The Rise of Meta Learning
The Rise of Meta Learning
2019-10-18 06:48:37
This blog is from: https://towardsdatascience.com/the-rise-of-meta-learning-9c61ffac8564


https://openai.com/blog/solving-rubiks-cube/
Meta-Learning describes the abstraction to designing higher level components associated with training Deep Neural Networks. The term “Meta-Learning” is thrown around in Deep Learning literature frequently referencing “AutoML”, “Few-Shot Learning”, or “Neural Architecture Search” when in reference to the automated design of neural network architectures. Emerging from comically titled papers such as “Learning to learn by gradient descent by gradient descent”, the success of OpenAI’s rubik’s cube robotic hand demonstrates the maturity of the idea. Meta-Learning is the most promising paradigm to advance the state-of-the-art of Deep Learning and Artificial Intelligence.
OpenAI set the AI world on fire by demonstrating ground-breaking capabilities of a robotic hand trained with Reinforcement Learning. This success builds on a very similar study presented in July 2018 tasking a robotic hand to orient a block in a configuration matching a visual prompt. This evolution from block orientation to solving a rubik’s cube is fueled by a Meta-Learning algorithm controlling the training data distribution in simulation, Automatic Domain Randomization (ADR).
Domain Randomization — Data Augmentation
Domain randomization is an algorithm to address the data augmentation problem for Sim2Real transfer. The core function of function approximation (and Deep Learning) is to generalize from what it has learned in training, to never-seen-before test data. Although not as surprising as misclassifications do to hardly noticeable adversarial noise injections, Deep Convolutional Neural Networks will not generalize when trained on images in simulation (displayed below on the left) to real visual data (shown below on the right) without special modifications.
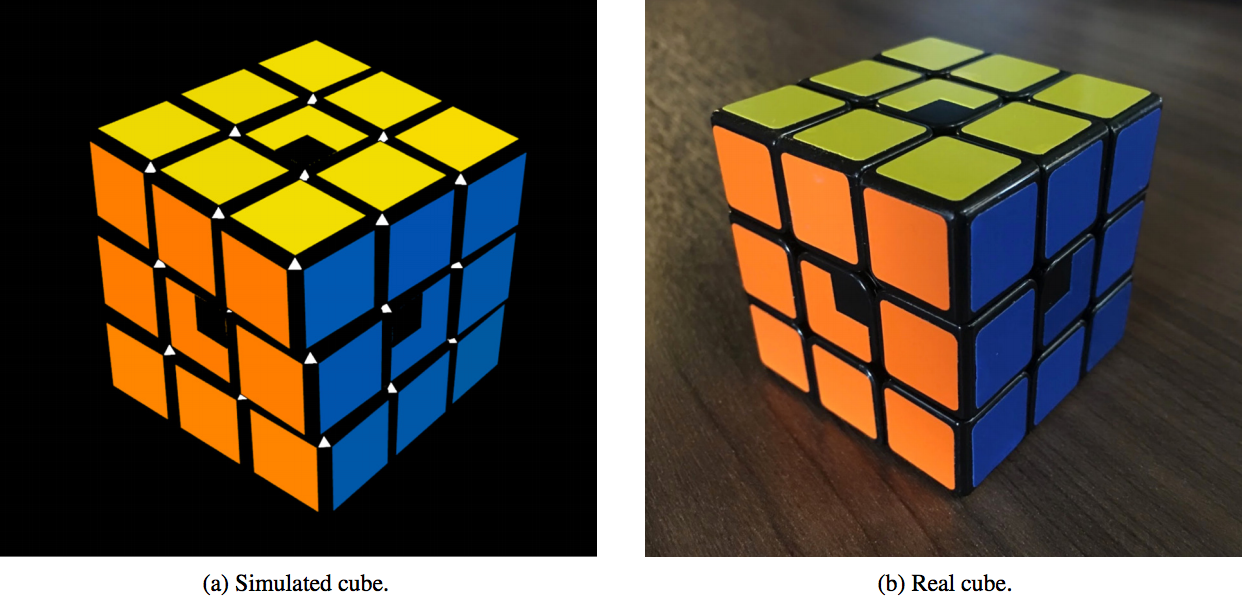
“Solving Rubik’s Cube with a Robot Hand” by Ilge Akkaya, Marcin Andrychowicz, Maciek Chociej, Mateusz Litwin, Bob McGrew, Arthur Petron, Alex Paino, Matthias Plappert, Glenn Powell, Raphael Ribas, Jonas Schneider, Nikolas Tezak, Jerry Tworek, Peter Welinder, Lilian Weng, Qiming Yuan, Wojciech Zaremba, Lei Zhang
Naturally, there are two approaches to align the simulated and real data distributions. One such approach, developed by researchers at Apple is called SimGAN. SimGAN uses an adversarial loss to train the generator of a Generative Adversarial Network to make simulated images appear as realistic as possible, criticized by a discriminator classifying images as belonging to the real or simulated dataset. The research reports a positive result on eye gaze estimation and hand pose estimation. The other approach is to make the simulated data as diverse as possible, contrarily to as realistic as possible.
