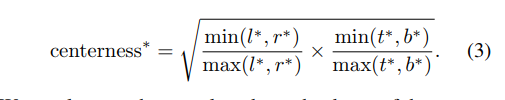
这里用开放的作用是降低center-ness的衰减速度。center-ness的取值范围为0至1,因此使用binary 交叉熵损失进行训练。当进行测试时,通过结合对应的分类分数及多个预测得到的center-ness计算得到分数用于对检测的边框进行排序。因此,center-ness可以降低距离目标中心较远预测框的权重。虽然其更高的概率值,但仍可能会被NMS干掉。对比基于anchor的检测器设置两个IoU的阈值用于对anchor进行标记,center-ness可以看作是soft threshold。在网络训练时进行学习,并不需要花费时间及经历进行微调。,同时本文方法可以将任意落入ground box的位置看作为正样本,因此,可以尽可能的利用正样本用于回归。
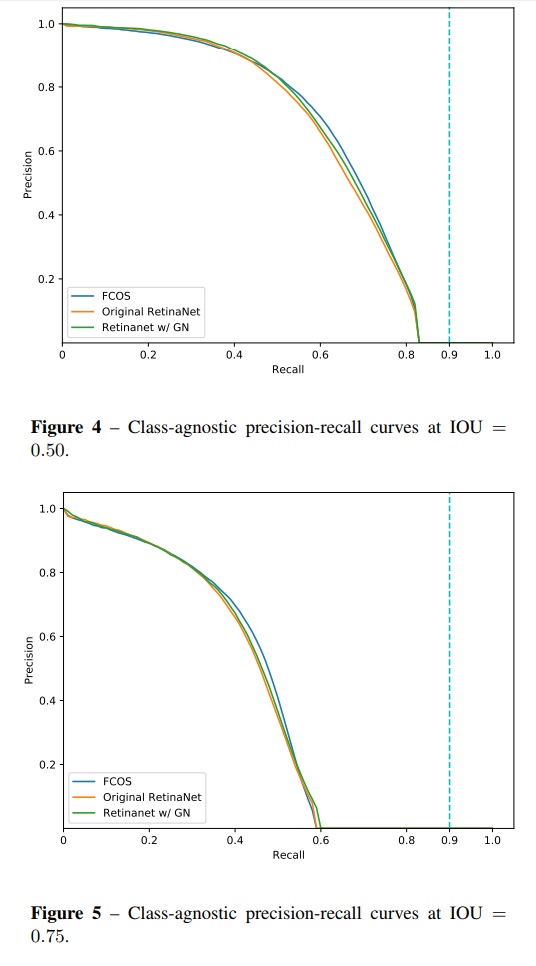
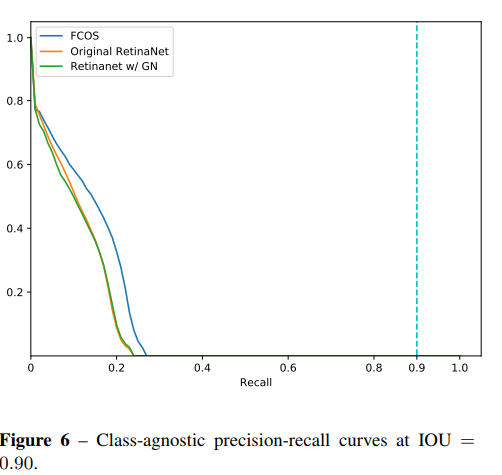
实验








Reference
[1] L. Boominathan, S. S. Kruthiventi, and R. V. Babu.Crowdnet: A deep convolutional network for dense crowd counting. In Proc. ACM Int. Conf. Multimedia,pages 640–644. ACM, 2016.
[2] Y. Chen, C. Shen, X.-S. Wei, L. Liu, and J. Yang.Adversarial PoseNet: A structure-aware convolutional network for human pose estimation. In Proc. IEEE Int.Conf. Comp. Vis., 2017.
[3] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. 2009.
[4] C.-Y. Fu, W. Liu, A. Ranga, A. Tyagi, and A. Berg.DSSD: Deconvolutional single shot detector. arXiv preprint arXiv:1701.06659, 2017.
论文阅读笔记五十七:FCOS: Fully Convolutional One-Stage Object Detection(CVPR2019)的更多相关文章
- 论文阅读笔记五十一:CenterNet: Keypoint Triplets for Object Detection(CVPR2019)
论文链接:https://arxiv.org/abs/1904.08189 github:https://github.com/Duankaiwen/CenterNet 摘要 目标检测中,基于关键点的 ...