The latter approach is referred to as Domain Randomization. This idea is well illustrated in the image below from Tobin et al.’s paper in 2017:

“Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World” by Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, Pieter Abbeel
Domain Randomization appears to be the key to bridging the Sim2Real gap, allowing Deep Neural Networks to generalize to real data when trained on simulation. Not unlike most algorithms, Domain Randomization comes with many parameters to be tuned. The image below shows randomizations in the colors of the blocks, the lighting of the environment, and the magnitude of shadows, to name a few. Each of these randomized environment features comes with a lower to upper bound interval and some kind of sampling distribution. For example, when sampling a randomized environment, what is the probability this environment has very bright lighting?
In OpenAI’s original Dactyl study achieving block orientation with a robotic hand, the domain randomization data curriculum is manually encoded prior to the experiment. This domain randomization transcends the visual world, randomizing components in the physics simulator that leads to a policy enabling the robotic hand to move with dexterity and precision. Similarly to the idea of visual randomization, these physics randomizations include dimensions such as the size/mass of the cube and the friction of the fingers in the robot’s hand, amongst others (See Appendeix B of Solving Rubik’s Cube with a Robot Hand for more details).
The key from Dactyl to the Rubik’s Cube solver is that the domain randomization is curriculum defining the intensity of randomization is automated rather than manually designed, clearly defined in the following lines of the ADR algorithm:
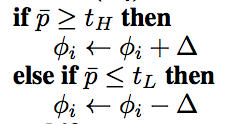
Image from “Solving Rubik’s Cube with a Robot Hand”. If the agent’s performance exceeds a parametric performance threshold, the intensity of the randomization is increased (given by delta with phi defining the distribution of the environment parameters)
AI that Designs its Own Data
One of the best examples of AI that designs its own data is the Paired Open-Ended Trailblazer (POET) algorithm developed by researchers at Uber AI Labs.
“Paired Open-Ended Trailblazer (POET): Endlessly Generating Increasingly Complex and Diverse Learning Environments and Their Solutions” by Rui Wang, Joel Lehman, Jeff Clune, Kenneth O. Stanley
POET trains a bipedal walking agent by simultaneously optimizing the agent and the environment in which it learns to walk in. POET is different from OpenAI’s rubik’s cube solver in that it uses an evolutionary algorithm, maintaining a population of walkers and environments. The structure of having populations of agents and environments is key to structuring the evolution of complexity in this research. Despite the use of Reinforcement Learning to train a single agent compared to Population-based Learning to adapt a group of agents, POET and Automatic Domain Randomization are very similar. They both develop a progression of increasingly challenging training datasets in an automated way. The Bipedal’s walking environment does not change as a manually encoded function, but rather as a result of the population of walkers performances in the different environments, signaling when it is time to crank up the challenge of the terrain.
Data or Models?
Research in Meta-Learning has generally focused on data and model architectures, with exceptions such as Meta-Learning optimizers, which seems to still fall under the umbrella of model optimization. Meta-learning in the data space such as Automatic Domain Randomization has been heavily studied in the form of Data Augmentation.
Data Augmentation is most easily understood in the context of image data, although we have already seen how the physics data can be augmented and randomized as well. These image augmentations typically include horizontal flips and small magnitudes of rotations or translations. This kind of augmentation is typical in any computer vision pipeline such as image classification, object detection, or super resolution.
Curriculum Learning is another data-level optimization concerned with the order in which data is presented to learning models. For example, starting a student off with easy examples such as 2 + 2 = 4, before introducing more difficult ideas such as 2³ = 8. Meta-Learning controllers of Curriculum Learning look at how data is ranked according to some metric of perceived difficulty and the order in which this data should be presented in. A recent study from Hacohen and Weinshall presents interesting success with this (shown below) in the ICML 2019 conference.
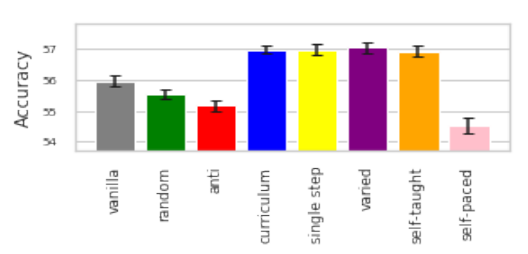
“On the Power of Curriculum Learning in Training Deep Networks” by Guy Hacohen and Daphan Weinshall. Vanilla SGD data selection shown on the gray bar on the far left is outperformed by curriculum learning methods
Neural Architecture Search, or Meta-Learning models generally receive more attention than data-level optimizations. This is highly motivated by the trends in Deep Learning research. There is a clear performance benefit from extending the foundational AlexNet architecture that pioneered the use of Deep Convolutional Networks trained on big datasets on big GPU computing to the ResNet architecture. ResNet was further extended with manual designs such as DenseNet, and then surpassed by meta-learning techniques such as AmoebaNet and EfficientNet. The timeline of image classification benchmark advancement can be found onpaperswithcode.com.
Meta-learning neural architectures try to describe a space of possible architectures and then search for the best architecture according to one or multiple objective metrics.
Advanced Meta Learners
Neural Architecture Search has employed a wide range of algorithms to search for architectures, Random Search, Grid Search, Bayesian Optimization, Neuro-evolution, Reinforcement Learning, and Differentiable Search. These search algorithms are all relatively sophisticated compared to the technique presented in OpenAI’s Automatic Domain Randomization. It seems likely that the ideas of Automatic Domain Randomization would be improved with advanced search algorithms, i.e. something like the Population-Based Search proven useful in Data Augmentation by Researchers at UC Berkeley or AutoAugment from Google.
How Expressive is Meta Learning?
One of the limitations of Meta-Learning frequently addressed in Neural Architecture Search is the constraint of the search space. Neural Architecture Searches begin from a manually designed encoding of possible architectures. This manual encoding naturally limits the discoveries possible by the search. However, there is a trade-off necessary to make the search computable at all.
Current architecture searches view neural architectures as Directed Acyclic Graphs (DAGs) and try to optimize the connections between nodes. Papers such as “Weight Agnostic Neural Networks” by Gaier and Ha and “Exploring Randomly Wired Neural Networks for Image Recognition” by Xie et al. show that constructing DAG neural architectures is complex and not well understood.
The interesting question is when will Neural Architecture Search be able to optimize the operations at nodes, the connections between them, and then have the freedom to discover things like novel activation functions, optimizers, or normalization techniques such as Batch Normalization.
It is interesting to think about how abstract can Meta-Learning controllers be. For example, OpenAI’s Rubik’s cube solver essentially has 3 “intelligent” components, a symbolic rubik’s cube solver, a vision model, and a controller network to manipulate the robotic hand. Could Meta-Learning controllers be smart enough to understand this kind of modularity and design the hybrid systems between symbolic and Deep Learning systems recently campaigned by Gary Marcus?
Meta-Learning data augmentation is very constrained as well. Most data augmentation searches (even automatic domain randomization) is constrained to a set of transformations available to the meta-learning controller. These transformations could include things like the brightness of the image or the intensity of shadows in the simulation. An interesting opportunity for increasing the freedom of data augmentation is to combine these controllers with generative models capable of exploring very unique data points. These generative models could design new images of dogs and cats, rather than rotating existing ones or making the images darker/brighter. Although very interesting, it doesn’t seem like the current state-of-the-art generative models such as BigGAN or VQ-VAE-2 works for data augmentation on ImageNet classification.
Transfer and Meta Learning
“Meta-Learning” is frequently used to describe the capabilities of transfer and few-shot learning, differently from how “AutoML” is used to describe the optimization of models or datasets. This kind of definition aligns well with the domain adaptation task of Sim2Real solved by Automatic Domain Randomization. However, this definition also describes learning such as transferring from ImageNet classification to identifying steel defects.

An interesting result of the Rubik’s Cube Solver is the ability to adapt to perturbations. For example, the solver is able to continue despite putting a rubber glove on the hand, tying fingers together, and blanket occlusion of the cube, (the vision model must be completely impaired, thus the sensing has to be done by the Giiker cube’s sensors). This kind of Transfer Meta-Learning is a result of the LSTM layers in the policy network used to train the robotic hand control. I think this use of “Meta-Learning” is more of a characteristic of Memory Augmented Networks compared to AutoML optimization. I think this demonstrates the difficulty of unifying Meta-Learning and settling on a single definition for the term.
Conclusion
The success of the Rubik’s Cube solver is obviously compelling due to the flashy display of robot hand coordination. However, the more interesting component of this research is the Meta-Learning Data Randomization under the hood. This is an algorithm that is learning while simultaneously designing its training data. This paradigm, described in Jeff Clune’s AI-GAs, of algorithms that contain meta-learning architectures, meta-learning the learning algorithms themselves, and generating effective learning environments stand to be an enormous opportunity for the advancement of Deep Learning and Artificial Intelligence. Thank you for reading!