- 论文阅读笔记二十七:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks(CVPR 2016)
论文源址:https://arxiv.org/abs/1506.01497 tensorflow代码:https://github.com/endernewton/tf-faster-rcnn 室友对 ...
- 论文阅读笔记五十四:Gradient Harmonized Single-stage Detector(CVPR2019)
论文原址:https://arxiv.org/pdf/1811.05181.pdf github:https://github.com/libuyu/GHM_Detection 摘要 尽管单阶段的检测 ...
- 论文阅读笔记三十三:Feature Pyramid Networks for Object Detection(FPN CVPR 2017)
论文源址:https://arxiv.org/abs/1612.03144 代码:https://github.com/jwyang/fpn.pytorch 摘要 特征金字塔是用于不同尺寸目标检测中的 ...
- 【计算机视觉】【神经网络与深度学习】论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
尊重原创,转载请注明:http://blog.csdn.net/tangwei2014 这是继RCNN,fast-RCNN 和 faster-RCNN之后,rbg(Ross Girshick)大神挂名 ...
- 论文阅读笔记五十六:(ExtremeNet)Bottom-up Object Detection by Grouping Extreme and Center Points(CVPR2019)
论文原址:https://arxiv.org/abs/1901.08043 github: https://github.com/xingyizhou/ExtremeNet 摘要 本文利用一个关键点检 ...
- 论文阅读笔记四十七:Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression(CVPR2019)
论文原址:https://arxiv.org/pdf/1902.09630.pdf github:https://github.com/generalized-iou 摘要 在目标检测的评测体系中,I ...
- 论文阅读笔记五十九:Res2Net: A New Multi-scale Backbone Architecture(CVPR2019)
论文原址:https://arxiv.org/abs/1904.01169 摘要 视觉任务中多尺寸的特征表示十分重要,作为backbone的CNN的对尺寸表征能力越强,性能提升越大.目前,大多数多尺寸 ...
- 论文阅读笔记五十三:Libra R-CNN: Towards Balanced Learning for Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.02701.pdf github:https://github.com/OceanPang/Libra_R-CNN 摘要 相比模型的结构 ...
随机推荐
- node爬虫之图片下载
背景:针对一些想换头像的玩家,而又不知道用什么头像的,作为一名代码爱好者,能用程序解决的,就不用程序来换头像,说干就干,然后就整理了一下. 效果图 环境配置 安装node环境 node -v node ...
- CF1195E OpenStreetMap
题目链接 题意 有一个\(n\times m\)的矩阵,询问其中所有大小为\(a \times b\)的子矩阵的最小值之和. \(1\le n,m \le 3000\) 思路 因为是子矩阵的大小是固定 ...
- [转]python 中的[:-1]和[::-1]
转自:https://blog.csdn.net/mingyuli/article/details/81604795 1.案例解释a='python'b=a[::-1]print(b) #nohtyp ...
- Python连载26-shelve模块
一.持久化 --shelve 持久化工具 (1)作用:类似字典,用kv对保存数据,存取方式类似于字典 (2)例子:通过一下案例创建了一个数据库,第二个程序我们读取了数据库 #使用shelve创建文件并 ...
- Linux网络编程基础API
第5章 Linux网络编程基础API 探讨Linux网络编程基础API与内核中TCP/IP协议族之间的关系,并未后续章节提供编程基础.从3个方面讨论Linux网络API. socket地址API.so ...
- CMPT 300 – Operating Systems
Assignment 4 – Create Simple YetFunctional File SystemCMPT 300 – Operating SystemsPlease submit a zi ...
- 算法初步---基本的数据结构(java为例)
最近搞算法,觉得超级吃力的,一直以为数学好的,数学可以考试满分,算法一定没什么问题,贱贱地,我发现我自己想多了,还是自己的基础薄弱吧,今天我来补补最基础的知识. 算法(Algorithm)是指解题方案 ...
- SQL Server温故系列(0):导航目录
创建本系列博文通用库表及数据的 SQL 语句:下载 SQL Server温故系列(0):导航目录 SQL Server温故系列(1):SQL 数据操作 CRUD 之增删改合 SQL Server温故系 ...
- 纯C语言实现循环双向链表创建,插入和删除
#include <stdio.h> #include <stdlib.h> typedef int ElemType; typedef struct DLNode{ Elem ...
- Python基础18
“为什么有列表,还要元组?” 1. 元组可看成是简单的对象组合,而列表是随时间改变的数据集合. 2. 元组的不可变特性提供了某种完整性,确保元组不会被另一个引用来修改.类似于其它语言中的常数声明.