The Rise of Meta Learning的更多相关文章
- [转载]Meta Learning单排小教学
原文链接:Meta Learning单排小教学 虽然Meta Learning现在已经非常火了,但是还有很多小伙伴对于Meta Learning不是特别理解.考虑到我的这个AI游乐场将充斥着Meta ...
- 论文笔记:Visual Question Answering as a Meta Learning Task
Visual Question Answering as a Meta Learning Task ECCV 2018 2018-09-13 19:58:08 Paper: http://openac ...
- 深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning)
深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning) 2018-08-09 12:21:33 The video tutorial can ...
- (转)Paper list of Meta Learning/ Learning to Learn/ One Shot Learning/ Lifelong Learning
Meta Learning/ Learning to Learn/ One Shot Learning/ Lifelong Learning 2018-08-03 19:16:56 本文转自:http ...
- 论文阅读之:Deep Meta Learning for Real-Time Visual Tracking based on Target-Specific Feature Space
Deep Meta Learning for Real-Time Visual Tracking based on Target-Specific Feature Space 2018-01-04 ...
- MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning
MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning 2019-08-11 19:48:17 Paper: h ...
- 【MetaPruning】2019-ICCV-MetaPruning Meta Learning for Automatic Neural Network Channel Pruning-论文阅读
MetaPruning 2019-ICCV-MetaPruning Meta Learning for Automatic Neural Network Channel Pruning Zechun ...
- 【元学习】Meta Learning 介绍
目录 元学习(Meta-learning) 元学习被用在了哪些地方? Few-Shot Learning(小样本学习) 最近的元学习方法如何工作 Model-Agnostic Meta-Learnin ...
- 什么是 Meta Learning / Learning to Learn ?
Learning to Learn Chelsea Finn Jul 18, 2017 A key aspect of intelligence is versatility – the cap ...
随机推荐
- Palo Alto GlobalProtect上的PreAuth RCE
0x00 前言 SSL VPN虽然可以保护企业资产免受互联网被攻击的风险影响,但如果SSL VPN本身容易受到攻击呢?它们暴露在互联网上,可以可靠并安全地连接到内网中.一旦SSL VPN服务器遭到入侵 ...
- 解决在页面中无法获取qrcode.js生成的base64的图片
应用场景 生成带二维码的推广海报图片 旧方法: 将用户自己的推广连接先通过qrcode.js生成二维码,然后再用后台返回的一张背景图片和二维码通过canvas绘制成一张海报. 问题 在部分安卓手机上获 ...
- vagrant 无法挂载共享目录
Vagrant was unable to mount VirtualBox shared folders. This is usually because the filesystem " ...
- SpringBoot2.x搭建SpringBootAdmin2.x
1 说明 全部配置基于1.8.0_111 当前SpringBoot使用2.0.5 SpringBootAdmin基于Eureka进行Client发现,Eureka搭建参见SpringBoot2.x搭建 ...
- Python 字符集
什么是字符? 1.在Python中,字符串中的内容都是字符. 2.什么是字符编码(encode)和字符集(charset)? 计算机只能识别数值,而字符不能识别,为了让计算机能处理字符,必须将字符和数 ...
- 黄金矿工(LeetCode Medium难度)1129题 题解(DFS)
题目描述: 给定一个二维网络,给定任意起点与终点.每一步可以往4个方向走.要找出黄金最多的一条线路. 很明显的是要“一条路走到黑,一直下去直到某个条件停止”. 运用dfs(深度优先搜索)求解. 因为起 ...
- seaborn(1)---画关联图
将 Seaborn 提供的样式声明代码 sns.set() 放置在绘图前,就可以设置图像的样式 sns., color_codes=False, rc=None) context= 参数控制着默认的画 ...
- 《团队名称》第八次团队作业:Alpha冲刺day4
项目 内容 这个作业属于哪个课程 2016计算机科学与工程学院软件工程(西北师范大学) 这个作业的要求在哪里 实验十二 团队作业8-软件测试与ALPHA冲刺 团队名称 快活帮 作业学习目标 (1)掌握 ...
- Convert PadLeft Bit Operate
using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace Cons ...
- 什么叫pure function(纯函数)
(来自:http://en.wikipedia.org/wiki/Pure_function) 在计算机编程中,假如满足下面这两个句子的约束,一个函数可能被描述为一个纯函数: 给出同样的参数值,该函数 ...